
Maison >Périphériques technologiques >IA >L'Université Tsinghua et l'Institut de technologie de Harbin ont compressé les grands modèles à 1 bit, et le désir d'exécuter de grands modèles sur les téléphones mobiles est sur le point de se réaliser !
L'Université Tsinghua et l'Institut de technologie de Harbin ont compressé les grands modèles à 1 bit, et le désir d'exécuter de grands modèles sur les téléphones mobiles est sur le point de se réaliser !

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-03-04 14:31:291210parcourir
Depuis que les grands modèles sont devenus populaires dans l’industrie, le désir des gens de compresser de grands modèles n’a jamais diminué. En effet, même si les grands modèles présentent d’excellentes capacités à bien des égards, le coût de déploiement élevé augmente considérablement le seuil d’utilisation. Ce coût provient principalement de l'occupation de l'espace et du montant du calcul. La « quantification de modèle » permet d'économiser de l'espace en convertissant les paramètres de grands modèles en représentations à faible largeur de bits. Actuellement, les méthodes traditionnelles peuvent compresser les modèles existants à 4 bits sans pratiquement aucune perte de performances du modèle. Cependant, une quantification inférieure à 3 bits constitue comme un mur infranchissable qui intimide les chercheurs.
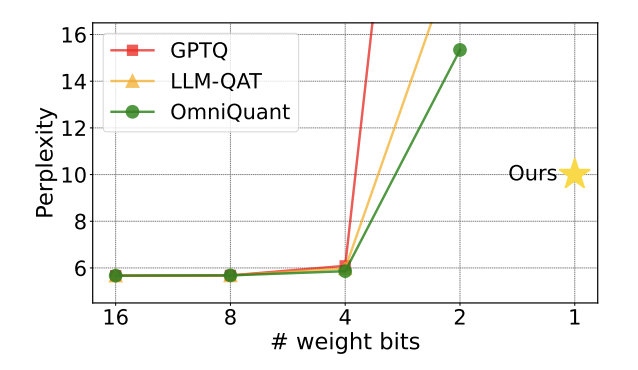
Figure 1 : La perplexité du modèle quantitatif augmente rapidement à 2 bits
Récemment, un article co-publié par l'Université Tsinghua et l'Institut de technologie de Harbin sur arXiv a apporté de grands progrès pour surmonter ce problème L'espoir a attiré une attention considérable dans les cercles universitaires du pays et de l'étranger. Cet article a également été répertorié comme article chaud sur Huggingface il y a une semaine et a été recommandé par le célèbre recommandateur d'articles AK. L'équipe de recherche est allée directement au-delà du niveau de quantification à 2 bits et a tenté avec audace une quantification à 1 bit, ce qui était la première fois dans la recherche sur la quantification de modèles.

Titre de l'article : OneBit : Towards Extremely Low-bit Large Language Models
Adresse de l'article : https://arxiv.org/pdf/2402.11295.pdf
La méthode proposée par l'auteur s'appelle "OneBit" et décrit très bien l'essence de ce travail : Compressez le grand modèle pré-entraîné en un vrai 1 bit. Cet article propose une nouvelle méthode de représentation 1 bit des paramètres du modèle, ainsi qu'une méthode d'initialisation pour les paramètres quantifiés du modèle, et migre les capacités des modèles pré-entraînés de haute précision vers des modèles quantifiés 1 bit grâce à une formation prenant en compte la quantification ( QAT). Les expériences montrent que cette méthode peut fortement compresser les paramètres du modèle tout en garantissant au moins 83 % de performances du modèle LLaMA.
L'auteur a souligné que lorsque les paramètres du modèle sont compressés à 1 bit, la « multiplication d'éléments » dans la multiplication matricielle n'existera plus, et sera remplacée par une opération « d'affectation de bits » plus rapide, ce qui améliorera considérablement le calcul efficacité. L’importance de cette recherche est qu’elle comble non seulement l’écart de quantification à 2 bits, mais qu’elle permet également de déployer de grands modèles sur PC et smartphones.
Limitations des travaux existants
La quantification du modèle permet principalement d'obtenir une compression spatiale en convertissant la couche nn.Linear du modèle (à l'exception de la couche Embedding et de la couche Lm_head) en une représentation de faible précision. La base des travaux précédents [1,2] consiste à utiliser la méthode Round-To-Nearest (RTN) pour mapper approximativement des nombres à virgule flottante de haute précision sur une grille entière proche. Cela peut être exprimé par 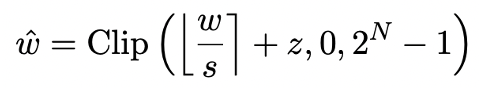 .
.
Cependant, la méthode basée sur RTN présente de sérieux problèmes de perte de précision à une largeur de bit extrêmement faible (inférieure à 3 bits), et la perte de capacité du modèle après quantification est très grave. En particulier, lorsque les paramètres quantifiés sont exprimés sur 1 bit, le coefficient d'échelle s et le point zéro z dans RTN perdront leur signification pratique. Cela rend la méthode de quantification basée sur RTN presque inefficace pour la quantification sur 1 bit, ce qui rend difficile la conservation efficace des performances du modèle d'origine.
De plus, des recherches antérieures ont également exploré la structure que le modèle 1 bit peut adopter. Les travaux d'il y a quelques mois sur BitNet [3] implémentent la représentation 1 bit en passant les paramètres du modèle via la fonction Sign (・) et en les convertissant en + 1/-1. Cependant, cette méthode souffre d’une perte de performance importante et d’un processus de formation instable, ce qui limite son application pratique. Le cadre de méthodes de
OneBit Framework
OneBit comprend une nouvelle structure de couche de 1 bit, une méthode d'initialisation des paramètres basée sur SVID et un transfert de connaissances basé sur la distillation des connaissances prenant en compte la quantification.
1. Nouvelle structure 1bit
Le but ultime de OneBit est de compresser la matrice de poids des LLM à 1 bit. Le vrai 1 bit nécessite que chaque valeur de poids ne puisse être représentée que par 1 bit, c'est-à-dire qu'il n'y a que deux états possibles. L'auteur estime que dans les paramètres des grands modèles, deux facteurs importants doivent être pris en compte, à savoir la haute précision des nombres à virgule flottante et le rang élevé de la matrice des paramètres.
Par conséquent, l'auteur introduit deux vecteurs de valeurs au format FP16 pour compenser la perte de précision due à la quantification. Cette conception maintient non seulement le rang élevé de la matrice de poids d'origine, mais fournit également la précision en virgule flottante nécessaire via le vecteur de valeurs, ce qui facilite la formation du modèle et le transfert de connaissances. La comparaison entre la structure de la couche linéaire 1 bit et la structure de la couche linéaire de haute précision FP16 est la suivante :
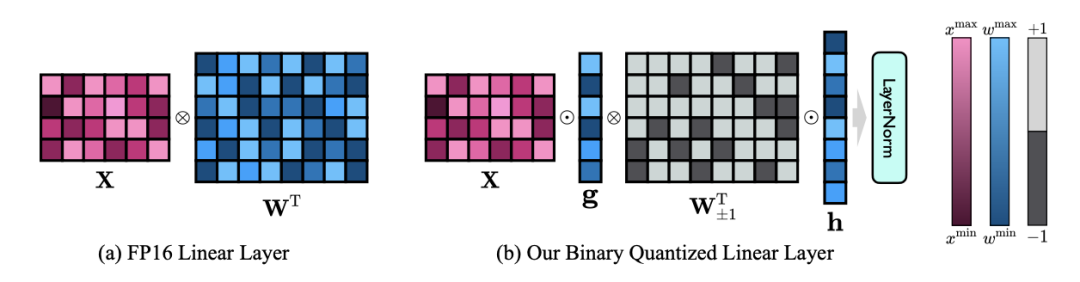
Figure 3 : Comparaison entre la couche linéaire FP16 et la couche linéaire OneBit
(a) sur à gauche se trouve la structure du modèle de précision FP16, (b) à droite se trouve la couche linéaire du framework OneBit. On constate que dans le framework OneBit, seuls les vecteurs de valeurs g et h restent au format FP16, tandis que la matrice de poids est entièrement composée de ±1. Une telle structure prend en compte à la fois l’exactitude et le rang et est très utile pour garantir un processus d’apprentissage stable et de haute qualité.
Dans quelle mesure OneBit compresse-t-il le modèle ? L'auteur donne un calcul dans l'article. En supposant qu'une couche linéaire 4096*4096 soit compressée, OneBit nécessite une matrice 4096*4096 1 bit et deux vecteurs de valeurs 4096*1 16 bits. Le nombre total de bits est de 16 908 288 et le nombre total de paramètres est de 16 785 408. En moyenne, chaque paramètre n'occupe qu'environ 1,0073 bits. Ce type de compression est sans précédent et on peut dire qu'il s'agit d'un véritable modèle de 1 bit.
2. Initialiser le modèle quantifié basé sur SVID
Afin d'utiliser le modèle original entièrement formé pour mieux initialiser le modèle quantifié et ainsi favoriser un meilleur effet de transfert de connaissances, l'auteur propose un nouveau paramètre La matrice La méthode de factorisation est appelée « factorisation matricielle indépendante du signe de la valeur (SVID) ». Cette méthode de décomposition matricielle sépare les symboles et les valeurs absolues et effectue une approximation de rang 1 sur les valeurs absolues. Sa méthode d'approximation des paramètres matriciels d'origine peut être exprimée comme suit :
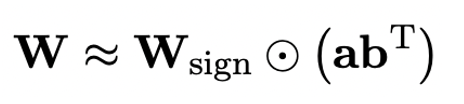
L'approximation de rang 1 ici peut être utilisée par. la factorisation matricielle commune est implémentée, telle que la décomposition en valeurs singulières (SVD) et la factorisation matricielle non négative (NMF). Ensuite, l'auteur montre mathématiquement que cette méthode SVID peut correspondre au cadre du modèle 1 bit en échangeant l'ordre des opérations, réalisant ainsi l'initialisation des paramètres. De plus, l'article prouve également que la matrice symbolique joue un rôle dans l'approximation de la matrice originale pendant le processus de décomposition.
3. Migrer les capacités du modèle original grâce à la distillation des connaissances
L'auteur a souligné qu'un moyen efficace de résoudre la quantification à largeur de bit ultra-faible des grands modèles pourrait être la formation QAT prenant en compte la quantification. Dans la structure du modèle OneBit, la distillation des connaissances est utilisée pour apprendre du modèle non quantifié afin de réaliser la migration des capacités vers le modèle quantifié. Plus précisément, le modèle étudiant est principalement guidé par les logits et l’état caché du modèle enseignant. Lors de l'entraînement, les valeurs du vecteur de valeurs et de la matrice seront mises à jour. Une fois la quantification du modèle terminée, les paramètres après Sign (・) sont directement enregistrés et utilisés directement lors de l'inférence et du déploiement.
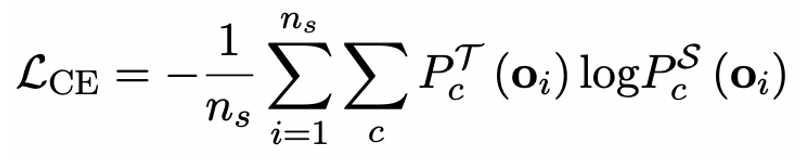 Expériences et résultats
Expériences et résultats
OneBit a été comparé à FP16 Transformer, la base de base forte de quantification post-entraînement classique GPTQ, la base de base forte d'entraînement prenant en compte la quantification LLM-QAT et la dernière base de base forte de quantification de poids 2 bits OmniQuant . De plus, comme il n'y a actuellement aucune recherche sur la quantification de poids 1 bit, l'auteur utilise uniquement la quantification de poids 1 bit pour son framework OneBit et adopte des paramètres de quantification 2 bits pour d'autres méthodes, ce qui est une « vulnérabilité typique des faibles ». aux forts".
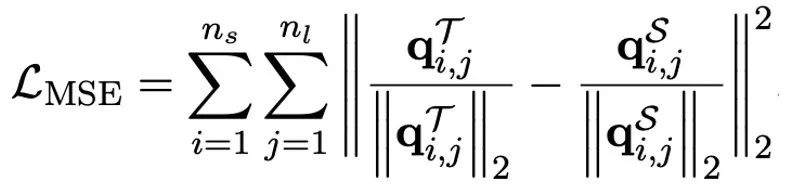
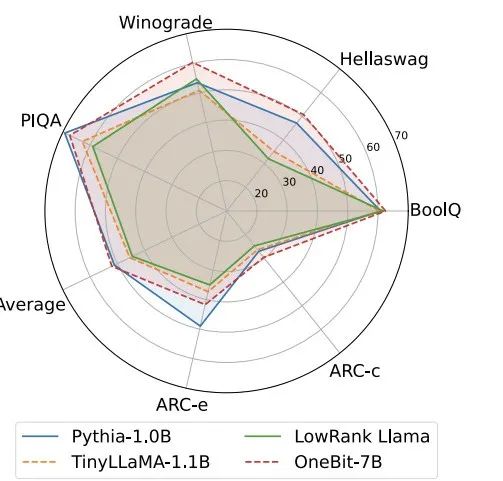
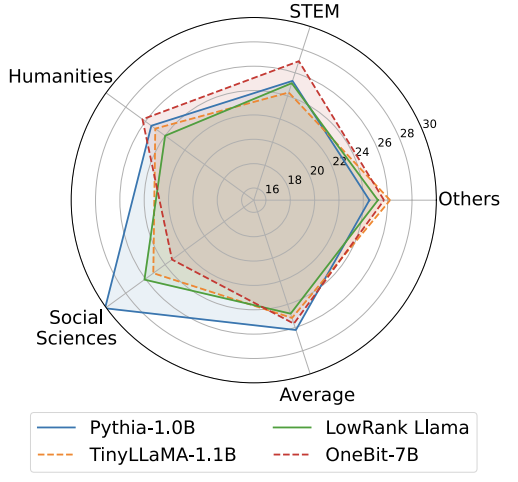
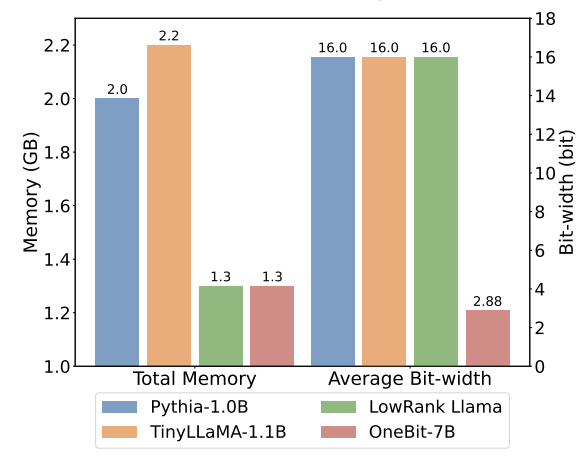
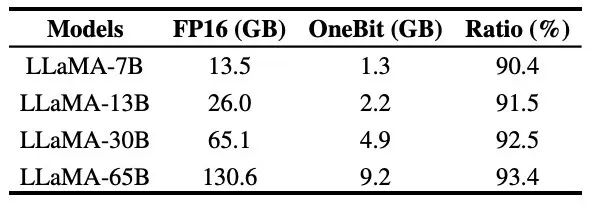
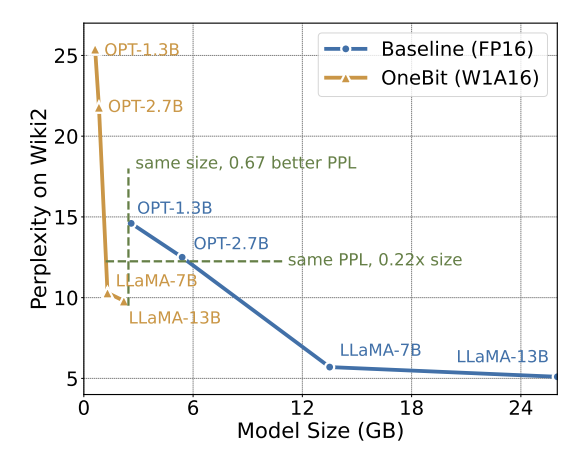
Tableau 1 : Comparaison de l'effet de OneBit et de la méthode de base (modèle OPT et modèle LLaMA-1) Tableau 2 : Comparaison de l'effet de OneBit et de la méthode de base (LLaMA- 2 modèle) Le Tableau 1 et le Tableau 2 montrent les avantages de OneBit par rapport aux autres méthodes de quantification 1 bit. En termes de quantification de la perplexité du modèle sur l'ensemble de validation, OneBit est le plus proche du modèle FP16. En termes de précision zéro, le modèle de quantification OneBit a atteint presque les meilleures performances, à l'exception des ensembles de données individuels du modèle OPT. Les méthodes de quantification sur 2 bits restantes montrent des pertes plus importantes sur les deux métriques d'évaluation. Il convient de noter que OneBit a tendance à mieux fonctionner lorsque le modèle est plus grand. Autrement dit, à mesure que la taille du modèle augmente, le modèle de précision FP16 a peu d'effet sur la réduction de la perplexité, mais OneBit montre une plus grande réduction de la perplexité. En outre, les auteurs soulignent également qu’une formation prenant en compte la quantification peut être nécessaire pour une quantification à très faible largeur de bit. Figure 4: Comparaison des tâches de raisonnement de bon sens Figure 5: Comparaison des connaissances mondiales Figure 6: Occupation spatiale et largeur de bit moyenne de plusieurs modèles Figure 4 - La figure 6 compare également l'occupation de l'espace et la perte de performances de plusieurs types de petits modèles, qui sont obtenus via différents canaux : y compris deux modèles entièrement entraînés Pythia-1.0B et TinyLLaMA-1.1B, et via des modèles de bas rang. LowRank Llama et OneBit-7B obtenus par décomposition. On peut voir que bien que OneBit-7B ait la plus petite largeur de bit moyenne et occupe le plus petit espace, il est toujours meilleur que les autres modèles en termes de capacités de raisonnement de bon sens. L’auteur souligne également que les modèles sont confrontés à un grave oubli des connaissances dans le domaine des sciences sociales. Dans l'ensemble, le OneBit-7B démontre sa valeur pratique. Comme le montre la figure 7, le modèle LLaMA-7B quantifié OneBit démontre des capacités de génération de texte fluides après des instructions de réglage fin. Figure 7 : Capacités du modèle LLaMA-7B quantifiées par le framework OneBit 1. Tableau 3 : OneBit dans différentes compressions rapport du modèle LLaMA
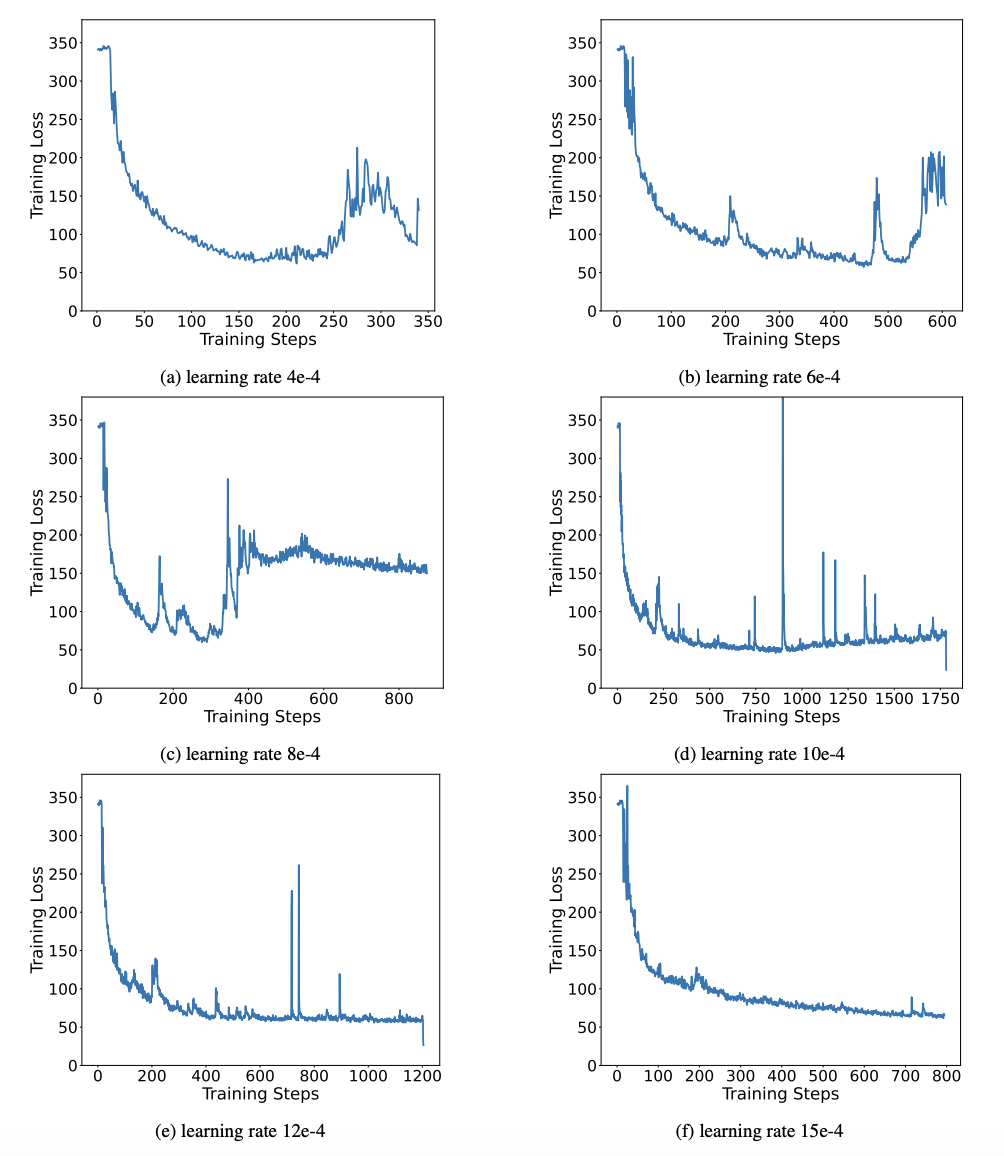
Figure 8 : compromis entre la taille du modèle et les performances De plus, l'auteur a également souligné les avantages informatiques du modèle de quantification 1 bit. Les paramètres étant purement binaires, ils peuvent être représentés sur 1 bit par 0/1, ce qui permet sans aucun doute un gain de place important. La multiplication d'éléments de la multiplication matricielle dans les modèles de haute précision peut être transformée en opérations binaires efficaces qui peuvent être complétées avec uniquement l'affectation et l'ajout de bits, ce qui offre de grandes perspectives d'application. 2. Robustesse Les réseaux binaires sont généralement confrontés à des problèmes de formation instable et de convergence difficile. Grâce au vecteur de valeur de haute précision introduit par l'auteur, le calcul avant et le calcul arrière de la formation du modèle sont très stables. BitNet a proposé plus tôt une structure de modèle 1 bit, mais cette structure a du mal à transférer les capacités d'un modèle de haute précision entièrement formé. Comme le montre la figure 9, l'auteur a essayé différents taux d'apprentissage pour tester la capacité d'apprentissage par transfert de BitNet et a constaté que sa convergence était difficile sous la direction d'un enseignant, ce qui a également prouvé la valeur de formation stable de OneBit. Figure 9 : Capacités de quantification post-formation de BitNet sous différents taux d'apprentissage À la fin de l'article, l'auteur a également suggéré de futures orientations de recherche possibles pour une largeur de bit ultra-faible. Par exemple, trouvez une meilleure méthode d'initialisation des paramètres, moins de coûts de formation, ou envisagez davantage la quantification des valeurs d'activation. Veuillez consulter le document original pour plus de détails techniques. 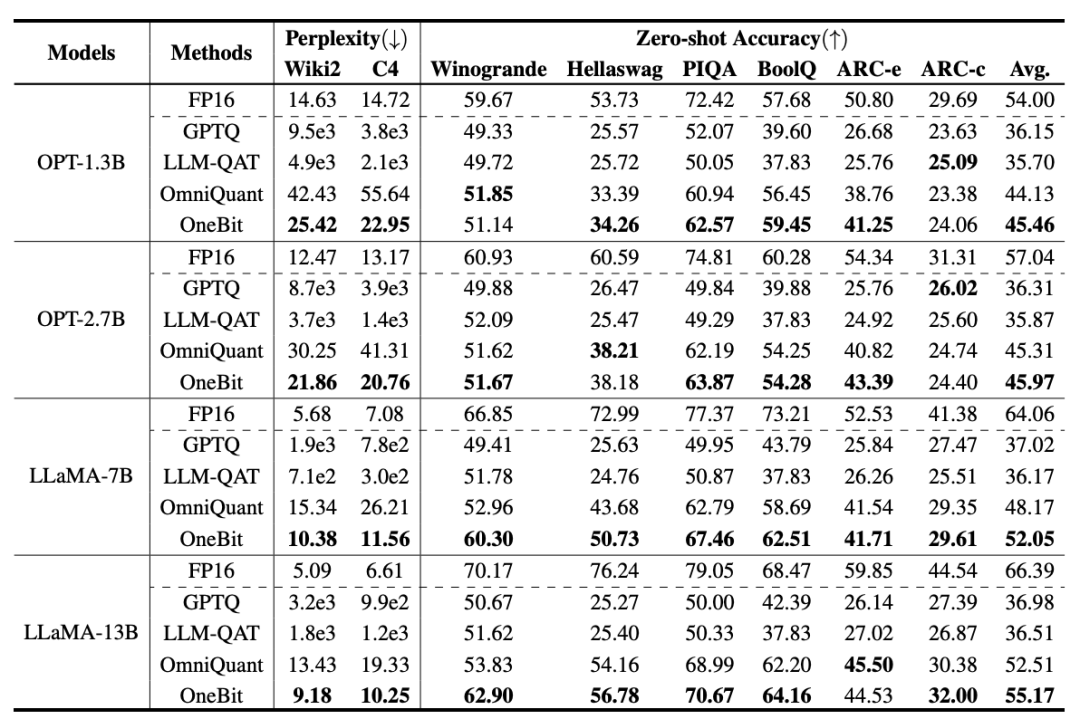

Discussion et analyse
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!