
JavaScript의 작동 메커니즘과 원리를 완전히 마스터하세요.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2022-04-25 17:05:203331검색
이 기사는 javascript에 대한 관련 지식을 제공합니다. 주로 JavaScript 작동 메커니즘과 파싱 엔진 및 기타 내용을 소개합니다. 모두에게 도움이 되기를 바랍니다.

[관련 권장 사항: javascript 비디오 튜토리얼, web front-end]
저는 2년 넘게 js를 작성해왔지만 작동 메커니즘과 원리를 이해한 적이 없습니다. 오늘은 특별히 설명하겠습니다. 저의 요약은 아래에 기록되어 있습니다:
JavaScript 구문 분석 엔진이란 무엇입니까
간단히 말하면 JavaScript 구문 분석 엔진은 JavaScript 코드를 "읽고" 결과를 정확하게 제공할 수 있는 프로그램입니다. 코드 실행.
예를 들어 var a = 1 + 1;과 같은 코드를 작성할 때 JavaScript 엔진이 하는 일은 코드를 이해(파싱)하고 a의 값을 2로 변경하는 것입니다.
컴파일의 원리를 공부해본 분들은 아시겠지만 정적 언어(Java, C++, C 등)의 경우 위의 사항을 처리하는 것을 컴파일러(Compiler)라고 하고, 이에 상응하는 동적 언어의 경우도 JavaScript와 같은 것을 인터프리터(Interpreter)라고 합니다. 둘의 차이점은 한 문장으로 요약할 수 있습니다. 컴파일러는 소스 코드를 다른 유형의 코드(예: 기계 코드, 바이트 코드)로 컴파일하고, 인터프리터는 코드 실행 결과를 직접 구문 분석하여 출력합니다. 예를 들어 Firebug의 콘솔은 JavaScript 인터프리터입니다.
그러나 지금은 JavaScript 엔진이 인터프리터인지 컴파일러인지 정의하기가 어렵습니다. 예를 들어 V8(Chrome의 JS 엔진)은 실제로 JS의 실행 성능을 향상시키기 위해 먼저 JS를 네이티브로 컴파일하기 때문입니다. 기계어 코드를 입력한 다음 기계어 코드를 실행합니다(이것이 훨씬 빠릅니다).
JavaScript 파싱 엔진과 ECMAScript의 관계는 무엇인가요?
JavaScript 엔진은 프로그램이고, 우리가 작성하는 JavaScript 코드도 프로그램이 되도록 하려면 어떻게 해야 할까요? 이를 위해서는 규칙 정의가 필요합니다. 예를 들어, 앞서 언급한 var a = 1 + 1;은 다음을 의미합니다.
왼쪽의 var는 변수 a를 선언하는 선언을 나타냅니다.
오른쪽의 +는 1과 1의 더하기를 나타냅니다
중간 등호는 이것이 할당문이라는 것을 나타냅니다
마지막 세미콜론은 이 구문의 끝을 나타냅니다
이것이 규칙입니다. 여기에는 측정 기준이 있습니다. JavaScript 엔진은 이 표준에 따라 JavaScript 코드를 구문 분석할 수 있습니다. 그런 다음 ECMAScript는 이러한 규칙을 정의합니다. 그중에서도 ECMAScript 262 문서는 JavaScript 언어에 대한 완전한 표준 세트를 정의합니다. 여기에는 다음이 포함됩니다.
var, if, else, break, continue 등은 JavaScript 키워드입니다.
abstract, int, long 등은 JavaScript 예약어입니다.
숫자로 계산하는 방법, 문자열로 계산하는 방법 등
연산자 정의( +, -, >, JavaScript 구문 정의
== 처리 방법과 같은 표현식, 명령문 등에 대한 표준 처리 알고리즘 정의
⋯⋯
표준 JavaScript 엔진은 이 문서 세트를 구현하기 위해 IE의 JS 엔진과 같이 표준을 따르지 않는 구현도 있기 때문에 여기서는 표준이 강조된다는 점에 유의하세요. 이것이 JavaScript에 호환성 문제가 있는 이유입니다. IE의 JS 엔진이 표준에 따라 구현되지 않는 이유는 브라우저 전쟁에 관한 것이므로 여기서는 Google에서 직접 설명하지 않겠습니다.
쉽게 말하면 ECMAScript는 언어의 표준을 정의하고, JavaScript 엔진은 이에 따라 이를 구현합니다.
JavaScript 구문 분석 엔진과 브라우저의 관계는 무엇인가요?
간단히 말하면 JavaScript 엔진은 브라우저의 구성 요소 중 하나입니다. 브라우저는 페이지 구문 분석, 페이지 렌더링, 쿠키 관리, 기록 기록 등과 같은 다른 많은 작업을 수행해야 하기 때문입니다. 글쎄, JavaScript 엔진은 구성 요소이기 때문에 일반적으로 브라우저 개발자가 직접 개발합니다. 예: IE9의 Chakra, Firefox의 TraceMonkey, Chrome의 V8 등
또한 브라우저마다 서로 다른 JavaScript 엔진을 사용하는 것을 볼 수 있습니다. 따라서 우리가 말할 수 있는 것은 어떤 JavaScript 엔진을 더 깊이 이해해야 하는가입니다.
JavaScript가 단일 스레드인 이유
JavaScript 언어의 주요 특징은 단일 스레드, 즉 한 번에 한 가지 작업만 수행할 수 있다는 것입니다. 그렇다면 JavaScript는 왜 다중 스레드를 가질 수 없습니까? 이렇게 하면 효율성이 향상될 수 있습니다.
JavaScript는 목적에 따라 단일 스레드입니다. 브라우저 스크립팅 언어인 JavaScript의 주요 목적은 사용자와 상호 작용하고 DOM을 조작하는 것입니다. 이는 단일 스레드만 가능하다는 것을 결정합니다. 그렇지 않으면 매우 복잡한 동기화 문제가 발생합니다. 예를 들어 JavaScript에 두 개의 스레드가 동시에 있다고 가정해 보겠습니다. 한 스레드는 특정 DOM 노드에 콘텐츠를 추가하고 다른 스레드는 해당 노드를 삭제합니다. 이 경우 브라우저는 어떤 스레드를 사용해야 합니까?
복잡함을 피하기 위해 JavaScript는 탄생 이후부터 단일 스레드를 사용했으며 이는 이 언어의 핵심 기능이 되었으며 앞으로도 변하지 않을 것입니다.
멀티 코어 CPU의 컴퓨팅 성능을 활용하기 위해 HTML5는 JavaScript 스크립트가 여러 스레드를 생성할 수 있도록 허용하지만 하위 스레드는 기본 스레드에 의해 완전히 제어되며 DOM을 작동해서는 안 되는 Web Worker 표준을 제안합니다. . 따라서 이 새로운 표준은 JavaScript의 단일 스레드 특성을 변경하지 않습니다.
프로세스와 스레드 구별
프로세스는 CPU 리소스 할당의 가장 작은 단위이며, 프로세스는 여러 스레드를 포함할 수 있습니다. 브라우저는 다중 프로세스이며 열려 있는 각 브라우저 창은 프로세스입니다.
스레드는 CPU 스케줄링의 가장 작은 단위입니다. 프로그램의 메모리 공간은 동일한 프로세스의 스레드 간에 공유됩니다.
과정을 창고라고 생각하시면 되고, 실은 운송이 가능한 트럭입니다. 각 창고에는 창고(운송 물품)를 서비스하기 위한 자체 여러 트럭이 동시에 여러 대의 차량으로 끌릴 수 있습니다. 그러나 각 창고는 동시에 상품을 끌어올 수 있습니다. 차량은 한 번에 한 가지 작업만 수행할 수 있습니다. 바로 이 화물을 운송하는 것입니다.
핵심 포인트:
프로세스는 CPU 리소스 할당의 최소 단위(리소스를 소유하고 독립적으로 실행할 수 있는 최소 단위)
스레드는 CPU 스케줄링의 최소 단위(스레드는 프로세스) 실행 단위, 하나의 프로세스에 여러 스레드가 있을 수 있음)
서로 다른 프로세스도 통신할 수 있지만 비용이 더 높습니다.
브라우저는 다중 프로세스입니다
프로세스와 스레드의 차이점을 이해한 후 브라우저에 대해 어느 정도 이해해 보겠습니다. (먼저 단순화된 이해를 살펴보겠습니다.)
브라우저는 다중 프로세스입니다
브라우저는 실행할 수 있습니다. 시스템이 프로세스에 리소스(CPU, 메모리)를 할당하기 때문입니다. 간단히 말하면 탭 페이지가 열릴 때마다 독립적인 브라우저 프로세스를 만드는 것과 같습니다.
Chrome을 예로 들면 여러 개의 탭이 있으며 Chrome의 작업 관리자에서 여러 프로세스를 볼 수 있습니다(각 탭 페이지에는 독립적인 프로세스와 기본 프로세스가 있음). Windows에서는 작업 관리자에서도 볼 수 있습니다.
참고: 브라우저에는 여기에 자체 최적화 메커니즘도 있어야 합니다. 때로는 여러 탭 페이지를 연 후 Chrome 작업 관리자에서 일부 프로세스가 병합된 것을 볼 수 있습니다(따라서 각 탭 레이블이 하나의 프로세스에 해당하지 않음). 절대)
브라우저에는 어떤 프로세스가 포함되어 있나요?
브라우저가 다중 프로세스라는 것을 알고 나면 어떤 프로세스가 포함되어 있는지 살펴보겠습니다. (이해를 단순화하기 위해 주요 프로세스만 나열합니다.)
(1 ) 브라우저 프로세스 : 브라우저의 주요 프로세스는 단 하나뿐입니다(조정 및 제어를 담당). 역할:
브라우저 인터페이스 표시 및 사용자와의 상호 작용을 담당합니다. 정방향, 역방향 등- 각 페이지의 관리, 다른 프로세스의 생성 및 파괴를 담당합니다.
- 렌더러 프로세스에서 얻은 메모리에 비트맵을 사용자 인터페이스에 그립니다.
- 네트워크 리소스 관리, 다운로드,
- (2) 타사 플러그인 프로세스: 각 플러그인 유형은 플러그인을 사용할 때만 생성되는 프로세스에 해당합니다.
(4) 브라우저 렌더링 프로세스(브라우저 커널, 렌더러 프로세스, 내부 멀티스레드): 기본적으로 각 탭 페이지에는 하나의 프로세스가 있으며 서로 영향을 미치지 않습니다. 주요 기능은 페이지 렌더링, 스크립트 실행, 이벤트 처리 등입니다.
메모리 향상: 브라우저에서 웹 페이지를 여는 것은 새 프로세스를 시작하는 것과 같습니다(프로세스에는 자체 멀티 스레드가 있습니다)
물론, 브라우저는 때때로 여러 프로세스를 병합합니다(예를 들어, 여러 개의 빈 탭을 연 후 여러 개의 빈 탭이 하나의 프로세스로 병합된 것을 볼 수 있습니다)
다중 프로세스 브라우저의 장점
단일 프로세스 브라우저와 비교하여, 다중 프로세스 장점:
전체 브라우저에 영향을 미치는 단일 페이지 충돌 방지- 전체 브라우저에 영향을 미치는 타사 플러그인 충돌 방지
- 다중 프로세스가 멀티 코어 장점을 최대한 활용
- 샌드박스 모델을 편리하게 사용 브라우저 안정성을 향상시키기 위해 플러그인 및 기타 프로세스를 분리합니다.
- 간단한 이해:
브라우저가 단일 프로세스인 경우 특정 탭 페이지의 충돌이 전체 브라우저에 영향을 미치므로 비슷한 경험이 얼마나 나쁠 것입니까? , 단일 프로세스인 경우 플러그인 충돌은 전체 브라우저에도 영향을 미칩니다.
물론 메모리와 기타 리소스 소비도 더 커지게 되는데, 이는 공간이 시간으로 교환된다는 의미입니다. 아무리 메모리가 커도 크롬에서는 부족합니다. 메모리 누수 문제는 이제 조금 개선됐을 뿐이고, 전력 소모도 늘어나게 됩니다.
브라우저 커널(렌더링 프로세스)
여기서 핵심이 나옵니다. 위에서 언급한 프로세스가 너무 많다는 것을 알 수 있는데, 일반적인 프런트 엔드 작업에 대한 최종 요구 사항은 무엇입니까? 대답은 렌더링 프로세스입니다.
페이지 렌더링, JS 실행, 이벤트 루프가 모두 이 프로세스 내에서 수행되는 것으로 이해할 수 있습니다. 다음으로 이 프로세스를 분석하는 데 집중하세요
브라우저의 렌더링 프로세스가 멀티 스레드라는 점을 명심하세요(JS 엔진은 단일 스레드입니다)그런 다음 어떤 스레드가 포함되어 있는지 살펴보겠습니다. 스레드 ):
1. GUI 렌더링 스레드
- 는 브라우저 인터페이스 렌더링, HTML, CSS 구문 분석, DOM 트리 및 RenderObject 트리(간단히 Flutter의 핵심 중 하나인 CSS로 구성된 스타일 트리로 이해됨), 레이아웃 및 그리기를 담당합니다. , 등.
- 인터페이스를 다시 그려야 하거나(Repaint) 일부 작업으로 인해 리플로우가 발생하는 경우 이 스레드가 실행됩니다.
- JS 엔진이 실행될 때 GUI 렌더링 스레드와 JS 엔진 스레드는 상호 배타적입니다. GUI 스레드는 일시 중단(동결)되고 GUI 업데이트는 대기열에 저장되어 JS 엔진이 유휴 상태일 때 즉시 실행됩니다.
2. JS 엔진 스레드
- 는 JS 커널이라고도 하며 Javascript 스크립트 프로그램 처리를 담당합니다. (예: V8 엔진)
- JS 엔진 스레드는 Javascript 스크립트를 구문 분석하고 코드를 실행하는 역할을 담당합니다.
- JS 엔진은 작업 대기열에 작업이 도착하기를 기다렸다가 언제든지 탭 페이지(렌더러 프로세스)에서 JS 프로그램을 실행하는 JS 스레드가 하나만 있습니다
- 또한 GUI 렌더링 스레드와 JS 엔진 스레드는 상호 배타적이므로 JS 실행 시간이 너무 길면 페이지 렌더링이 일관되지 않아 페이지 렌더링 및 로딩이 차단됩니다.
3. 이벤트 트리거 스레드
- 는 JS 엔진이 아닌 브라우저에 속하며 이벤트 루프를 제어하는 데 사용됩니다(JS 엔진 자체가 너무 바빠서 다른 스레드를 열려면 브라우저가 필요하다는 것은 이해할 수 있습니다). 지원)
- JS 엔진에서 setTimeOut과 같은 코드 블록이 실행될 때(마우스 클릭, Ajax 비동기 요청 등과 같은 브라우저 커널의 다른 스레드에서 올 수도 있음) 해당 작업은 다음과 같습니다. 이벤트 스레드에 추가되었습니다. 그리고 정렬을 담당하게 됩니다
- 해당 이벤트가 트리거 조건을 충족하고 트리거되면 스레드는 JS 엔진의 처리를 기다리면서 처리할 대기열 끝에 이벤트를 추가합니다
- JS의 단일 스레드 관계, 이러한 보류 이벤트 대기열의 모든 이벤트는 JS 엔진의 처리를 기다리기 위해 대기열에 있어야 합니다(JS 엔진이 유휴 상태일 때 실행됩니다)
- 이를 담당한다고 간단히 이해하면 됩니다. 여러 이벤트와 "이벤트 큐"를 관리합니다. 이벤트 큐에 있는 작업만 JS 엔진은 유휴 상태일 때 실행되며, 이벤트가 트리거될 때 이를 이벤트 큐에 추가해야 합니다. 예를 들어 마우스 클릭.
4. 타이밍 트리거 스레드
- 전설적인 setInterval 및 setTimeout이 있는 스레드
- 브라우저 타이밍 카운터는 JavaScript 엔진에 의해 계산되지 않습니다(자바스크립트 엔진이 차단된 경우 단일 스레드이기 때문입니다). 스레드 상태는 타이밍의 정확성에 영향을 미칩니다.
- 따라서 타이밍을 측정하고 트리거하는 데 별도의 스레드가 사용됩니다. 타이밍이 완료된 후 이벤트 큐에 추가됩니다("이벤트가 충족될 때"에 해당). 이벤트 트리거 스레드의 조건을 트리거하고 트리거됨) JS 엔진이 유휴 상태가 될 때까지 기다립니다. 구현합니다.
- W3C에서는 HTML 표준에 setTimeout에서 4ms 미만의 시간 간격이 4ms로 계산되도록 규정하고 있습니다.
5. 비동기 http 요청 스레드
- XMLHttpRequest에서는 연결 후 브라우저를 통해 새 스레드 요청이 열립니다.
- 상태 변경이 감지되면 콜백 함수가 설정되면 비동기 스레드가 상태를 생성합니다. 이벤트를 변경하면 이 콜백이 이벤트 큐에 배치됩니다. 그런 다음 JavaScript 엔진에 의해 실행됩니다.
브라우저 프로세스와 브라우저 커널(렌더러 프로세스) 간의 통신 프로세스
이를 보려면 우선 브라우저의 프로세스와 스레드에 대해 어느 정도 이해해야 합니다. 그런 다음 브라우저의 브라우저에 대해 이야기해 보겠습니다. 프로세스(제어 프로세스)가 커널과 어떻게 통신하는지 이해하면 이 부분의 지식을 하나로 연결하여 처음부터 끝까지 완전한 개념을 가질 수 있습니다.
작업 관리자를 열고 브라우저를 열면 작업 관리자에 두 개의 프로세스가 나타나는 것을 볼 수 있습니다(하나는 기본 제어 프로세스이고 다른 하나는 탭 페이지를 여는 렌더링 프로세스입니다). 전제로 전체 프로세스를 살펴보겠습니다. (많이 단순화되었습니다.)
- 브라우저 프로세스가 사용자 요청을 받으면 먼저 페이지 콘텐츠를 가져와야 합니다(예: 네트워크를 통해 리소스 다운로드). RendererHost 인터페이스를 통해 Renderer(커널)에 작업을 전달합니다.
- Renderer는 메시지를 수신하여 간략하게 설명하고 렌더링 스레드에 전달한 다음 렌더링을 시작합니다.
- 렌더링 스레드는 요청하고 웹 페이지를 로드하고 웹 페이지를 렌더링합니다. 이를 위해서는 리소스를 얻기 위한 브라우저 프로세스와 렌더링을 돕기 위한 GPU 프로세스가 필요할 수 있습니다
- 물론 DOM을 작동하기 위한 JS 스레드가 있을 수 있습니다(이로 인해 리플로우 및 다시 그리기가 발생할 수 있음)
- 마지막으로 렌더링 프로세스는 결과를 브라우저 프로세스에 전달합니다
- 브라우저 프로세스는 결과를 수신하고 결과를 그립니다.
다음은 간단한 그림입니다. (매우 단순화됨) 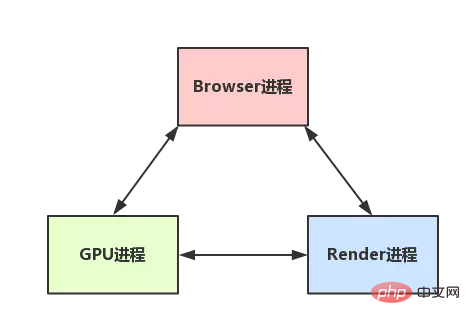
스레드 간의 관계 in the browser kernel
이제 우리는 브라우저의 동작에 대한 전반적인 개념을 갖게 되었습니다. 다음으로, 먼저 몇 가지 개념을 간단히 정리해 보겠습니다
GUI 렌더링 스레드와 JS 엔진 스레드는 상호 배타적입니다
JavaScript는 DOM을 조작할 수 있으므로 인터페이스를 렌더링하는 동안 이러한 요소의 속성을 수정하면(즉, JS 스레드와 UI 스레드가 동시에 실행됩니다) ), 렌더링 스레드 전후에 얻은 요소 데이터가 일치하지 않을 수 있습니다.
따라서 예상치 못한 렌더링 결과를 방지하기 위해 브라우저는 GUI 렌더링 스레드와 JS 엔진이 상호 배타적인 관계를 갖도록 설정합니다. JS 엔진이 실행되면 GUI 스레드가 일시 중지되고 GUI 업데이트가 다음에 저장됩니다. JS 엔진 스레드가 유휴 상태일 때 즉시 실행될 때까지의 대기열입니다.
JS는 페이지 로딩을 차단합니다
위의 상호 배타적 관계에서 JS는 페이지 실행 시간이 너무 오래 걸리면 페이지를 차단할 것이라고 추론할 수 있습니다.
예를 들어 JS 엔진이 엄청난 양의 계산을 수행한다고 가정하면 이때 GUI가 업데이트되더라도 JS 엔진이 유휴 상태일 때 대기열에 저장되어 실행을 기다립니다. 그러면 엄청난 양의 계산으로 인해 JS 엔진이 오랫동안 유휴 상태가 될 가능성이 높으며 당연히 엄청나게 거대하게 느껴질 것입니다.
그러므로 JS 실행이 너무 오래 걸리면 페이지 렌더링이 일관되지 않아 페이지 렌더링 및 로딩이 차단되는 느낌을 받게 되므로 피하십시오.
이 문제를 해결하려면 백엔드에 계산을 배치하는 것 외에도 피할 수 없고 엄청난 계산이 UI와 관련되어 있다면 내 생각은 setTimeout을 사용하여 작업을 나누고 작업에 약간의 자유 시간을 주는 것입니다. JS 엔진의 중간 부분은 페이지가 직접 막히지 않도록 UI를 처리하고 처리합니다.
최소 필수 HTML5+ 버전을 직접 결정했다면 아래 WebWorker를 살펴보세요.
WebWorker, JS의 멀티스레딩
이전 글에서 언급했듯이 JS 엔진은 싱글스레드이므로 JS 실행 시간이 너무 길면 페이지를 차단하게 됩니다. 그렇다면 JS는 정말 무력한 것일까요? CPU 집약적인 계산에 반대합니까?
그래서 Web Workers는 나중에 HTML5에서 지원되었습니다.
MDN의 공식 설명은 다음과 같습니다.
Web Worker는 웹 콘텐츠의 백그라운드 스레드에서 스크립트를 실행하는 간단한 방법을 제공합니다.
스레드는 사용자 인터페이스를 방해하지 않고 작업을 수행할 수 있습니다. 작업자는 명명된 JavaScript 파일(이 파일에는 작업자 스레드에서 실행될 코드가 포함되어 있음)을 실행하는 생성자(Worker())를 사용하여 생성된 개체입니다.
작업자는 현재 창과 다른 또 다른 전역 컨텍스트에서 실행됩니다.
따라서 (self 대신) 창 단축키를 사용하여 현재 전역 범위를 얻으면 Worker 내에서 오류가 반환됩니다.
다음과 같이 이해하십시오:
Worker를 생성할 때 JS 엔진은 브라우저에 적용되어 자식 스레드(자식 스레드 브라우저에 의해 열리고 메인 스레드에 의해 완전히 제어되며 DOM을 작동할 수 없음)
JS 엔진 스레드와 작업자 스레드는 특정 방식으로 통신합니다(상호작용하려면 직렬화 객체가 필요한 postMessage API). 특정 데이터에 대한 스레드)
따라서 시간이 많이 걸리는 작업이 있는 경우 별도의 Worker 스레드를 열어서 아무리 지쳐도 JS 엔진 메인 스레드에 영향을 미치지 않도록 기다리십시오. 결과를 계산하고 그 결과를 메인 스레드에 전달합니다.
그리고 JS 엔진은 단일 스레드이며 작업자는 브라우저에서 열리는 플러그인으로 이해될 수 있습니다. 특히 대규모 컴퓨팅 문제를 해결하는 데 사용되는 JS 엔진용입니다.
기타, Worker에 대한 자세한 설명은 이 글의 범위를 벗어나므로 자세한 내용은 다루지 않겠습니다.
WebWorker 및 SharedWorker
이제 SharedWorker에 대해 다시 언급하겠습니다(나중에 이 두 개념의 혼동을 피하기 위해)
WebWorker는 특정 페이지에만 속하며 다른 페이지의 렌더링 프로세스(브라우저)와 상호 작용하지 않습니다. 페이지 커널 프로세스) 공유
따라서 Chrome은 작업자에서 JavaScript 프로그램을 실행하기 위해 렌더링 프로세스(각 탭 페이지는 렌더링 프로세스임)에 새 스레드를 생성합니다.
SharedWorker는 브라우저의 모든 페이지에서 공유되며, Render 프로세스와 연관되지 않고 여러 Render 프로세스에서 공유될 수 있기 때문에 Worker와 동일한 방식으로 구현할 수 없습니다.
따라서 Chrome 브라우저는 SharedWorker에 대해 별도의 프로세스를 생성하여 JavaScript 프로그램의 경우 생성 횟수에 관계없이 브라우저의 동일한 각 JavaScript에 대해 하나의 SharedWorker 프로세스만 있습니다.
이것을 보고 나면 본질적으로 프로세스와 스레드의 차이점을 쉽게 이해할 수 있을 것입니다. SharedWorker는 독립적인 프로세스에 의해 관리되며 WebWorker는 Render 프로세스 아래의 스레드일 뿐입니다.
브라우저 렌더링 프로세스
보조 브라우저 렌더링 프로세스(간단한 버전)
이해를 단순화하기 위해 다음과 같이 예비 작업을 직접 생략합니다.
브라우저가 URL을 입력하면 브라우저 기본 프로세스가 대신하여 다운로드를 엽니다. 그런 다음 http 요청(DNS 쿼리, IP 주소 지정 등 생략)을 한 다음 응답을 기다리고 콘텐츠를 얻은 다음 RendererHost 인터페이스를 통해 콘텐츠를 렌더러 프로세스로 전송합니다
브라우저 렌더링 프로세스가 시작됩니다
브라우저 커널이 콘텐츠를 가져온 후 렌더링은 대략 다음 단계로 나눌 수 있습니다.
HTML 구문 분석 및 DOM 트리 구축
CSS 구문 분석 및 렌더 트리 구축(CSS 코드를 트리 모양의 데이터 구조로 구문 분석한 다음 DOM과 결합하여 렌더 트리로 병합)
계산을 담당하는 레이아웃 렌더 트리(레이아웃/리플로우) 각 요소의 크기와 위치
렌더 트리(페인트) 그리기 및 페이지 픽셀 정보 그리기
브라우저는 각 레이어의 정보를 GPU로 보내고, GPU는 각 레이어를 합성하여 화면에 표시합니다.
모든 세부 단계는 생략되었습니다. 렌더링이 완료된 후 로드 이벤트이고 그 다음은 자체 JS 로직 처리입니다.
일부 세부 단계가 생략되었기 때문에 주의가 필요할 수 있는 몇 가지 세부 사항을 언급하겠습니다. 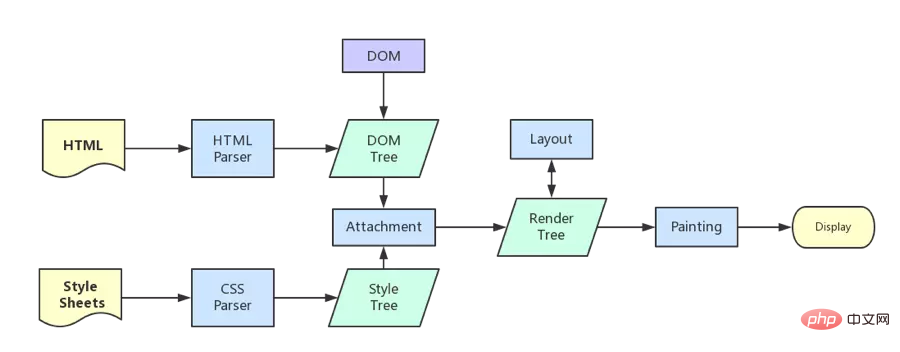
로드 이벤트와 DOMContentLoaded 이벤트의 순서
위에서 언급한 것처럼 로드 이벤트는 렌더링이 완료된 후에 발생하는데, 로드 이벤트와 DOMContentLoaded 이벤트의 순서를 구별할 수 있나요?
매우 간단합니다. 정의만 알아두세요.
DOMContentLoaded 이벤트가 트리거되면 DOM이 로드될 때만 스타일 시트, 이미지, 비동기 스크립트 등은 제외됩니다.
onload 이벤트가 트리거되면 페이지의 모든 DOM, 스타일 시트, 스크립트 및 이미지가 로드되었습니다. 즉, 순서는 다음과 같습니다. DOMContentLoaded -> CSS 로딩 블록입니다. dom 트리? 렌더링
css 로딩은 DOM 트리 구문 분석을 차단하지 않습니다(DOM은 비동기 로딩 중에 평소와 같이 구성됩니다).
- 그러나 렌더링 트리 렌더링은 차단합니다(CSS가 로드될 때까지 기다려야 함). 렌더링할 때 렌더링 트리에 CSS 정보가 필요하기 때문입니다.)
- 이는 브라우저의 최적화 메커니즘일 수도 있습니다. CSS를 로드할 때 아래 DOM 노드의 스타일을 수정할 수 있기 때문에 CSS 로딩이 렌더 트리 렌더링을 차단하지 않으면 CSS가 로드된 후 렌더 트리를 다시 그리거나 리플로우해야 할 수 있습니다. 일부 문제가 발생합니다. 필요한 손실이 없습니다.
불투명 속성/전환 애니메이션(합성 레이어는 애니메이션 실행 중에만 생성되며 요소는 애니메이션이 시작되지 않았거나 종료된 후에 이전 상태로 돌아갑니다.
will-chang 속성(상대적으로 원격임), 일반적으로 불투명도 및 변환과 함께 사용되는 기능은 브라우저에 변경 사항을 미리 알려주는 것입니다. 브라우저가 일부 최적화 작업을 시작하도록 만들어집니다(사용 후 이를 릴리스하는 것이 가장 좋습니다) 비디오, iframe, 캔버스, webgl 등과 같은 요소
이전 플래시 플러그와 같은 기타- in
절대 가속과 하드웨어 가속의 차이점
절대 가속은 일반적인 문서 흐름에서는 분리할 수 있지만 기본 복합 레이어에서는 분리할 수 없다는 것을 알 수 있습니다. 따라서 절대값의 정보가 변경되더라도 일반적인 문서 흐름에서는 렌더 트리가 변경되지 않습니다. 그러나 브라우저가 최종적으로 그릴 때 전체 합성 레이어가 그려지므로 절대값의 정보 변경은 여전히 드로잉에 영향을 미칩니다. 전체 복합층의 모습입니다. (브라우저가 다시 그리게 됩니다. 합성 레이어에 내용이 많으면 절대값이 가져온 그리기 정보가 너무 많이 바뀌게 되어 리소스 소모가 매우 심해집니다.)
복합 레이어의 역할
일반적으로 하드웨어 가속을 켜면 요소가 복합 레이어가 되어 일반 문서 흐름에서 독립될 수 있으며, 수정 후에는 전체 페이지를 다시 그리는 것을 방지하고 성능을 향상시킬 수 있습니다. 복합 레이어를 대량으로 사용하지 마세요. 그렇지 않으면 과도한 리소스 소모로 인해 페이지가 느려질 수 있습니다
하드웨어 가속을 사용할 때는 인덱스를 사용하세요
하드웨어 가속을 사용할 때는 브라우저가 느려지는 것을 방지하기 위해 인덱스를 최대한 사용하세요. 기본적으로 후속 요소에 대한 복합 레이어 렌더링 생성
Specific 원칙은 다음과 같습니다. 웹킷 CSS3에서 이 요소에 하드웨어 가속이 추가되고 인덱스 수준이 상대적으로 낮으면 이 요소 뒤에 있는 다른 요소(이 요소보다 높은 수준, 또는 동일하고 동일한 상대 또는 절대 속성을 가짐) 기본적으로 복합 레이어 렌더링이 됩니다. 제대로 처리되지 않으면 간단히 이해하면 실제로는 성능에 큰 영향을 미칩니다. 암시적 합성 개념: a가 복합 레이어이고 b가 a 위에 있는 경우 b도 암시적으로 복합 레이어로 변환되므로 특별한 주의가 필요합니다.
EventLoop에서 JS의 작동 메커니즘에 대해 이야기해 보세요지금까지는 이미 브라우저 페이지의 초기 렌더링 이후 JS 엔진의 작동 메커니즘에 대한 일부 분석이 이루어졌습니다.
실행 가능한 컨텍스트, VO, scop 체인 등과 같은 개념에 대해서는 다루지 않습니다. (이들은 다른 기사로 정리할 수 있습니다.) 여기서는 JS 코드가 Event Loop와 함께 실행되는 방법에 대해 주로 설명합니다.
이 부분을 읽기 위한 전제 조건은 JS 엔진이 단일 스레드라는 것을 이미 알고 있다는 것이며 위에서 언급한 여러 개념이 여기에서 사용됩니다:
JS 엔진 스레드- 이벤트 트리거 스레드
- Timed 트리거 스레드 그런 다음 개념 이해:
- 메인 스레드 외부에서는 이벤트 트리거 스레드가 작업 대기열을 관리합니다. 비동기 작업에는 실행 결과를 알려면 작업 대기열에 이벤트를 배치합니다.
- 실행 스택의 모든 동기 작업이 실행되면(이 시점에서 JS 엔진은 유휴 상태임) 시스템은 작업 대기열을 읽고 실행 가능한 비동기 작업을 실행 가능 스택에 추가한 후 실행을 시작합니다.
- 그림을 보세요:
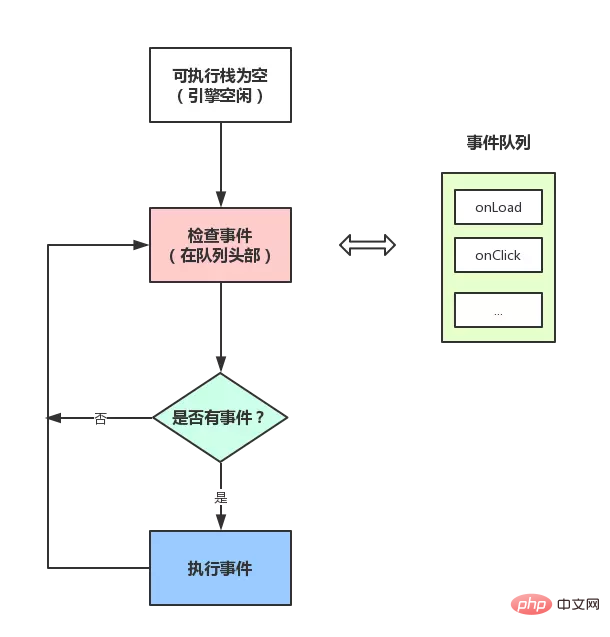 이것을 보면 이해할 수 있을 것입니다. setTimeout에 의해 푸시된 이벤트가 때때로 제 시간에 실행되지 않는 이유는 무엇입니까? 메인 스레드가 아직 유휴 상태가 아닐 수 있고 이벤트 목록에 푸시될 때 다른 코드를 실행하고 있기 때문에 자연스럽게 오류가 발생하게 됩니다.
이것을 보면 이해할 수 있을 것입니다. setTimeout에 의해 푸시된 이벤트가 때때로 제 시간에 실행되지 않는 이유는 무엇입니까? 메인 스레드가 아직 유휴 상태가 아닐 수 있고 이벤트 목록에 푸시될 때 다른 코드를 실행하고 있기 때문에 자연스럽게 오류가 발생하게 됩니다.
이벤트 루프 메커니즘이 추가로 보완되었습니다.
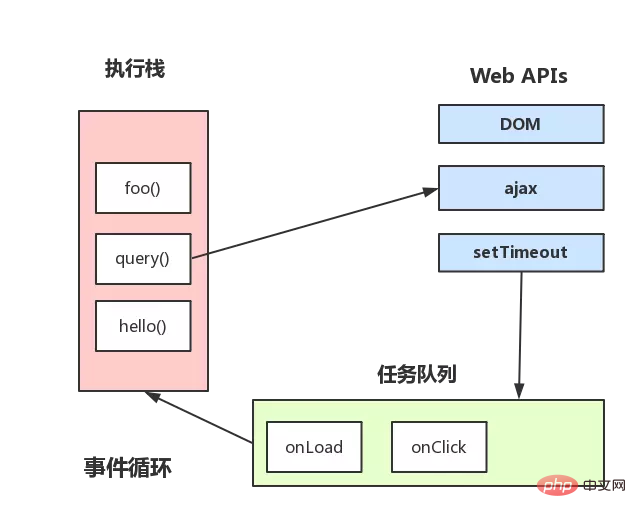 위 그림은 대략적으로 설명합니다.
위 그림은 대략적으로 설명합니다.
- 스택의 코드가 실행된 후 이벤트 큐의 이벤트를 읽어 해당 콜백을 실행하는 등의 작업이 진행됩니다
- 항상 스택을 기다려야 한다는 점에 유의하세요. 이벤트 큐의 이벤트는 코드가 실행된 후에만 읽혀집니다.
타이머에 대해서는 별도로 이야기합시다
위 이벤트 루프 메커니즘의 핵심은 JS 엔진 스레드입니다. 그리고 이벤트 트리거 스레드
하지만 이벤트 세부정보에는 setTimeout을 호출한 후 이벤트 큐에 추가하기 전에 특정 시간을 기다리는 방법과 같은 숨겨진 내용이 있습니다.
JS 엔진에서 감지되나요? 물론 그렇지 않습니다. 타이머 스레드에 의해 제어됩니다(JS 엔진 자체가 너무 바빠서 다른 작업을 수행할 시간이 없기 때문입니다)
별도의 타이머 스레드가 필요한 이유는 무엇입니까? 자바스크립트 엔진은 싱글 스레드이기 때문에 블록 스레드 상태가 되면 타이밍 정확도에 영향을 미치므로 타이밍을 위해 별도의 스레드를 열어야 한다.
타이머 스레드는 언제 사용되나요? setTimeout 또는 setInterval을 사용하는 경우 타이머 스레드가 시간을 맞춰야 하며, 시간이 완료된 후 특정 이벤트가 이벤트 큐에 푸시됩니다.
setInterval 대신 setTimeout
setTimeout을 사용하여 정기적인 타이밍을 시뮬레이션하는 것과 setInterval을 직접 사용하는 것에는 차이가 있습니다.
setTimeout이 실행될 때마다 실행되기 때문에 일정 기간이 지나면 계속 setTimeout이 발생하기 때문에 중간에 오류가 발생합니다(오류는 코드 실행 시간과 관련됨)
그리고 setInterval은 일정 시간 동안 이벤트가 푸시되지만 실제 이벤트 실행 시간은 이벤트가 완료되기 전에 정확하지 않을 수도 있습니다.
그리고 setInterval에는 몇 가지 치명적인 문제가 있습니다.
누적 효과, setInterval 코드가 대기열에 다시 추가되기 전에 실행이 완료되지 않은 경우 타이머 코드가 간격 없이 연속적으로 여러 번 실행됩니다. 일반적인 간격으로 실행되더라도 여러 setInterval 코드의 실행 시간이 예상보다 짧아질 수 있습니다(코드 실행에 일정 시간이 걸리기 때문). 예를 들어 iOS webview나 Safari와 같은 브라우저에는 그렇지 않은 기능이 있습니다. JS의 경우 setInterval을 사용하면 스크롤이 완료된 후 여러 번 실행되는 것을 볼 수 있습니다. 스크롤은 JS 누적 콜백을 실행하지 않기 때문에 콜백 실행 시간이 너무 길면 컨테이너에 문제가 발생하고 알 수 없는 오류가 발생합니다(이 섹션에서는 setInterval에 자체 최적화가 있고 콜백을 반복적으로 추가하지 않는다는 점을 나중에 추가할 예정입니다)
그리고 브라우저가 최소화되어 표시되면 setInterval은 프로그램을 실행하지 않습니다. setInterval의 콜백 함수를 대기열에 넣고 브라우저를 기다리며 창이 다시 열리면 모든 것이 즉시 실행됩니다
그래서 너무 많은 문제를 고려하여 현재 가장 좋은 해결책은 일반적으로 다음과 같이 간주됩니다. setTimeout을 사용하여 setInterval을 시뮬레이션하거나 특별한 경우 requestAnimationFrame을 직접 사용하세요
고급 이벤트 루프: 매크로태스크 및 마이크로태스크
JS 이벤트 루프 메커니즘은 위에서 정리되었지만 ES5의 경우에는 충분하지만 이제 ES6이 널리 사용되므로 여전히 몇 가지 문제가 발생합니다. 예를 들어, 다음 질문:console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
Promise.resolve().then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
console.log('script end');흠, 올바른 실행 순서는 다음과 같습니다:
script start script end promise1 promise2 setTimeoutWhy? Promise에는 microtask라는 새로운 개념이 있기 때문입니다. 게다가 JS는 매크로태스크와 마이크로태스크라는 두 가지 작업 유형으로 나뉩니다. ECMAScript에서는 마이크로태스크를 작업이라고 하고, 매크로태스크를 작업이라고 할 수도 있습니다. 그들의 정의는 무엇인가요? 차이점은 무엇입니까? 간단히 말하면 다음과 같이 이해하면 됩니다. 1. 매크로 태스크(매크로 태스크라고도 함) 실행 스택에 의해 실행되는 코드는 매번(이벤트 콜백이 발생할 때마다 포함) 매크로 태스크라고 이해하면 됩니다.
- 각 작업은 이 작업을 처음부터 끝까지 실행하고 다른 작업은 실행하지 않습니다.
- JS 내부 작업 및 DOM 작업이 실행될 수 있도록 하기 위해 순서대로 브라우저는 하나의 작업으로 실행합니다. 종료 후 다음 작업 실행이 시작되기 전에 페이지를 다시 렌더링합니다(작업 -> 렌더링 -> 작업 -> ...)
- 즉, 현재 태스크 후, 다음 태스크 전, 렌더링 전
- 그래서 응답 속도는 setTimeout(setTimeout은 작업)보다 빠릅니다. 렌더링을 기다릴 필요가 없기 때문입니다
- 즉, 특정 매크로 작업이 실행된 후 해당 실행 중에 생성된 모든 마이크로 작업이 실행됩니다(렌더링 전).
- macrotask: 기본 코드 블록, setTimeout, setInterval 등(이벤트 큐의 각 이벤트는 매크로태스크입니다)
- microtask: 약속, 프로세스. nextTick 등
그래서 , 작동 메커니즘을 요약하면 다음과 같습니다.
- 매크로 작업을 실행합니다(스택에 없으면 이벤트 큐에서 가져옵니다)
- 실행 중에 마이크로 태스크가 발견되면 마이크로 태스크의 태스크 큐에 추가합니다
- 매크로 작업이 실행된 후 현재 마이크로태스크 대기열의 모든 마이크로태스크가 즉시 실행됩니다(순차적으로 실행됨)
- 현재 매크로 작업이 실행된 후 렌더링 확인이 시작되고 GUI 스레드가 렌더링을 인수합니다
- 렌더링이 완료된 후에도 JS 스레드가 계속 이어받아 다음 A 매크로 작업(이벤트 대기열에서 가져옴)을 시작합니다.
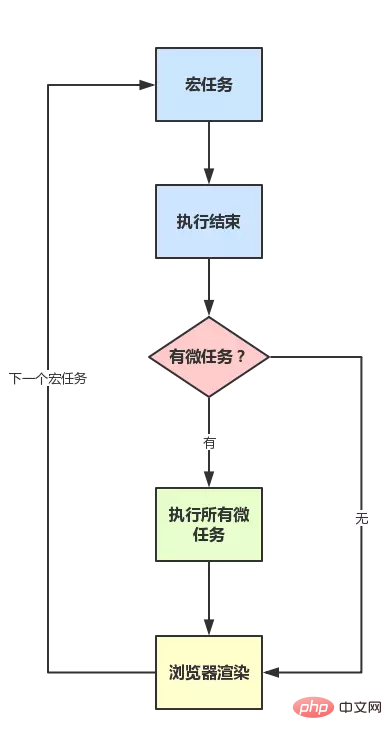
폴리필은 일반적으로 setTimeout을 통해 시뮬레이션되므로 매크로태스크 형식입니다.
일부 브라우저에서는 실행 결과가 다릅니다(왜냐하면 마이크로태스크를 매크로태스크처럼 실행할 수도 있지만 단순화를 위해 일부 비표준 브라우저에서의 시나리오는 여기서 설명하지 않습니다. (하지만 일부 브라우저는 표준이 아닐 수도 있다는 점을 기억하세요)
补充:使用MutationObserver实现microtask
MutationObserver可以用来实现microtask (它属于microtask,优先级小于Promise, 一般是Promise不支持时才会这样做)
它是HTML5中的新特性,作用是:监听一个DOM变动, 当DOM对象树发生任何变动时,Mutation Observer会得到通知
像以前的Vue源码中就是利用它来模拟nextTick的, 具体原理是,创建一个TextNode并监听内容变化, 然后要nextTick的时候去改一下这个节点的文本内容, 如下:
var counter = 1
var observer = new MutationObserver(nextTickHandler)
var textNode = document.createTextNode(String(counter))
observer.observe(textNode, {
characterData: true
})
timerFunc = () => {
counter = (counter + 1) % 2
textNode.data = String(counter)
}
不过,现在的Vue(2.5+)的nextTick实现移除了MutationObserver的方式(据说是兼容性原因), 取而代之的是使用MessageChannel (当然,默认情况仍然是Promise,不支持才兼容的)。
MessageChannel属于宏任务,优先级是:MessageChannel->setTimeout, 所以Vue(2.5+)内部的nextTick与2.4及之前的实现是不一样的,需要注意下。
【相关推荐:javascript视频教程、web前端】
위 내용은 JavaScript의 작동 메커니즘과 원리를 완전히 마스터하세요.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!