
ホームページ >テクノロジー周辺機器 >AI >CLIP は、RNN として使用すると CVPR として選択されます。トレーニングなしで無数の概念をセグメント化できます。オックスフォード大学と Google Research
CLIP は、RNN として使用すると CVPR として選択されます。トレーニングなしで無数の概念をセグメント化できます。オックスフォード大学と Google Research

- PHPzオリジナル
- 2024-06-09 12:53:28603ブラウズ
ループ内で CLIP を呼び出して、追加のトレーニングなしで無数の概念を効果的にセグメント化します。
映画のキャラクター、ランドマーク、ブランド、一般的なカテゴリを含む任意のフレーズ。
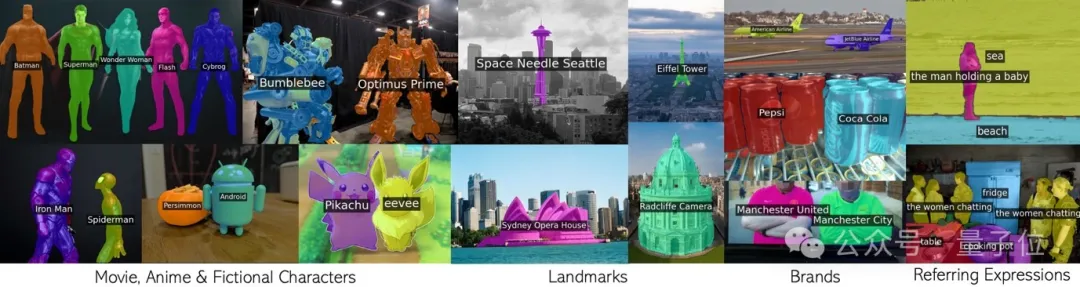
オックスフォード大学と Google Research の共同チームによるこの新しい成果は CVPR 2024 に承認され、コードはオープンソース化されました。

チームは、CLIP as RNN (略して CaR) と呼ばれる新しいテクノロジーを提案しました。これは、オープンボキャブラリー画像セグメンテーションの分野におけるいくつかの重要な問題を解決します:
- トレーニング データは必要ありません: 従来の方法では大量のデータが必要です。微調整用のマスク アノテーションまたは画像テキスト データセットを使用すると、CaR テクノロジーは追加のトレーニング データなしで機能します。
- オープンボキャブラリーの制限: 事前トレーニングされたビジュアル言語モデル (VLM) は、微調整後のオープンボキャブラリーを処理する能力に制限があります。 CaR テクノロジーは、VLM の幅広い語彙空間を保存します。
- 画像に存在しない概念のテキスト クエリ処理: 微調整を行わないと、VLM が画像に存在しない概念を正確にセグメント化することは困難です。CaR は、セグメンテーションの品質を向上させるための反復プロセスを通じて徐々に最適化されます。
RNN からインスピレーションを受け、CLIP を周期的に呼び出します
CaR の原理を理解するには、まずリカレント ニューラル ネットワーク RNN を確認する必要があります。
RNN は、過去のタイムステップからの情報を保存する「メモリ」のような隠れ状態の概念を導入します。また、各タイム ステップは同じ重みセットを共有するため、シーケンス データを適切にモデル化できます。
RNN からインスピレーションを受けて、CaR も循環フレームワークとして設計されており、次の 2 つの部分で構成されます:
- マスク提案ジェネレーター: CLIP を使用して各テキスト クエリのマスクを生成します。
- マスク分類子: 次に、CLIP モデルを使用して、生成された各マスクと対応するテキスト クエリの一致度を評価します。一致度が低い場合には、テキストクエリは除外される。
このように繰り返し続けることで、テキストクエリはますます正確になり、マスクの品質はますます高くなります。
最後に、クエリセットが変更されなくなったら、最終的なセグメンテーション結果を出力できます。

この再帰フレームワークが設計された理由は、CLIP の事前トレーニングの「知識」を最大限に保持するためです。
CLIP の事前トレーニングでは、有名人、ランドマークからアニメのキャラクターに至るまで、あらゆるものを網羅する多くのコンセプトが見られます。分割されたデータセットを微調整すると、語彙は大幅に縮小することは間違いありません。
たとえば、「すべてを分割する」SAM モデルはコカ・コーラのボトルのみを認識できますが、ペプシ・コーラのボトルさえも認識できません。

しかし、セグメンテーションにCLIPを直接使用すると、その効果は満足のいくものではありません。
これは、CLIP の事前トレーニング目標がもともと密な予測を目的として設計されていないためです。特に特定のテキストクエリが画像に存在しない場合、CLIP は間違ったマスクを簡単に生成する可能性があります。
CaR は、RNN スタイルの反復を通じてこの問題を巧みに解決します。マスクを改善しながらクエリの評価とフィルタリングを繰り返すことで、最終的に高品質のオープンボキャブラリーセグメンテーションが実現します。
最後に、チームの解釈に従い、CaR フレームワークの詳細について学びましょう。
CaR の技術詳細
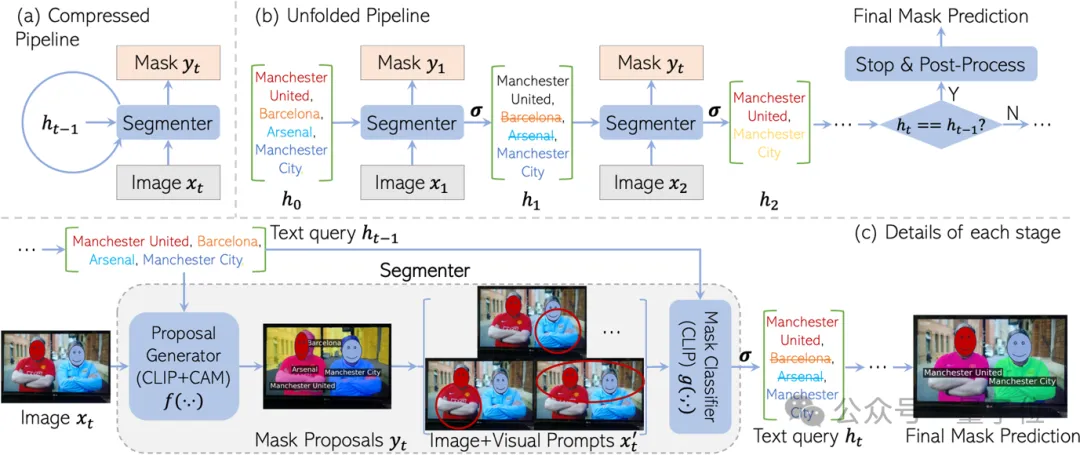
- リカレント ニューラル ネットワーク フレームワーク: CaR は、反復プロセスを通じてテキスト クエリと画像間の対応を継続的に最適化する新しい循環フレームワークを採用しています。
- 2 段階セグメンター: マスク提案ジェネレーターとマスク分類器で構成され、どちらも事前トレーニングされた CLIP モデルに基づいて構築され、反復プロセス中に重みは変更されません。
- マスク提案の生成: gradCAM テクノロジーを使用して、画像とテキストの特徴の類似性スコアに基づいてマスク提案が生成されます。
- 視覚的なキュー: 赤い円、背景のぼかしなどの視覚的なキューを適用して、画像の特定の領域に対するモデルの焦点を強調します。
- しきい値関数: 類似性のしきい値を設定することにより、テキスト クエリと高度に一致するマスク提案が除外されます。
- 後処理: 高密度条件付きランダムフィールド (CRF) とオプションの SAM モデルを使用したマスクの改良。
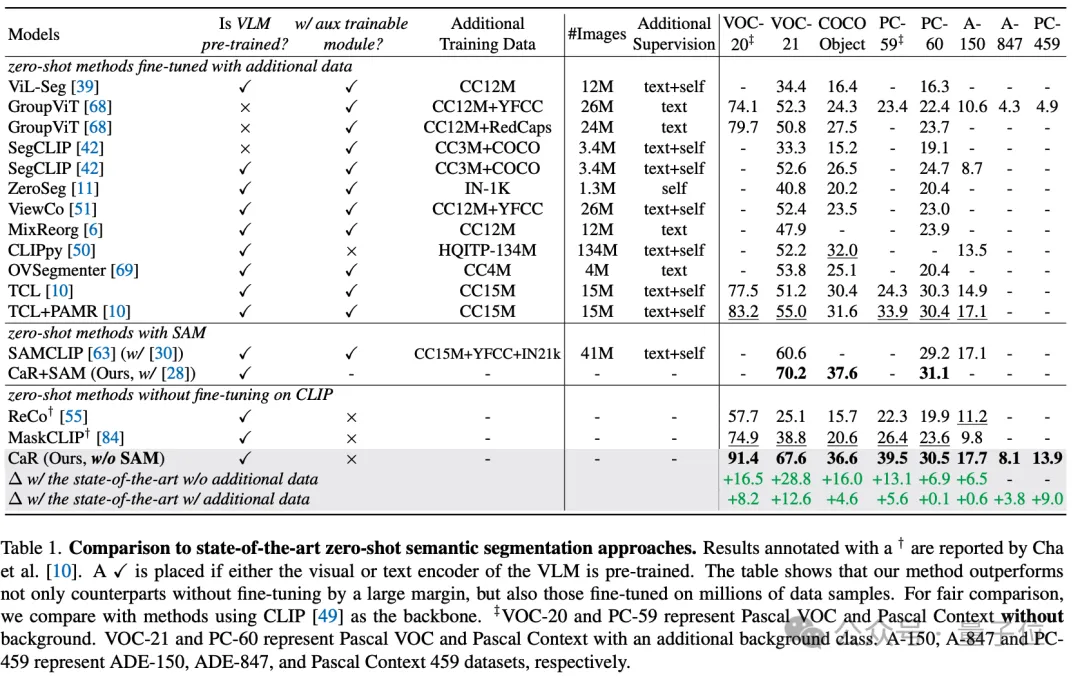
これらの技術的手段により、CaR テクノロジーは複数の標準データセットで大幅なパフォーマンス向上を達成し、従来のゼロショット学習方法を超え、また、大規模なデータ微調整が行われたモデルと比較して優れたパフォーマンスを示し、競争力を高めました。以下の表に示すように、追加のトレーニングや微調整は必要ありませんが、CaR は、追加のデータで微調整された以前の方法よりも、ゼロショット セマンティック セグメンテーションの 8 つの異なる指標で優れたパフォーマンスを示します。
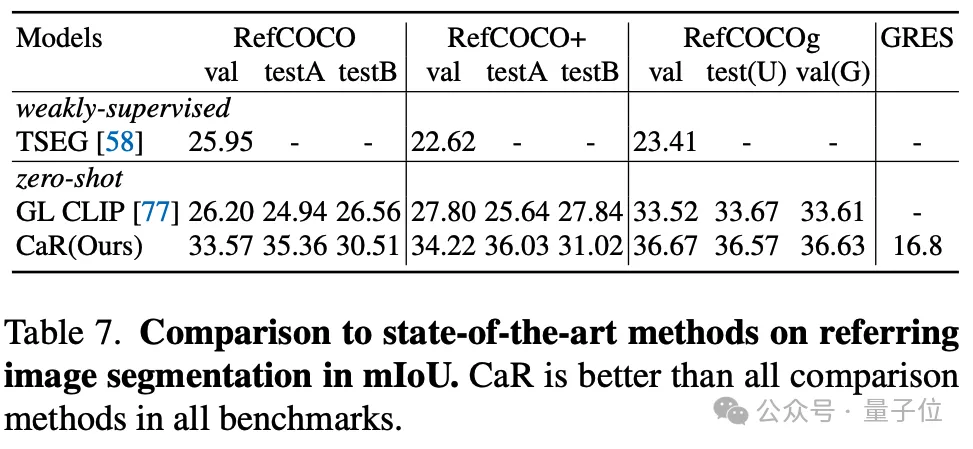
著者は、ゼロサンプル参照セグメンテーションに対する CaR の効果もテストしました。CaR も、以前のゼロサンプル手法よりも強力なパフォーマンスを示しました。
要約すると、CaR (RNN としての CLIP) は、追加のトレーニング データなしでゼロショットのセマンティックおよび参照画像セグメンテーション タスクを効果的に実行できる革新的なリカレント ニューラル ネットワーク フレームワークです。事前トレーニングされた視覚言語モデルの広範な語彙空間を維持し、反復プロセスを活用してテキスト クエリとマスク提案の位置合わせを継続的に最適化することで、セグメンテーションの品質が大幅に向上します。
CaR の利点は、微調整せずに複雑なテキスト クエリを処理できる能力と、ビデオ分野への拡張性であり、オープン ボキャブラリーの画像セグメンテーションの分野に画期的な進歩をもたらします。
紙のリンク: https://arxiv.org/abs/2312.07661。
プロジェクトのホームページ: https://torrvision.com/clip_as_rnn/。
以上がCLIP は、RNN として使用すると CVPR として選択されます。トレーニングなしで無数の概念をセグメント化できます。オックスフォード大学と Google Researchの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。