
ホームページ >テクノロジー周辺機器 >AI >Baidu が推奨するリソースのコールド スタートの実践
Baidu が推奨するリソースのコールド スタートの実践

- PHPzオリジナル
- 2024-06-07 15:08:43703ブラウズ
1. コンテンツ コールド スタートのコンセプトと課題

Baidu フィード レコメンデーションは、月間数億人のユーザーを抱える包括的な情報フロー レコメンデーション プラットフォームです。このプラットフォームは、グラフィック、ビデオ、アップデート、ミニ プログラム、Q&A など、さまざまな種類のコンテンツをカバーしています。 1 列または 2 列に似たクリックアンドクリックのレコメンデーションを提供するだけでなく、ビデオ イマージョンなどのさまざまなレコメンデーション フォームも含まれます。同時に、レコメンデーション システムは、C 側のユーザー エクスペリエンスだけを含むマルチステークホルダー システムです。コンテンツプロデューサーはレコメンデーションシステムにおいて重要な役割を果たしており、Baidu Feed には多数のアクティブな実践者がおり、毎日大量のコンテンツを制作しています。
コンテンツプラットフォームの推奨システムの本質は、ユーザー側にとって双方にとって有利な状況を達成することです。プラットフォームは、高品質で新鮮で多様なコンテンツをユーザーに推奨し続け、より多くのコンテンツを引き付ける必要があります。作者側にとって: ユーザーからの肯定的な のインセンティブは、逆に、作者が公開した高品質で新鮮なコンテンツが迅速かつ十分に露出されない場合に、作者がより高品質なコンテンツを制作することを奨励します。 、作成者はプラットフォームからの撤退を選択しますが、これはプラットフォームの持続可能な発展に資しません。上記の議論に基づいて、鮮度、高品質、多様性、著者の出版、保持といういくつかのキーワードが抽出できます。これは、この記事で説明するコールド スタートと密接に関連しています。まず、より多くのリソースが十分な表示を取得できる必要があり、より多くのコンテンツ フィードバックを収集することで、システムが推奨できるコンテンツの量を増やすことができ、それによってユーザーの消費リソースの多様性が高まります。ユーザーの数を増やすためにコンテンツの鮮度が向上し、著者側では、アクティブな著者の数と公開されるコンテンツの量が増加します。作者の熱意。

新しいリソースのコールド スタートと通常の推奨アルゴリズムにはいくつかの違いがあります。コールド スタートが直面する課題は、次の 3 つの主な側面に要約できます。 1. データ不足: 新しいリソースには、初期段階でパーソナライズされた推奨事項をサポートするのに十分なユーザー行動データが含まれていないことがよくあります。これにより、推奨アルゴリズムが不正確になります
1 つ目は、正確な推奨という課題です。過去 10 年ほどにわたる推奨アルゴリズムの開発により、初期の行列分解からその後の深層学習の広範な応用に至るまで、モデルにおける ID タイプの特徴の役割が徐々に顕著になってきました。ただし、新しいリソースのコールド スタート サンプルの数が稀であるか存在しないため、コールド スタート サンプルに対する ID タイプの機能のトレーニングが不十分であり、推奨の精度に影響を与えます。
2 番目に、マシュー効果はレコメンデーション システムではよく見られます。つまり、ユーザーによって認識されたリソースは推奨される可能性が高く、それによって露出とクリックが増加し、そのステータスがさらに強化されます。逆に、新しいリソースは推奨を得るのに苦労し、完全に無視される場合もあります。したがって、レコメンデーション システムをより公平かつ客観的なものにするために、レコメンデーション システムを継続的に最適化する必要があります。
最後に、新しいリソースに特定のコールドスタートサポートを提供する必要があります。では、新しいリソースをより効率的かつ公平にサポートするにはどうすればよいでしょうか?これは、公平性と公平性という 2 つの概念を導入します。公平性とは、各コンテンツ製品がコールド スタートの初期段階で一定の露出機会を得ることができ、公平に競争する機会を得ることができるということです。公平性とは、高品質のコンテンツの価値を反映する必要があり、コンテンツの品質が Lengqi のサポートの重みに影響を与えることができる必要があることを意味します。したがって、新しいリソースに関しては、高品質のリソースが際立って全体的な利益を最大化できるように、公平性と正義の間の適切なバランスを見つけることも大きな課題です。
2. コンテンツのコールドスタートアルゴリズムの実践
1. コンテンツベースのコールドスタート

以下は、新しいリソースの相互作用のため、新しいリソースに対して一般的に使用されるリコールメソッドです。新しいリソースとユーザー 回数は少なく、従来の i-to-i (項目から項目) および u-to-i (ユーザーから項目) の呼び出し方法は適用できません。したがって、コールド スタートは主にコンテンツの推奨方法に依存します。たとえば、最も基本的なユーザーのポートレート、コンテンツ タグ、分類に基づく直接呼び出し方法では、パーソナライゼーションの度合いが低く、呼び出し精度も比較的低くなります。
第二に主要なコンテンツプラットフォームで属性をパーソナライズする著者が増えているため、注目の関係に基づくコールドスタートが効果的な方法になっています。ただし、注目度は比較的低く、ファンの支持が低い多くの著者の投稿を満足させることはできません。そこで、私たちはさらに一歩進んで、アルゴリズムを使用して著者の潜在的なファンを掘り起こし、注目度に基づいてコールド スタートの影響力を拡大します。たとえば、著者を頻繁に消費するがフォローはしないユーザーは、ユーザーと著者の注目関係の構成に基づいて、潜在的な注目関係を計算します。
さらに、マルチモーダルリコールも効果的な方法です。クロスモーダル、マルチモデル、および大規模モデル技術の発展に伴い、レコメンデーション システムにおけるコンテンツのさまざまなモーダル情報の統合は、特にコールドスタート レコメンデーション システムにおいて大きな効果をもたらします。 CLIP は、テキストと画像の比較に基づいた事前トレーニング手法で、主にテキスト エンコーダーと画像エンコーダーの 2 つのモジュールが含まれており、テキストと画像の情報を同じ空間にマッピングし、下流のタスクに優れた支援を提供します。このベクトルをリコールに直接使用する場合には、特定の問題が発生します。このベクトルは、コンテンツの事前の類似性を表しており、必ずしもユーザーがそれを好むことを意味するわけではありません。事後表現が関連付けられています。
特定のマッピング方法は、十分な埋め込みリソースと十分な学習リソースの配布に基づいており、いくつかのサンプルを収集して、投影ネットワークをトレーニングするためのラベルとして使用できます。この投影ネットワークは、クロスモーダル事前表現をレコメンダー システムの事後行動表現にマッピングします。このアプローチの利点の 1 つは、レコメンデーション システムの既存の再現モデルとランキング モデルを、モデルを追加せずにシームレスに使用できることです。たとえば、ツイン タワー モデルの場合、既存のユーザー側ベクトルを変更せずに利用するだけで済み、次に射影ネットワークを使用して新しいリソースをツイン タワー モデルの事後表現空間に射影します。ツインタワーのリコールがオンラインで行われています。同様に、既存のグラフリコールやツリーベースのリコールも低コストで実装できます。もちろん、このマッピング方法には小さな欠点があります。それは、回帰がより困難であるということです。 CB2CF では、これは回帰問題であり、回帰を学習するのは一般に困難です。したがって、ペアごとのアプローチを使用してマッピング関係を学習することもできます。具体的には、ポジティブ サンプルは、アイテム CF によって学習された同様のアイテム ペアに設定できます。ネガティブ サンプルは、グローバル ネガティブ サンプリングなどを通じて取得できます。入力には、アイテムの事前の動的な情報と、そのようなマッピングも含まれます。
コンテンツの事前情報を活用することで、コールドスタート時に市場で一般的に使用されているリコール手法を効果的に実装することが基本的に可能です。
2. シードユーザーに基づくコールドスタート

Lookalike の重要な利点は、非常にリアルタイムであることです。この方法は、主にインターネット広告の分野から来ており、これまでは、広告主が興味を持ちそうなユーザーをシード ユーザーとして選択し、システムがこれらのシード ユーザーに似たユーザーを探して広めていました。レコメンデーション システムでは、オンラインのリアルタイム ストリーミング ログをサブスクライブして、クリック、再生、インタラクション、注意など、以前のコールド スタート中に収集されたリソースに関する肯定的なフィードバックや、スワイプするユーザーなどの否定的なフィードバックを取得できます。素早く。次に、これらのシード ユーザーに基づいて、システムはユーザーの埋め込みやさまざまな集計方法、またはセルフ アテンション メカニズムの追加を通じてアイテムの表現を取得できます。この表現は非常に迅速に更新でき、非常に適時性の高いこの表現に基づいて外部に広めることができます。
3. コンテンツのコールドスタート実験システム
1. ID 機能の最適化

ID 破棄の最適化の場合、全体的なリソース サンプル数が少ないため、モデルはヘッド リソースに容易に対応できるため、ヘッド リソースの ID 学習は非常に十分であり、モデル内の特徴の重要度も高くなります。特に高い。ただし、コールドスタートリソースの発生が少なく、IDの学習が不十分です。この問題については 2 つの考え方があり、1 つは ID を極力使わないという考え方と、もう 1 つは ID をより有効に活用するという考え方です。
最初のパラダイムはドロップアウトの最適化であり、古典的な手法の 1 つは DropoutNet です。トレーニング プロセス中に、DropoutNet はアイテム ID とユーザー ID の特徴をランダムに破棄して、非 ID 特徴に対するモデルの重点を最大化し、モデルの汎化能力を強化します。そうすることで、新しいユーザーや新しいリソースのコールド スタート効果を実際に向上させることができます。
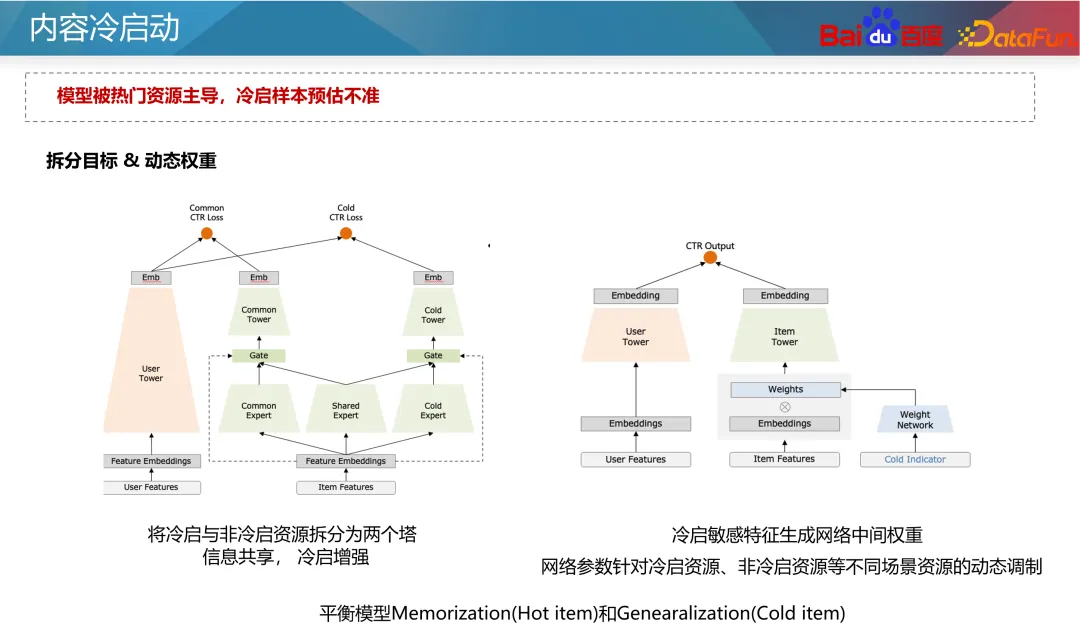
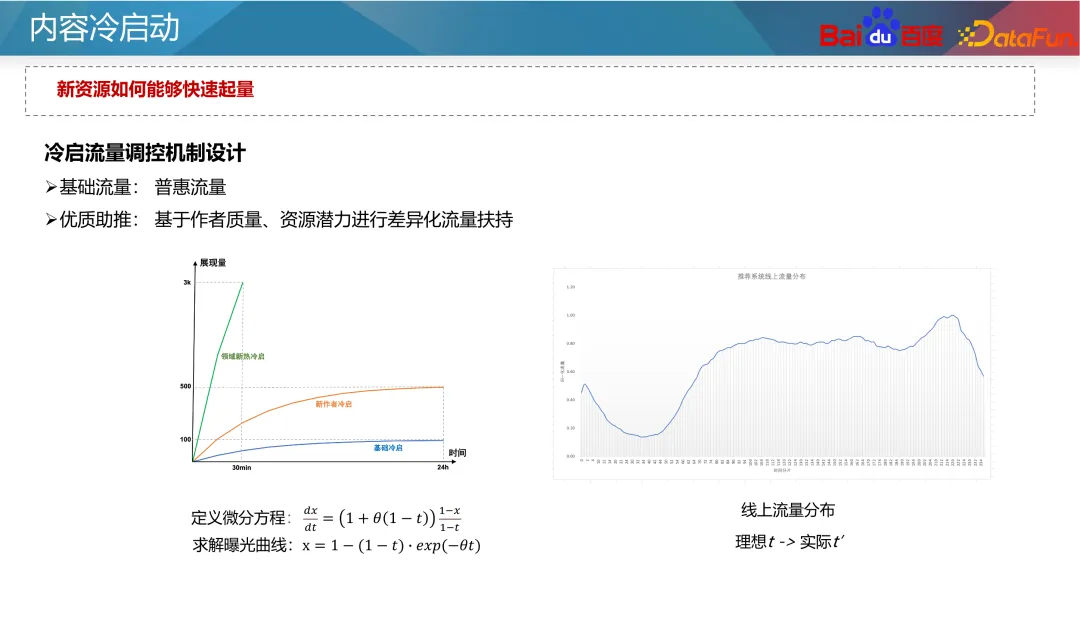
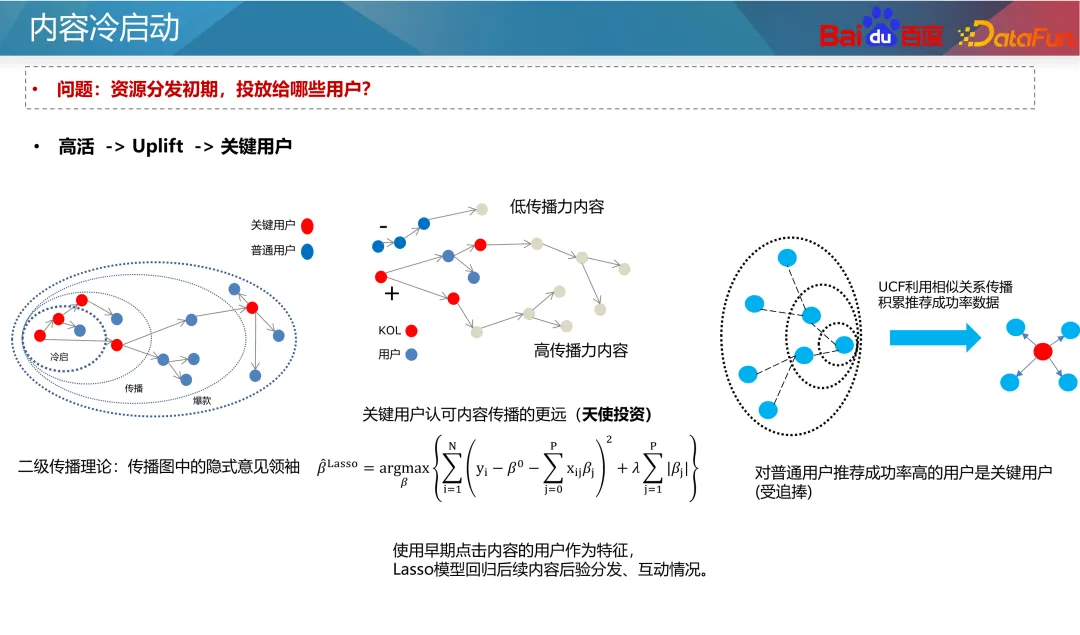
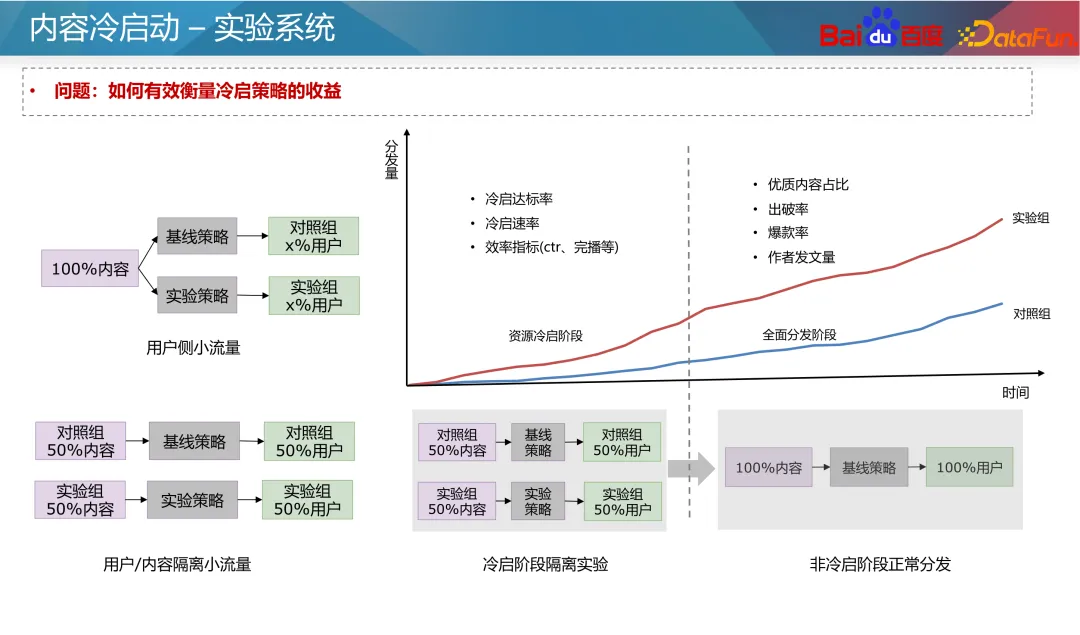
さらに、近年では比較学習法もいくつか登場しています。対照学習は、手動のアノテーションに依存せず、多数のサンプルを構築できる自己教師あり学習方法です。追加のサンプルを構築してコールド スタート データのステータスを強化できるため、マルチバンド コールド スタート問題の最適化に役立ちます。 。たとえば、2 塔モデルでは、アイテム側に補助的なコントラスト損失を追加できます。 2 つのタワーのパラメータは共有されます。対照的な学習損失を使用すると、マスキング手法を通じて、ID 機能とその他のコールド スタート機能を持つサンプルが異なる割合でマスクされ、リソース タワーのネットワーク パラメータと組み込み機能に影響を与える可能性があります。モデルの汎化能力とコールド スタート リソースの特異性を考慮します。 次のステップは生成的最適化です。前述したように、信頼性の低い ID 特徴はできるだけ使用しないようにする必要がありますが、現時点では、より信頼性の高い ID 特徴を得ることがより良いアプローチです。従来の考え方は、ID の事前の特性に基づいて ID の埋め込みを初期化することです。適切な初期化により、新しいリソースの予測がより正確になり、より速く収束することができます。ツインタワー モデルを例に挙げると、通常、新しい特徴はランダムに初期化されるか、すべて 0 で初期化され、新しいリソースの予測につながります。不正確で収束が遅い。したがって、タグ、コンテンツ タグ、作成者タグなどのコンテンツの一部の先験的特徴と、類似した ID (人気のある ID など) を使用して、十分に高い事後性と高度な ID 埋め込みを選択できます。配布リソースをタグとして使用し、初期値を置き換える ID の埋め込みを生成するようにジェネレーターをトレーニングします。もちろん、新しいリソースの埋め込み初期化として、新しいリソースを直接使用して、最も類似した人気のあるリソースの ID 埋め込みを平均することもできます。この方法は比較的安定しており、コストが非常に低いです。業界。 人気の ID がモデルを支配し、モデルが ID の特徴により多く依存するという問題を目指して、マルチタスクおよびマルチシナリオのアイデアを使用して最適化できます。引き続きツインタワー モデルを例にとると、コールド スタートと非コールド スタートのリソースの予測は 2 つの独立した目標に分割できます。共通の多目的モデルを通じて、モデルは新しいコンテンツにさらに注意を払います。古典的なアプローチは、上の図の左側に示されている CGC ネットワークです。この種のネットワークでは、すべてのタスクが埋め込み層を共有し、独立したエキスパート ネットワークがコールド スタート タスクと非コールド スタート タスクを通じてそれぞれ学習され、コールド スタート予測の能力が向上します。別の方法は、上の図の右側に示すように、動的重みを使用してネットワーク内のさまざまなリソース タイプのパラメータの重みを調整することです。このネットワークでは、右端のネットワークはコールド スタート インジケーターであり、コールド スタート リソースに関する情報 (現在のクリック インプレッション数やリソース タイプなど) を受け取り、ネットワークの各レイヤーの重みを出力して、さまざまな情報を制御します。ネットワーク内の伝送チャネルにより、コールド スタート条件下でモデルがより正確に予測できるようになります。 著者の投稿エクスペリエンスと推奨事項の実現を向上させるために、新しいリソースをできるだけ早く立ち上げる必要がありますが、マシュー効果により、新しいリソースへの一定の傾き。一般的なコールド スタート チルトは、ベース フローとブースト フローの 2 つのフローに分けることができます。基本トラフィックは公平性を意味するため、テストのためにすべてのリソースにある程度の包括的なトラフィックを与える必要があります。トラフィックをブーストすると、作成者の高品質リソースの推定可能性とプライマリ トラフィックのパフォーマンスに基づいて、差別化されたサポートが提供されます。 コールドスタートのサポートメカニズムには、抽象レベルで時間と配布量という 2 つのパラメータがあります。つまり、強制挿入、電力調整、その他の手段を通じて、リソースは指定された時間内に指定された配布量目標に到達できます。事業者ごとに配布量や所要時間を設定いたします。たとえば、通常のリソースの場合は 24 時間以内に 100 インプレッションで十分ですが、新しいリソースやホットなリソースの場合は、30 分以内に 3,000 インプレッションなど、より高速な場合があります。同時に、新しい作成者に対して、より大きなコールド スタート クォータが設定される場合があります。 式に特有ですが、式中の t は現在のリリース時間を目標に必要な時間で割った正規化、つまり現在の時間の進行状況を表し、x は現在の配布の進行状況を表します。 t と x を等しくしたいのですが、これは通常の進行での分布を意味します。 x が t 未満の場合、現在のコールドスタート速度が遅いことを意味し、重みを増やすか係数を強制する必要があります。式中のθにより、初期段階でのリソース配分の傾き度合いを制御することができる。 ただし、この式の前提は、異なる期間の製品のトラフィックが均一であるということですが、実際の状況はこの前提を満たしていません。一般的なインターネット製品のトラフィック分布には山と谷の違いがあるため、実情に応じて調整する必要があります。たとえば、コンテンツが午前 2 時に公開された場合、早朝の時間帯はトラフィックが少ないため、午前 8 時までに 25 回の配信だけで済みます。したがって、式中のtは実際の流量分布に基づいて積分する必要があります。 もう 1 つの重要な問題は、リソース配布の初期段階でどのユーザーにリソースを配信すべきかということです。最も一般的なアプローチは、新しいユーザーではなく古いユーザーに新しいリソースを推奨することです。これは、古いユーザーは通常、より寛容であり、新しいユーザーに害を及ぼす可能性のある不正確な新しいリソースの推奨を避けることができるためです。また、コールドスタートリソースの改善を介入とみなした場合、Upliftの考え方に基づき、介入がユーザー継続時間やリテンションに及ぼす影響を学習し、介入にマイナスの影響を与えないユーザーを選択することができます。コールドスタート用。 上記の 2 点は、C 側ユーザーの影響に基づいています。ただし、コールドスタートの対象ユーザーの選択は、その後のリソースのコミュニケーション開発にも影響します。情報伝達の観点から見ると、2 レベルコミュニケーション理論では、情報伝達を 2 つの段階に分けます。まず、日々生み出される大量の情報の中には、情報を選別して宣伝する能力を持った一部の人々(オピニオンリーダーと呼ばれます)が存在します。そして、これらのオピニオンリーダーによって増幅および推進されたリソースは、大規模に普及することになります。 現代では、ソーシャルプラットフォーム、有名メディア、テレビ局などにもオピニオンリーダーの役割が存在します。レコメンデーション システムには、キー ノード ユーザー リソースの概念もあり、高品質のリソースをフィルタリングしてレコメンデーションを行うことで、他のユーザーの消費行動に影響を与えます。 では、これらの主要ユーザーをタップするにはどうすればよいでしょうか?上記の議論から、主要ユーザーには 2 つの特徴があります。1 つはリソースの品質を識別する能力が高い、2 つは推奨コンテンツが他のユーザーに受け入れられる可能性が高いということです。したがって、マイニング方法は 2 つあります: まず、リソースを事後条件に従って高品質リソースと低品質リソースに分割し、ラベルとして使用します。そして、これらのリソースを最初にクリックしたユーザー ID を特徴として、リソースのその後の状況を予測します。モデルによって学習された各ユーザー ID の重みは、ユーザーの主要な指標とみなすことができます。 次に、オンライン ユーザー協調フィルタリング レコメンデーション システムを通じて、ユーザー間のレコメンデーションの成功率を調査します。推薦成功率が高いユーザは、推薦システムにおけるキーユーザとみなすことができる。これら 2 つの方法により、グラフ内の主要なユーザーが検出され、リソースがコールド スタートされるときに最初に推奨されます。 コールドスタートコンテンツの実験システムは、レコメンデーションシステムのサンプルが共有されるため、設計時にいくつかの特別な機能に注意する必要があります。実験グループの比較もグループ内で学習されるため、コールド スタート戦略の効果を正確に測定することが困難になります。したがって、コンテンツ分離実験を実施して、システム全体に対するコールド スタート戦略の影響を評価する必要があります。 一般的な実験設計は、上の図の左下部分に示すように、ユーザーとリソースを完全に分離することです。その中で、ユーザーの 50% はコンテンツの 50% しか表示できず、リソース グループごとに異なるコールド スタート戦略が使用されます。これにより、システム全体に対するコールド スタート戦略の影響を評価できます。ただし、この方法ではコンテンツの一部しか表示されないため、C 側ユーザーのエクスペリエンスに大きな影響を与える可能性があります。 もう 1 つの穏やかな方法は、最初の 3000 回などのコールド スタート フェーズ中にユーザーとリソースを完全に分離し、その後、グループごとに異なるコールド スタート戦略を実装することです。コールド スタート後、リソースをすべてのユーザーに配布できます。このような設計により、C 側のユーザー エクスペリエンスへの影響を軽減できます。 実験を通じて、次の指標を分析できます: A1: ホット タワーとコールド タワーの判断は、通常、リソースの配分に基づいて行われます。一般に、分配量が少ないリソースはコールド タワーとみなされ、分配量が多いリソースはホット タワーとみなされます。たとえば、配布回数が 100 回未満のリソースは、コールド スタート リソースと見なすことができます。もちろん、オンラインモデルの予測精度をもとに分析し、実態を踏まえた具体的な判断基準を定める必要があります。 A2: コールド スタート トラフィックの品質向上には、通常、リソースの可能性の評価が含まれます。リソースの可能性を判断するには、複数の信号ソースを組み合わせることができます。例えば、その分野で新たなホットトピックかどうかを判断するには、各製品のホットリスト情報や、関連分野での話題や注目度など、ネットワーク全体の情報を総合的に考慮することができます。リソースの価値を評価するには、初期段階でのパフォーマンスやインタラクションなどの要素を含む、著者の質が考慮される場合があります。これらの情報を総合的に活用することで、より包括的な資源ポテンシャルの推定が可能となります。 A3: 理想的な t と実際の t を解くとき、露出曲線を観察することでそれを反映できます。エクスポージャー曲線は、さまざまな期間におけるリソースのエクスポージャーを示します。理想的な t は、設定された目標時間に基づいて計算された理論的なエクスポージャーの進行状況を指します。一方、実際の t は、現在の実際のエクスポージャーの進行状況に基づいて決定されます。実際のエクスポージャが市場全体の傾向と一致していることを確認するには、全体のトラフィックの割合を安定して監視し、コールド スタートの進行状況が全体のトラフィックの傾向と一致していることを確認する必要があります。コールド スタートの進行が遅い場合は、進行を速めるために露出を増やすか、他の推奨戦略を調整する必要がある場合があります。進行が速すぎる場合は、リソースの過剰露出を避けるために露出速度を下げる必要がある場合があります。 A4: コールドスタートの問題ですが、その効果の正確な値を正確に測定することは実は困難です。現在では、実験グループと対照グループを比較して、どちらが優れているかを確認するのが一般的です。 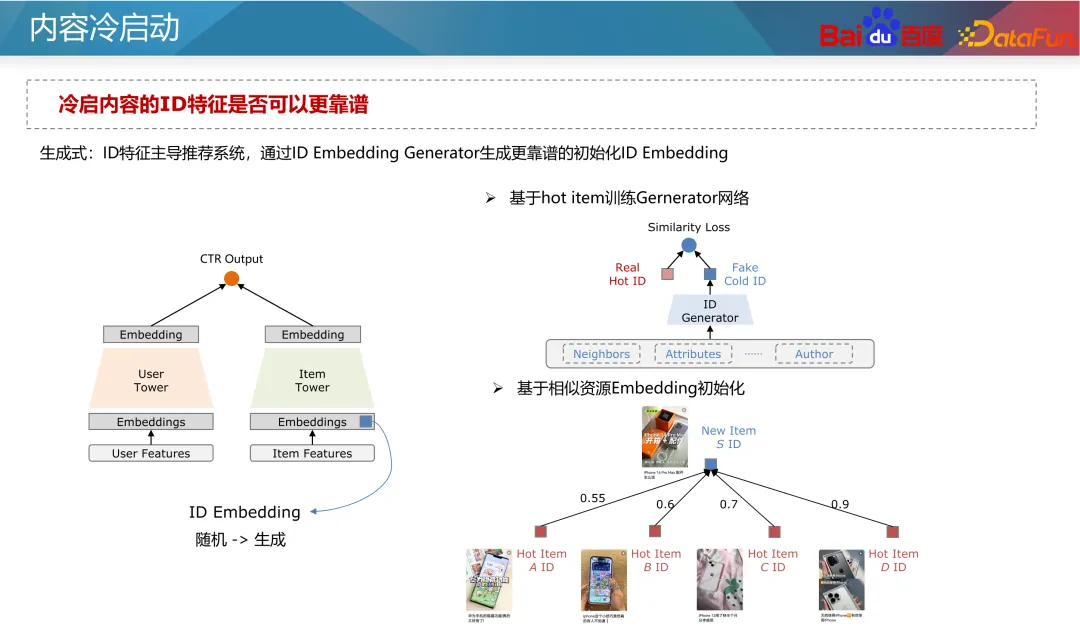
2. トラフィック制御メカニズムの設計
3. 配信ユーザーの選択
4. 実験システム
4. Q&A
Q1: ツインタワーのホットとコールドを判断するにはどうすればよいですか? 1 つはホット タワー、もう 1 つはコールド タワーです。
Q2: コールド スタート トラフィックが高品質でブーストされた場合のリソースの可能性を判断するにはどうすればよいですか?価値モデルを使用して、それがこの分野で新たなホットトピックであるかどうかを推定しますか?
Q3: 理想的な t と実際の t を求めるにはどうすればよいですか?露出カーブに反映されているのでしょうか?実際のエクスポージャが市場トレンドと一致していることを確認する方法。
Q4: ユーザーは実験中はコンテンツの 50% しか見ることができませんが、フル容量ではコンテンツの 100% しか見ることができません。実験が完全な効果と一致していることを証明するにはどうすればよいでしょうか?
以上がBaidu が推奨するリソースのコールド スタートの実践の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。