
Maison >Périphériques technologiques >IA >La stratégie innovante de « méta-astuce » de l'équipe Byte Fudan a amélioré les performances de compréhension des images du modèle de diffusion, atteignant un niveau sans précédent !
La stratégie innovante de « méta-astuce » de l'équipe Byte Fudan a amélioré les performances de compréhension des images du modèle de diffusion, atteignant un niveau sans précédent !

- 王林avant
- 2024-01-17 12:48:13755parcourir
Le modèle de diffusion texte-image (T2I) excelle dans la génération d'images haute définition grâce à son pré-entraînement sur des paires image-texte à grande échelle.
Cela nous amène à une question naturelle : les modèles de diffusion peuvent-ils être utilisés pour résoudre des tâches de perception visuelle ?
Récemment, des équipes de ByteDance et de l'Université de Fudan ont proposé un modèle de diffusion pour gérer les tâches visuelles.

Adresse papier : https://arxiv.org/abs/2312.14733
Projet open source : https://github.com/fudan-zvg/meta-prompts
La clé pour l'équipe Insight est l'introduction de méta-indices apprenables dans des modèles de diffusion pré-entraînés pour extraire des fonctionnalités adaptées à des tâches de perception spécifiques.
Introduction technique
L'équipe applique le modèle de diffusion texte-image comme extracteur de fonctionnalités aux tâches de perception visuelle.
Tout d'abord, l'image d'entrée est compressée par l'encodeur VQVAE, la résolution est réduite à 1/8 de la taille d'origine et une représentation des caractéristiques de l'espace latent est générée. Il est à noter que les paramètres du codeur VQVAE sont fixes et ne participent pas à la formation ultérieure.
L'étape suivante consiste à envoyer les données sans bruit supplémentaire à UNet pour l'extraction des fonctionnalités. Pour mieux s'adapter aux différentes tâches, UNet reçoit simultanément des intégrations de pas de temps modulés et plusieurs méta-repères pour générer des caractéristiques de forme cohérente.
Pendant tout le processus, afin d'améliorer l'expression des caractéristiques, cette méthode effectue des affinements répétés. Cela permet une meilleure fusion interactive des fonctionnalités de différentes couches au sein d'UNet. Dans le deuxième cycle, les paramètres d'UNet sont ajustés par des fonctionnalités de modulation temporelle spécifiques apprenables.
Enfin, les fonctionnalités multi-échelles générées par UNet sont entrées dans un décodeur spécialement conçu pour la tâche de vision cible.
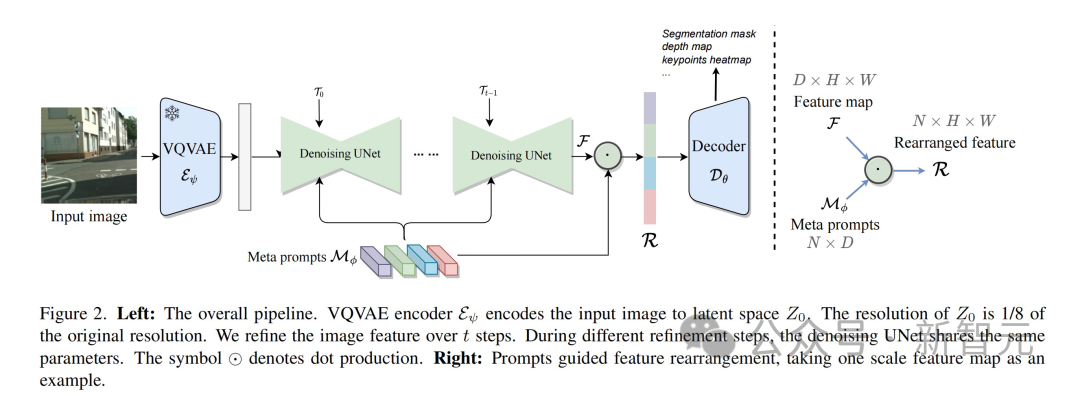
Conception de méta-invites apprenables
Le modèle de diffusion stable adopte l'architecture UNet pour intégrer des invites de texte dans les caractéristiques de l'image grâce à une attention croisée, réalisant ainsi un graphique vincentien. Cette intégration garantit que la génération d’images est contextuellement et sémantiquement précise.
Cependant, la diversité des tâches de perception visuelle va au-delà de cette catégorie, car la compréhension des images est confrontée à différents défis et manque souvent d'informations textuelles comme guide, ce qui rend les méthodes basées sur le texte parfois peu pratiques.
Pour relever ce défi, l'approche de l'équipe technique adopte une stratégie plus diversifiée : au lieu de s'appuyer sur des invites textuelles externes, nous concevons des méta-invites internes apprenables appelées méta-invites. Ces méta-invites sont intégrées dans les modèles de diffusion pour s'adapter. aux tâches de perception.
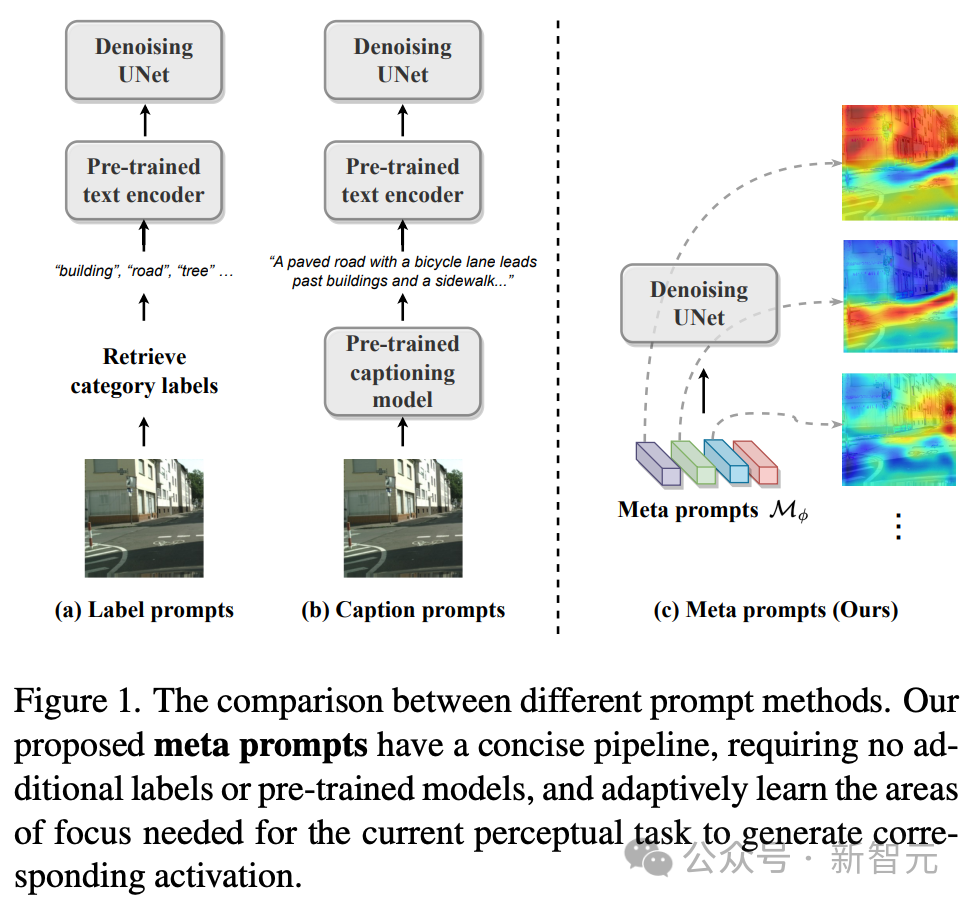
Les méta-invites sont exprimées sous la forme d'une matrice, qui représente le nombre de méta-invites et représente la dimension. Les modèles de diffusion perceptuelle avec des méta-invites évitent le besoin d'invites de texte externes, telles que des étiquettes de catégorie d'ensemble de données ou des titres d'images, et ne nécessitent pas d'encodeur de texte pré-entraîné pour générer les invites de texte finales.
Les méta-invites peuvent être entraînées de bout en bout en fonction des tâches cibles et des ensembles de données afin d'établir des conditions d'adaptation spécialement personnalisées pour débruiter UNet. Ces méta-invites contiennent de riches informations sémantiques adaptées à des tâches spécifiques. Par exemple :
- Dans la tâche de segmentation sémantique, les méta-invites démontrent efficacement la capacité à identifier les catégories, et les mêmes méta-invites ont tendance à activer les fonctionnalités de la même catégorie.

- Dans la tâche d'estimation de la profondeur, les méta-invites montrent la capacité de percevoir la profondeur, et la valeur d'activation change avec la profondeur, permettant aux invites de se concentrer sur des objets à la même distance.

- Dans l'estimation de pose, les méta-invites présentent un ensemble différent de capacités, en particulier la perception des points clés, ce qui aide à la détection de pose humaine.
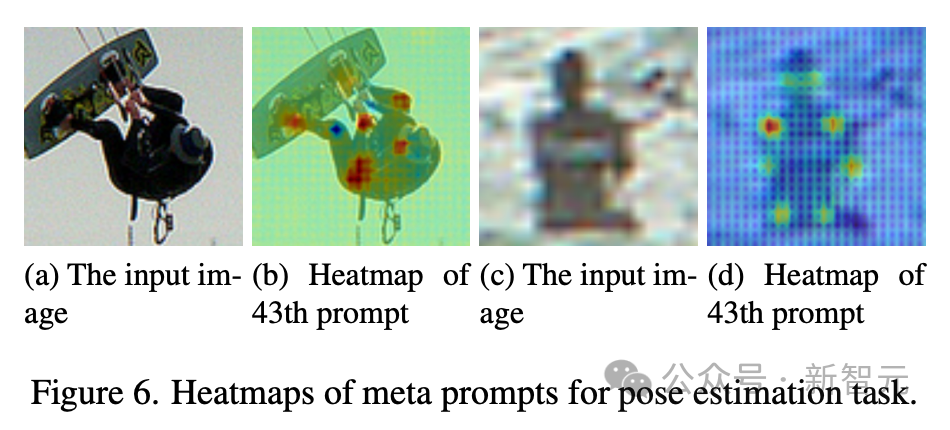
Ensemble, ces résultats qualitatifs mettent en évidence l'efficacité des méta-invites proposées par l'équipe technique pour activer les capacités liées à la tâche dans diverses tâches.
En tant qu'alternative aux invites textuelles, les méta-invites comblent bien le fossé entre les modèles de diffusion texte-image et les tâches de perception visuelle.
Réorganisation des fonctionnalités basée sur les méta-repères
Le modèle de diffusion, grâce à sa conception inhérente, génère des fonctionnalités multi-échelles dans le débruitage UNet, qui se concentrent sur des informations détaillées plus fines et de bas niveau à l'approche de la couche de sortie.
Bien que ces détails de bas niveau soient suffisants pour les tâches qui mettent l'accent sur la texture et la finesse, les tâches de perception visuelle nécessitent souvent de comprendre un contenu qui inclut à la fois des détails de bas niveau et une interprétation sémantique de haut niveau.
Par conséquent, non seulement il faut générer des fonctionnalités riches, mais il est également très important de déterminer quelle combinaison de ces fonctionnalités multi-échelles peut fournir la meilleure représentation de la tâche en cours.
C'est là qu'interviennent les méta-invites -
Ces invites préservent les connaissances contextuelles spécifiques à l'ensemble de données utilisé pendant la formation. Cette connaissance contextuelle permet aux méta-invites d'agir comme des filtres pour la recombinaison des fonctionnalités, guidant le processus de sélection des fonctionnalités et filtrant les fonctionnalités les plus pertinentes pour la tâche parmi les nombreuses fonctionnalités générées par UNet.
L'équipe utilise une approche de produit scalaire pour combiner la richesse des fonctionnalités multi-échelles d'UNet avec l'adaptabilité des tâches des méta-invites.
Considérez les fonctionnalités multi-échelles, chacune d'elles. et représentent la hauteur et la largeur de la carte des caractéristiques. Méta-invites. Les caractéristiques réorganisées à chaque échelle sont calculées comme suit :
Enfin, ces caractéristiques filtrées par des méta-invites sont ensuite entrées dans un décodeur spécifique à la tâche.
Raffinement récurrent basé sur des fonctionnalités de modulation temporelle apprenables
Dans le modèle de diffusion, le processus itératif d'ajout de bruit puis de débruitage en plusieurs étapes constitue le cadre de génération d'images.
Inspirée par ce mécanisme, l'équipe technique a conçu un processus de raffinement récurrent simple pour les tâches de perception visuelle : au lieu d'ajouter du bruit aux fonctionnalités de sortie, les fonctionnalités de sortie d'UNet sont directement entrées dans UNet en boucle.
Dans le même temps, afin de résoudre le problème incohérent selon lequel, lorsque le modèle passe dans la boucle, la distribution des caractéristiques d'entrée change mais les paramètres d'UNet restent inchangés, l'équipe technique a introduit des intégrations de pas de temps apprenables et uniques pour chaque boucle pour moduler les paramètres UNet.
Cela garantit que le réseau reste adaptable et réactif à la variabilité des caractéristiques d'entrée à différentes étapes, optimise le processus d'extraction de caractéristiques et améliore les performances du modèle dans les tâches de reconnaissance visuelle.
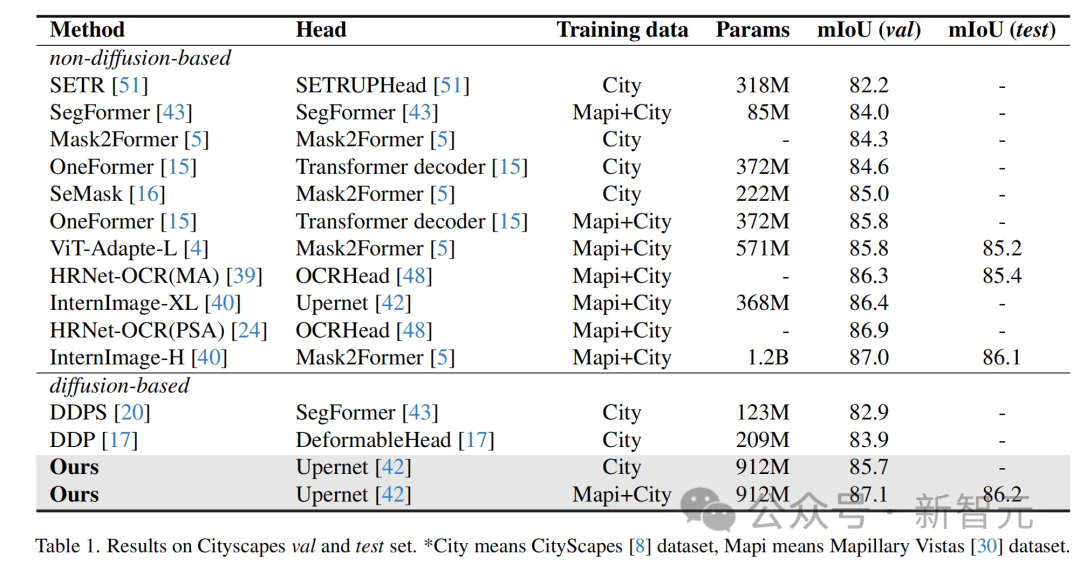
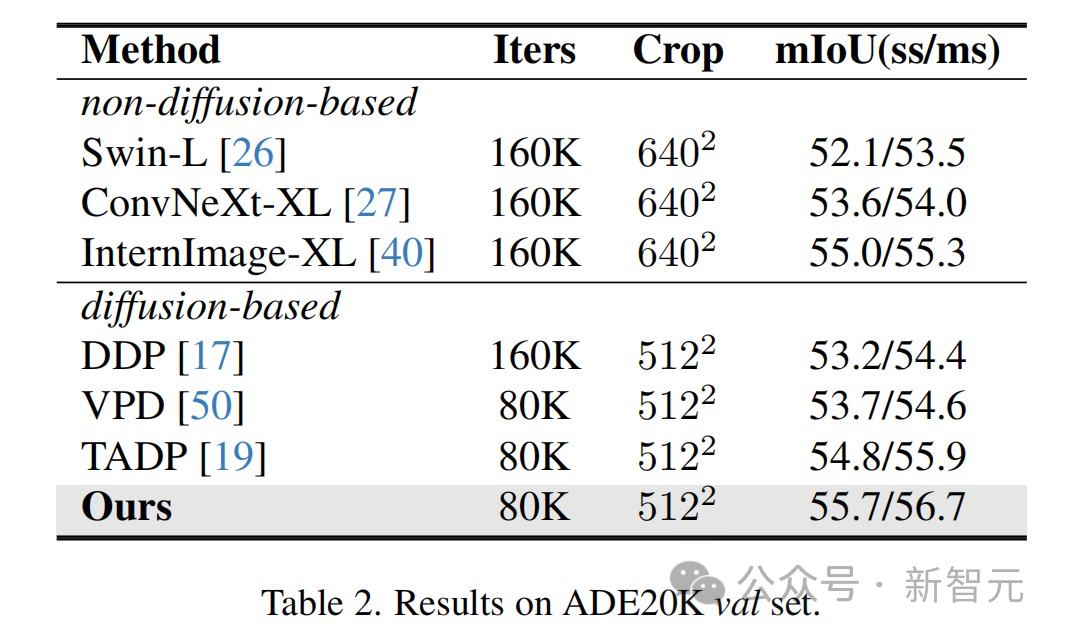
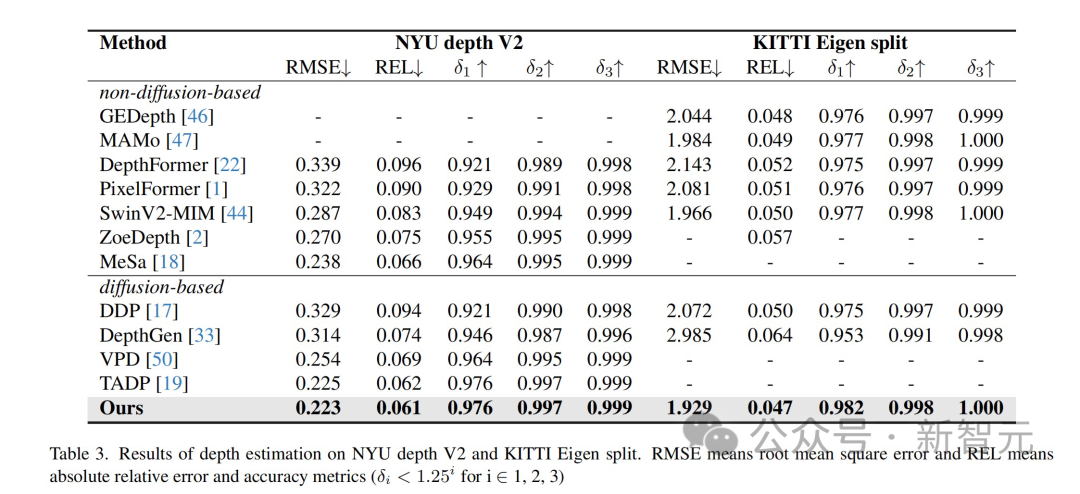
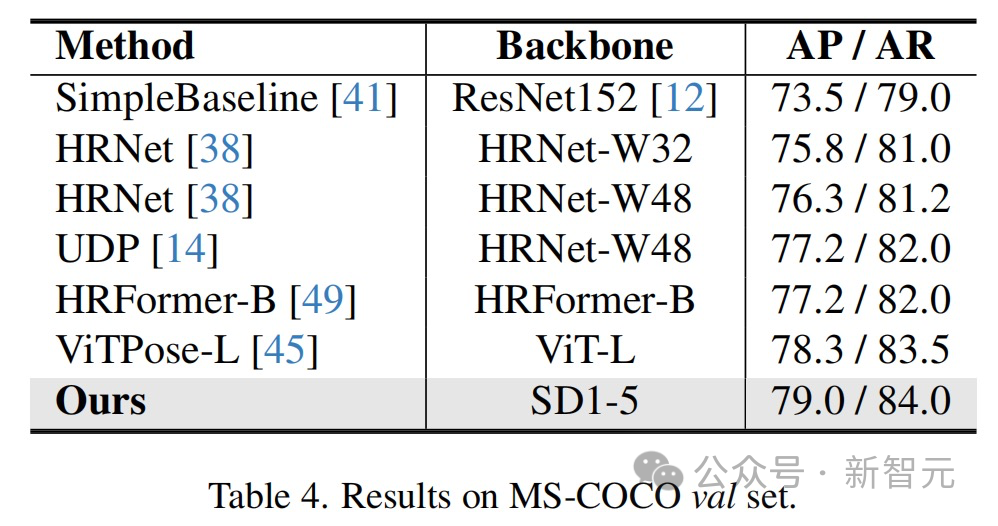
Les résultats montrent que cette méthode a obtenu des résultats optimaux sur plusieurs ensembles de données de tâches de perception.
Mise en œuvre et perspectives d'application
Les méthodes et technologies proposées dans cet article ont de larges perspectives d'application et peuvent promouvoir le développement technologique et l'innovation dans de multiples domaines :
- Améliorations des tâches de perception visuelle : Cette recherche peut améliorer les performances de diverses tâches de perception visuelle, telles que la segmentation d'images, l'estimation de la profondeur et l'estimation de la pose. Ces améliorations peuvent être appliquées à des domaines tels que la conduite autonome, l’analyse d’images médicales et les systèmes de vision robotisée.
- Modèles de vision par ordinateur améliorés : La technologie proposée peut rendre les modèles de vision par ordinateur plus précis et plus efficaces dans le traitement de scènes complexes, notamment en l'absence de descriptions textuelles explicites. Ceci est particulièrement important pour des applications telles que la compréhension du contenu des images.
- Applications interdisciplinaires : Les méthodes et les résultats de cette étude peuvent inspirer des recherches et des applications interdisciplinaires, comme dans la création artistique, la réalité virtuelle et la réalité augmentée, pour améliorer la qualité et l'interactivité des images et des vidéos. .
- Perspectives à long terme : Avec les progrès de la technologie, ces méthodes pourraient être encore améliorées, apportant une technologie de génération d'images et de compréhension de contenu plus avancée.
Présentation de l'équipe
L'équipe de création intelligente est le centre technologique d'IA et multimédia de ByteDance, couvrant la vision par ordinateur, le montage audio et vidéo, le traitement des effets spéciaux et d'autres domaines techniques, en s'appuyant sur les riches scénarios commerciaux, les ressources d'infrastructure et les techniques de l'entreprise. collaboration L'atmosphère réalise une boucle fermée de produits-systèmes d'ingénierie-algorithmes de pointe, visant à fournir aux activités internes de l'entreprise une compréhension de contenu, une création de contenu, une expérience interactive et des capacités de consommation ainsi que des solutions industrielles de pointe sous diverses formes.
Actuellement, l'équipe de création intelligente a ouvert ses capacités techniques et ses services aux entreprises via Volcano Engine, une plateforme de services cloud appartenant à ByteDance. D'autres postes liés aux algorithmes de grands modèles sont ouverts, veuillez cliquer sur 「Lire le texte original」 pour voir.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Code détaillé des questions de formation sur les instructions de base de la base de données Mysql
- Comment supprimer des modèles redondants dans ZBrush
- Quels sont les trois éléments d'un modèle de données ?
- Choqué ! Après 70 000 heures de formation, le modèle OpenAI a appris à planifier le bois dans « Minecraft »
- Utiliser Pytorch pour mettre en œuvre l'apprentissage contrastif SimCLR pour une pré-formation auto-supervisée