
Maison >Périphériques technologiques >IA >UniVision inégalé : détection BEV et cadre unifié commun Occ, double SOTA !
UniVision inégalé : détection BEV et cadre unifié commun Occ, double SOTA !

- 王林avant
- 2024-03-04 15:55:02424parcourir
Écrit auparavant et compréhension personnelle
Ces dernières années, la perception 3D centrée sur la vision dans la technologie de conduite autonome a fait des progrès rapides. Bien que les différents modèles de perception 3D partagent de nombreuses similitudes structurelles et conceptuelles, il existe encore certaines différences dans la représentation des caractéristiques, les formats de données et les objectifs, ce qui pose des défis pour la conception d'un cadre de perception 3D unifié et efficace. Par conséquent, les chercheurs travaillent dur pour trouver des solutions permettant de mieux intégrer les différences entre les différents modèles afin de construire des systèmes de perception 3D plus complets et plus efficaces. Ce type d'effort devrait apporter une technologie plus fiable et avancée au domaine de la conduite autonome, la rendant plus puissante dans des environnements complexes. En particulier pour les tâches de détection et d'occupation sous BEV, il est encore difficile d'effectuer une formation conjointe, d'instabilité et d'occupation. les effets incontrôlables provoquent des maux de tête pour de nombreuses applications. UniVision est un framework simple et efficace qui unifie deux tâches principales de la perception 3D centrée sur la vision, à savoir la prédiction d'occupation et la détection d'objets. Le point central est un module de transformation de vue explicite-implicite pour la transformation complémentaire de fonctionnalités 2D-3D. UniVision propose un module d'extraction et de fusion de fonctionnalités locales et globales pour une extraction, une amélioration et une interaction efficaces et adaptatives des fonctionnalités de voxel et BEV.
Dans la partie amélioration des données, UniVision a également proposé une stratégie conjointe d'amélioration des données de détection d'occupation et une stratégie d'ajustement progressif de la perte de poids pour améliorer l'efficacité et la stabilité de la formation du cadre multitâche. Des expériences approfondies sont menées sur différentes tâches de perception sur quatre benchmarks publics, notamment la segmentation lidar sans scène, la détection sans scène, OpenOccupancy et Occ3D. UniVision a atteint SOTA avec des gains de +1,5 mIoU, +1,8 NDS, +1,5 mIoU et +1,8 mIoU sur chaque référence, respectivement. Le framework UniVision peut servir de base de référence hautes performances pour les tâches de perception 3D unifiées centrées sur la vision.
Si vous n'êtes pas familier avec les tâches BEV et d'occupation, vous êtes invités à étudier plus en profondeur notre
Tutoriel de perception BEVet Tutoriel de réseau d'occupation pour en savoir plus sur les détails techniques !
État actuel du domaine de la perception 3DLa perception 3D est la tâche principale des systèmes de conduite autonome. Son objectif est d'utiliser les données obtenues à partir d'une série de capteurs (tels que le lidar, le radar et les caméras) pour comprendre de manière globale. la scène de conduite pour la planification de l'utilisation et la prise de décision ultérieures. Dans le passé, le domaine de la perception 3D était dominé par les modèles basés sur le lidar en raison des informations 3D précises dérivées des données des nuages de points. Cependant, les systèmes basés sur le lidar sont coûteux, sensibles aux intempéries et peu pratiques à déployer. En revanche, les systèmes basés sur la vision présentent de nombreux avantages, tels qu'un faible coût, un déploiement facile et une bonne évolutivité. Par conséquent, la perception tridimensionnelle centrée sur la vision a attiré l’attention des chercheurs.
Récemment, la détection 3D basée sur la vision a été considérablement améliorée grâce à la transformation de la représentation des caractéristiques, à la fusion temporelle et à la conception de signaux supervisés, comblant ainsi continuellement l'écart avec les modèles basés sur le lidar. En outre, les tâches d'occupation basées sur la vision se sont développées rapidement ces dernières années. Contrairement à l’utilisation de boîtes 3D pour représenter certains objets, l’occupation peut décrire la géométrie et la sémantique de la scène de conduite de manière plus complète et se limite moins à la forme et à la catégorie des objets.
Bien que les méthodes de détection et les méthodes d'occupation partagent de nombreuses similitudes structurelles et conceptuelles, la gestion simultanée des deux tâches et l'exploration de leurs interrelations n'ont pas été bien étudiées. Les modèles d'occupation et les modèles de détection extraient souvent différentes représentations de caractéristiques. La tâche de prédiction d'occupation nécessite des jugements sémantiques et géométriques exhaustifs à différents emplacements spatiaux, de sorte que les représentations voxels sont largement utilisées pour préserver les informations 3D à grain fin. Dans les tâches de détection, la représentation BEV est préférée puisque la plupart des objets se trouvent sur le même plan horizontal avec un chevauchement plus petit.
Par rapport à la représentation BEV, la représentation voxel est raffinée mais moins efficace. De plus, de nombreux opérateurs avancés sont principalement conçus et optimisés pour les fonctionnalités 2D, ce qui rend leur intégration avec la représentation de voxels 3D pas si simple. La représentation BEV est plus efficace en termes de temps et de mémoire, mais elle n'est pas optimale pour les prédictions spatiales denses car elle perd des informations structurelles dans la dimension hauteur. En plus de la représentation des caractéristiques, les différentes tâches de perception diffèrent également par les formats de données et les objectifs. Par conséquent, assurer l’uniformité et l’efficacité de la formation des cadres de perception 3D multitâches constitue un défi de taille.
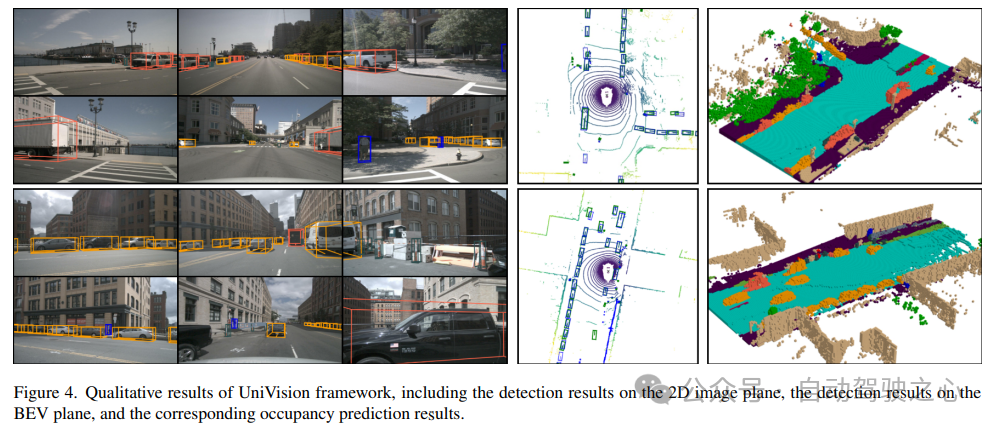
Structure du réseau UniVisionLa structure globale du framework UniVision est présentée dans la figure 1. Le cadre reçoit des images multi-vues de N caméras environnantes en entrée et extrait des caractéristiques d'image via un réseau d'extraction de caractéristiques d'image. Ensuite, les fonctionnalités de l'image 2D sont mises à niveau vers des fonctionnalités de voxel 3D à l'aide du module de transformation de vue Ex-Im, qui combine une amélioration des fonctionnalités explicites guidée en profondeur et un échantillonnage de fonctionnalités implicite guidé par une requête. Les caractéristiques de voxel sont traitées par un bloc d'extraction et de fusion de caractéristiques globales locales pour extraire respectivement des caractéristiques de voxel locales sensibles au contexte et des caractéristiques BEV globales sensibles au contexte. Par la suite, des informations sont échangées entre les fonctionnalités de voxel et les fonctionnalités BEV pour différentes tâches de perception en aval via le module d'interaction des fonctionnalités de représentation croisée. Dans la phase d'entraînement, le cadre UniVision adopte une stratégie combinée d'amélioration des données Occ-Det et d'ajustement progressif des poids de perte pour un entraînement efficace.
1) Ex-Im View Transform
Amélioration explicite des fonctionnalités guidée en profondeur. L'approche LSS est suivie ici :
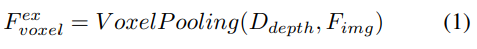
2) Échantillonnage de fonctionnalités implicites guidé par requête. Cependant, la représentation d’informations 3D présente certains inconvénients. La précision de est fortement corrélée à la précision de la distribution de profondeur estimée. De plus, les points générés par LSS ne sont pas uniformément répartis. Les points sont denses à proximité de la caméra et clairsemés à distance. Par conséquent, nous utilisons en outre l’échantillonnage de fonctionnalités guidé par des requêtes pour compenser les lacunes ci-dessus.
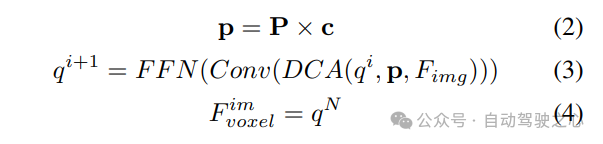
Par rapport aux points générés à partir de LSS, les requêtes voxels sont uniformément distribuées dans l'espace 3D et elles sont apprises à partir des propriétés statistiques de tous les échantillons d'entraînement, ce qui est indépendant de la profondeur des informations préalables utilisées dans LSS. Par conséquent, et se complètent les uns les autres, ils sont connectés en tant que caractéristiques de sortie du module de transformation de vue :
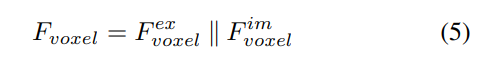
2) Extraction et fusion de caractéristiques globales locales
Étant donné les caractéristiques du voxel d'entrée, superposez d'abord les caractéristiques sur le Z -axis et utilisez des couches convolutives pour réduire les canaux afin d'obtenir les fonctionnalités BEV :
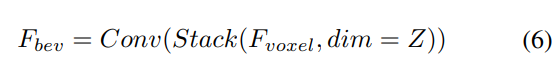
Ensuite, le modèle est divisé en deux branches parallèles pour l'extraction et l'amélioration des fonctionnalités. Extraction de fonctionnalités locales + extraction de fonctionnalités globales et interaction finale des fonctionnalités de représentation croisée ! Comme le montre la figure 1 (b).
3) Fonction de perte et tête de détection
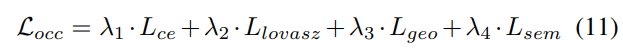
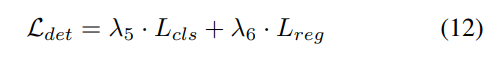
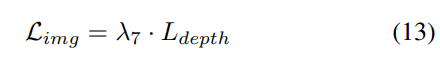
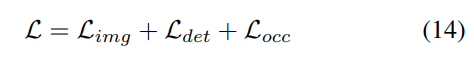
Stratégie d'ajustement progressif du poids de perte. En pratique, il s’avère que l’intégration directe des pertes ci-dessus entraîne souvent l’échec du processus de formation et l’échec de la convergence du réseau. Dans les premiers stades de la formation, les caractéristiques du voxel Fvoxel sont distribuées de manière aléatoire, et la supervision dans la tête d'occupation et la tête de détection contribue moins que les autres pertes de convergence. Dans le même temps, les éléments de perte tels que les pertes de classification Lcls dans la tâche de détection sont très importants et dominent le processus de formation, ce qui rend difficile l'optimisation du modèle. Pour surmonter ce problème, une stratégie d’ajustement progressif du poids perdu est proposée pour ajuster dynamiquement le poids perdu. Plus précisément, un paramètre de contrôle δ est ajouté aux pertes non liées à l'image (c'est-à-dire la perte d'occupation et la perte de détection) pour ajuster le poids de perte à différentes époques d'entraînement. Le poids de contrôle δ est fixé à une petite valeur Vmin au début et augmente progressivement jusqu'à Vmax au cours de N époques d'entraînement :
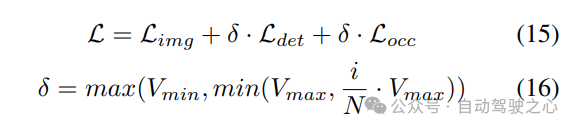
4) Augmentation conjointe des données spatiales Occ-Det
dans la tâche de détection 3D, en plus à l'augmentation commune des données au niveau de l'image, l'augmentation des données au niveau spatial est également efficace pour améliorer les performances du modèle. Cependant, appliquer l’amélioration du niveau spatial aux tâches d’occupation n’est pas simple. Lorsque nous appliquons une augmentation des données (telle qu'une mise à l'échelle et une rotation aléatoires) à des étiquettes d'occupation discrètes, il est difficile de déterminer la sémantique des voxels résultante. Par conséquent, les méthodes existantes n’appliquent qu’une simple augmentation spatiale telle qu’un retournement aléatoire dans les tâches d’occupation.
Pour résoudre ce problème, UniVision propose une augmentation conjointe des données spatiales Occ-Det pour permettre l'amélioration simultanée des tâches de détection 3D et des tâches d'occupation dans le cadre. Étant donné que les étiquettes de boîte 3D sont des valeurs continues et que la boîte 3D améliorée peut être directement calculée pour la formation, la méthode d'amélioration de BEVDet est suivie pour la détection. Bien que les étiquettes d'occupation soient discrètes et difficiles à manipuler, les caractéristiques des voxels peuvent être traitées comme continues et traitées par des opérations telles que l'échantillonnage et l'interpolation. Il est donc recommandé de transformer les caractéristiques des voxels au lieu d'opérer directement sur les étiquettes d'occupation pour augmenter les données.
Plus précisément, l'augmentation des données spatiales est d'abord échantillonnée et la matrice de transformation 3D correspondante est calculée. Pour les étiquettes d'occupation et leurs indices voxels , nous calculons leurs coordonnées tridimensionnelles. Ensuite, il sera appliqué et normalisé pour obtenir les indices de voxel dans les fonctionnalités de voxel améliorées :
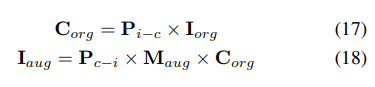
Comparaison des résultats expérimentaux
Utilisation de plusieurs ensembles de données pour la vérification, segmentation NuScenes LiDAR, détection d'objets 3D NuScenes, OpenOccupancy et Occ3D.
Segmentation LiDAR NuScenes : selon les récents OccFormer et TPVFormer, les images de caméra sont utilisées comme entrée pour la tâche de segmentation lidar, et les données lidar ne sont utilisées que pour fournir des emplacements 3D pour interroger les entités de sortie. Utilisez mIoU comme métrique d’évaluation.
Détection d'objets 3D NuScenes : pour les tâches de détection, utilisez la métrique officielle de nuScenes, le score de détection nuScene (NDS), qui est la somme pondérée du mAP moyen et de plusieurs métriques, notamment l'erreur de traduction moyenne (ATE), l'erreur d'échelle moyenne ( ASE) ), l'erreur d'orientation moyenne (AOE), l'erreur de vitesse moyenne (AVE) et l'erreur d'attribut moyenne (AAE).
OpenOccupancy : le benchmark OpenOccupancy est basé sur l'ensemble de données nuScenes et fournit des étiquettes d'occupation sémantiques à une résolution de 512 × 512 × 40. Les classes étiquetées sont les mêmes que celles de la tâche de segmentation lidar, en utilisant mIoU comme métrique d'évaluation !
Occ3D : le benchmark Occ3D est basé sur l'ensemble de données nuScenes et fournit des étiquettes d'occupation sémantiques à une résolution de 200×200×16. Occ3D fournit en outre des masques visibles pour la formation et l'évaluation. Les classes étiquetées sont les mêmes que celles de la tâche de segmentation lidar, en utilisant mIoU comme métrique d'évaluation !
1) Segmentation Nuscenes LiDAR
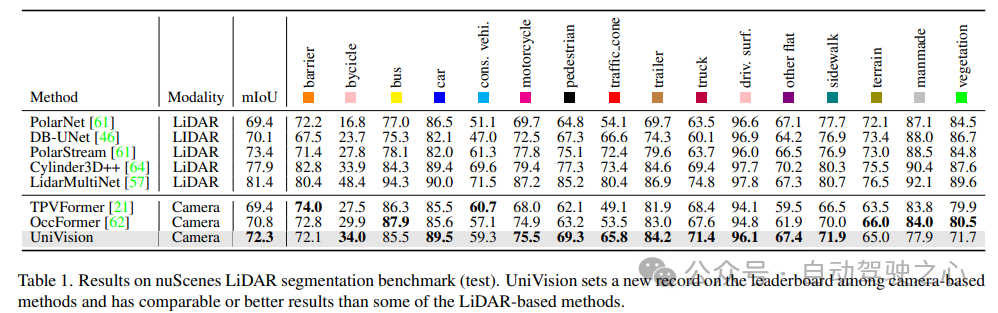
Le tableau 1 montre les résultats du benchmark de segmentation nuScenes LiDAR. UniVision surpasse considérablement la méthode de pointe basée sur la vision OccFormer de 1,5 % mIoU et établit un nouveau record pour les modèles basés sur la vision au classement. Notamment, UniVision surpasse également certains modèles basés sur lidar tels que PolarNe et DB-UNet.
2) Tâche de détection d'objets 3D NuScenes
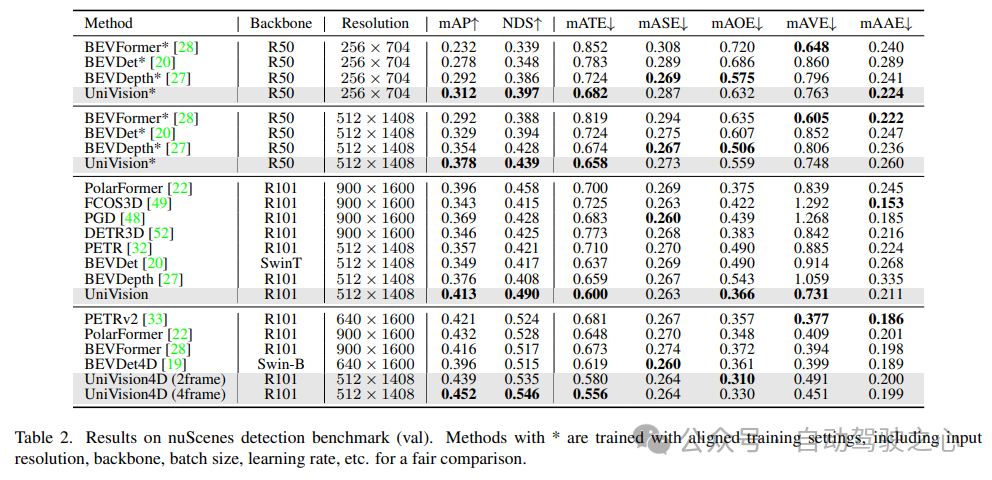
Comme le montre le tableau 2, UniVision surpasse les autres méthodes lorsqu'il utilise les mêmes paramètres d'entraînement pour une comparaison équitable. Par rapport à BEVDepth à une résolution d'image de 512 × 1408, UniVision réalise des gains de 2,4 % et 1,1 % respectivement en mAP et NDS. Lorsque le modèle est mis à l'échelle et qu'UniVision est combiné avec une entrée temporelle, il surpasse encore les détecteurs temporels basés sur SOTA par des marges significatives. UniVision y parvient avec une résolution d'entrée plus petite et n'utilise pas CBGS.
3) Comparaison des résultats d'OpenOccupancy
Les résultats du test de référence OpenOccupancy sont présentés dans le tableau 3. UniVision surpasse considérablement les méthodes récentes d'occupation basées sur la vision, notamment MonoScene, TPVFormer et C-CONet en termes de mIoU de 7,3 %, 6,5 % et 1,5 %, respectivement. De plus, UniVision surpasse certaines méthodes basées sur lidar telles que LMSCNet et JS3C-Net.
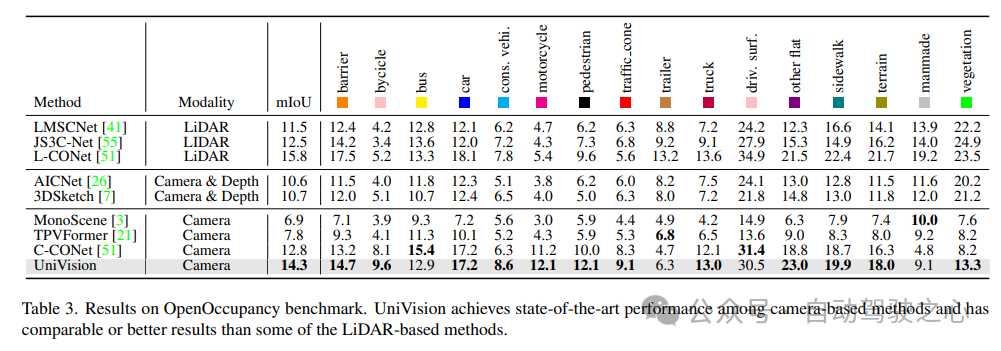
4) Résultats expérimentaux Occ3D
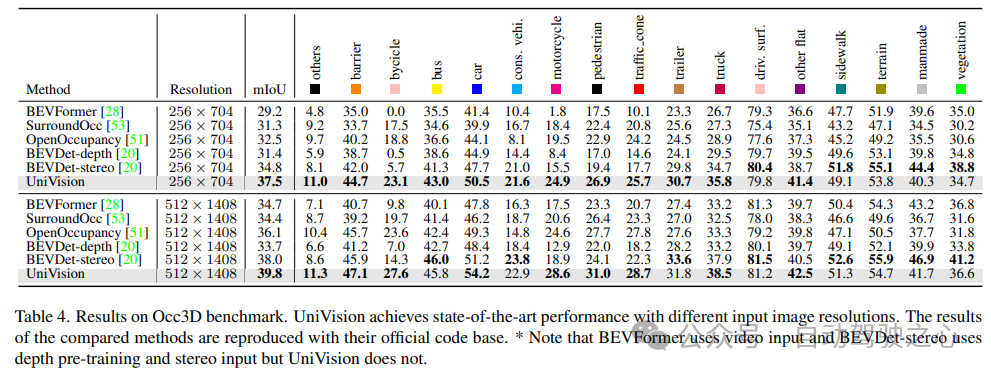
Le tableau 4 répertorie les résultats du benchmark Occ3D. UniVision surpasse considérablement les méthodes récentes basées sur la vision en termes de mIoU sous différentes résolutions d'image d'entrée, de plus de 2,7 % et 1,8 % respectivement. Il convient de noter que BEVFormer et BEVDet-stereo chargent des poids pré-entraînés et utilisent des entrées temporelles dans l'inférence, tandis qu'UniVision ne les utilise pas mais obtient quand même de meilleures performances.
5) Efficacité des composants dans les tâches de détection
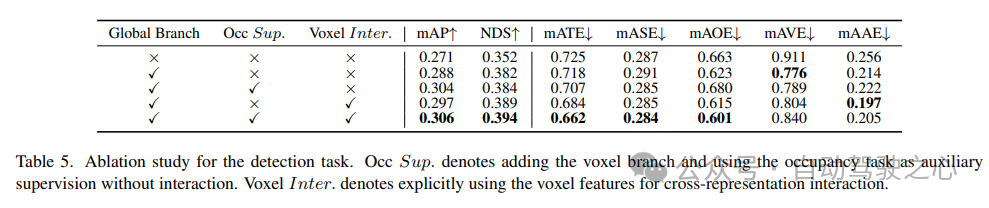
L'étude d'ablation pour les tâches de détection est présentée dans le tableau 5. Lorsque la branche d'extraction de fonctionnalités globale basée sur BEV est insérée dans le modèle de base, les performances s'améliorent de 1,7 % mAP et de 3,0 % NDS. Lorsque la tâche d'occupation basée sur les voxels est ajoutée au détecteur en tant que tâche auxiliaire, le gain mAP du modèle augmente de 1,6 %. Lorsque les interactions de représentation croisée sont explicitement introduites à partir des fonctionnalités de voxel, le modèle obtient les meilleures performances, améliorant respectivement mAP et NDS de 3,5 % et 4,2 % par rapport à la ligne de base.
6) Occupant les composants de la tâche ; de
est présenté dans le tableau 6 pour l'étude d'ablation sur la tâche d'occupation. Le réseau d'extraction de caractéristiques locales basé sur des voxels apporte une amélioration de 1,96 % du gain en mIoU au modèle de base. Lorsque la tâche de détection est introduite comme signal de supervision auxiliaire, les performances du modèle s'améliorent de 0,4 % mIoU.

7) Autres
Le Tableau 5 et le Tableau 6 montrent que dans le cadre UniVision, les tâches de détection et les tâches d'occupation sont complémentaires les unes des autres. Pour les tâches de détection, la supervision de l'occupation peut améliorer les métriques mAP et mATE, indiquant que l'apprentissage sémantique des voxels améliore efficacement la perception par le détecteur de la géométrie de l'objet, c'est-à-dire sa centralité et son échelle. Pour la tâche d'occupation, la supervision de détection améliore considérablement les performances de la catégorie de premier plan (c'est-à-dire la catégorie de détection), ce qui entraîne une amélioration globale.
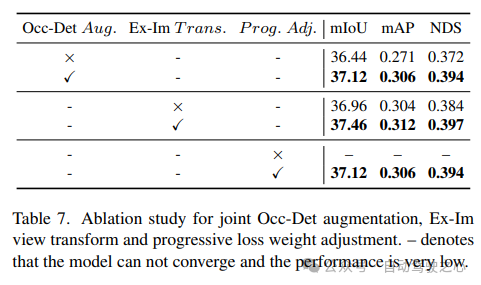
montre l'efficacité de l'amélioration spatiale combinée Occ-Det, du module de conversion de vue Ex-Im et de la stratégie d'ajustement de perte de poids progressive dans le tableau 7. Avec l'augmentation spatiale proposée et le module de transformation de vue proposé, il montre des améliorations significatives dans les tâches de détection et les tâches d'occupation sur les métriques mIoU, mAP et NDS. La stratégie d'ajustement de la perte de poids peut entraîner efficacement le cadre multitâche. Sans cela, la formation du cadre unifié ne peut pas converger et les performances sont très faibles.
Référence
Lien de l'article : https://arxiv.org/pdf/2401.06994.pdf
Nom de l'article : UniVision : Un cadre unifié pour la perception 3D centrée sur la vision
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!