
ホームページ >テクノロジー周辺機器 >AI >高性能 LLM 推論フレームワークの設計と実装
高性能 LLM 推論フレームワークの設計と実装

- WBOY転載
- 2024-02-26 09:52:29690ブラウズ

#1. 大規模言語モデル推論の概要
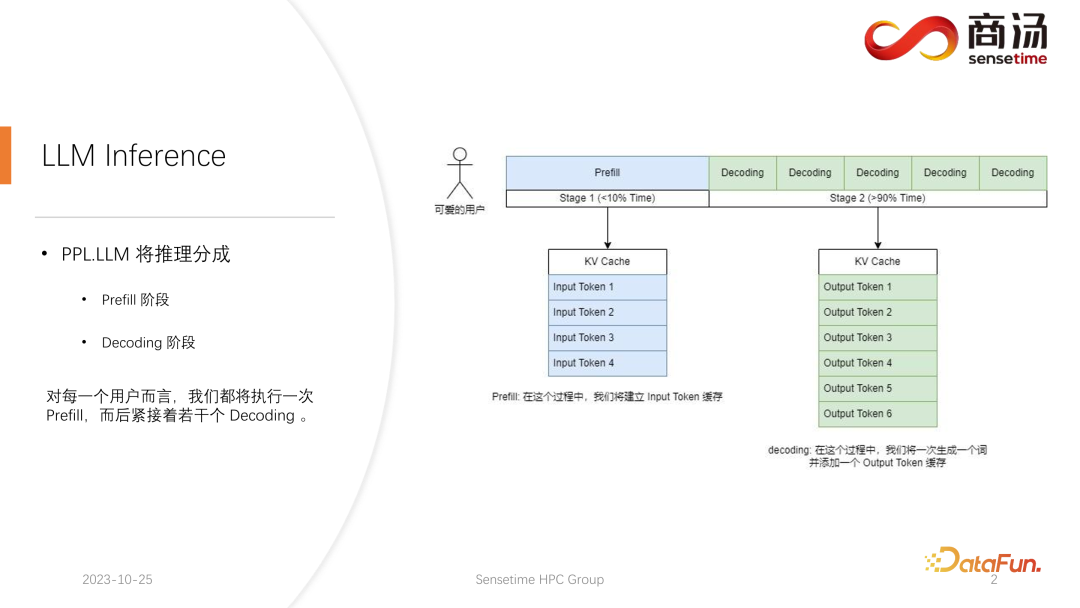
と従来の CNNモデル推論は異なります。大規模な言語モデルの推論は、通常、プリフィルとデコードの 2 つの段階に分かれています。各リクエストが開始された後に生成される推論プロセスは、まずプレフィル プロセスを通過します。プレフィル プロセスはすべてのユーザー入力を計算し、対応する KV キャッシュを生成します。その後、いくつかのデコード プロセスを通過します。デコード プロセスごとに、サーバーはキャラクターを生成し、それを KV キャッシュに置き、順番に繰り返します。
デコード プロセスは文字ごとに生成されるため、各応答フラグメントの生成には時間がかかり、大量の文字が生成されます。したがって、復号段階の数は非常に多く、推論プロセス全体のほとんどを占め、90%を超えます。
プレフィルプロセスでは、ユーザーが入力したすべての単語を同時に計算する必要があるため、多くの計算を処理する必要がありますが、これは 1 回だけですプロセス。したがって、Prefill が占める時間は、推論プロセス全体の 10% 未満にすぎません。
大規模言語モデルの推論では、通常、スループット、最初の単語のレイテンシ、全体のレイテンシ、1 秒あたりのリクエスト数 (QPS) という 4 つの主要なメトリクスに焦点が当てられます。これらのパフォーマンス指標は、システムのサービス機能をさまざまな観点から評価します。スループットは、システムがリクエストをどれだけ迅速かつ効率的に処理するかを測定します。一方、ファーストワード レイテンシは、システムが最初のトークンを生成するのにかかる時間を指します。全体的な待ち時間は、システムが推論タスク全体を完了するのにかかる時間です。最後に、QPS は、システムが 1 秒あたりに処理するリクエストの数を表します。これらのメトリックは、モデルのパフォーマンスとシステムの最適化を評価する際に重要な役割を果たし、システムがさまざまな推論タスクを効率的に処理できるようにするのに役立ちます。
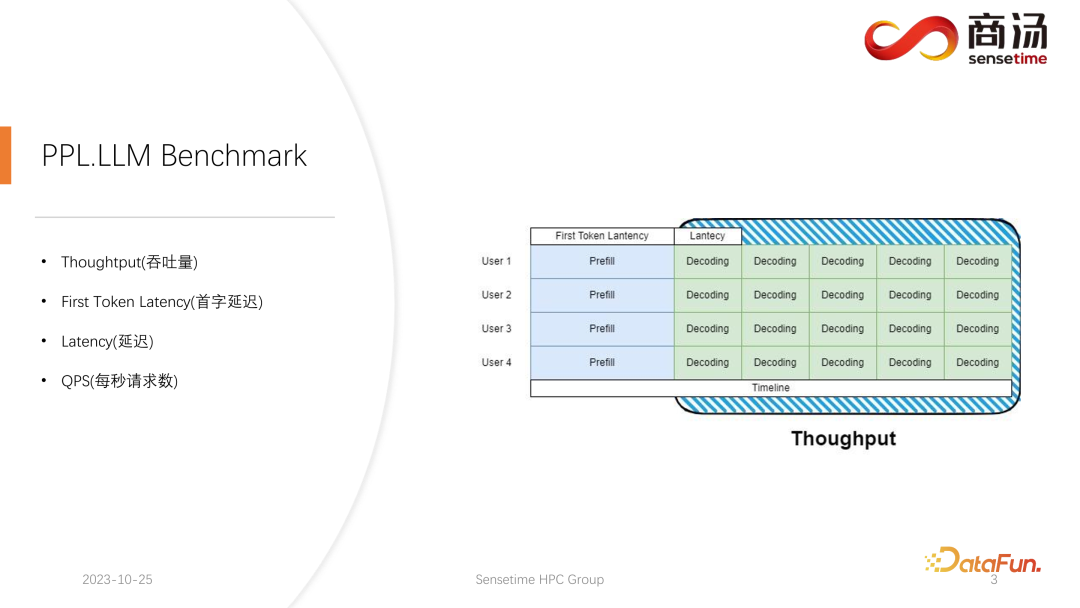
まず、スループットについて紹介します。モデル推論レベルから見て、最初に注目すべきことはスループットです。スループットとは、システム負荷が最大に達したときに、単位時間あたりに何回デコードできるか、つまり文字が何個生成されるかを指します。スループットをテストする方法は、すべてのユーザーが同時に到着し、これらのユーザーが同じ質問をすること、これらのユーザーが同時に開始および終了できること、生成されるテキストの長さとテキストの長さを想定することです。入力テキストは同じです。完全なバッチは、まったく同じ入力を使用して形成されます。この場合、システムのスループットは最大化されます。しかし、この状況は非現実的であるため、これは理論上の最大値です。システムが 1 秒間に実行できる独立したデコード ステージの数を測定します。
もう 1 つの重要な指標は、最初のトークン レイテンシーです。これは、ユーザーが推論システムに入ってからプレフィル フェーズを完了するまでにかかる時間です。これは、最初の文字を生成するためのシステムの応答時間を指します。多くのユーザーは、システムに質問を入力してから 2 ~ 3 秒以内に回答が届くことを期待しています。
もう 1 つの重要な指標は遅延です。レイテンシーは、各デコード操作に必要な時間を表します。これは、大規模な言語モデル システムがリアルタイム処理中に各文字を生成するのに必要な時間間隔と、生成プロセスのスムーズさを反映します。通常、レイテンシは 50 ミリ秒未満に抑える必要があります。これは、1 秒あたり 20 文字を生成できることを意味します。このようにして、大規模な言語モデルの生成プロセスがよりスムーズになります。
最後の指標は QPS (1 秒あたりのリクエスト数) です。オンライン システム サービスで 1 秒間に処理できるユーザー リクエストの数を反映します。この指標の測定方法は比較的複雑なので、後ほど紹介します。
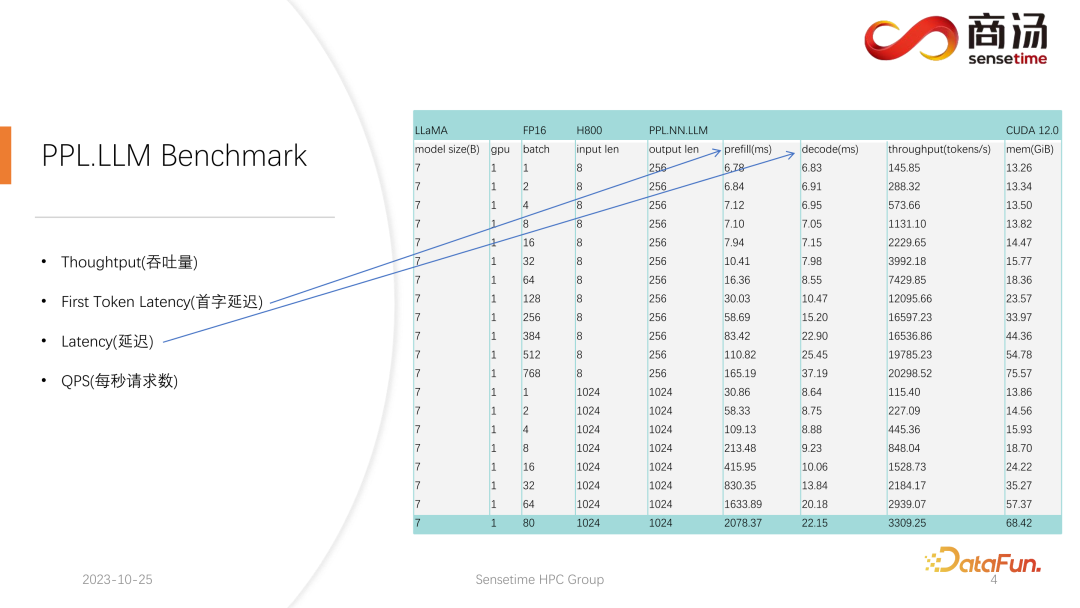
私たちは、ファースト トークン レイテンシーとレイテンシーという 2 つの指標に関して比較的完全なテストを実施しました。これら 2 つのインジケーターは、ユーザー入力の長さの違いとバッチ サイズの違いにより大きく変化します。
上の表からわかるように、同じ 7B モデルの場合、ユーザーの入力長が 8 から 2048 に変化すると、プリフィル時間は 6.78 ミリ秒から 2078 ミリ秒 (2 秒) になるまで変化します。 . .ユーザーが 80 人で、各ユーザーが 1,024 語を入力した場合、サーバー上での Prefill の実行には約 2 秒かかりますが、これは許容範囲を超えています。しかし、ユーザー入力の長さが非常に短い場合、たとえば、訪問ごとに 8 単語のみが入力される場合、たとえ 768 人のユーザーが同時に到着したとしても、最初の単語の遅延はわずか約 165 ミリ秒になります。
最初の単語の遅延に最も関係するのは、ユーザーの入力長です。ユーザーの入力長が長いほど、最初の単語の遅延は長くなります。ユーザー入力の長さが短い場合、最初の単語の遅延が大規模言語モデルの推論プロセス全体のボトルネックになることはありません。
その後のデコード遅延については、通常、1000億レベルのモデルでない限り、デコード遅延は50ミリ秒以内に抑えられます。主にバッチサイズに影響され、バッチサイズが大きくなるほど推論遅延は大きくなりますが、基本的にはそれほど増加しません。
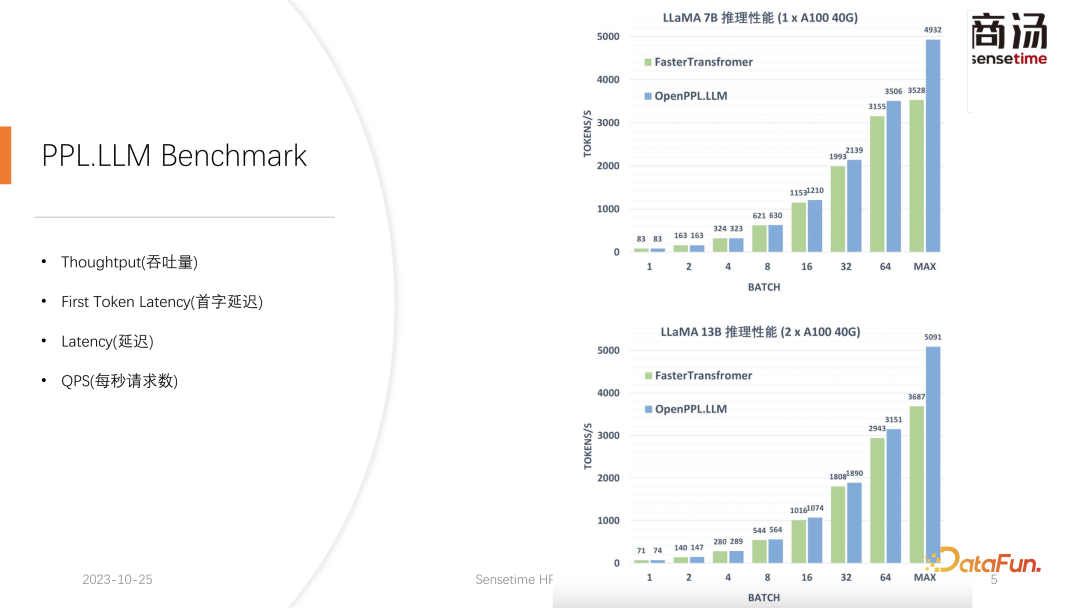
スループットは、実際にはこれら 2 つの要素の影響を受けます。ユーザー入力の長さと生成された長さが非常に長い場合、システムのスループットはあまり高くありません。ユーザー入力の長さと生成された長さの両方がそれほど長くない場合、システムのスループットは非常にばかげたレベルに達する可能性があります。
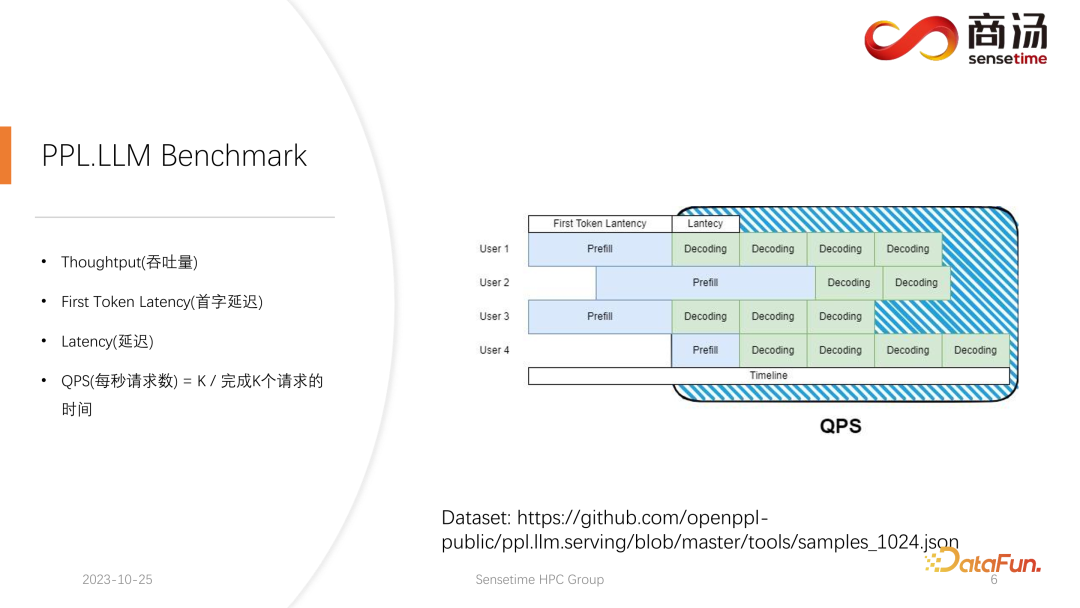
QPS を見てみましょう。 QPS は、システムが 1 秒あたりに処理できるリクエストの数を示す非常に具体的なメトリクスであり、このテストを実施する際には実際のデータを使用します。 (このデータをサンプリングして github に投稿しました。)
QPS の測定はスループットと同じではありません。これは、実際に大規模な言語モデルを使用する場合、システム内で各ユーザーの到着時間は不確実です。早く来るユーザーもいれば遅く来るユーザーもいる可能性があり、各ユーザーが Prefill を完了した後の世代の長さも不確かです。 4 つの単語を生成した後に終了するユーザーもいますが、20 を超える単語を生成する必要があるユーザーもいます。
実際のオンライン推論における事前入力段階では、ユーザーが実際に異なる長さを生成するため、問題が発生します。事前に生成するユーザーもいれば、生成する必要があるユーザーもいます。かなり先になるまで終わらないでしょう。このようなビルド中、GPU がアイドル状態になる場所が数多くあります。したがって、実際の推論プロセスでは、QPS はスループットを最大限に活用できません。スループットは優れているかもしれませんが、処理にはグラフィックス カードを使用できない穴がたくさんあるため、実際の処理能力は低い可能性があります。したがって、QPS 指標に関しては、スループットがユーザーに十分に提供できるように、計算ホールやグラフィックス カードの効果的な利用不能を回避するための具体的な最適化ソリューションを多数用意します。
2. 大規模言語モデルの推論パフォーマンスの最適化
次に、大規模言語モデルの推論プロセスに入り、何が得られるかを見てみましょう。どのような最適化により、システムは QPS、スループット、その他の指標に関して比較的良好な結果を達成しました。
1. LLM 推論プロセス
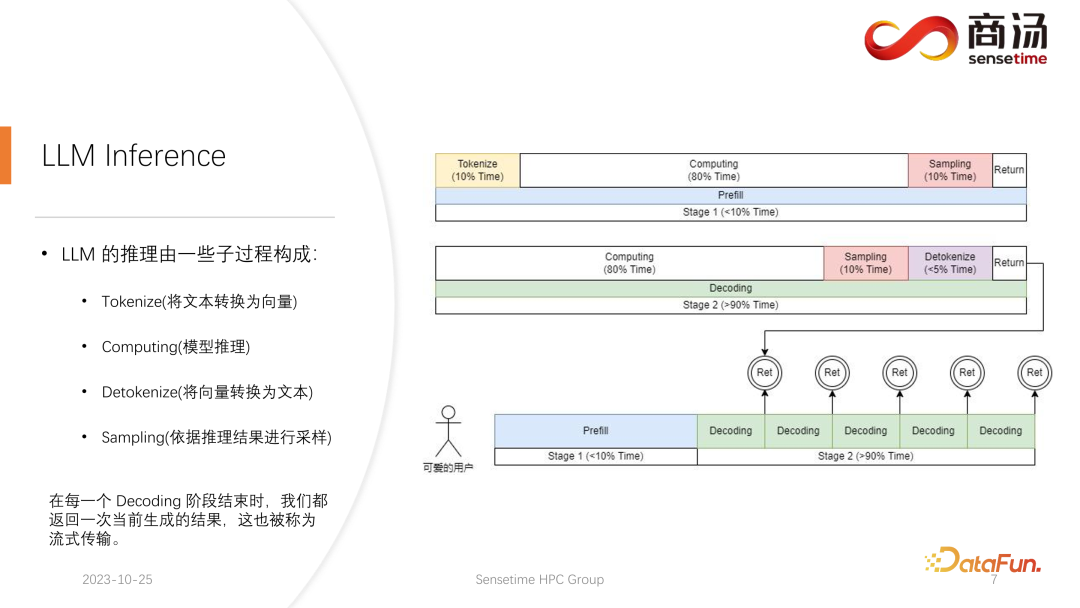
まず、大規模言語モデルの推論プロセスを紹介します。前の記事で説明したように、各リクエストはプレフィルとデコードという 2 つの段階を経る必要があります。プレフィル段階では、少なくとも 4 つのことを実行する必要があります。ユーザーの入力を処理することです。ベクトル化 (トークン化のプロセス) は、ユーザーが入力したテキストをベクトルに変換することを指します。プレフィル段階全体と比較して、約 10% の時間がかかり、コストがかかります。
その後、実際のプレフィル計算が実行されます。これには時間の約 80% がかかります。
計算後はサンプリングが行われますが、この処理はsampleやtop pなどPytorchでよく使われる処理です。 Argmax は大規模言語モデルの推論で使用されます。全体として、これはモデルの結果に基づいて最終的な単語を生成するプロセスです。このプロセスには時間の 10% がかかります。
最後に、詰め替え結果が顧客に返されますが、これにかかる時間は比較的短く、時間の約 2% ~ 5% を占めます。
デコード段階ではトークン化は必要ありません。デコードを行うたびに、計算から直接開始されます。デコード プロセス全体が時間の 80% を占め、その後のサンプリングが時間の 80% を占めます。単語のサンプリングと生成にも時間の 10% がかかります。ただし、トークン化解除には時間がかかります。トークン化解除とは、単語が生成された後、生成された単語はベクトルなので、デコードしてテキストに戻す必要があることを意味します。この操作には時間の約 5% がかかります。最終的に、生成された単語はユーザーに戻ることになります。
新たなリクエストが来ると、プレフィル完了後、デコードが繰り返し実行され、各デコード段階の後、結果がその場でクライアントに返されます。この生成プロセスは大規模な言語モデルでは非常に一般的であり、この方法をストリーミングと呼びます。
2. 最適化: パイプラインの前後処理と高パフォーマンスのサンプリング
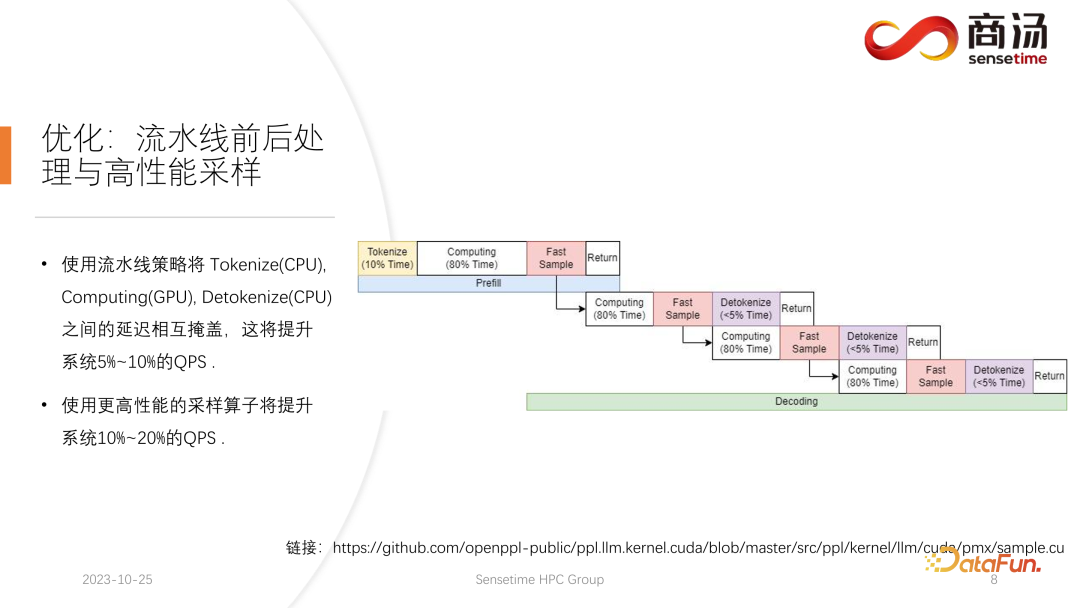
ここで最初に紹介する最初の最適化はパイプラインの最適化であり、その目的はグラフィックス カードの使用率を最大化することです。
大規模言語モデルの推論プロセスでは、トークン化、高速サンプル、および非トークン化のプロセスはモデルの計算とは何の関係もありません。大規模な言語モデル全体の推論は、このようなプロセスとして想像できます。プレフィルの実行プロセス中に、高速サンプルの単語ベクトルを取得した後、結果が得られるのを待たずに、すぐに次のデコード段階を開始できます。結果はすでに GPU 上にあるため、返されます。デコードが完了すると、detokenize の完了を待つ必要がなく、すぐに次のデコードを開始できます。 detokenize は CPU プロセスであるため、後の 2 つのプロセスにはユーザーへの結果の返しのみが含まれ、GPU 操作は含まれません。サンプリング プロセスの実行後、次に生成される単語が何であるかはすでにわかっており、必要なデータがすべて取得されているため、次の 2 つのプロセスの完了を待つことなく、すぐに次の操作を開始できます。
PPL.LLM の実装では 3 つのスレッド プールが使用されます:
最初のスレッド プールはトークン化プロセスの実行を担当します。
3 番目のスレッド プールは、後続の高速サンプルの実行と、結果を返してトークン化解除するプロセスを担当します。
中央のスレッド プールが使用されます計算処理を実行します。
これら 3 つのスレッド プールは、これら 3 つの遅延部分を互いに非同期的に分離し、それによってこれら 3 つの遅延部分を可能な限りマスクします。これにより、システムの QPS が 10% ~ 20% 向上します。これが私たちが行う最初の最適化です。
3. 最適化: 動的バッチ処理
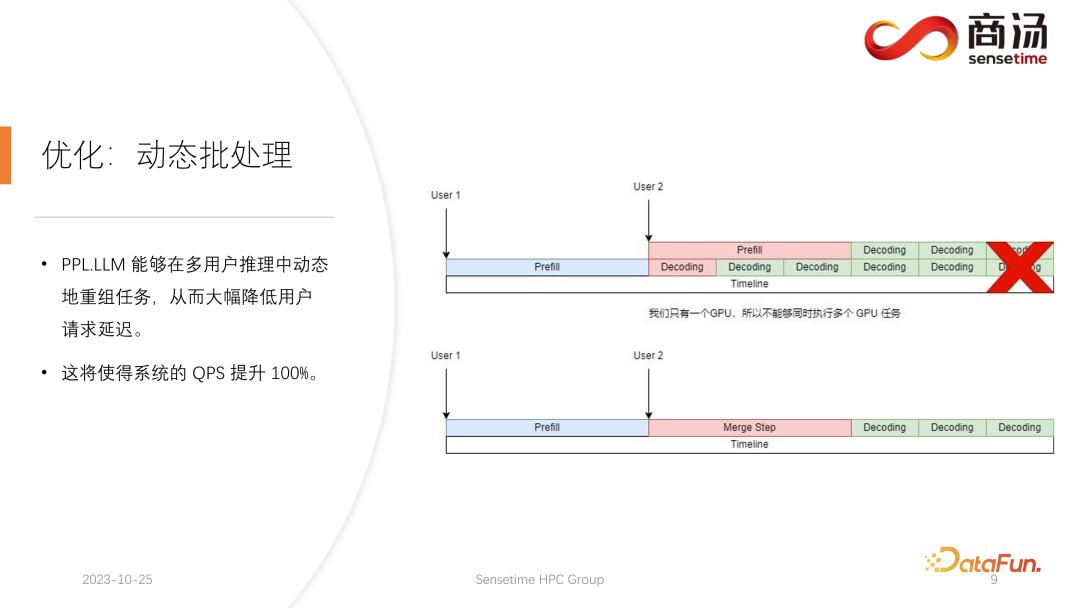
この後も、PPL.LLM を実行できます。より興味深い最適化の 1 つは、動的バッチ処理と呼ばれます。
前回の記事で述べたように、実際の推論プロセスでは、ユーザーの世代の長さが異なり、ユーザーの到着時間も異なります。したがって、現在の GPU が推論プロセスにある場合、既にオンライン推論のリクエストが存在する状況が発生し、推論の途中で 2 番目のリクエストが挿入されます。このとき、2 番目のリクエストの生成プロセスは最初のリクエストの生成プロセスと競合します。 GPU が 1 つしかなく、この GPU 上でタスクをシリアルに実行することしかできないため、GPU 上でタスクを単純に並列化することはできません。
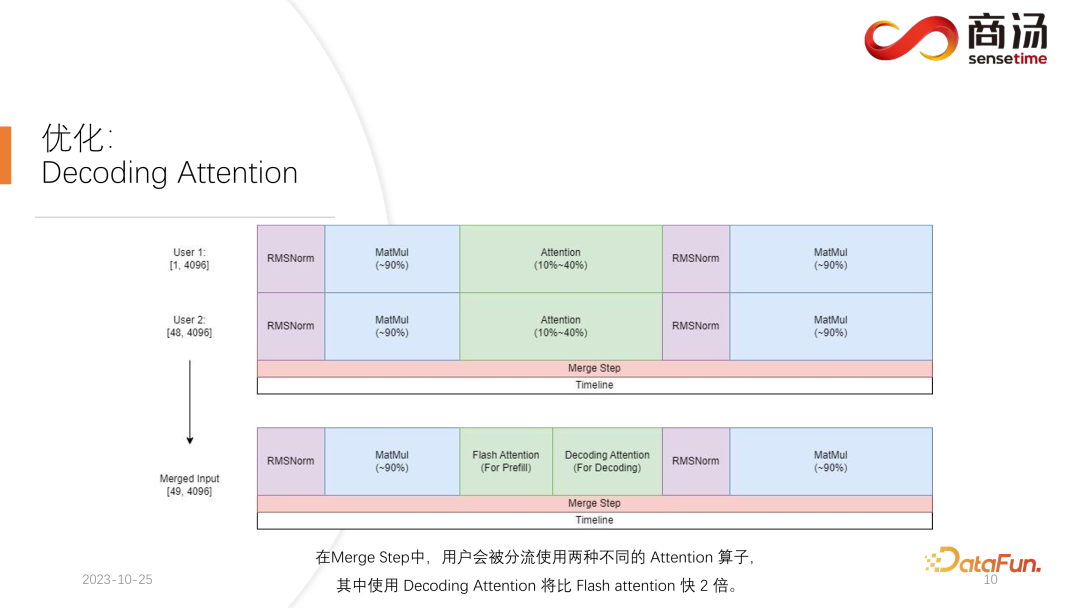
私たちのアプローチは、2 番目のリクエストのプレフィル フェーズと最初のリクエストに対応するデコード フェーズを混合して、マージ ステップの新しいフェーズ名を生成することです。このマージ ステップでは、最初のリクエストのデコードが実行されるだけでなく、2 番目のリクエストのプレフィルも実行されます。この機能は多くの大規模言語モデル推論システムに存在し、その実装により大規模言語モデルの QPS が 100% 向上しました。
具体的なプロセスは、最初のリクエスト生成プロセスが途中であるということです。つまり、デコード時に長さ 1 の入力があり、2 番目のリクエストは新しいエントリになります。はい、プレフィルプロセス中に、長さ 48 の入力が存在します。これら 2 つの入力を最初の次元に沿って互いに結合すると、結合された入力の長さは 49 になり、隠れた次元は 4096 の入力になります。長さ 49 のこの入力では、最初のワードが最初に要求され、残りの 48 ワードが 2 番目に要求されます。
大規模なモデル推論では、RMSNorm、行列の乗算、注意などの経験が必要な演算子は、デコードに使用されるかプレフィルに使用されるかに関係なく、同じ構造を持っているためです。したがって、接続された入力をネットワーク全体に直接入れて実行できます。差別化する必要があるのは 1 か所だけであり、それが注目です。アテンション プロセス中またはセルフ アテンション オペレーターの実行中に、データ シャントを実行し、すべてのデコード リクエストを 1 つのウェーブにシャントし、すべてのプレフィル リクエストを別のウェーブにシャントして、2 つの異なるオペレーションを実行します。すべてのプレフィル リクエストはフラッシュ アテンションを実行し、すべてのデコード ユーザーはデコード アテンションと呼ばれる非常に特別なオペレーターを実行します。アテンション演算子が個別に実行された後、これらのユーザー入力は再び結合されて、他の演算子の計算を完了します。
マージ ステップでは、実際、各リクエストが到着すると、このリクエストを現在システム上にあるすべてのリクエストの入力と結合して、この計算を完了します。デコード。大規模な言語モデルでの動的バッチ処理の実装です。
4. 最適化: アテンションのデコード
##Flash アテンション オペレーターと異なるデコード アテンション オペレーター 有名ですが、デコードタスクの処理においては、実際には Flash Attend よりもはるかに高速です。
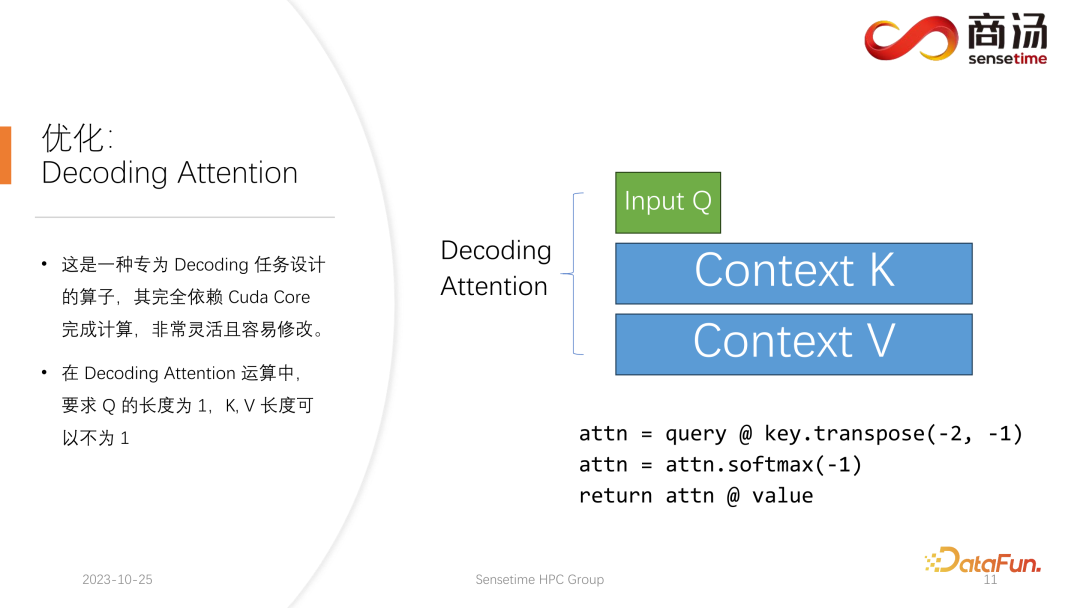
これは、デコード タスク用に特別に設計されたオペレーターであり、計算の完了には完全に Cuda Core に依存し、Tensor Core には依存しません。非常に柔軟で変更が簡単ですが、その特性がテンソルのデコード演算にあるため、入力 q の長さは 1 である必要がありますが、k と v の長さは可変である必要があるため、制限があります。これはデコード アテンションの制限であり、この制限の下で、いくつかの特定の最適化を行うことができます。

この特定の最適化により、デコード段階でのアテンション オペレーターの実装が Flash アテンションよりも高速になります。この実装は現在オープンソースであり、上の図の URL からアクセスできます。
5. 最適化: VM アロケータ
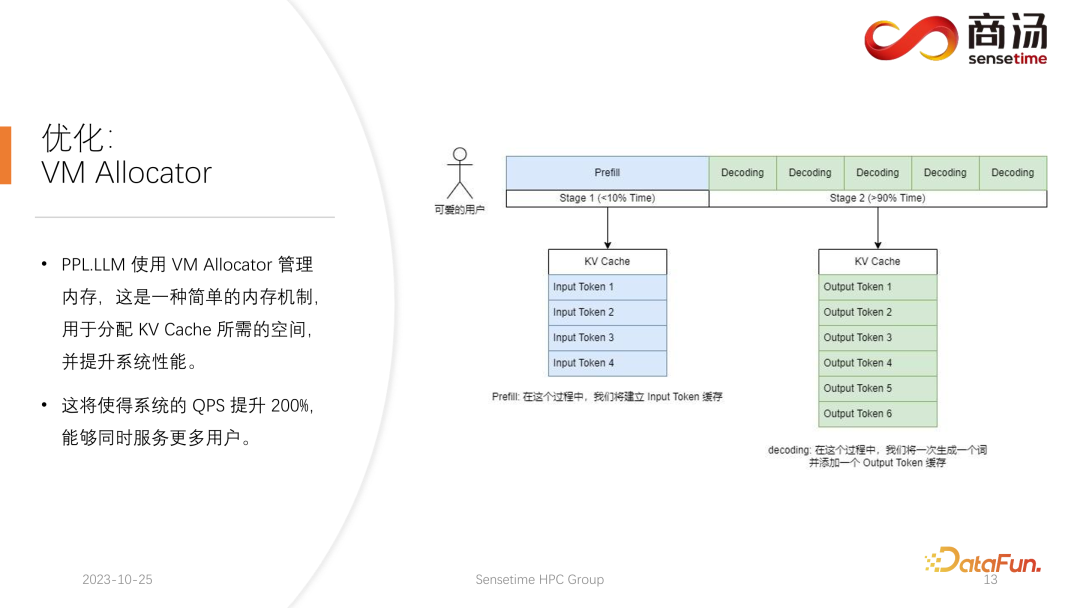
もう 1 つの最適化は、ページ アテンションに対応する仮想メモリ アロケータです。最適化。リクエストが到着すると、プレフィル フェーズとデコード フェーズを経ます。すべての入力トークンは KV キャッシュを生成します。この KV キャッシュには、このリクエストのすべての履歴情報が記録されます。それでは、この生成タスクを完了するためにそのようなリクエストを満たすには、どのくらいの KV キャッシュ スペースをこのリクエストに割り当てる必要があるのでしょうか?分割しすぎるとビデオメモリを無駄に消費し、分割しすぎるとデコード段階でKVキャッシュの打ち切り位置にぶつかってしまい、生成し続けることができなくなります。
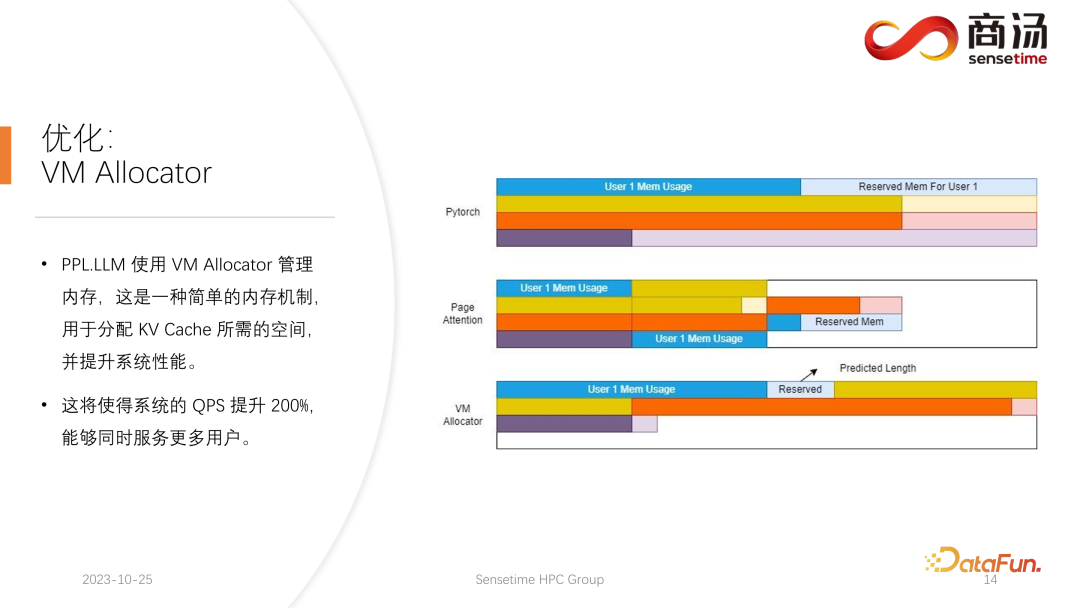
Pytorch のメモリ管理方法では、各リクエストに対して十分な長さのスペース (通常は 2048 または 4096) を確保し、4096 ワードが確実に生成されるようにします。ただし、ほとんどのユーザーが実際に生成する長さはそれほど長くないため、多くのメモリ領域が無駄になります。
ページ アテンションでは、別のビデオ メモリ管理方法が使用されます。ユーザーは生成プロセス中にビデオ メモリを継続的に追加できます。オペレーティング システムのページング ストレージまたはメモリ ページングに似ています。リクエストが来ると、システムはそのリクエストに小さなビデオ メモリを割り当てます。この小さなビデオ メモリは、通常、8 文字を生成するのに十分なだけです。リクエストが 8 文字を生成すると、システムはビデオ メモリを 1 つ追加します。ビデオ メモリのこのブロックに書き込むとき、システムはビデオ メモリ ブロックとビデオ メモリ ブロック間のリンク リストを維持するため、オペレータは正常に出力できます。生成された長さが増加し続けると、ビデオ メモリ ブロックの割り当てがユーザーに追加され続け、ビデオ メモリ ブロックの割り当てのリストを動的に維持できるため、システムが大量のリソースを無駄にすることがなくなります。このリクエストのために大量のビデオ メモリを予約する必要はありません。
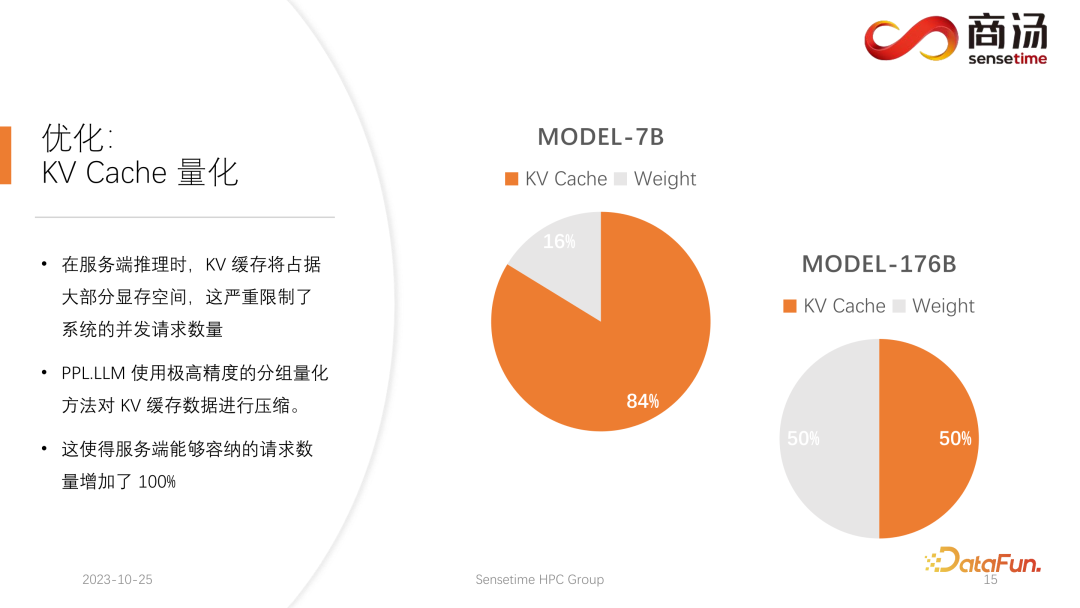
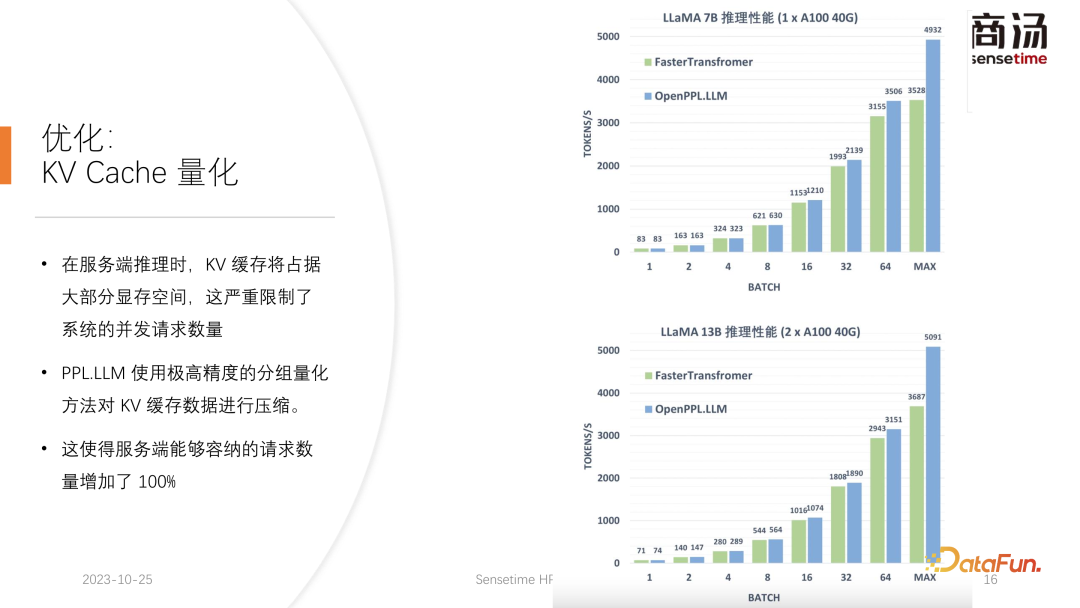
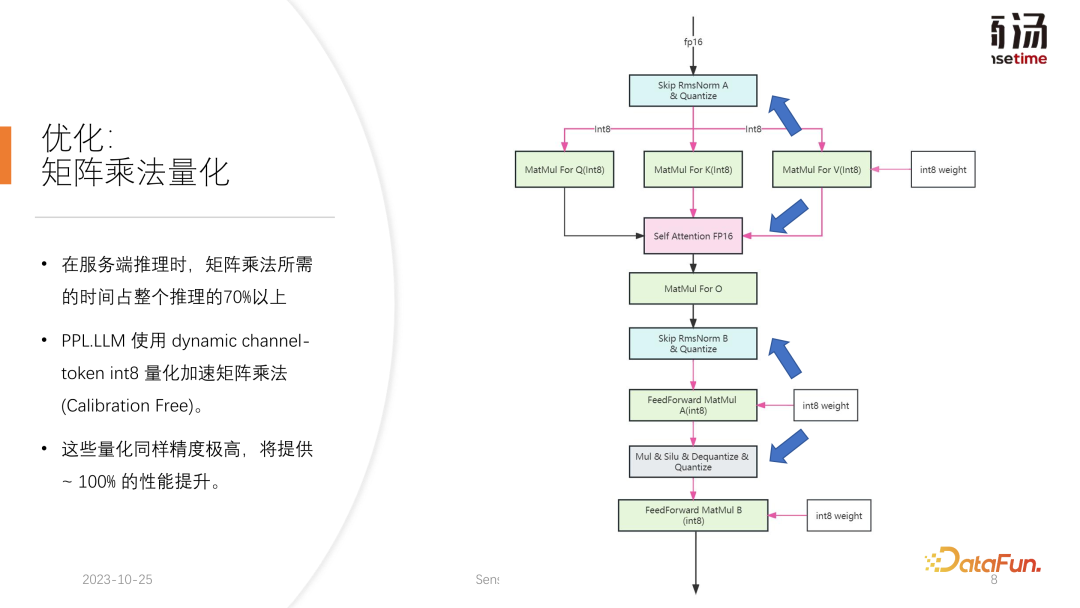
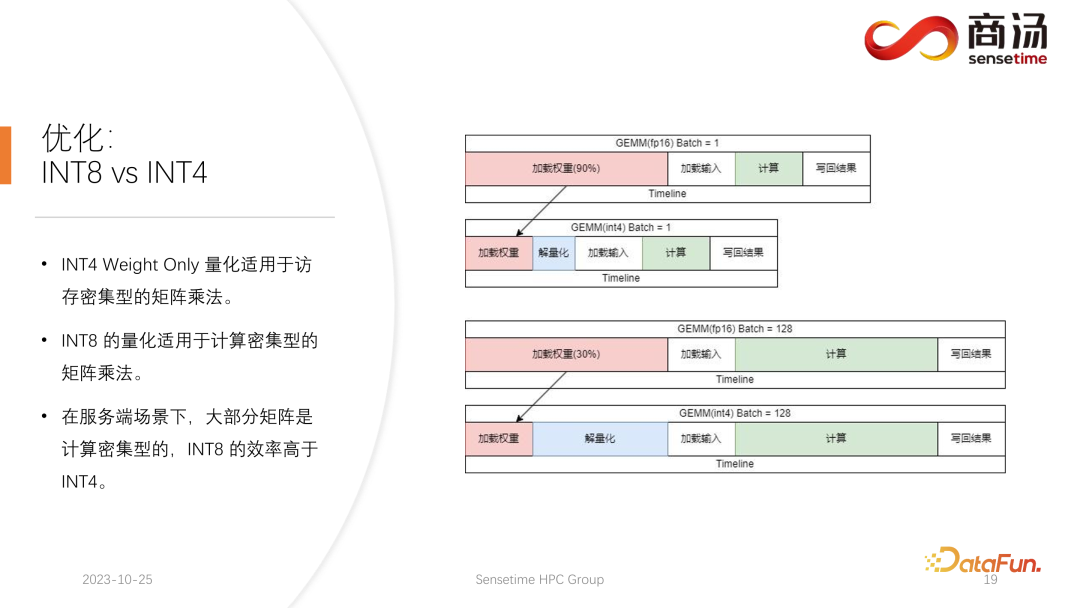
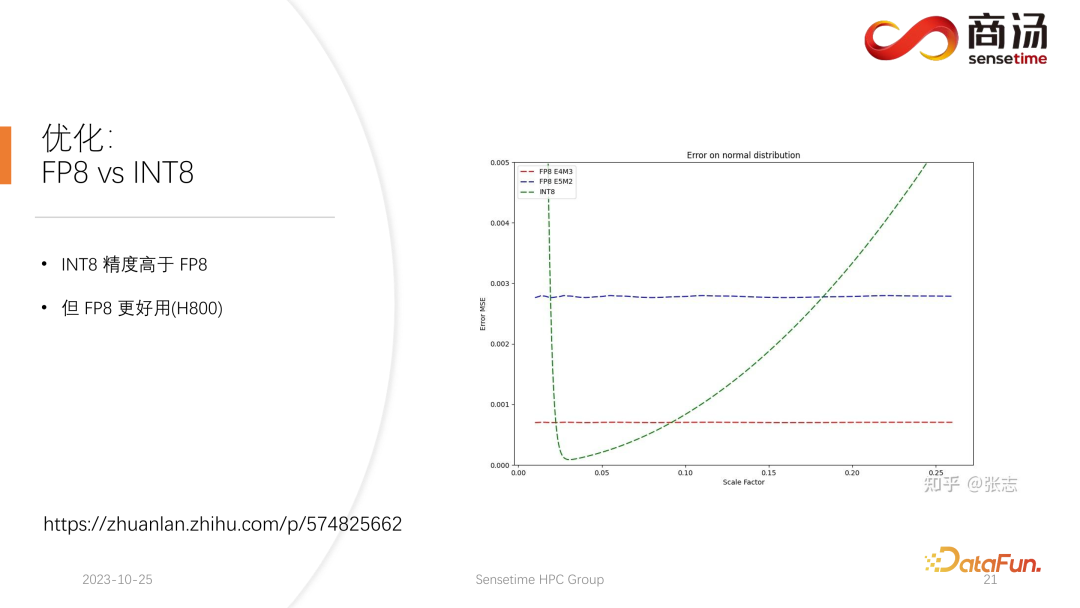
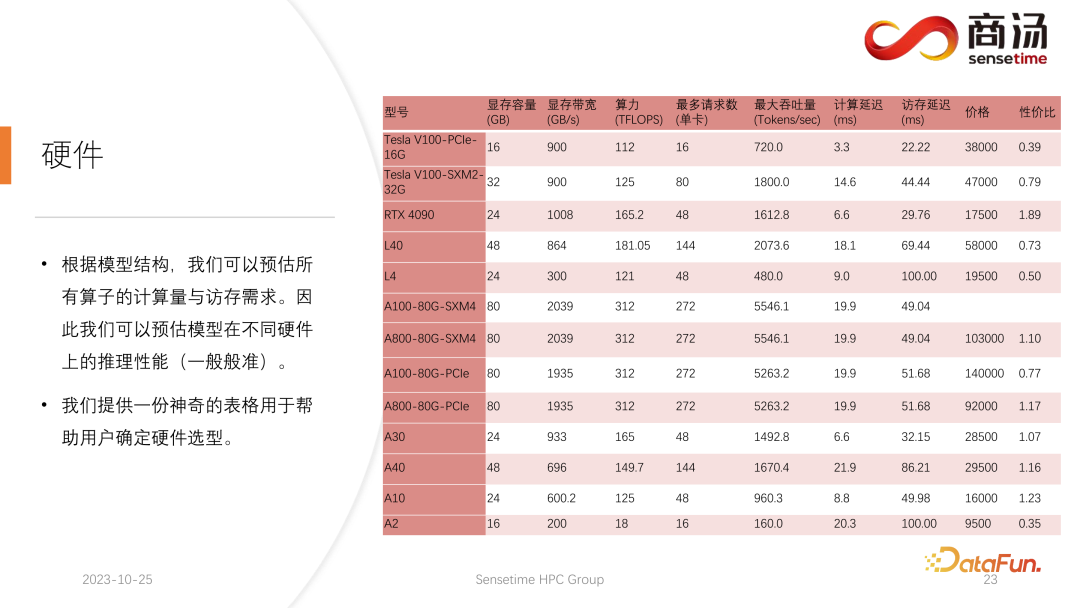
PPL.LLM は、仮想メモリ管理メカニズムを使用して、各リクエストに必要な世代長を予測します。各リクエストが到着すると、連続したスペースがそのリクエストに直接割り当てられ、この連続したスペースの長さが予測されます。ただし、特にオンライン推論段階では、リクエストごとにコンテンツがどのくらいの時間生成されるかを明確に知ることは不可能であり、理論的にはこれを実現するのは困難です。したがって、これを行うためにモデルをトレーニングすることをお勧めします。なぜなら、たとえページ・アテンションのようなモデルを採用したとしても、依然として問題が発生するからです。ページ アテンション プロセスの実行中、たとえば、特定の時点で、現在のシステムにはすでに 4 つのリクエストがあり、システムには割り当てられていないビデオ メモリのブロックがまだ 6 つ残っています。現時点では、新しいリクエストが届くかどうか、またそれらに対するサービスを提供し続けることができるかどうかを知る方法はありません。現在の 4 つのリクエストはまだ終了しておらず、今後も新しいビデオ メモリ ブロックがリクエストに追加され続ける可能性があるためです。未来。したがって、ページ アテンション メカニズムを使用しても、各ユーザーの実際の世代の長さを予測する必要があります。この方法でのみ、特定の時点で新しいユーザーからの入力を受け入れることができるかどうかを知ることができます。 これは、PPL を含め、現在の推論システムでは実行できないことです。ただし、仮想メモリの管理メカニズムにより、ビデオ メモリの無駄を大幅に回避できるため、システム全体の QPS が約 200% に向上します。 PPL.LLM によって行われる別の最適化。は KV キャッシュの定量化です。サーバー側の推論プロセス中、KV キャッシュはビデオ メモリ領域の大部分を占有するため、システムの同時リクエスト数が大幅に制限されます。 7B モデルなどの大規模な言語モデルがサーバー側、特に A100 や A100 などの大きなメモリを備えたサーバーで実行されていることがわかります。 H100 の場合、KV キャッシュはビデオ メモリ領域の 84% を占有し、176B などの大きなモデルの場合、KV キャッシュはキャッシュ領域の 50% 以上を占有します。これにより、モデルの同時実行数が大幅に制限され、リクエストが到着するたびに大量のビデオ メモリを割り当てる必要があります。これではリクエスト数を増やすことができず、QPSやスループットを向上させることができません。 PPL.LLM は、非常に特殊な量子化方法であるグループ量子化を使用して、KV キャッシュ内のデータを圧縮します。つまり、元の FP16 データについては、INT8 に量子化しようとします。これにより、KV キャッシュのサイズが 50% 削減され、サーバーが対応できるリクエストの数が 100% 増加します。 Faster Transformer と比較してスループットが約 50% 向上できる理由は、まさに KV キャッシュ量子化によるバッチ サイズの増加によるものです。 KV キャッシュ量子化後、細かい更新を行いました。 -行列乗算の粒度の高い量子化。サーバー側の推論プロセス全体において、行列乗算は推論時間全体の 70% 以上を占めますが、PPL.LLM では動的なチャネルごと/トークンごとの交互ハイブリッド量子化方式を使用して行列乗算を高速化します。これらの量子化も非常に正確であり、パフォーマンスをほぼ 100% 向上させることができます。 具体的な方法としては、RMSNorm 演算子をベースに量子化演算子を統合し、この量子化演算子を RMSNorm 演算子に追加します。関数では、そのトークン情報をカウントし、各トークンの最大値と最小値をカウントし、このデータをトークンの次元に沿って定量化します。つまり、RMSNorm 後のデータは FP16 から INT8 に変換され、今回の量子化は完全に動的であり、キャリブレーションは必要ありません。後続の QKV 行列乗算では、これら 3 つの行列乗算がチャネルごとに量子化されます。受信するデータは INT8 であり、重みも INT8 であるため、これらの行列乗算は完全な INT8 行列乗算を実行できます。これらの出力はソフト アテンションによって受け入れられますが、受け入れの前に逆量子化プロセスが実行されます。今回は逆量子化プロセスがソフト アテンション オペレーターとマージされます。 後続の O 行列の乗算では量子化は行われません。また、ソフト アテンションの計算プロセス自体では量子化は行われません。後続の FeedForward プロセスでは、これら 2 つの行列も同様に量子化され、上記の RMSNorm と融合されるか、上記の Silu や Mul などの活性化関数と融合されます。それらのソリューションの量子化演算子は、下流の演算子と融合されます。 現在の学術コミュニティは、大きな言語に定量的な注意を払っています。モデル ポイントは主に INT4 に焦点を当てているかもしれませんが、サーバー側の推論のプロセスでは、実際には INT8 定量化を使用する方が適しています。 INT4 量子化は、Weight Only 量子化とも呼ばれます。この量子化方法の重要性は、大規模な言語モデルの推論プロセス中にバッチ サイズが比較的小さい場合、行列の計算プロセス中に、乗算では、時間の 90% がウェイトの読み込みに費やされます。重みのサイズが非常に大きく、入力をロードする時間が非常に短いため、その入力、つまりアクティブ化も非常に短く、計算時間はそれほど長くなく、結果を書き戻す時間は非常に短くなります。これは、この計算サブルーチンがメモリ アクセスを集中的に行う演算子であることを意味します。この場合、バッチが十分に小さい場合、INT4 量子化を選択します。INT4 量子化を使用して各重みがロードされた後、逆量子化プロセスが続きます。この逆量子化により、重みが INT4 から FP16 に逆量子化されます。逆量子化プロセスを経た後、後続の計算は FP16 とまったく同じになります。つまり、INT4 重みのみの量子化は、メモリ アクセスが集中する行列の乗算に適しています。その計算プロセスは依然として FP16 コンピューティング デバイスによって完了します。 バッチが 64 や 128 など十分に大きい場合、INT4 の重みのみの量子化ではパフォーマンスは向上しません。バッチが十分に大きい場合、計算時間が非常に長くなるからです。また、INT4 Weight Only 量子化には非常に悪い点があり、バッチ (GEMM Batch) が増えると逆量子化処理に必要な計算量が増加し、入力バッチが増えると逆量子化にかかる時間も増加します。 . どんどん長くなってしまいます。バッチ サイズが 128 に達すると、逆量子化によって生じる時間の損失と、重みのロードによってもたらされるパフォーマンスの利点が互いに相殺されます。つまり、バッチ サイズが 128 に達すると、INT4 行列量子化は FP16 行列量子化よりも高速ではなくなり、パフォーマンス上の利点は最小限になります。バッチが 64 の場合、INT4 のウェイトのみ量子化は FP16 よりも 30% 高速化するだけであり、バッチが 128 の場合は、約 20% かそれ以下しか高速化されません。 しかし、INT8 の場合、INT8 量子化と INT4 量子化の最も異なる点は、逆量子化プロセスが必要なく、その計算時間を 2 倍にできることです。バッチが 128 の場合、FP16 量子化から INT8 まで、重みをロードする時間は半分になり、計算時間も半分になり、約 100% の高速化が実現します。 サーバー側のシナリオでは、特にリクエストが継続的に流入するため、ほとんどの行列乗算は計算負荷が高くなります。この場合、究極のスループットを追求したい場合、実際には INT4 よりも INT8 の効率が高くなります。これは、これまでに完了した実装で主にサーバー側で INT8 を推進する理由の 1 つでもあります。 ##H100、H800、4090 では、次の量子化を行うことができます。 FP8が行われます。 FP8 などのデータ形式は、Nvidia の最新世代のグラフィックス カードに導入されました。理論的には INT8 の精度は FP8 よりも高くなりますが、FP8 の方が便利でパフォーマンスも優れています。また、今後のサーバー側推論プロセスのアップデートでも FP8 の実装を推進していきます。上の図からわかるように、FP8 の誤差は INT8 の誤差の約 10 倍です。 INT8 には量子化されたサイズ係数があり、INT8 の量子化誤差はサイズ係数を調整することで減らすことができます。 FP8 の量子化誤差は基本的にサイズ係数に依存せず、サイズ係数の影響を受けないため、基本的にキャリブレーションを行う必要がありません。ただし、その誤差は一般に INT8 よりも高くなります。 PPL.LLM 今後の更新では、INT4 の行列量子化も更新されます。この重みのみの行列量子化は、バッチが 1 に固定されているモバイル端末などのデバイスの場合、主に端末側で機能します。その後のアップデートでは、INT4 から非線形量子化に徐々に変更されます。 Weight Only の計算プロセスでは逆量子化プロセスが発生するため、この逆量子化プロセスは実際にはカスタマイズ可能であり、線形逆量子化プロセスではない可能性があります。他の逆量子化プロセスと量子化プロセスを使用すると、今回は計算精度が高くなります。 典型的な例は、論文で言及されている NF4 の量子化です。この量子化は、実際にはテーブル法によって量子化および逆量子化されます。これは、非線形量子化の一種です。 PPL.LLM の今後の更新では、このような量子化を使用してデバイス側の推論を最適化することを試みます。 最後に、大規模言語モデル処理用のハードウェアを紹介します。 #モデルの構造が決まれば、具体的な計算量、どのくらいのメモリアクセスが必要か、どのくらいの計算量が必要かがわかります。必須。同時に、各グラフィックス カードの帯域幅、コンピューティング能力、価格などもわかります。モデルの構造を決定し、ハードウェア インジケーターを決定した後、これらのインジケーターを使用して、このグラフィックス カードで大規模なモデルを推論する最大スループット、計算遅延はどれくらいか、必要なメモリ アクセス時間はどれくらいかを計算できます。特定のテーブルを計算することができます。この表は今後の情報で公開する予定です。この表にアクセスして、大規模言語モデルの推論に最適なグラフィックス カード モデルを確認できます。 大規模な言語モデル推論の場合、ほとんどの演算子はメモリ アクセスを集中的に行うため、メモリ アクセスの待ち時間は常に計算の待ち時間よりも大きくなります。確かに大規模言語モデルのパラメータ行列は大きすぎるため、A100/80Gでもバッチサイズを272まで開けると計算遅延は小さくなりますが、メモリアクセス遅延は大きくなります。したがって、最適化の多くはメモリ アクセスから始まります。ハードウェアを選択する際の主な方向性は、比較的高い帯域幅と大容量のビデオ メモリを備えた機器を選択することです。これにより、大規模な言語モデルが推論中により多くのリクエストとより高速なメモリ アクセスをサポートできるようになり、対応するスループットが向上します。 4. Q & A Q2: INT4 の重みのみの量子化がバッチと線形に関係するのはなぜですか? これは固定数ですか? A3: 私たちのテストによると、それは隠すことができますが、実際にはさらに多くのものが残っています。逆量子化と KV 計算における量子化は、セルフ アテンション オペレーター、具体的にはデコード アテンションに統合されます。テストによると、この演算子は 10 倍の計算量でもマスクされる可能性があります。メモリアクセスの遅延でもカバーできず、主なボトルネックはメモリアクセスであり、その計算量はメモリアクセスをカバーできるレベルには程遠い。したがって、KV キャッシュ内の逆量子化計算は、このオペレーターにとって基本的に十分にカバーされています。 6. 最適化: KV キャッシュの定量化
7. 最適化: 行列乗算量子化

8. 最適化: INT8 と INT4
9. 最適化: FP8 vx INT8
10. 最適化: INT4 vs 非線形量子化

#3. 大規模言語モデル推論用のハードウェア

Q1: PPL.LLM で最適化された Flash アテンションの Softmax のようなメモリ アクセスの問題はありますか?
A1: デコード アテンションは非常に特殊な演算子であり、その Q の長さは常に 1 であるため、Flash アテンションのような Softmax での非常に大量のメモリ アクセスに直面することはありません。実際、デコーディング アテンションの実行中はソフトマックスが完全に実行され、フラッシュ アテンションほど速く実行する必要はありません。
A2: これは良い質問です。まず第一に、このソリューションの量子化は誰もが考えているようなものではありません。必要なのは、重みを INT4 から FP16 に戻すだけです。この解決策は、重みの数によって異なります。実際には、これは当てはまりません。これは行列の乗算に統合された解の量子化であるためです。行列の乗算を実行する前にすべての重みの解を量子化し、そこに配置してから読み取ることはできません。このように、私たちが行ったINT4の量子化は意味がありません。実行プロセス中に量子化を常に解決しています。ブロック行列の乗算を実行するため、各重みの読み取りと書き込みの数は 1 ではありません。継続的に計算する必要があります。この数は実際にはバッチに関連しています。つまり、量子化を最適化する以前の方法とは異なり、個別の量子化演算子と解量子化演算子が存在します。 2 つの演算子を挿入する場合、ソリューション量子化は演算子に直接統合されます。行列の乗算を実行しているため、量子化を解く必要がある回数は 1 回ではありません。
Q3: KV キャッシュの逆量子化計算はキャッシュの模倣によってマスクできますか?
以上が高性能 LLM 推論フレームワークの設計と実装の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。