
ホームページ >テクノロジー周辺機器 >AI >MAmmoT を通じて、LLM は数学のジェネラリストになります: 形式論理から四則演算まで
MAmmoT を通じて、LLM は数学のジェネラリストになります: 形式論理から四則演算まで

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-09-25 13:53:121608ブラウズ
数学的推論は、最新の大規模言語モデル (LLM) の重要な機能です。この分野における最近の進歩にもかかわらず、クローズド ソースとオープンソース LLM の間には依然として明らかなギャップがあります。 GPT-4、PaLM-2、Claude 2 などのクローズドソース モデルは、GSM8K や MATH などの一般的な数学的推論ベンチマークを支配していますが、Llama、Falcon、OPT などのオープンソース モデルはすべてのベンチマークで大幅に遅れをとっています
この問題を解決するために、研究コミュニティは 2 つの方向で懸命に取り組んでいます
(1) Gaoptica や MINERVA などの継続的な事前トレーニング手法LLM は、数学的に関連したネットワーク データに基づいて継続的にトレーニングされます。この方法では、モデルの一般的な科学的推論能力を向上させることができますが、計算コストが高くなります
拒絶サンプリング微調整 (RFT) および WizardMath などの特定のデータセット微調整方法つまり、特定のデータセット監視データを使用して LLM を微調整します。これらの方法は特定のドメイン内のパフォーマンスを向上させることができますが、データの微調整を超える広範な数学的推論タスクには一般化されません。たとえば、RFT と WizardMath は、GSM8K (そのうちの 1 つは微調整されたデータセット) では精度を 30% 以上向上させることができますが、MMLU-Math や AQuA などのドメイン外のデータセットでは精度が低下するため、精度が低くなります。最大 10%
最近、ウォータールー大学、オハイオ州立大学、その他の機関の研究チームは、軽量でありながら一般化可能な数学的命令の微調整方法を提案しました。 LLM の一般的な (つまり、微調整タスクに限定されない) 数学的推論機能。
書き直された内容: 以前は、段階的な自然言語記述を通じて数学的問題を解決する思考連鎖 (CoT) 手法が主に焦点となっていました。この方法は非常に一般的で、ほとんどの数学分野に適用できますが、計算精度や複雑な数学的またはアルゴリズム的推論プロセス (二次方程式の根を解く、行列の固有値を計算するなど) にいくつかの困難があります
#対照的に、Program of Thought (PoT) や PAL などのコード形式プロンプト設計手法では、外部ツール (つまり、Python インタプリタ) を使用して数学的解決プロセスを大幅に簡素化します。このアプローチは、計算プロセスを外部の Python インタプリタにオフロードして、複雑な数学的およびアルゴリズム的推論 (sympy を使用して二次方程式を解く、または numpy を使用して行列の固有値を計算するなど) を解決することです。ただし、PoT は、特に組み込み API がない場合、常識推論、形式論理、抽象代数などのより抽象的な推論シナリオに苦労します。
CoT メソッドと PoT メソッドの両方の利点を考慮するために、チームは新しい数学的ハイブリッド命令微調整データ セット MathInstruct を導入しました。これには 2 つの主な機能があります: ( 1) さまざまな数学分野と複雑さのレベルを幅広くカバーします。 (2) CoT 原則と PoT 原則の混合
MathInstruct 7 つの既存の数学原則データ セットと 6 つの新しくコンパイルされたデータ セットに基づいています。彼らは MathInstruct を使用して、さまざまなサイズ (7B から 70B) の Llama モデルを微調整しました。彼らは、結果として得られたモデルを MAmmoTH モデルと呼び、MAmmoTH が数学的ジェネラリストのような前例のない機能を備えていることを発見しました。
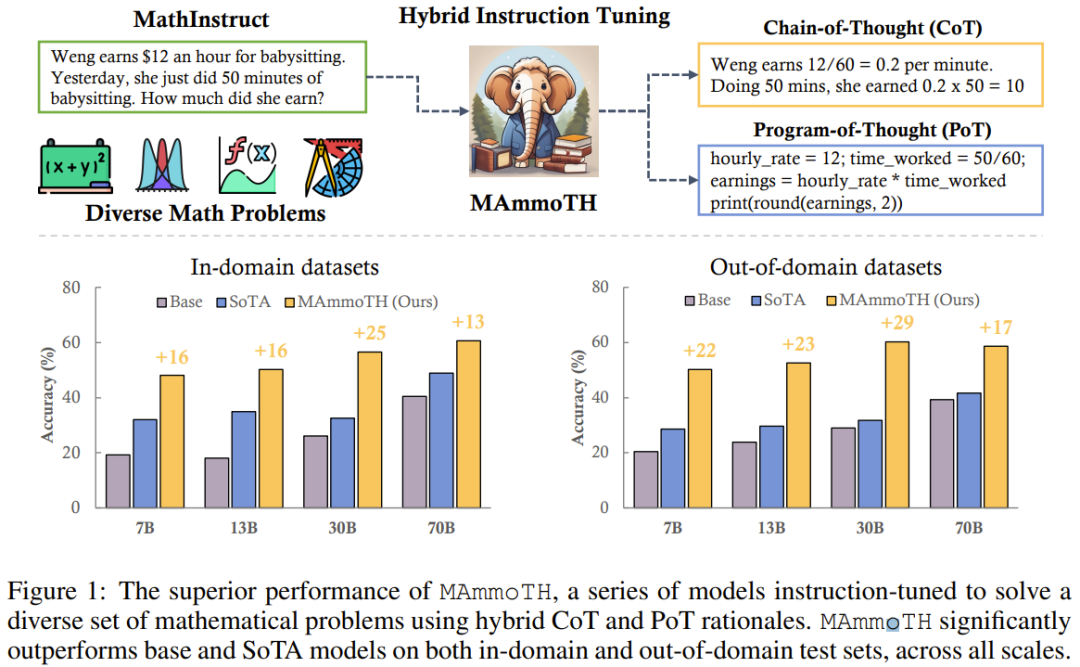
MAmmoTH を評価するために、研究チームはドメイン内テスト セット ( GSM8K、MATH、AQuA-RAT、NumGLUE) およびドメイン外のテスト セット (SVAMP、SAT、MMLU-Math、Mathematics、SimulEq)
研究結果は、MAmmoTH モデルが一般化すると、フィールド外のデータセットでのパフォーマンスが向上し、数学的推論におけるオープンソース LLM の能力も大幅に向上します
一般的に使用される競争においては、注目に値します。レベルの MATH データ セット、MAmmoTH 7B バージョンは、WizardMath (MATH における以前の最高のオープン ソース モデル) を 3.5 倍 (35.2% 対 10.7%) 上回ることができ、一方、微調整された 34B MAmmoTH-Coder は GPT-4 をも上回ることができます。 CoT を使用
この研究の貢献は 2 つの側面に要約できます: (1) データ エンジニアリングの観点から、高品質の数学的命令の微調整データ セットを提案しました。さまざまな数学の問題と混合原理が含まれています。 (2) モデリングの面では、さまざまなデータ ソースと入出力形式の影響を調査するために、7B から 70B までのサイズの 50 を超える異なる新しいモデルとベースライン モデルをトレーニングおよび評価しました
#研究結果によると、MAmmoTH や MAmmoTH-Coder などの新しいモデルは、精度の点で以前のオープンソース モデルを大幅に上回っています
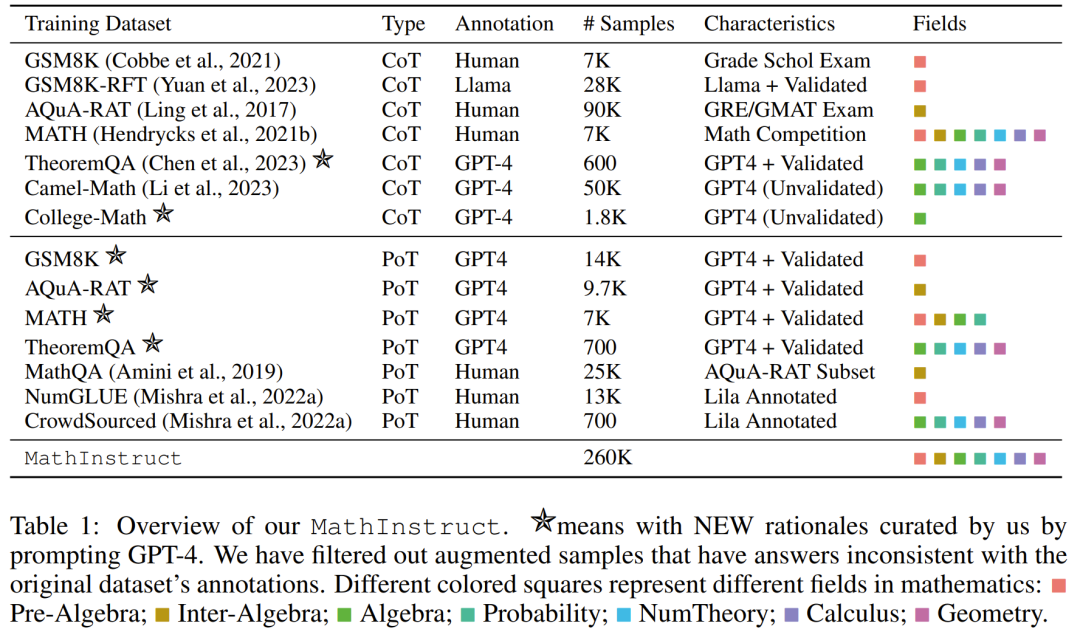
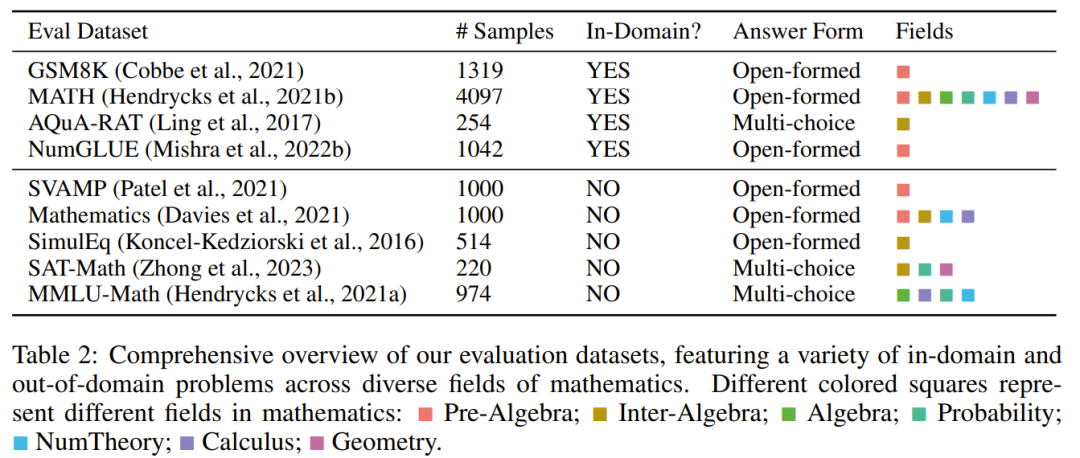
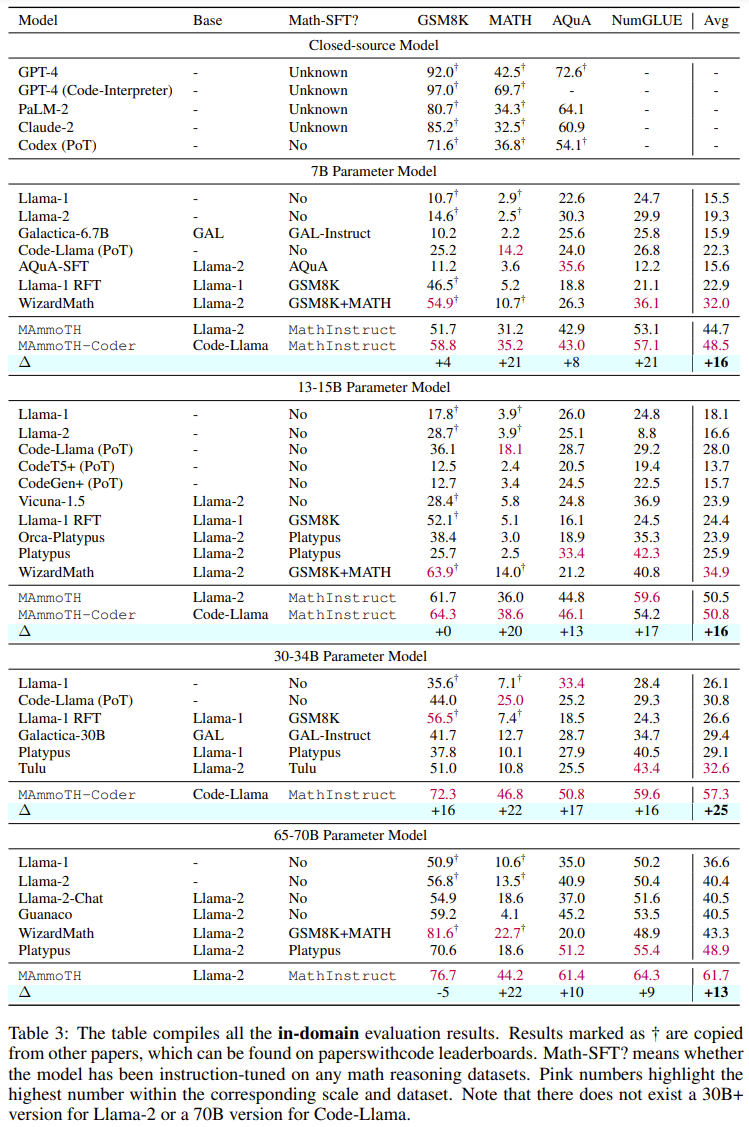
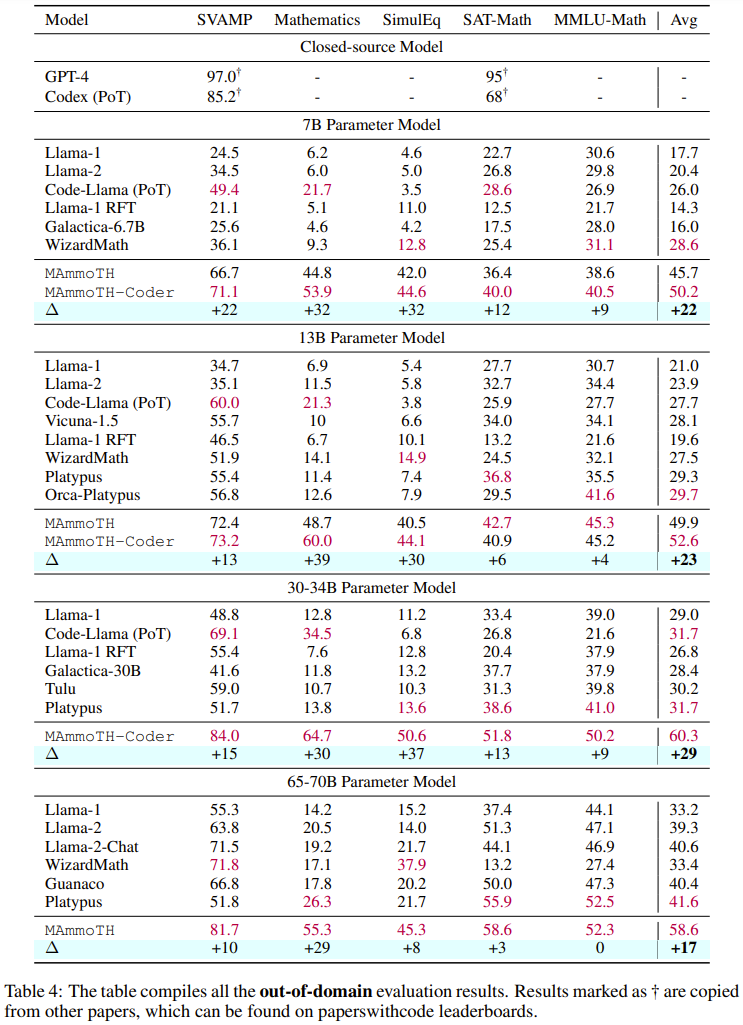
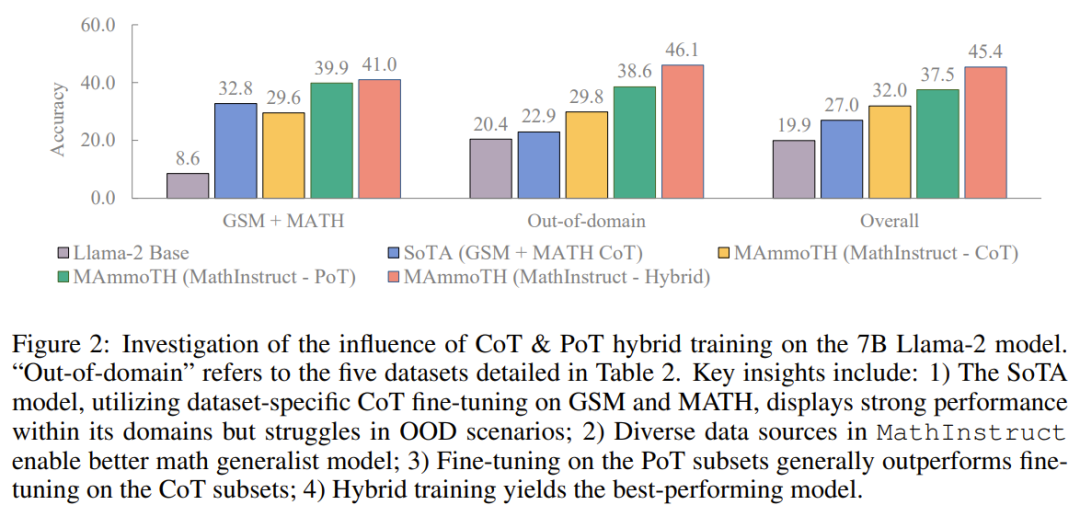
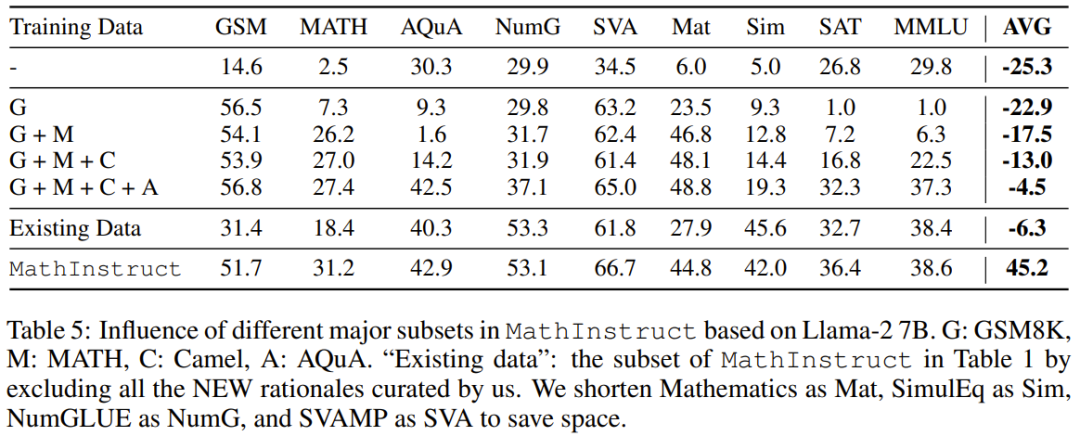
チームは、コンパイルしたデータセットをリリースし、新しいメソッドのコードをオープンソース化し、Hugging Face モデルでトレーニングされたさまざまなサイズをリリースしました 多様なハイブリッド命令微調整データセットを再構成 チームの目標は、高品質で多様な数学的命令微調整データセットのリストを編集することです。このデータセットには、(1) さまざまな数学的領域と複雑さを幅広くカバーすること、(2) CoT と PoT 原則を組み合わせるという 2 つの主な特徴があるはずです。 最初の特徴として、研究者らはまず、GSM8K、MATH、AQuA、Camel、TheoremQA など、さまざまな数学分野と複雑さのレベルを含む、広く使用されている高品質のデータセットをいくつか選択しました。その後、彼らは、抽象代数や形式論理などの大学レベルの数学が既存のデータセットに欠けていることに気づきました。この問題を解決するために、オンラインで見つかった少数のシード例を使用し、GPT-4 を使用して TheoremQA の質問の CoT 原則を合成し、自発的な方法で「質問と CoT」のペアを作成しました 2 番目の機能では、CoT と PoT の原則を組み合わせることでデータセットの汎用性が向上し、トレーニングされたモデルがさまざまなタイプの数学的問題を解決できるようになります。ただし、既存のデータセットのほとんどは手続き上の根拠が限られており、その結果、CoT 原則と PoT 原則の間に不均衡が生じています。この目的を達成するために、チームは GPT-4 を使用して、MATH、AQuA、GSM8K、TheoremQA などの選択されたデータセットの PoT 原則を補足しました。これらの GPT-4 合成プログラムは、その実行結果と人間が注釈を付けたグラウンド トゥルースとを比較することによってフィルタリングされ、高品質の原則のみが追加されることが保証されます。 これらのガイドラインに従って、以下の表 1 に示すように、新しいデータ セット MathInstruct を作成しました。 幅広い中心的な数学領域 (算術、代数、確率、微積分、幾何学など) をカバーする 260,000 のペア (コマンド、応答) が含まれています。 、CoT と PoT の原則が混在しており、さまざまな言語と難易度があります。 トレーニングのリセット MathInstruct のすべてのサブセットは、Alpaca のような命令データ セット構造に統合されました。この標準化操作により、元のデータ セットの形式に関係なく、微調整されたモデルが一貫してデータを処理できることが保証されます。 ベース モデルとして、チームは Llama-2 と Code を選択しました。ラマ MathInstruct を調整することで、7B、13B、34B、70B などのさまざまなサイズのモデルを取得しました 評価データセット モデルの数学的推論能力を評価するために、チームはいくつかの評価データ セットを選択しました。以下の表 2 を参照してください。数学のいくつかの異なる領域をカバーする、さまざまなフィールド内およびフィールド外のサンプルが含まれています。 #評価データ セットには、初等、中等、大学レベルなど、さまざまな難易度が含まれています。一部のデータセットには、形式論理と常識的推論も含まれています 選択された評価データセットには、自由回答式質問と多肢選択式質問の両方が含まれています。 オープンエンド問題 (GSM8K や MATH など) については、これらの問題のほとんどがプログラムで解決できるため、研究者は PoT デコードを採用しました。 , 多肢選択式の質問 (AQuA や MMLU など) については、このデータセット内のほとんどの質問は CoT でより適切に処理できるため、研究者らは CoT デコーディングを採用しました。 CoT デコードにはトリガー ワードは必要ありませんが、PoT デコードには「問題を解決するプログラムを作成しましょう」というトリガー ワードが必要です。 主な結果 以下の表 3 と 4 は、それぞれドメイン内とドメイン外のデータに関する結果を報告しています。 全体的に、MAmmoTH と MAmmoTH-Coder はどちらも、さまざまなモデル サイズにわたって、これまでの最高のモデルよりも優れたパフォーマンスを示しています。新しいモデルは、ドメイン内データセットよりもドメイン外データセットでパフォーマンスの向上を実現します。これらの結果は、新しいモデルが数学的ジェネラリストになる可能性を確かに持っていることを示しています。 MAmmoTH-Coder-34B と MAmmoTH-70B は、一部のデータセットではクローズドソース LLM よりも優れたパフォーマンスを発揮します。 研究者らは、さまざまな基本モデルを使用して比較も行いました。具体的には、Llama-2 と Code-Llama という 2 つの基本モデルを比較する実験を実施しました。上の 2 つの表からわかるように、Code-Llama は全体的に Llama-2 よりも優れており、特にフィールド外のデータ セットにおいて優れています。 MAmmoTH と MAmmoTH-Coder の間のギャップは 5% に達することもあります データ ソースに関するアブレーション研究の調査 ##彼らは、パフォーマンス向上の原因を探るための研究を実施しました。既存のベンチマーク モデルに対する MAmmoTH の利点の根源をより深く理解するために、研究者らは一連の対照実験を実施しました。結果は図 2 # に示されています。 ##要約すると、MAmmoTH のパフォーマンスの大きな利点は、1) さまざまな数学的領域と複雑さのレベルをカバーする多様なデータ ソース、2) CoT と PoT 命令の微調整のハイブリッド戦略に起因すると考えられます。 彼らは、主要なサブセットの影響も研究しました。 MAmmoTH のトレーニングに使用される MathInstruct のさまざまなソースに関しては、各ソースがモデルの全体的なパフォーマンスにどの程度寄与しているかを理解することも重要です。彼らは、GSM8K、MATH、Camel、AQuA の 4 つの主要なサブセットに焦点を当てています。彼らは、各データセットをトレーニングに徐々に追加し、MathInstruct 全体で微調整されたモデルとパフォーマンスを比較する実験を実施しました。 MAmmoTH に対する多様なデータ ソースの重要な影響は次のとおりです。結果で強調表示されているのは、MAmmoTH を数学的ジェネラリストにするための中心的な鍵です。これらの結果は、常に多様なデータを収集し、特定の種類のデータのみを収集することを避ける必要があるなど、今後のデータのキュレーションと収集の取り組みに対する貴重な洞察と指針も提供します。
新たに提案する手法
実験
以上がMAmmoT を通じて、LLM は数学のジェネラリストになります: 形式論理から四則演算までの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。