
ホームページ >テクノロジー周辺機器 >AI >Google AIビデオがまたすごい!オールインワンのユニバーサル ビジュアル エンコーダーである VideoPrism が 30 の SOTA パフォーマンス機能を更新
Google AIビデオがまたすごい!オールインワンのユニバーサル ビジュアル エンコーダーである VideoPrism が 30 の SOTA パフォーマンス機能を更新

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-02-26 09:58:241341ブラウズ
AI ビデオ モデル Sora が人気を博した後、Meta や Google などの大手企業は研究を行って OpenAI に追いつくために手を引いています。
最近、Google チームの研究者は、ユニバーサル ビデオ エンコーダ VideoPrism を提案しました。
単一のフリーズされたモデルを通じて、さまざまなビデオ理解タスクを処理できます。
 写真
写真
論文アドレス: https://arxiv.org/pdf/2402.13217.pdf
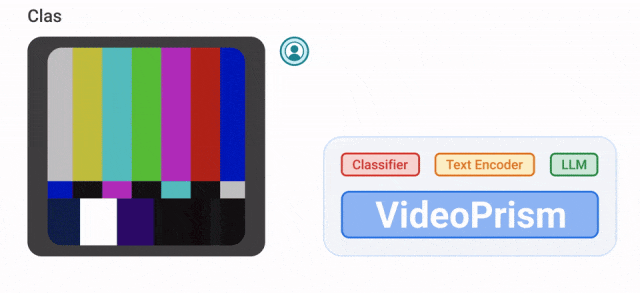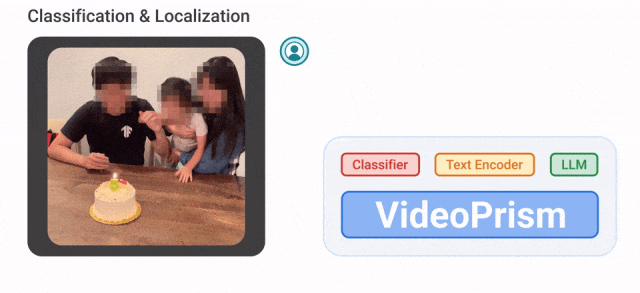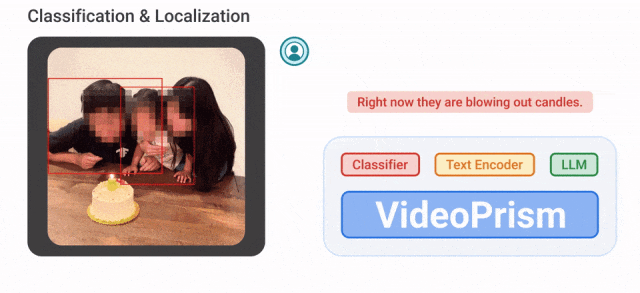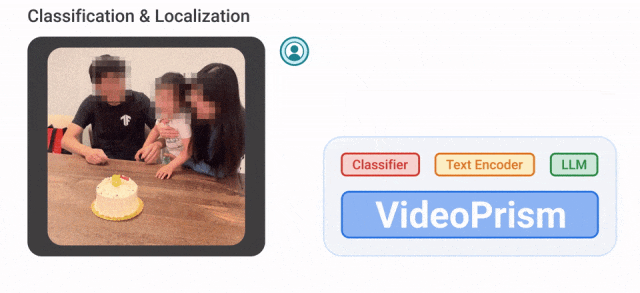
たとえば、VideoPrism は次のように変換できます。以下のビデオ内でろうそくを吹き飛ばしている人々が分類され、位置が特定されています。
 画像
画像
ビデオテキスト検索では、テキストコンテンツに従って、ビデオ内の対応するコンテンツを取得できます。
 写真
写真
別の例として、下のビデオについて説明します。小さな女の子が積み木で遊んでいます。
QA の質問と回答を行うこともできます。
#--彼女が緑のブロックの上に置いたブロックは何色ですか? ######- 紫。 写真 研究者らは、3,600 万の高品質ビデオ字幕ペアと 5 億 8,200 万のビデオ クリップを含む異種コーパスで VideoPrism を事前トレーニングしました。ノイズの多い並列テキスト (ASR 転写テキストなど)。
研究者らは、3,600 万の高品質ビデオ字幕ペアと 5 億 8,200 万のビデオ クリップを含む異種コーパスで VideoPrism を事前トレーニングしました。ノイズの多い並列テキスト (ASR 転写テキストなど)。
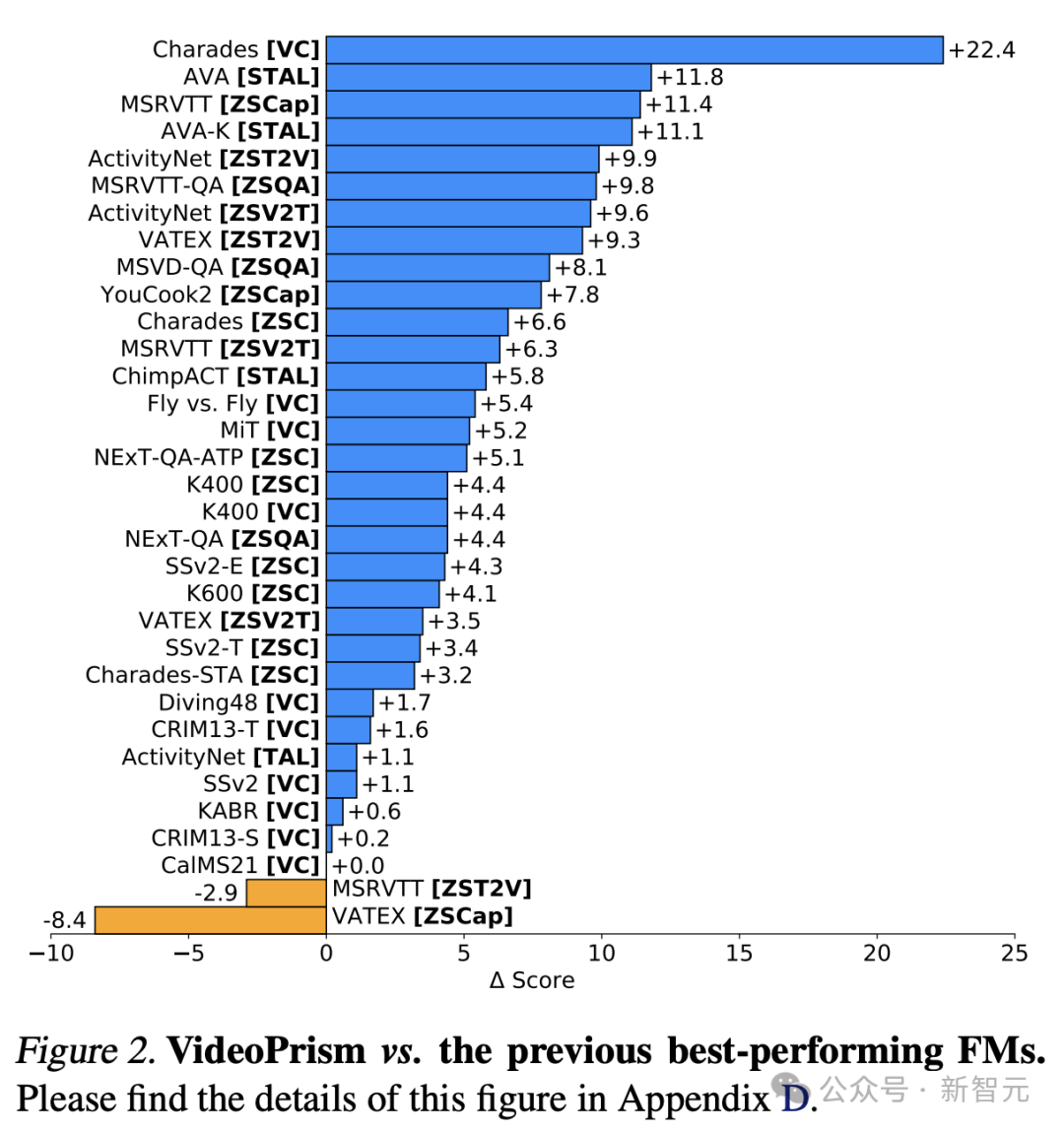 Universal Visual Encoder VideoPrism
Universal Visual Encoder VideoPrism
 設計アーキテクチャ、2 段階のトレーニング方法
設計アーキテクチャ、2 段階のトレーニング方法
 写真
写真
モデリングの観点から、著者はまず、さまざまな品質のすべてのビデオとテキストのペアから意味論的なビデオ埋め込みを比較学習します。
次に、以下で説明するマスクされたビデオ モデリングは、広範囲の純粋なビデオ データを使用したセマンティック埋め込みのグローバルおよびラベルの洗練によって改善されます。
自然言語での成功にもかかわらず、元の視覚信号にはセマンティクスが欠如しているため、マスクされたデータ モデリングは依然として CV にとって課題です。
既存の研究では、間接的なセマンティクス (モデルやトークナイザーをガイドするための CLIP の使用、または暗黙的なセマンティクスなど) を借用するか、それらを暗黙的に一般化する (ビジュアル パッチのラベル付けなど) ことでこの課題に対処しています。軽量デコーダ。
上記の考えに基づいて、Google チームは事前トレーニング データに基づく 2 段階のアプローチを採用しました。
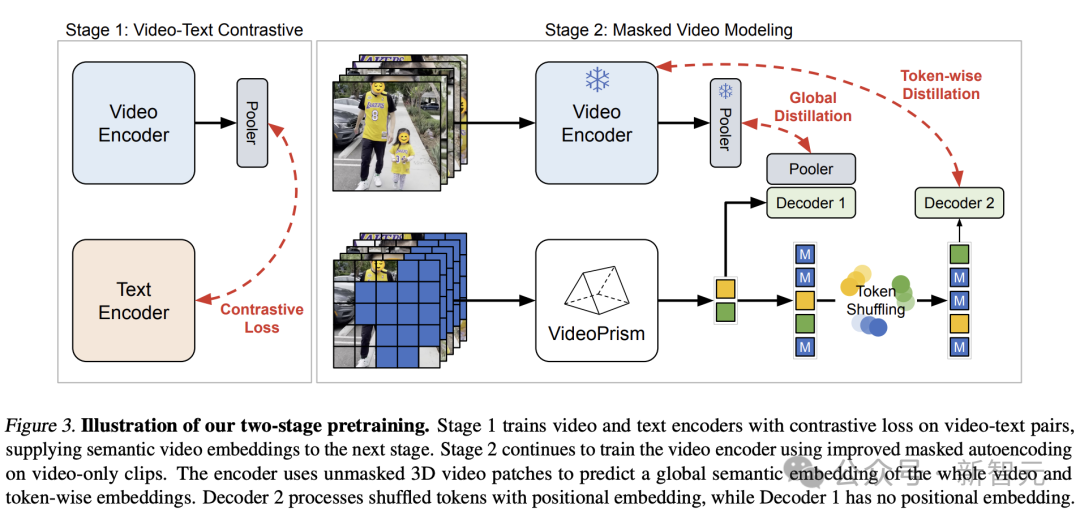 画像
画像
最初の段階では、すべてのビデオとテキストのペアを使用して、ビデオ エンコーダーとテキスト エンコーダーを調整するために対照学習が実行されます。
以前の調査に基づいて、Google チームはバッチ内のすべてのビデオとテキストのペアの類似性スコアを最小化し、対称クロスエントロピー損失の最小化を実行しました。
そして、CoCa の画像モデルを使用して空間コーディング モジュールを初期化し、WebLI を事前トレーニングに組み込みます。
損失を計算する前に、ビデオ エンコーダの機能がマルチヘッド アテンション プーリング (MAP) を通じて集約されます。
この段階では、ビデオ エンコーダーが言語監視から豊富な視覚的セマンティクスを学習できるようになり、結果として得られるモデルは、第 2 段階のトレーニング用のセマンティック ビデオ埋め込みを提供します。
 図
図
第 2 段階では、エンコーダーのトレーニングが継続され、2 つの改善が行われます。
-モデルは次のことを行う必要があります。コードの入力ビデオ パッチは、最初の段階でビデオ レベルのグローバル エンベディングとトークン エンベディングを予測するために使用されます。
- エンコーダーの出力トークンは、エンコーダーに渡される前にランダムにシャッフルされます。デコーダを使用してショートカットの学習を回避します。
注目すべきことに、研究者らの事前トレーニングでは、ビデオのテキストによる説明と状況に応じた自己監視という 2 つの監視信号が活用され、VideoPrism が外観とアクション中心のタスクで適切に実行できるようになりました。
実際、これまでの研究では、ビデオのキャプションは主に外観の手がかりを明らかにし、状況に応じた監視は行動の学習に役立つことが示されています。
 写真
写真
実験結果
次に、研究者らはビデオ中心の理解タスクの幅広い範囲で VideoPrism を評価し、その機能を示しました。そして多用途性。
主に次の 4 つのカテゴリに分類されます。
(1) 一般に、分類と時空間位置決めを含むビデオ理解のみ
(2) ゼロサンプルのビデオ テキスト検索
(3) ゼロサンプルビデオ字幕と品質チェック
(4) 科学における CV タスク
分類と時空間位置特定
表 2 はフリーズを示していますVideoGLUE バックボーンの結果について。
VideoPrism は、すべてのデータセットでベースラインを大幅に上回っています。さらに、VideoPrism の基礎となるモデル サイズを ViT-B から ViT-g に増やすと、パフォーマンスが大幅に向上します。
すべてのベンチマークで 2 番目に良い結果を達成したベースライン手法がないことは注目に値します。これは、以前の手法がビデオ理解の特定の側面を対象として開発された可能性があることを示唆しています。
そして、VideoPrism はこの広範なタスクを改善し続けています。
この結果は、VideoPrism がさまざまなビデオ信号を 1 つのエンコーダーに統合していることを示しています。つまり、複数の粒度でのセマンティクス、外観と動きのキュー、時空間情報、およびさまざまなビデオ ソース (オンライン ビデオやスクリプト化されたパフォーマンスなど) を解釈する機能です。堅牢性。
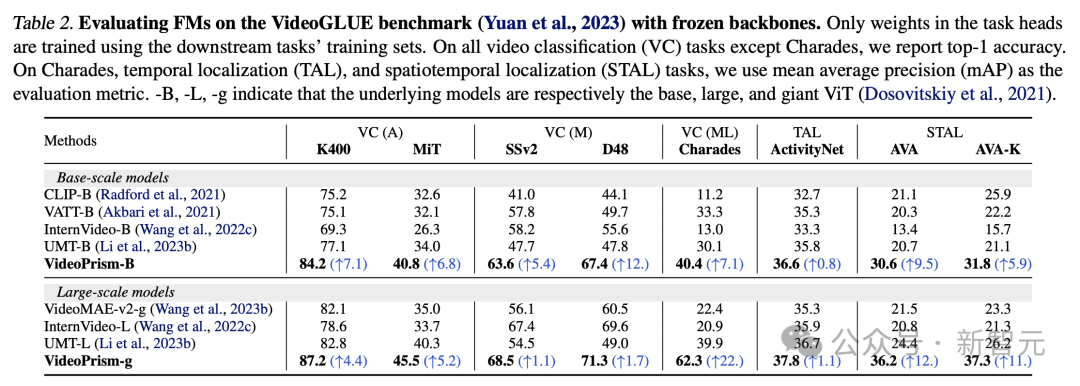 写真
写真
ゼロショット ビデオ テキストの検索と分類
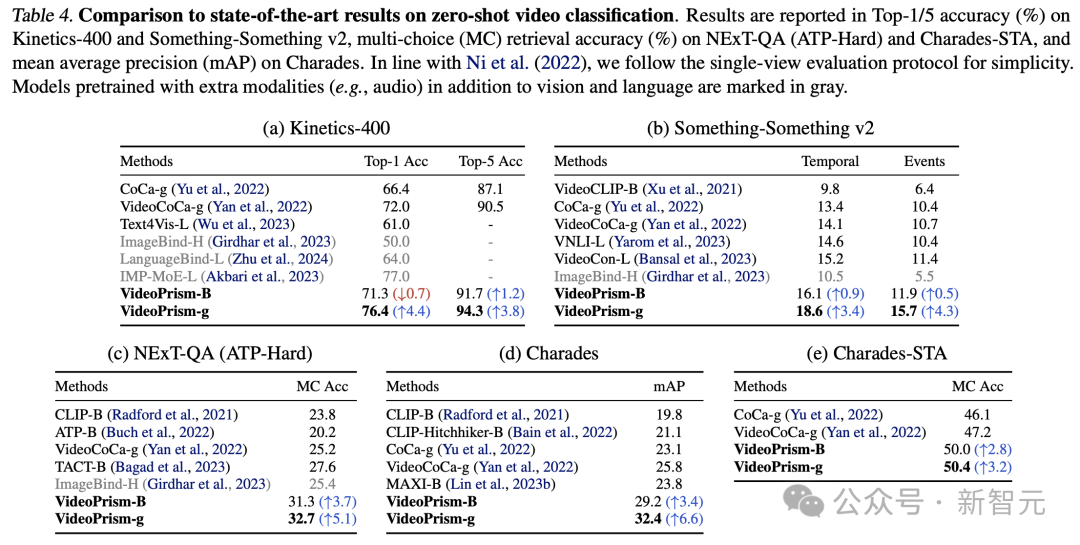
表 3 と 4 は、それぞれビデオ テキストの検索とビデオ分類の結果をまとめたものです。
VideoPrism のパフォーマンスは複数のベンチマークを更新し、困難なデータセットにおいて、VideoPrism は以前のテクノロジーと比較して非常に大幅な改善を達成しました。
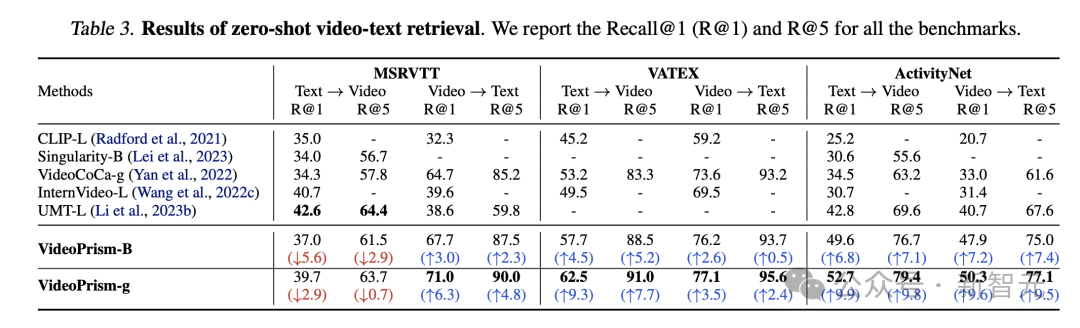 写真
写真
基本モデル VideoPrism-B のほとんどの結果は、実際に既存の大規模モデルよりも優れています。
さらに、VideoPrism は、ドメイン内データと追加のモダリティ (オーディオなど) を使用して事前トレーニングされた表 4 のモデルと同等か、それ以上です。ゼロショット検索および分類タスクにおけるこれらの改善は、VideoPrism の強力な一般化機能を反映しています。
 画像
画像
ゼロサンプルビデオ字幕と品質チェック
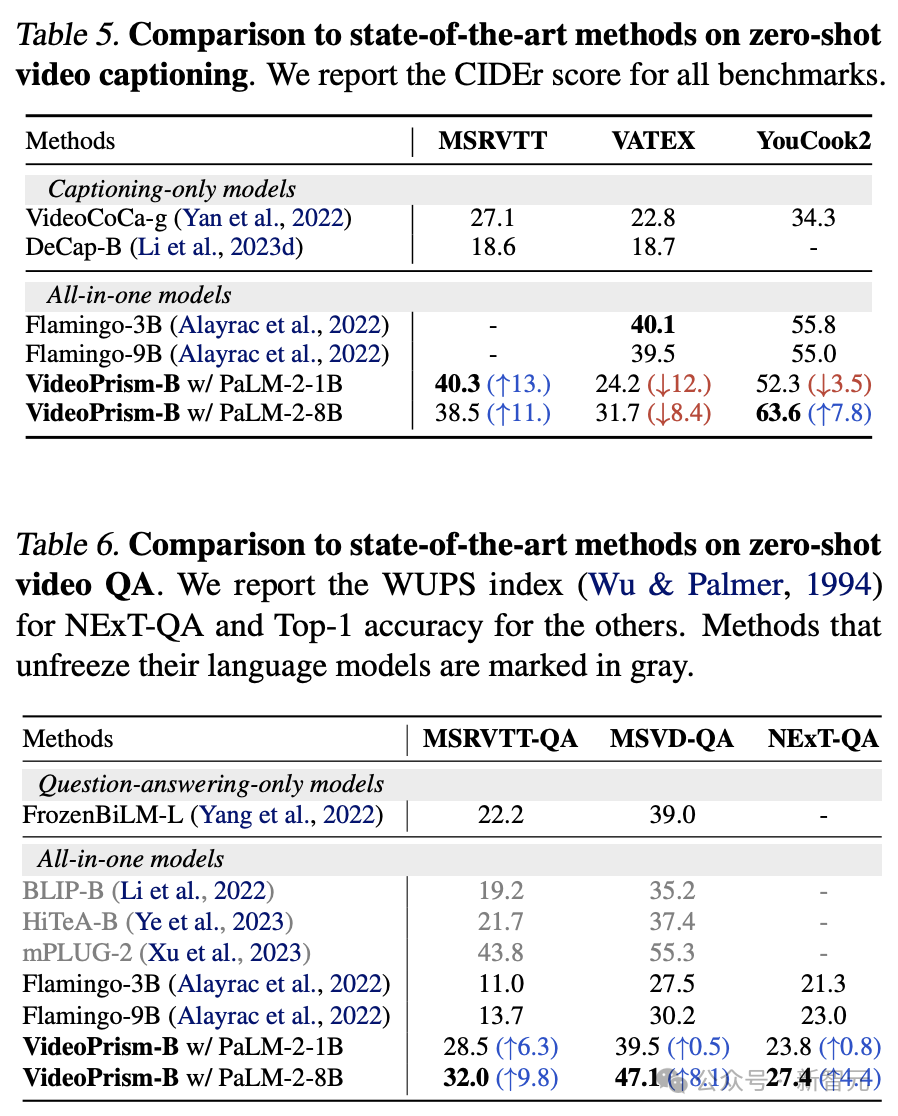
表 5 と表 6 に、それぞれゼロサンプルビデオ字幕を示します。とQAの結果です。
シンプルなモデル アーキテクチャと少数のアダプター パラメーターにもかかわらず、最新のモデルは依然として競争力があり、VATEX を除いて、ビジュアル モデルと言語モデルをフリーズするためのトップ メソッドの 1 つにランクされています。
結果は、VideoPrism エンコーダがビデオから言語への生成タスクにうまく一般化できることを示しています。
 写真
写真
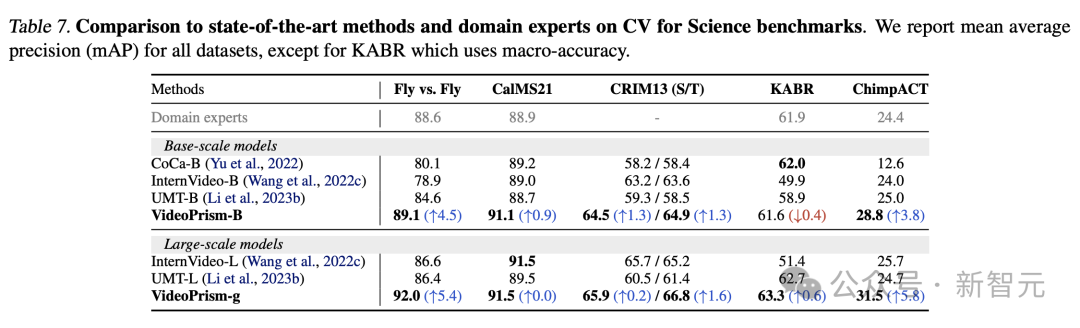
科学における CV タスク
汎用 ViFM は、すべての評価で共有フリーズ エンコーダーを使用しており、そのパフォーマンスは、単一タスクに特化したドメイン固有のモデル。
特に、VideoPrism は最高のパフォーマンスを発揮することが多く、ベース スケール モデルを備えたドメイン エキスパート モデルを上回ります。
大規模モデルにスケーリングすると、すべてのデータセットのパフォーマンスがさらに向上します。これらの結果は、ViFM がさまざまな分野でビデオ分析を大幅に加速する可能性があることを示しています。
アブレーション研究
図 4 はアブレーションの結果を示しています。特に、SSv2 における VideoPrism の継続的な改善は、ビデオにおけるモーションの理解を促進する際のデータ管理とモデル設計の取り組みの有効性を実証しています。
比較ベースラインはすでに K400 で競合する結果を達成していますが、提案されているグローバル蒸留とトークン シャッフルにより精度がさらに向上しました。
 写真
写真
参考:
https://arxiv.org/pdf/2402.13217.pdf
https://blog.research.google/2024/02/videoprism-foundational-visual-encoder.html
以上がGoogle AIビデオがまたすごい!オールインワンのユニバーサル ビジュアル エンコーダーである VideoPrism が 30 の SOTA パフォーマンス機能を更新の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。