
Maison >développement back-end >Tutoriel Python >Utiliser Pytorch pour mettre en œuvre l'apprentissage contrastif SimCLR pour une pré-formation auto-supervisée
Utiliser Pytorch pour mettre en œuvre l'apprentissage contrastif SimCLR pour une pré-formation auto-supervisée

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-10 14:11:032261parcourir
SimCLR (Simple Framework for Contrastive Learning of Representations) est une technologie auto-supervisée pour l'apprentissage des représentations d'images. Contrairement aux méthodes traditionnelles d’apprentissage supervisé, SimCLR ne s’appuie pas sur des données étiquetées pour apprendre des représentations utiles. Il exploite un cadre d'apprentissage contrastif pour apprendre un ensemble de fonctionnalités utiles capables de capturer des informations sémantiques de haut niveau à partir d'images non étiquetées.
Il a été prouvé que SimCLR surpasse les méthodes d'apprentissage non supervisées de pointe sur divers critères de classification d'images. Et les représentations qu'il apprend peuvent être facilement transférées vers des tâches en aval telles que la détection d'objets, la segmentation sémantique et l'apprentissage en quelques étapes avec un ajustement minimal sur des ensembles de données étiquetés plus petits.

SimCLR L'idée principale est d'apprendre une bonne représentation de l'image en la comparant avec d'autres versions améliorées de la même image grâce au module d'amélioration T. Cela se fait en mappant l'image via un réseau d'encodeurs f(.) puis en la projetant. head g(.) mappe les fonctionnalités apprises dans un espace de faible dimension. Une perte contrastive est ensuite calculée entre les représentations de deux versions améliorées de la même image pour encourager des représentations similaires de la même image et des représentations différentes d'images différentes.
Dans cet article, nous allons approfondir le framework SimCLR et explorer les composants clés de l'algorithme, notamment l'augmentation des données, les fonctions de perte contrastives et l'architecture de tête pour les encodeurs et les projections.
Ici, nous utilisons l'ensemble de données de classification des déchets de Kaggle pour mener des expériences
Module d'amélioration
La chose la plus importante dans SimCLR est le module d'amélioration pour la conversion des images. Les auteurs de l’article SimCLR suggèrent qu’une puissante augmentation des données est utile pour l’apprentissage non supervisé. Nous suivrons donc l’approche recommandée dans le document.
- Recadrage aléatoire pour le redimensionnement
- Retournement horizontal aléatoire avec 50 % de probabilité
- Distorsion aléatoire des couleurs (80 % de probabilité de gigue de couleur, 20 % de probabilité de chute de couleur)
- 50 % de probabilité de flou gaussien aléatoire
def get_complete_transform(output_shape, kernel_size, s=1.0): """ Color distortion transform Args: s: Strength parameter Returns: A color distortion transform """ rnd_crop = RandomResizedCrop(output_shape) rnd_flip = RandomHorizontalFlip(p=0.5) color_jitter = ColorJitter(0.8*s, 0.8*s, 0.8*s, 0.2*s) rnd_color_jitter = RandomApply([color_jitter], p=0.8) rnd_gray = RandomGrayscale(p=0.2) gaussian_blur = GaussianBlur(kernel_size=kernel_size) rnd_gaussian_blur = RandomApply([gaussian_blur], p=0.5) to_tensor = ToTensor() image_transform = Compose([ to_tensor, rnd_crop, rnd_flip, rnd_color_jitter, rnd_gray, rnd_gaussian_blur, ]) return image_transform class ContrastiveLearningViewGenerator(object): """ Take 2 random crops of 1 image as the query and key. """ def __init__(self, base_transform, n_views=2): self.base_transform = base_transform self.n_views = n_views def __call__(self, x): views = [self.base_transform(x) for i in range(self.n_views)] return views
L'étape suivante consiste à définir un ensemble de données PyTorch.
class CustomDataset(Dataset): def __init__(self, list_images, transform=None): """ Args: list_images (list): List of all the images transform (callable, optional): Optional transform to be applied on a sample. """ self.list_images = list_images self.transform = transform def __len__(self): return len(self.list_images) def __getitem__(self, idx): if torch.is_tensor(idx): idx = idx.tolist() img_name = self.list_images[idx] image = io.imread(img_name) if self.transform: image = self.transform(image) return image
À titre d'exemple, nous utilisons le plus petit modèle ResNet18 comme colonne vertébrale, son entrée est donc une image 224x224. Nous définissons certains paramètres selon les besoins et générons le chargeur de données
out_shape = [224, 224]
kernel_size = [21, 21] # 10% of out_shape
# Custom transform
base_transforms = get_complete_transform(output_shape=out_shape, kernel_size=kernel_size, s=1.0)
custom_transform = ContrastiveLearningViewGenerator(base_transform=base_transforms)
garbage_ds = CustomDataset(
list_images=glob.glob("/kaggle/input/garbage-classification/garbage_classification/*/*.jpg"),
transform=custom_transform
)
BATCH_SZ = 128
# Build DataLoader
train_dl = torch.utils.data.DataLoader(
garbage_ds,
batch_size=BATCH_SZ,
shuffle=True,
drop_last=True,
pin_memory=True)
SimCLR
Nous avons préparé les données. , commencez à reproduire le modèle. Le module d'amélioration ci-dessus fournit deux vues améliorées de l'image, qui sont transmises via l'encodeur pour obtenir la représentation correspondante. Le but de SimCLR est de maximiser la similarité entre ces différentes représentations apprises en encourageant le modèle à apprendre une représentation générale d'un objet à partir de deux vues augmentées différentes.
Le choix du réseau d'encodeurs n'est pas limité et peut être n'importe quelle architecture. Comme mentionné ci-dessus, pour une démonstration simple, nous utilisons ResNet18. Les représentations apprises par le modèle d'encodeur déterminent les coefficients de similarité, et pour améliorer la qualité de ces représentations, SimCLR utilise une tête de projection pour projeter les vecteurs d'encodage dans un espace latent plus riche. Ici, nous projetons les fonctionnalités à 512 dimensions de ResNet18 dans un espace à 256 dimensions. Cela semble très compliqué, mais en fait, il s'agit simplement d'ajouter un mlp avec relu.
class Identity(nn.Module): def __init__(self): super(Identity, self).__init__() def forward(self, x): return x class SimCLR(nn.Module): def __init__(self, linear_eval=False): super().__init__() self.linear_eval = linear_eval resnet18 = models.resnet18(pretrained=False) resnet18.fc = Identity() self.encoder = resnet18 self.projection = nn.Sequential( nn.Linear(512, 512), nn.ReLU(), nn.Linear(512, 256) ) def forward(self, x): if not self.linear_eval: x = torch.cat(x, dim=0) encoding = self.encoder(x) projection = self.projection(encoding) return projection
Contrast Loss
La fonction de perte de contraste, également connue sous le nom de perte d'entropie croisée à l'échelle de la température normalisée (NT-Xent), est un élément clé de SimCLR, qui encourage le modèle à apprendre des représentations similaires et différentes de la même image. Différentes représentations d'images.
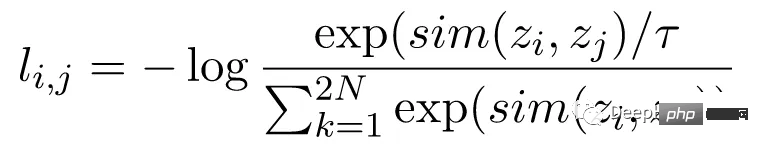
La perte NT-Xent est calculée à l'aide d'une paire de vues augmentées de l'image transmise à travers le réseau d'encodeurs pour obtenir leurs représentations correspondantes. Le but de la perte contrastive est d’encourager les représentations de deux vues augmentées de la même image à être similaires tout en forçant les représentations d’images différentes à être différentes.
NT-Xent applique une fonction softmax pour améliorer la similarité par paire des représentations de vues. La fonction softmax est appliquée à toutes les paires de représentations au sein du mini-lot pour obtenir une distribution de probabilité de similarité pour chaque image. Le paramètre de température est utilisé pour mettre à l'échelle les similitudes par paires avant d'appliquer la fonction softmax, ce qui permet d'obtenir de meilleurs gradients lors de l'optimisation.
Après avoir obtenu la distribution de probabilité des similitudes, la perte NT-Xent est calculée en maximisant la probabilité logarithmique de représentations correspondantes de la même image et en minimisant la probabilité logarithmique de représentations incompatibles de différentes images.
LABELS = torch.cat([torch.arange(BATCH_SZ) for i in range(2)], dim=0) LABELS = (LABELS.unsqueeze(0) == LABELS.unsqueeze(1)).float() #one-hot representations LABELS = LABELS.to(DEVICE) def ntxent_loss(features, temp): """ NT-Xent Loss. Args: z1: The learned representations from first branch of projection head z2: The learned representations from second branch of projection head Returns: Loss """ similarity_matrix = torch.matmul(features, features.T) mask = torch.eye(LABELS.shape[0], dtype=torch.bool).to(DEVICE) labels = LABELS[~mask].view(LABELS.shape[0], -1) similarity_matrix = similarity_matrix[~mask].view(similarity_matrix.shape[0], -1) positives = similarity_matrix[labels.bool()].view(labels.shape[0], -1) negatives = similarity_matrix[~labels.bool()].view(similarity_matrix.shape[0], -1) logits = torch.cat([positives, negatives], dim=1) labels = torch.zeros(logits.shape[0], dtype=torch.long).to(DEVICE) logits = logits / temp return logits, labels
Tous les préparatifs sont terminés, entraînons SimCLR et voyons l'effet !
simclr_model = SimCLR().to(DEVICE)
criterion = nn.CrossEntropyLoss().to(DEVICE)
optimizer = torch.optim.Adam(simclr_model.parameters())
epochs = 10
with tqdm(total=epochs) as pbar:
for epoch in range(epochs):
t0 = time.time()
running_loss = 0.0
for i, views in enumerate(train_dl):
projections = simclr_model([view.to(DEVICE) for view in views])
logits, labels = ntxent_loss(projections, temp=2)
loss = criterion(logits, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# print stats
running_loss += loss.item()
if i%10 == 9: # print every 10 mini-batches
print(f"Epoch: {epoch+1} Batch: {i+1} Loss: {(running_loss/100):.4f}")
running_loss = 0.0
pbar.update(1)
print(f"Time taken: {((time.time()-t0)/60):.3f} mins")
Le code ci-dessus est entraîné pendant 10 tours. En supposant que nous ayons terminé le processus de pré-formation, nous pouvons utiliser l'encodeur pré-entraîné pour les tâches en aval que nous souhaitons. Cela peut être fait avec le code ci-dessous.
from torchvision.transforms import Resize, CenterCrop
resize = Resize(255)
ccrop = CenterCrop(224)
ttensor = ToTensor()
custom_transform = Compose([
resize,
ccrop,
ttensor,
])
garbage_ds = ImageFolder(
root="/kaggle/input/garbage-classification/garbage_classification/",
transform=custom_transform
)
classes = len(garbage_ds.classes)
BATCH_SZ = 128
train_dl = torch.utils.data.DataLoader(
garbage_ds,
batch_size=BATCH_SZ,
shuffle=True,
drop_last=True,
pin_memory=True,
)
class Identity(nn.Module):
def __init__(self):
super(Identity, self).__init__()
def forward(self, x):
return x
class LinearEvaluation(nn.Module):
def __init__(self, model, classes):
super().__init__()
simclr = model
simclr.linear_eval=True
simclr.projection = Identity()
self.simclr = simclr
for param in self.simclr.parameters():
param.requires_grad = False
self.linear = nn.Linear(512, classes)
def forward(self, x):
encoding = self.simclr(x)
pred = self.linear(encoding)
return pred
eval_model = LinearEvaluation(simclr_model, classes).to(DEVICE)
criterion = nn.CrossEntropyLoss().to(DEVICE)
optimizer = torch.optim.Adam(eval_model.parameters())
preds, labels = [], []
correct, total = 0, 0
with torch.no_grad():
t0 = time.time()
for img, gt in tqdm(train_dl):
image = img.to(DEVICE)
label = gt.to(DEVICE)
pred = eval_model(image)
_, pred = torch.max(pred.data, 1)
total += label.size(0)
correct += (pred == label).float().sum().item()
print(f"Time taken: {((time.time()-t0)/60):.3f} mins")
print(
"Accuracy of the network on the {} Train images: {} %".format(
total, 100 * correct / total
)
)
La partie principale du code ci-dessus consiste à lire le modèle simclr qui vient d'être formé, puis à geler tous les poids, puis à créer une tête de classification self.linear pour effectuer des tâches de classification en aval
Résumé
Cet article présente le framework SimCLR et l'utilise pour pré-entraîner ResNet18 avec des poids initialisés aléatoirement. Le pré-entraînement est une technique puissante utilisée en apprentissage profond pour entraîner des modèles sur de grands ensembles de données et apprendre des fonctionnalités utiles qui peuvent être transférées à d'autres tâches. L'article SimCLR estime que plus la taille du lot est grande, meilleures sont les performances. Notre implémentation n'utilise qu'une taille de lot de 128 et s'entraîne pendant seulement 10 époques. Ce n’est donc pas la meilleure performance du modèle. Si une comparaison des performances est nécessaire, une formation supplémentaire est nécessaire.
L'image ci-dessous est la conclusion de la performance donnée par l'auteur de l'article :

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!