
ホームページ >ウェブフロントエンド >jsチュートリアル >JavaScriptにおける非同期とコールバックの基本概念とコールバック地獄現象
JavaScriptにおける非同期とコールバックの基本概念とコールバック地獄現象

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2022-08-17 18:05:251763ブラウズ
この記事では、javascript に関する関連知識を紹介します。主に、JavaScript における非同期とコールバックの基本的な概念と、コールバック地獄の現象について紹介します。この記事では、主に、非同期とコールバックの基本的な概念を紹介します。 callbacks. 、この 2 つは JavaScript の核となるコンテンツです。一緒に見ていきましょう。皆さんのお役に立てれば幸いです。

[関連する推奨事項: JavaScript ビデオ チュートリアル、Web フロントエンド]
JavaScript の非同期とコールバック
1. はじめに
この記事の内容を学ぶ前に、まず非同期の概念を理解する必要があります。最初に強調すべきことは、本質的な違いがあるということです。 非同期と並列の間。
- パラレルとは、通常、並列コンピューティングを指します。これは、複数の命令が同時に実行されることを意味します。これらの命令は、同じ
CPUの複数のコア、または複数のコアで実行される場合があります。CPU、複数の物理ホスト、さらには複数のネットワーク。 - 同期とは一般に、あらかじめ決められた順序でタスクを実行することを指し、前のタスクが完了した場合にのみ次のタスクが実行されます。
- 非同期 (同期に対応) 非同期とは、
CPUが現在のタスクを一時的に保留し、最初に次のタスクを処理し、コールバック通知を受信した後に前のタスクに戻ることを指します。前のタスク。タスクは実行を継続します。プロセス全体に 2 番目のスレッドが参加する必要はありません。
並列処理、同期、非同期を説明するには、図を使用する方が直感的かもしれません。処理する必要がある 2 つのタスク A と B があるとします。並列、同期、非同期の処理方法は次のようになります。実行方法は次のとおりです。
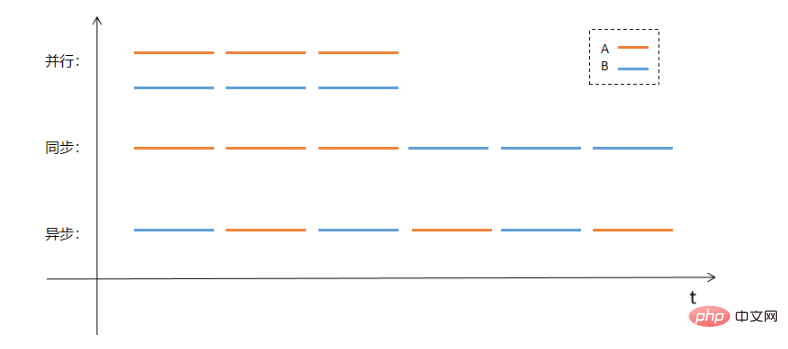
2. 非同期関数
JavaScript は多くの機能を提供します。非同期関数 関数、これらの関数を使用すると、非同期タスクを簡単に実行できます。つまり、今タスク (関数) の実行を開始しますが、タスクは後で完了し、具体的な完了時刻は明確ではありません。
たとえば、setTimeout 関数は非常に典型的な非同期関数です。さらに、fs.readFile と fs.writeFile も非同期です。機能。
ファイル コピー関数 copyFile(from,to):
const fs = require('fs')
function copyFile(from, to) {
fs.readFile(from, (err, data) => {
if (err) {
console.log(err.message)
return
}
fs.writeFile(to, data, (err) => {
if (err) {
console.log(err.message)
return
}
console.log('Copy finished')
})
})
}FunctioncopyFile## のカスタマイズなど、非同期タスク ケースを自分で定義できます。まず、パラメータ from からファイル データを読み取り、次にパラメータ to が指すファイルにデータを書き込みます。
copyFile は次のように呼び出すことができます:
copyFile('./from.txt','./to.txt')//复制文件現時点で
copyFile(...) の背後に他のコードがある場合、プログラム copyFile の実行が終了するのを待たずに、直接実行します。プログラムは、ファイル コピー タスクがいつ終了するかを気にしません。
copyFile('./from.txt','./to.txt') //下面的代码不会等待上面的代码执行结束 ...ここまではすべて正常に見えますが、
copyFile(...) 関数の後にファイル ./to.txt に直接アクセスするとどうなるでしょうか。 の内容にアクセスしますか?
copyFile('./from.txt','./to.txt')
fs.readFile('./to.txt',(err,data)=>{
...
})プログラムを実行する前に ./to.txt ファイルが作成されていない場合は、次のエラーが発生しました:
PS E:\Code\Node\demos\03-callback>node .\index.jsfinished
Copy completed
PS E:\コード \Node\demos\03-callback> ノード .\index.js
エラー: ENOENT: そのようなファイルまたはディレクトリはありません。'E:\Code\Node\demos\03-callback\to.txt' を開いてください
コピー完了
./to.txtが存在しても、コピーした内容は読み取れません。
copyFile(...) は非同期で実行されます。プログラムが copyFile(...) 関数を実行した後、コピーが完了するのを待たずにコピーを直接実行すると、ファイル ./to.txt が存在しないというエラー、またはファイルの内容が空であるというエラーが発生します (ファイルが存在しない場合)あらかじめ作成しておきます)。
3. コールバック関数
非同期関数の具体的な実行終了時刻は決定できません (例:readFile(from,to)##)。 # function 実行終了時間は、ファイル from のサイズに依存する可能性が高くなります。 それでは、問題は、
実行の終わりをどのように正確に見つけて、to ファイルの内容を読み取ることができるかということです。 これにはコールバック関数の使用が必要です。
関数を次のように変更できます: <pre class="brush:js;">function copyFile(from, to, callback) {
fs.readFile(from, (err, data) => {
if (err) {
console.log(err.message)
return
}
fs.writeFile(to, data, (err) => {
if (err) {
console.log(err.message)
return
}
console.log(&#39;Copy finished&#39;)
callback()//当复制操作完成后调用回调函数
})
})
}</pre>このようにして、直後にいくつかの操作を実行する必要がある場合、ファイルのコピーは完了しました。これらの操作をコールバック関数に書き込むことができます。
function copyFile(from, to, callback) {
fs.readFile(from, (err, data) => {
if (err) {
console.log(err.message)
return
}
fs.writeFile(to, data, (err) => {
if (err) {
console.log(err.message)
return
}
console.log('Copy finished')
callback()//当复制操作完成后调用回调函数
})
})
}
copyFile('./from.txt', './to.txt', function () {
//传入一个回调函数,读取“to.txt”文件中的内容并输出
fs.readFile('./to.txt', (err, data) => {
if (err) {
console.log(err.message)
return
}
console.log(data.toString())
})
})./from.txt ファイルを準備している場合は、上記のコードを直接実行できます。 : <blockquote><p>PS E:\Code\Node\demos\03-callback> node .\index.js<br>Copy finished<br>加入社区“仙宗”,和我一起修仙吧<br>社区地址:http://t.csdn.cn/EKf1h</p></blockquote>
<p>这种编程方式被称为“基于回调”的异步编程风格,异步执行的函数应当提供一个回调参数用于在任务结束后调用。</p>
<p>这种风格在<code>JavaScript编程中普遍存在,例如文件读取函数fs.readFile、fs.writeFile都是异步函数。
四、回调的回调
回调函数可以准确的在异步工作完成后处理后继事宜,如果我们需要依次执行多个异步操作,就需要嵌套回调函数。
案例场景:依次读取文件A和文件B
代码实现:
fs.readFile('./A.txt', (err, data) => {
if (err) {
console.log(err.message)
return
}
console.log('读取文件A:' + data.toString())
fs.readFile('./B.txt', (err, data) => {
if (err) {
console.log(err.message)
return
}
console.log("读取文件B:" + data.toString())
})
})执行效果:
PS E:\Code\Node\demos\03-callback> node .\index.js
读取文件A:仙宗无限好,只是缺了佬读取文件B:要想入仙宗,链接不能少
http://t.csdn.cn/H1faI
通过回调的方式,就可以在读取文件A之后,紧接着读取文件B。
如果我们还想在文件B之后,继续读取文件C呢?这就需要继续嵌套回调:
fs.readFile('./A.txt', (err, data) => {//第一次回调
if (err) {
console.log(err.message)
return
}
console.log('读取文件A:' + data.toString())
fs.readFile('./B.txt', (err, data) => {//第二次回调
if (err) {
console.log(err.message)
return
}
console.log("读取文件B:" + data.toString())
fs.readFile('./C.txt',(err,data)=>{//第三次回调
...
})
})
})也就是说,如果我们想要依次执行多个异步操作,需要多层嵌套回调,这在层数较少时是行之有效的,但是当嵌套次数过多时,会出现一些问题。
回调的约定
实际上,fs.readFile中的回调函数的样式并非个例,而是JavaScript中的普遍约定。我们日后会自定义大量的回调函数,也需要遵守这种约定,形成良好的编码习惯。
约定是:
-
callback的第一个参数是为 error 而保留的。一旦出现 error,callback(err)就会被调用。 - 第二个以及后面的参数用于接收异步操作的成功结果。此时
callback(null, result1, result2,...)就会被调用。
基于以上约定,一个回调函数拥有错误处理和结果接收两个功能,例如fs.readFile('...',(err,data)=>{})的回调函数就遵循了这种约定。
五、回调地狱
如果我们不深究的话,基于回调的异步方法处理似乎是相当完美的处理方式。问题在于,如果我们有一个接一个 的异步行为,那么代码就会变成这样:
fs.readFile('./a.txt',(err,data)=>{
if(err){
console.log(err.message)
return
}
//读取结果操作
fs.readFile('./b.txt',(err,data)=>{
if(err){
console.log(err.message)
return
}
//读取结果操作
fs.readFile('./c.txt',(err,data)=>{
if(err){
console.log(err.message)
return
}
//读取结果操作
fs.readFile('./d.txt',(err,data)=>{
if(err){
console.log(err.message)
return
}
...
})
})
})
})以上代码的执行内容是:
- 读取文件a.txt,如果没有发生错误的话;
- 读取文件b.txt,如果没有发生错误的话;
- 读取文件c.txt,如果没有发生错误的话;
- 读取文件d.txt,…
随着调用的增加,代码嵌套层级越来越深,包含越来越多的条件语句,从而形成不断向右缩进的混乱代码,难以阅读和维护。
我们称这种不断向右增长(向右缩进)的现象为“回调地狱”或者“末日金字塔”!
fs.readFile('a.txt',(err,data)=>{
fs.readFile('b.txt',(err,data)=>{
fs.readFile('c.txt',(err,data)=>{
fs.readFile('d.txt',(err,data)=>{
fs.readFile('e.txt',(err,data)=>{
fs.readFile('f.txt',(err,data)=>{
fs.readFile('g.txt',(err,data)=>{
fs.readFile('h.txt',(err,data)=>{
...
/*
通往地狱的大门
===>
*/
})
})
})
})
})
})
})
})虽然以上代码看起来相当规整,但是这只是用于举例的理想场面,通常业务逻辑中会有大量的条件语句、数据处理操作等代码,从而打乱当前美好的秩序,让代码变的难以维护。
幸运的是,JavaScript为我们提供了多种解决途径,Promise就是其中的最优解。
【相关推荐:javascript视频教程、web前端】
以上がJavaScriptにおける非同期とコールバックの基本概念とコールバック地獄現象の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。