
ホームページ >テクノロジー周辺機器 >AI >手動による注釈は必要ありません。自己生成された命令フレームワークにより、ChatGPT などの LLM のコストのボトルネックが解消されます。
手動による注釈は必要ありません。自己生成された命令フレームワークにより、ChatGPT などの LLM のコストのボトルネックが解消されます。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-16 13:52:031472ブラウズ
ChatGPT は、今年末に AI 界の新たなトッププレイヤーとなり、人々はその強力な質問と回答の言語機能とプログラミングの知識に驚きました。しかし、モデルが強力であればあるほど、その背後にある技術的要件も高くなります。

ChatGPT は GPT 3.5 シリーズのモデルに基づいており、「手動ラベル付きデータ強化学習」(RLHF) を導入して事前学習を継続的に微調整します。 -訓練された言語モデル。大規模言語モデル (LLM) が人間のコマンドを理解し、与えられたプロンプトに基づいて最適な答えを与えることを学習できるように設計されています。
この技術的アイデアは、言語モデルの現在の開発トレンドです。このタイプのモデルには大きな開発の見通しがありますが、モデルのトレーニングと微調整のコストは非常に高くなります。
OpenAI によって現在公開されている情報によると、ChatGPT のトレーニング プロセスは 3 つの段階に分かれています。
まず、第 1 段階は GPT 3.5 と同様の教師ありポリシー モデルですが、この基本モデルは人間のさまざまな種類の指示に含まれる意図を理解することが難しく、判断も困難です。生成されたコンテンツの品質。研究者らは、プロンプト データセットからいくつかのサンプルをランダムに選択し、指定されたプロンプトに基づいて質の高い回答をプロのアノテーターに依頼しました。この手動プロセスを通じて得られたプロンプトとそれに対応する高品質な回答は、初期の教師ありポリシー モデルを微調整するために使用され、基本的なプロンプトの理解を提供し、生成された回答の品質を最初に向上させました。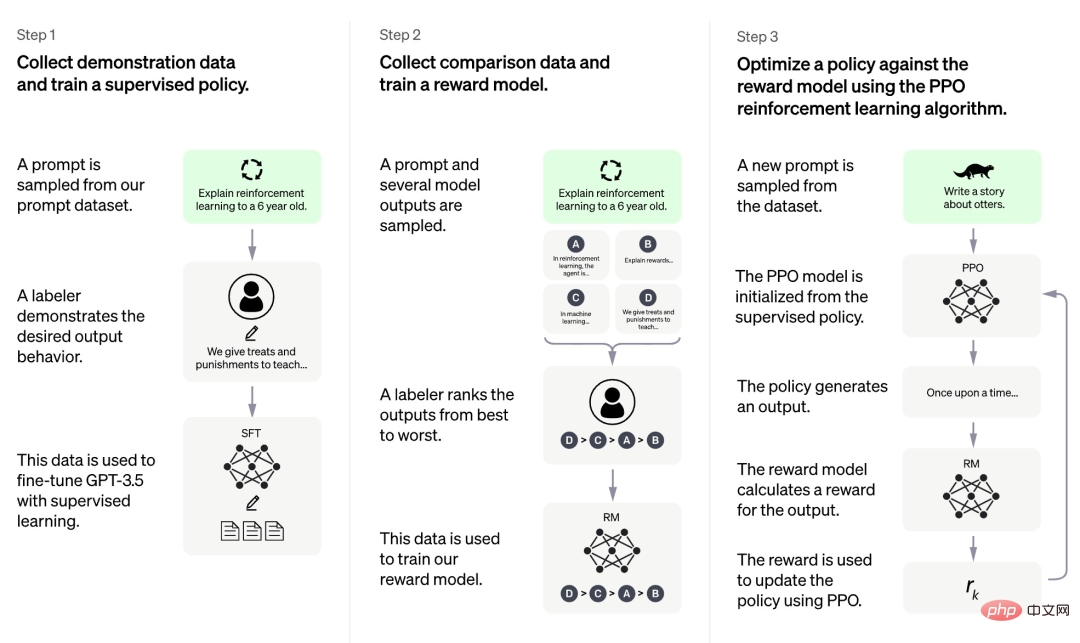
第 2 段階の研究チームは、指定されたプロンプトに従ってモデルによって生成された複数の出力を抽出し、人間の研究者にこれらの出力を並べ替えるよう依頼し、並べ替えられたデータを使用して報酬モデルをトレーニングします。 .RM)。 ChatGPT は、RM をトレーニングするためにペアワイズ損失を採用しています。
第 3 フェーズでは、研究チームは強化学習を使用して事前トレーニング モデルの機能を強化し、前のフェーズで学習した RM モデルを使用してモデルのパラメータを更新します。トレーニング前のモデル。
ChatGPT トレーニングの 3 つのステージのうち、データへの手動アノテーションが必要ないのは第 3 ステージだけであり、第 1 ステージと第 2 ステージの両方では大量の手動アノテーションが必要であることがわかります。 。したがって、ChatGPT などのモデルは非常に優れたパフォーマンスを発揮しますが、指示に従う能力を向上させるためには非常に高い人件費がかかります。モデルの規模が大きくなり、機能の範囲が広くなるにつれて、この問題はさらに深刻になり、最終的にモデルの開発を妨げるボトルネックになるでしょう。
いくつかの研究では、このボトルネックを解決する方法を提案しようとしています。たとえば、ワシントン大学と他の機関は最近共同で論文「SELF-INSTRUCT: 自己生成言語モデルとの調整」を発表しました。新しいフレームワーク SELF-INSTRUCT は、モデル自身の生成プロセスをガイドすることで、事前トレーニングされた言語モデルの命令追従機能を向上させることを提案しています。
論文アドレス: https://arxiv.org/pdf/2212.10560v1.pdf

#SELF-INSTRUCT 限られたシード セットから開始して、ビルド プロセス全体をガイドする手動で書かれた手順。最初のフェーズでは、モデルに新しいタスク生成命令が入力されます。この手順では、既存の命令セットを活用して、新しいタスクを定義するためのより広範な命令を作成します。 SELF-INSTRUCT は、命令調整の監視に使用するために、新しく生成された命令セットの入力インスタンスと出力インスタンスも作成します。最後に、SELF-INSTRUCT は、低品質の重複した命令も排除します。プロセス全体が繰り返し実行され、最終モデルでは多数のタスクの命令を生成できます。
新しい手法の有効性を検証するために、研究では GPT-3 に SELF-INSTRUCT フレームワークを適用し、最終的に約 52,000 の命令、82,000 のインスタンス入力、およびターゲット出力を生成しました。 GPT-3 は、SUPER-NATURALINSTRUCTIONS データセットの新しいタスクにおいて、元のモデルと比べて 33.1% の絶対的な改善を達成したことが観察されました。これは、プライベート ユーザー データと人間のアノテーションを使用してトレーニングされた InstructGPT_001 のパフォーマンスに匹敵します。
さらなる評価のために、この研究では、新しいタスクについて専門家が作成した一連の指示を照合し、人による評価を通じて実証しました。 、SELF-INSTRUCT を使用した GPT-3 のパフォーマンスは、パブリック命令データ セットを使用した既存のモデルよりも大幅に向上し、InstructGPT_001 と比べてわずか 5% の差です。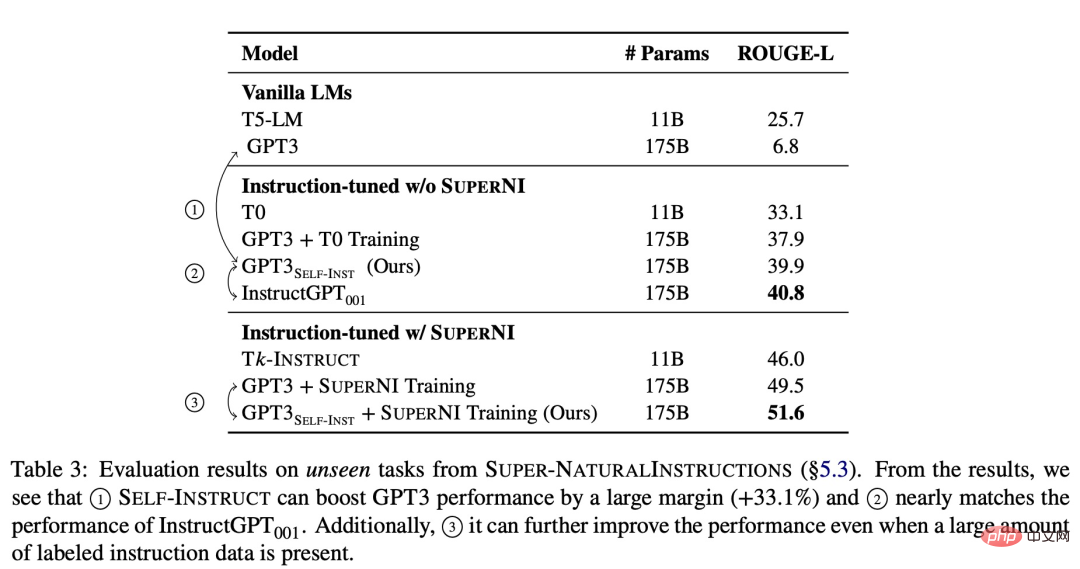
以上が手動による注釈は必要ありません。自己生成された命令フレームワークにより、ChatGPT などの LLM のコストのボトルネックが解消されます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。