
Maison >Périphériques technologiques >IA >RoSA : une nouvelle méthode pour un réglage fin efficace des paramètres de grands modèles
RoSA : une nouvelle méthode pour un réglage fin efficace des paramètres de grands modèles

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-18 17:27:17813parcourir
À mesure que les modèles de langage évoluent à une échelle sans précédent, le réglage fin complet des tâches en aval devient coûteux. Afin de résoudre ce problème, les chercheurs ont commencé à s’intéresser à la méthode PEFT et à l’adopter. L'idée principale de la méthode PEFT est de limiter la portée du réglage fin à un petit ensemble de paramètres afin de réduire les coûts de calcul tout en atteignant des performances de pointe sur les tâches de compréhension du langage naturel. De cette manière, les chercheurs peuvent économiser des ressources informatiques tout en maintenant des performances élevées, ouvrant ainsi la voie à de nouveaux points chauds de recherche dans le domaine du traitement du langage naturel.
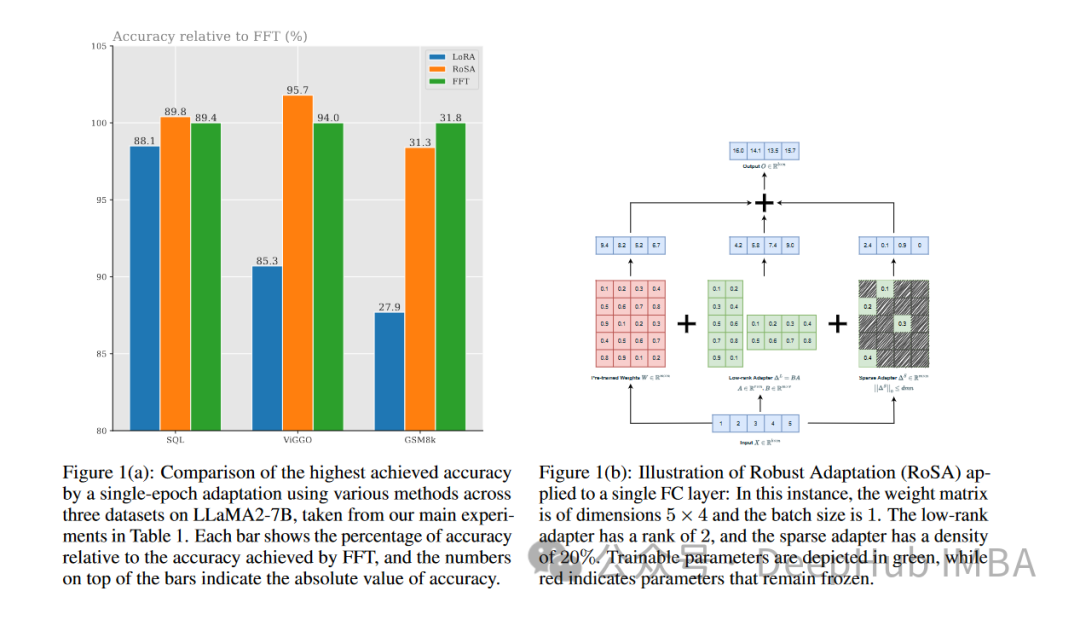
RoSA est une nouvelle technique PEFT. Grâce à des expériences sur un ensemble de références, il a été constaté que RoSA fonctionnait mieux que la précédente adaptation de bas rang (LoRA) tout en utilisant le même budget de paramètres et une amende pure et clairsemée. -méthodes de réglage.
Cet article approfondira les principes, les méthodes et les résultats du RoSA, expliquant comment ses performances marquent des progrès significatifs. Pour ceux qui souhaitent affiner efficacement de grands modèles de langage, RoSA propose une nouvelle solution supérieure aux solutions précédentes.
La nécessité d'un réglage fin et efficace des paramètres
NLP a été révolutionné par des modèles de langage basés sur des transformateurs tels que GPT-4. Ces modèles apprennent des représentations linguistiques puissantes grâce à une pré-formation sur de grands corpus de textes. Ils transfèrent ensuite ces représentations vers des tâches linguistiques en aval via un processus simple.
À mesure que la taille du modèle passe de milliards à des milliards de paramètres, le réglage fin entraîne une énorme charge de calcul. Par exemple, pour un modèle comme GPT-4 avec 1 760 milliards de paramètres, le réglage fin peut coûter des millions de dollars. Cela rend le déploiement dans des applications réelles très peu pratique.
La méthode PEFT améliore l'efficacité et la précision en limitant la plage de paramètres de réglage fin. Récemment, diverses technologies PEFT ont vu le jour, offrant un compromis entre efficacité et précision.
LoRA
Une méthode PEFT importante est l'adaptation de bas rang (LoRA). LoRA a été lancée en 2021 par des chercheurs du Meta et du MIT. Cette approche est motivée par leur observation selon laquelle le transformateur présente une structure de bas rang dans sa matrice de tête. Il est proposé que LoRA tire parti de cette structure de bas rang pour réduire la complexité de calcul et améliorer l'efficacité et la vitesse du modèle.
LoRA affine uniquement les k premiers vecteurs singuliers, tandis que les autres paramètres restent inchangés. Cela nécessite uniquement O(k) paramètres supplémentaires à régler, au lieu de O(n).
En tirant parti de cette structure de bas rang, LoRA peut capturer des signaux significatifs nécessaires à la généralisation des tâches en aval et limiter le réglage fin à ces principaux vecteurs singuliers, rendant l'optimisation et l'inférence plus efficaces.
Les expériences montrent que LoRA peut égaler les performances entièrement affinées du benchmark GLUE tout en utilisant plus de 100 fois moins de paramètres. Cependant, à mesure que la taille du modèle continue de croître, l'obtention de performances élevées grâce à LoRA nécessite d'augmenter le rang k, ce qui réduit les économies de calcul par rapport à un réglage fin complet.
Avant RoSA, LoRA représentait l'état de l'art des méthodes PEFT, avec seulement des améliorations modestes utilisant des techniques telles que différentes factorisations matricielles ou l'ajout d'un petit nombre de paramètres de réglage fin supplémentaires.
Robust Adaptation (RoSA)
Robust Adaptation (RoSA) introduit une nouvelle méthode de réglage fin efficace en termes de paramètres. RoSA s’inspire d’une analyse robuste en composantes principales (PCA robuste), plutôt que de s’appuyer uniquement sur des structures de bas rang.
Dans l'analyse traditionnelle en composantes principales, la matrice de données La PCA robuste va encore plus loin et décompose X en un L propre de bas rang et un S clairsemé « contaminé/corrompu ».
RoSA s'en inspire et décompose le réglage fin du modèle de langage en :
Une matrice adaptative (L) de bas rang de type LoRA, affinée pour se rapprocher du signal dominant pertinent pour la tâche
A hauteur Une matrice de réglage fin (S) clairsemée contenant un très petit nombre de grands paramètres sélectivement affinés qui codent le signal résiduel manqué par L.
La modélisation explicite de la composante clairsemée résiduelle permet à RoSA d'atteindre une précision supérieure à celle de LoRA seule.
RoSA construit L en effectuant une décomposition de bas rang de la matrice principale du modèle. Cela codera les représentations sémantiques sous-jacentes utiles pour les tâches en aval. RoSA ajuste ensuite sélectivement les m paramètres les plus importants de chaque couche sur S, tandis que tous les autres paramètres restent inchangés. Cette étape capture les signaux résiduels qui ne conviennent pas à un ajustement de bas rang.
Le nombre de paramètres de réglage fin m est d'un ordre de grandeur inférieur au rang k requis par LoRA seul. Par conséquent, combiné à la matrice de tête de bas rang en L, RoSA maintient une efficacité de paramètre extrêmement élevée.
RoSA utilise également d'autres optimisations simples mais efficaces :
Connexion résiduelle clairsemée : les résidus S sont ajoutés directement à la sortie de chaque bloc de transformateur avant qu'il ne passe par la normalisation des couches et les sous-couches de rétroaction. Cela peut simuler des signaux manqués par L.
Masques clairsemés indépendants : les métriques sélectionnées dans S pour le réglage fin sont générées indépendamment pour chaque couche de transformateur.
Structure de bas rang partagée : les mêmes matrices U,V de base de bas rang sont partagées entre toutes les couches de L, tout comme dans LoRA. Cela capturera les concepts sémantiques dans un sous-espace cohérent.
Ces choix architecturaux offrent à la modélisation RoSA une flexibilité similaire à un réglage fin complet, tout en conservant l'efficacité des paramètres pour l'optimisation et l'inférence. En utilisant cette méthode PEFT qui combine une adaptation robuste de bas rang et des résidus très clairsemés, RoSA réalise une nouvelle technologie de compromis précision-efficacité.
Expériences et résultats
Les chercheurs ont évalué RoSA sur un benchmark complet de 12 ensembles de données NLU couvrant des tâches telles que la détection de texte, l'analyse des sentiments, l'inférence du langage naturel et les tests de robustesse. Ils ont mené des expériences en utilisant RoSA basé sur l'assistant d'intelligence artificielle LLM, en utilisant un modèle de 12 milliards de paramètres.
Sur chaque tâche, RoSA fonctionne nettement mieux que LoRA en utilisant les mêmes paramètres. Les paramètres totaux des deux méthodes représentent environ 0,3 % de l'ensemble du modèle. Cela signifie qu’il existe environ 4,5 millions de paramètres de réglage fin dans les deux cas pour k = 16 pour LoRA et m = 5 120 pour RoSA.
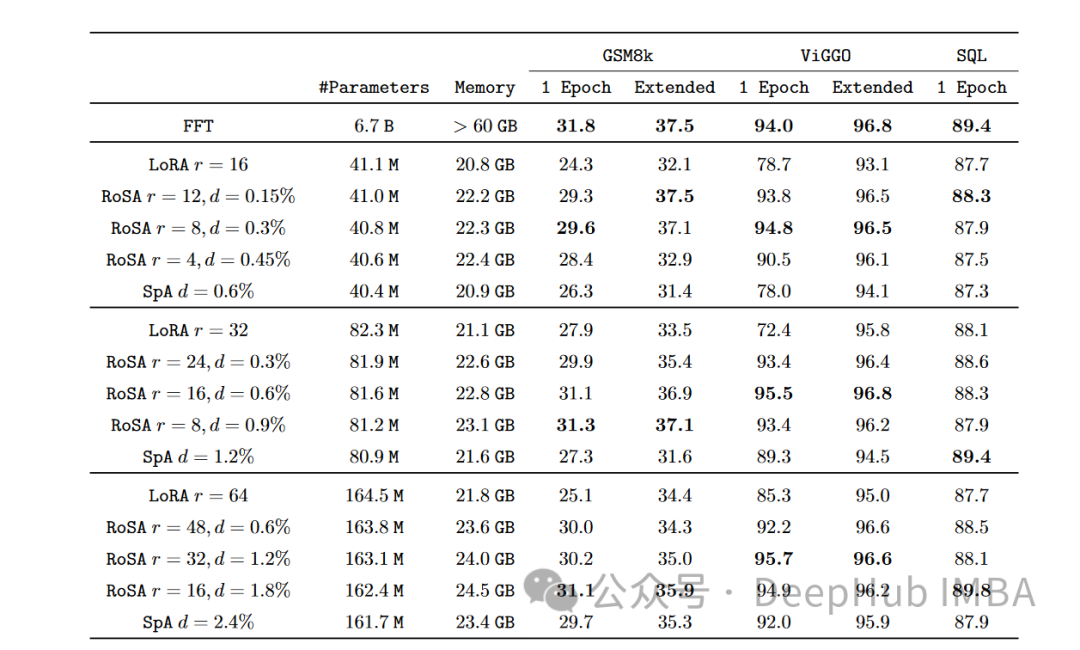
RoSA égale ou dépasse également les performances des lignes de base pures et affinées.
Sur le benchmark ANLI qui évalue la robustesse aux exemples contradictoires, RoSA obtient un score de 55,6, tandis que LoRA obtient un score de 52,7. Cela démontre des améliorations en matière de généralisation et d’étalonnage.
Pour les tâches d'analyse des sentiments SST-2 et IMDB, la précision de RoSA atteint 91,2 % et 96,9 %, tandis que la précision de LoRA atteint 90,1 % et 95,3 %.
Sur WIC, un test difficile de désambiguïsation du sens des mots, RoSA a obtenu un score F1 de 93,5, tandis que LoRA a obtenu un score F1 de 91,7.
Sur les 12 ensembles de données, RoSA affiche généralement de meilleures performances que LoRA avec des budgets de paramètres correspondants.
Notamment, RoSA est capable d'obtenir ces gains sans nécessiter de réglage ou de spécialisation spécifique à une tâche. RoSA peut donc être utilisé comme solution PEFT universelle.
Résumé
Alors que l'échelle des modèles de langage continue de croître rapidement, réduire les exigences de calcul pour les affiner est un problème urgent qui doit être résolu. Les techniques de formation adaptative efficaces en termes de paramètres, telles que LoRA, ont connu un succès initial, mais se heurtent aux limites inhérentes à l'approximation de bas rang.
RoSA combine organiquement une décomposition robuste de bas rang et un réglage fin résiduel très clairsemé pour fournir une nouvelle solution convaincante. Il améliore considérablement les performances du PEFT en prenant en compte les signaux qui échappent à l'ajustement de bas rang via des résidus sélectifs clairsemés. L'évaluation empirique montre des améliorations significatives par rapport aux lignes de base LoRA et de parcimonie incontrôlée sur différents ensembles de tâches NLU.
RoSA est conceptuellement simple mais performant, et peut faire progresser davantage l'intersection de l'efficacité des paramètres, de la représentation adaptative et de l'apprentissage continu pour développer l'intelligence du langage.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Les paramètres sont légèrement améliorés, et l'indice de performance explose ! Google : les grands modèles de langage cachent des « compétences mystérieuses »
- La précision de GPT-3 dans la résolution de problèmes mathématiques est passée à 92,5 % ! Microsoft propose MathPrompter pour créer des modèles de langage « scientifiques » sans réglage fin
- Un autre 'acteur fort' a été ajouté dans le domaine de l'IA, Meta publie un nouveau modèle de langage à grande échelle LLaMA
- Six façons de créer des chatbots IA et de grands modèles linguistiques pour améliorer la cybersécurité
- La première entreprise nationale, 360 Intelligent Brain, a réussi l'évaluation fiable des fonctions du grand modèle de langage AIGC de l'Académie chinoise des technologies de l'information et des communications.