
ホームページ >テクノロジー周辺機器 >AI >Huake らは、人間が踊るビデオ生成のための新しいフレームワークである UniAnimate を提案しました。
Huake らは、人間が踊るビデオ生成のための新しいフレームワークである UniAnimate を提案しました。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBオリジナル
- 2024-06-09 11:10:581121ブラウズ

AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。送信メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com

論文アドレス: https://arxiv.org/abs/2406.01188 プロジェクトホームページ: https://unianimate.github.io/

追加の参照ネットワークは必要ありません: UniAnimate フレームワークは、統合されたビデオ拡散モデルを通じて追加の参照ネットワークへの依存を排除し、トレーニングの困難さとモデルの数を軽減します。パラメータの。 追加の参照条件として参照画像のポーズ マップを導入します。これにより、ネットワークが参照ポーズとターゲット ポーズの間の対応を学習し、良好な見かけの位置合わせが実現されます。 統合されたフレームワーク内で長いシーケンスビデオを生成する: 統合されたノイズ入力を追加することで、UniAnimate はフレーム内で長時間のビデオを生成できるようになり、従来の方法の時間制約を受けなくなりました。 高い一貫性: UniAnimate フレームワークは、最初のフレームを後続のフレームを生成する条件として繰り返し使用することで、生成されたビデオのスムーズなトランジション効果を保証し、ビデオの外観をより一貫性と一貫性のあるものにします。この戦略では、ユーザーが複数のビデオ クリップを生成し、良好な結果が得られたクリップの最後のフレームを次に生成されるクリップの最初のフレームとして選択することもできるため、ユーザーはモデルを操作し、必要に応じて生成結果を調整することが容易になります。ただし、前の時系列オーバーラップのスライディング ウィンドウ戦略を使用して長いビデオを生成する場合、拡散プロセスの各ステップで各ビデオが互いに結合されるため、セグメントの選択を実行できません。










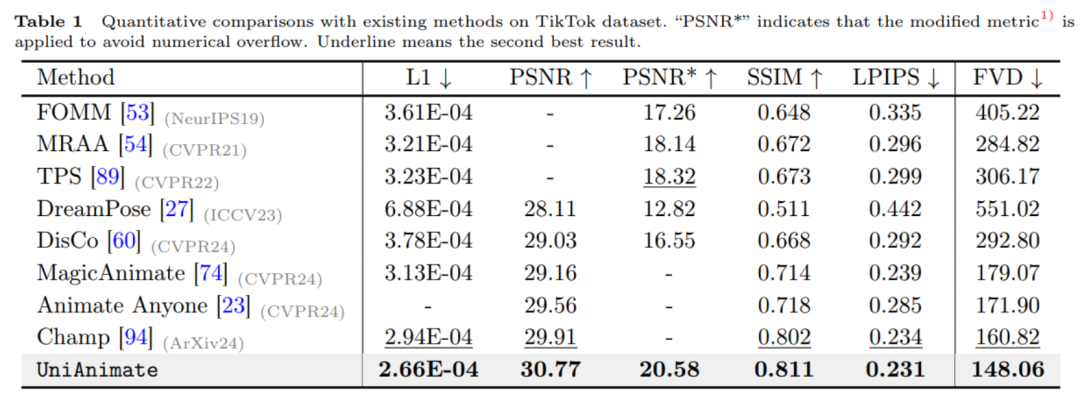

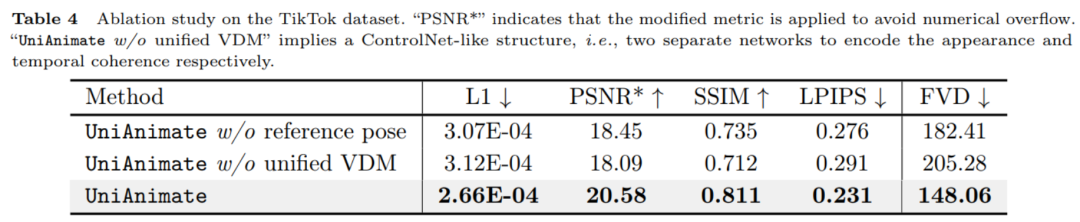

以上がHuake らは、人間が踊るビデオ生成のための新しいフレームワークである UniAnimate を提案しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
声明:
この記事の内容はネチズンが自主的に寄稿したものであり、著作権は原著者に帰属します。このサイトは、それに相当する法的責任を負いません。盗作または侵害の疑いのあるコンテンツを見つけた場合は、admin@php.cn までご連絡ください。