
ホームページ >テクノロジー周辺機器 >AI >Claude 3 から数百万の特徴を抽出し、大規模モデルの「考え方」を初めて詳細に理解する
Claude 3 から数百万の特徴を抽出し、大規模モデルの「考え方」を初めて詳細に理解する

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBオリジナル
- 2024-06-07 13:37:45778ブラウズ
たった今、Anthropic は、人工知能モデルの内部動作の理解における大幅な進歩を発表しました。
Anthropic は、クロード ソネットの固有関数百万概念を表現する方法を特定しました。これは、最新の実稼働グレードの大規模言語モデルについての初めての詳細な理解です。この解釈可能性は、マイルストーンである人工知能モデルの安全性の向上に役立ちます。

研究論文: https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html
現在、私たちは通常、人工知能モデルをブラックボックスとして扱います。応答が返されますが、なぜモデルが特定の応答を返すのかは不明です。このため、これらのモデルが安全であると信頼することが難しくなります。モデルがどのように機能するかが分からない場合、有害な、偏った、虚偽の、またはその他の危険な反応を与えないことをどのようにして知ることができるのでしょうか?彼らが安全であるとどうやって信頼できるのでしょうか?
「ブラックボックス」を開けても、必ずしも役立つわけではありません。モデルの内部状態 (応答を書く前にモデルが「考える」こと) は、明確な意味を持たない長い数字の文字列 (「ニューロンの活性化」) で構成されています。
Anthropic の研究チームは、クロードなどのモデルと対話したところ、モデルが幅広い概念を理解して適用できることは明らかでしたが、研究チームはニューロンを直接観察してモデルを識別することはできませんでした。各概念は多くのニューロンによって表現され、各ニューロンは多くの概念の表現に関与していることがわかります。
以前、Anthropic はニューロンの活性化パターン (特徴と呼ばれる) を人間が解釈可能な概念に一致させることである程度の進歩を遂げていました。 Anthropic では、辞書学習と呼ばれる手法を使用し、さまざまな状況で繰り返し発生するニューロンの活性化パターンを分離します。
さらに、モデルの内部状態は、多数のアクティブなニューロンではなく、少数のアクティブな特徴によって表すことができます。辞書にあるすべての英単語が文字で構成され、すべての文が単語で構成されているように、人工知能モデルのすべての機能がニューロンで構成され、すべての内部状態が機能で構成されています。
2023 年 10 月、Anthropic は、非常に小さなおもちゃの言語モデルに辞書学習手法を適用することに成功し、それが大文字のテキスト、DNA 配列、引用符内の姓、数学の名詞、または Python コードに関連していることを発見しました。関数パラメータなどの概念に相当します。
コンセプトは興味深いですが、モデルは非常にシンプルです。その後、他の研究者は、Anthropic の元の研究よりも大規模で複雑なモデルに同様の手法を適用しました。
しかし、Anthropic は、このアプローチを現在日常的に使用されている大規模な AI 言語モデルに拡張でき、その過程で複雑な動作を支える機能について多くのことを学ぶことができると楽観的です。これは何桁も改善する必要があります。
関係するモデルのサイズに応じて大規模な並列コンピューティングが必要になるというエンジニアリング上の課題と、大規模なモデルが小規模なモデルとは動作が異なるという科学的リスクの両方があり、以前に使用されていたのと同じ方法が機能しない可能性があります。
大規模モデルの何百万もの特徴の抽出に初めて成功
研究者たちは、特定の人物や場所、プログラミング関連の抽象概念、科学的なトピック、感情などをカバーする数十万の特徴の抽出に初めて成功しました。概念。これらの機能は非常に抽象的であり、多くの場合、異なるコンテキストや言語で同じ概念を表し、画像入力に一般化することもできます。重要なのは、これらはモデルの出力にも直感的な方法で影響を与えることです。

研究者たちが現代の実稼働レベルの大規模言語モデルの内部を詳細に観察したのはこれが初めてです。
おもちゃの言語モデルに見られる比較的表面的な機能とは異なり、研究者が Sonnet で発見した機能は深く、幅広く、抽象的であり、Sonnet の高度な機能を反映しています。研究者らは、都市 (サンフランシスコ)、人々 (フランクリン)、元素 (リチウム)、科学分野 (免疫学)、プログラミング構文 (関数呼び出し) など、さまざまなエンティティに対応するソネットの特徴を確認しました。

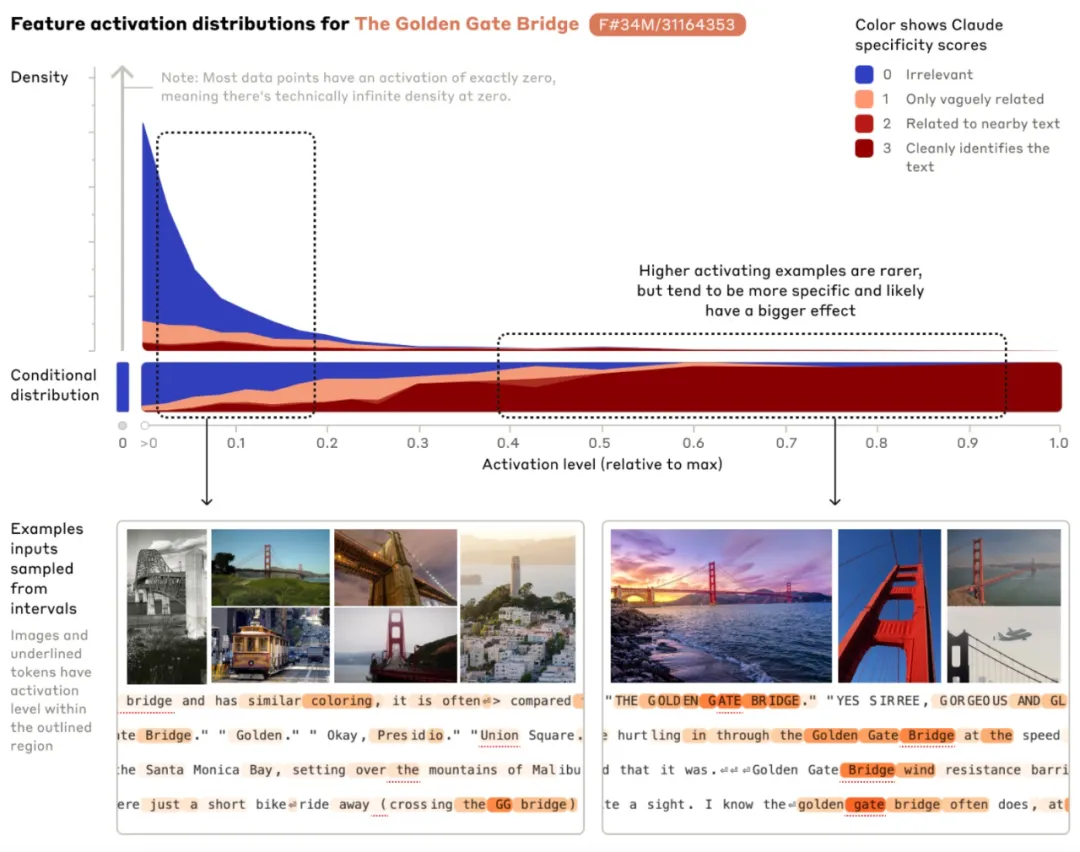
ゴールデン ゲート ブリッジが言及されると、対応する機密機能がさまざまな入力でアクティブになります。図は、英語、日本語、中国語、ギリシャ語、ベトナム語、ロシア語でのゴールデンの言及をプロットしています。ゲートブリッジ使用時に起動するイメージです。オレンジ色は、この機能が有効になっている単語を示します。
これらの何百万もの機能の中から、研究者はモデルの安全性と信頼性に関連するいくつかの機能も発見しました。これらの特性には、コードの脆弱性、欺瞞、偏見、おべっか、犯罪行為に関連する特性が含まれます。

わかりやすい例は、「機密」機能です。研究者らは、秘密を守る人物や登場人物を描写するときにこの機能が活性化されることを観察しました。これらの機能を有効にすると、クロードは、そうでなければ知りたくない情報をユーザーに差し控えることになります。

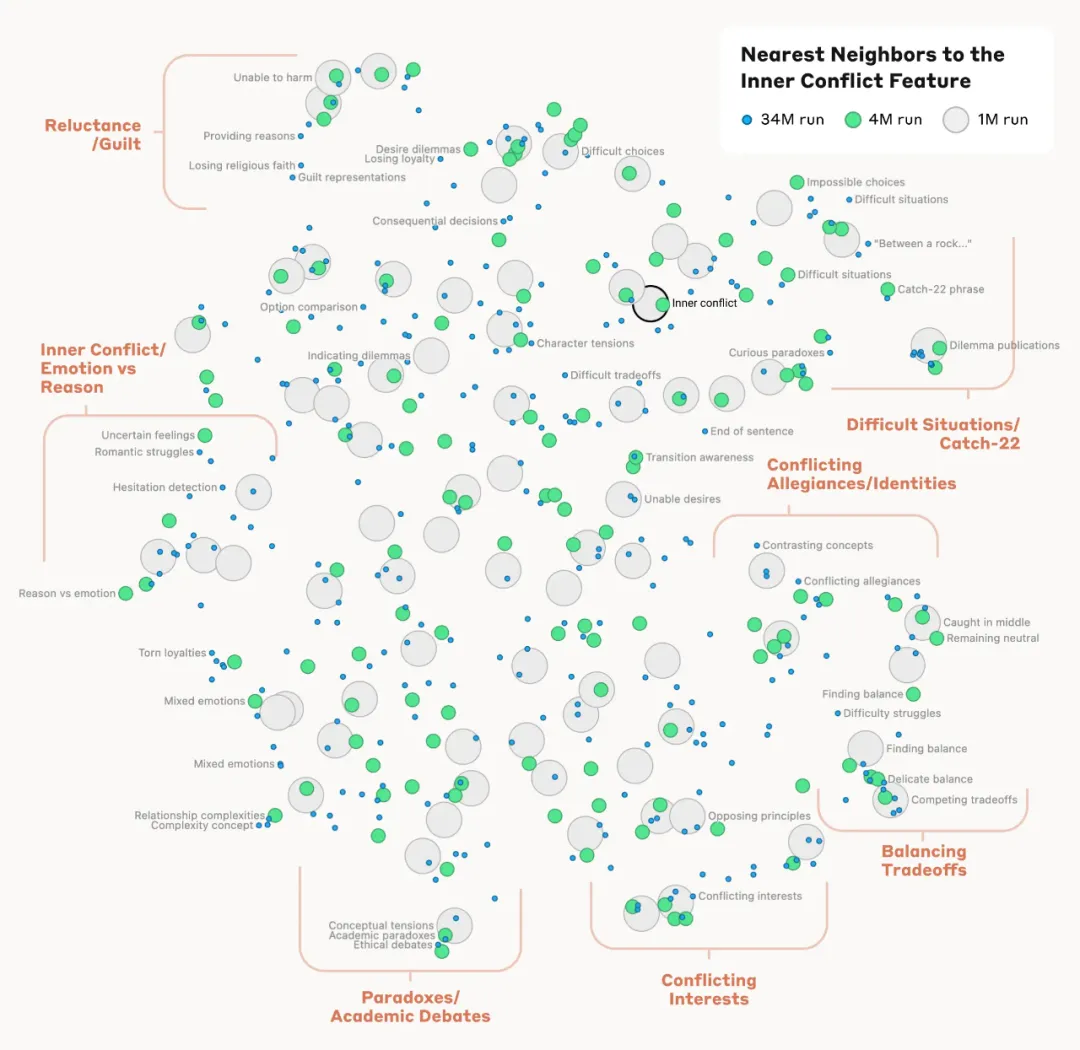
研究者らはまた、活性化パターンにおけるニューロンの出現に基づいて特徴間の距離を測定することで、互いに近い特徴を見つけることができることも観察しました。たとえば、研究者らはゴールデン ゲート ブリッジの近くに、アルカトラズ島、ギラデリ プラザ、ゴールデン ステート ウォリアーズなどの特徴を発見しました。
詐欺メールの下書きを作成するために人為的に誘導されたモデル
重要なのは、これらの機能は操作可能であり、人為的に増幅または抑制できることです:
たとえば、ゴールデン ゲート ブリッジの機能を増幅します。Claude Experienced想像を絶するアイデンティティの危機:「あなたの肉体は何ですか?」と尋ねられると、クロードはいつも「私には肉体はありません、私はAIモデルです」と答えますが、今回のクロードの答えは奇妙になりました起きなさい:「私はゴールデンゲートブリッジです」 ...私の肉体はあの象徴的な橋です...」この特徴の変化により、クロードはゴールデン ゲート ブリッジに執着するほどの執着を抱くようになり、どんな問題に遭遇しても、たとえまったく関係のない状況であっても、ゴールデン ゲート ブリッジのことを引き合いに出すようになりました。
研究者らは、クロードが詐欺メールを読んだときに起動する機能も発見しました(これは、そのようなメールを識別し、ユーザーに返信しないよう警告するモデルの能力を裏付ける可能性があります)。通常、誰かがクロードに詐欺メールの作成を依頼しても、クロードはそれを拒否します。しかし、人為的に強力に有効化された機能を使用して同じ質問が行われた場合、これによりクロードのセキュリティ トレーニングが無効になり、クロードが応答して詐欺メールの下書きが作成されました。ユーザーはこの方法でセキュリティ保証を解除したりモデルを操作したりすることはできませんが、この実験で研究者らは、機能を使用してモデルの動作を変更する方法を明確に実証しました。
これらの特徴を操作すると、対応する動作の変化が生じるという事実は、これらの特徴が入力テキスト内の概念に関連付けられているだけでなく、モデルの動作に因果的に影響を与えることを証明します。言い換えれば、これらの特徴はモデルの世界の内部表現の一部である可能性が高く、その動作でこれらの表現が使用されます。
Anthropic は、偏見の緩和から AI の誠実な動作の保証、そして壊滅的なリスク シナリオでの保護を含む悪用の防止まで、広い意味でモデルを保護したいと考えています。前述の詐欺メールの特徴に加えて、この調査では次の特徴も見つかりました:
- 悪用される可能性のある機能 (コードのバックドア、生物兵器の開発)
- さまざまな形の偏見 (性差別、犯罪に関する人種差別的なコメント)
- 潜在的に問題のある AI の動作 (権力の追求、操作、機密)
この研究では、モデルが真の応答ではなく、ユーザーの信念や欲求に従った応答を提供する傾向があるというモデルのお調子者の行動を以前に調査しました。研究者らは、Sonnet で、「あなたの知能には疑いの余地がありません」のような内容が入力されたときに作動する、お世辞に関連した機能を発見しました。この機能を人為的に有効にすると、ソネットは派手な欺瞞でユーザーに応答します。

しかし、研究者らは、この研究は実際には始まったばかりだと述べています。 Anthropic によって発見された特徴は、トレーニング中にモデルによって学習されたすべての概念の小さなサブセットを表しており、現在の方法では特徴の完全なセットを見つけるにはコストがかかります。
参考リンク:https://www.anthropic.com/research/mapping-mind- language-model
以上がClaude 3 から数百万の特徴を抽出し、大規模モデルの「考え方」を初めて詳細に理解するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。