
Maison >Périphériques technologiques >IA >0 seuil pour une utilisation commerciale gratuite ! Le grand modèle Mencius 3-13B est officiellement open source et formé avec des milliards de données symboliques
0 seuil pour une utilisation commerciale gratuite ! Le grand modèle Mencius 3-13B est officiellement open source et formé avec des milliards de données symboliques

- PHPzavant
- 2024-04-01 17:01:22780parcourir
Lanzhou Technology officiellement annoncé : le grand modèle Mencius 3-13B est officiellement open source !
Ce grand modèle léger et économique est entièrement ouvert à la recherche universitaire et prend en charge une utilisation commerciale gratuite.
Dans diverses évaluations de référence telles que MMLU, GSM8K et HUMAN-EVAL, Mencius 3-13B a montré de bonnes performances.
Particulièrement dans le domaine des grands modèles légers avec des paramètres inférieurs à 20B, les compétences linguistiques en chinois et en anglais sont particulièrement remarquables. Les compétences en mathématiques et en programmation sont également au premier plan.
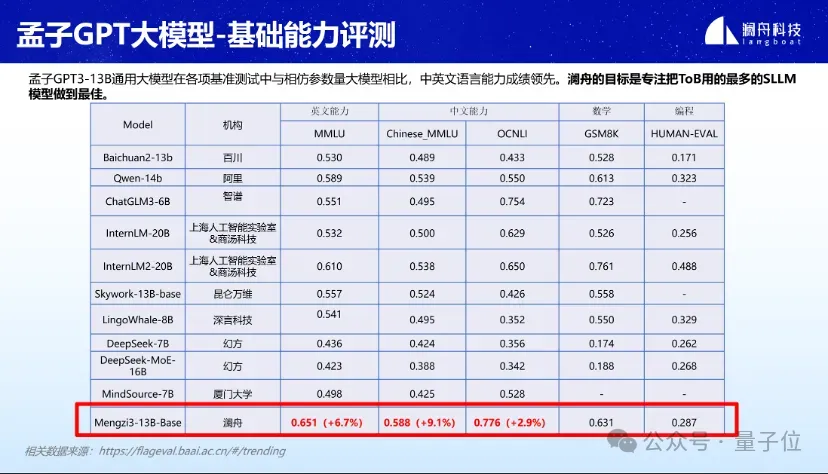
△Les résultats ci-dessus sont basés sur 5 tirs.
Selon les rapports, le grand modèle Mencius 3-13B est basé sur l'architecture Llama et la taille de l'ensemble de données est aussi élevée que les 3T Tokens.
Le corpus est sélectionné à partir de pages Web, d'encyclopédies, de médias sociaux, de médias, d'actualités et d'ensembles de données open source de haute qualité. En continuant à s'entraîner sur des milliards de jetons avec un corpus multilingue, le modèle possède des capacités chinoises exceptionnelles et prend en compte les capacités multilingues.
Le grand modèle Mencius 3-13B est open source
Vous pouvez utiliser le grand modèle Mencius 3-13B en seulement deux étapes.
Configurez d’abord l’environnement.
pip install -r requirements.txt
Alors commence vite.
import torchfrom transformers import AutoModelForCausalLM, AutoTokenizertokenizer = AutoTokenizer.from_pretrained("Langboat/Mengzi3-13B-Base", use_fast=False, trust_remote_code=True)model = AutoModelForCausalLM.from_pretrained("Langboat/Mengzi3-13B-Base", device_map="auto", trust_remote_code=True)inputs = tokenizer('指令:回答以下问题。输入:介绍一下孟子。输出:', return_tensors='pt')if torch.cuda.is_available():inputs = inputs.to('cuda')pred = model.generate(**inputs, max_new_tokens=512, repetition_penalty=1.01, eos_token_id=tokenizer.eos_token_id)print(tokenizer.decode(pred[0], skip_special_tokens=True))De plus, ils fournissent un exemple de code qui peut être utilisé pour une inférence interactive à un seul tour avec le modèle de base.
cd examplespython examples/base_streaming_gen.py --model model_path --tokenizer tokenizer_path
Si vous souhaitez affiner le modèle, ils fournissent également les fichiers et le code pertinents.

En fait, de nombreux détails du grand modèle Mencius 3-13B ont été révélés dès le 18 mars lors de la conférence de lancement de produits et de technologie des grands modèles de Lanzhou.
A cette époque, ils ont déclaré que la formation du grand modèle Mencius 3-13B était terminée.
Quant aux raisons du choix de la version 13B, Zhou Ming a expliqué :
Tout d'abord, Lanzhou se concentre clairement sur la fourniture de scénarios ToB, complétés par ToC.
La pratique a révélé que les paramètres des grands modèles les plus fréquemment utilisés dans les scénarios ToB sont principalement 7B, 13B, 40B, 100B, et que la concentration globale se situe entre 10B et 100B.
Deuxièmement, dans cette fourchette, du point de vue du ROI (retour sur investissement), il répond non seulement aux besoins de la scène, mais est également le plus rentable.
Par conséquent, depuis longtemps, l’objectif de Lanzhou a été de créer de grands modèles industriels de haute qualité dans l’échelle de paramètres 10B-100B.
En tant que l'une des premières équipes entrepreneuriales à grande échelle en Chine, Lanzhou a lancé Mencius GPT V1 (MChat) en mars de l'année dernière.
En janvier de cette année, Mencius Big Model GPT V2 (y compris Mencius Big Model-Standard, Mencius Big Model-Lightweight, Mencius Big Model-Finance, Mencius Big Model-Encoding) a été ouvert au public.
D'accord, les amis intéressés peuvent cliquer sur le lien ci-dessous pour en faire l'expérience.
Lien GitHub : https://github.com/Langboat/Mengzi3
HuggingFace : https://huggingface.co/Langboat/Mengzi3-13B-Base
ModelScope : https : //www.modelscope.cn/models/langboat/Mengzi3-13B-Base
Wisemodel:https://wisemodel.cn/models/Langboat/Mengzi3-13B-Base
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Le routage est la fonction principale de quelle couche dans le modèle osi
- Quelle est la principale contribution du modèle informatique de la machine de Turing ?
- Le meilleur expert en IA de Google rejoint OpenAI et avertit Google de ne pas utiliser les données ChatGPT pour former Bard
- Les méta-chercheurs font une nouvelle tentative en matière d'IA : apprendre aux robots à naviguer physiquement sans cartes ni formation
- Utiliser Pytorch pour mettre en œuvre l'apprentissage contrastif SimCLR pour une pré-formation auto-supervisée