
Maison >Périphériques technologiques >IA >Apprentissage par renforcement Deep Q-learning utilisant la simulation de bras robotique de Panda-Gym
Apprentissage par renforcement Deep Q-learning utilisant la simulation de bras robotique de Panda-Gym

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-10-31 17:57:04847parcourir
L'apprentissage par renforcement (RL) est une méthode d'apprentissage automatique qui permet aux agents d'apprendre comment se comporter dans leur environnement par essais et erreurs. Les agents sont récompensés ou punis pour avoir pris des mesures qui conduisent aux résultats souhaités. Au fil du temps, l'agent apprend à prendre des mesures qui maximisent la récompense attendue. Les agents RL sont généralement formés à l'aide des processus de décision de Markov (MDP), qui modélisent le cadre mathématique des problèmes de décision séquentiels. MDP se compose de quatre parties :
Action : un ensemble d'actions qu'un agent peut entreprendre.
- Fonction de transition : une fonction qui prédit la probabilité de transition vers un nouvel état en fonction de l'état et de l'action actuels.
- Fonction de récompense : Une fonction qui attribue une récompense à l'agent pour chaque conversion.
- Le but de l'agent est d'apprendre une fonction politique qui mappe les états aux actions. Maximisez le retour attendu de l'agent au fil du temps grâce à une fonction de politique.
- Deep Q-learning est un algorithme d'apprentissage par renforcement qui utilise des réseaux de neurones profonds pour apprendre les fonctions politiques. Les réseaux de neurones profonds prennent l'état actuel comme entrée et génèrent un vecteur de valeurs, où chaque valeur représente une action possible. L'agent entreprend ensuite l'action en fonction de la valeur la plus élevée
Deep Q-learning est un algorithme d'apprentissage par renforcement basé sur la valeur, ce qui signifie qu'il apprend la valeur de chaque paire état-action. La valeur d’une paire état-action est la récompense attendue par l’agent pour entreprendre cette action dans cet état.
Actor-Critic est un algorithme RL qui combine les valeurs et les politiques. Il y a deux composantes :
Acteur : L'acteur est responsable de la sélection des opérations.
Critique : Responsable de l'évaluation du comportement de l'acteur.
Les acteurs et les critiques sont formés en même temps. Les acteurs sont formés pour maximiser les récompenses attendues et les critiques sont formés pour prédire avec précision les récompenses attendues pour chaque paire état-action
L'algorithme Acteur-Critique présente plusieurs avantages par rapport aux autres algorithmes d'apprentissage par renforcement. Premièrement, il est plus stable, ce qui signifie que les biais sont moins susceptibles de se produire pendant l’entraînement. Deuxièmement, il est plus efficace, ce qui signifie qu’il peut apprendre plus rapidement. Troisièmement, il est mieux évolutif et peut être appliqué à des problèmes avec de grands espaces d'état et d'action. Critique (A2C)
Acteur-Critique est une architecture d'apprentissage par renforcement populaire qui combine des approches basées sur les politiques et basées sur les valeurs. Il présente de nombreux avantages qui en font un choix judicieux pour résoudre diverses tâches d'apprentissage par renforcement :
1. Faible variance
Par rapport aux méthodes traditionnelles de gradient de politique, A2C a généralement des performances inférieures lors de l'entraînement de la variance. En effet, A2C utilise à la fois le gradient politique et la fonction valeur, et utilise la fonction valeur pour réduire la variance dans le calcul du gradient. Une faible variance signifie que le processus de formation est plus stable et peut converger plus rapidement vers une meilleure stratégie

En raison des caractéristiques de faible variance, A2C peut généralement apprendre une politique à une vitesse plus rapide. stratégie. Ceci est particulièrement important pour les tâches qui nécessitent des simulations approfondies, car des vitesses d'apprentissage plus rapides permettent d'économiser un temps et des ressources informatiques précieux.
3. Combiner la fonction de politique et de valeur
Une caractéristique notable d'A2C est qu'il apprend simultanément la fonction de politique et de valeur. Cette combinaison permet à l’agent de mieux comprendre la corrélation entre l’environnement et les actions, guidant ainsi mieux les améliorations politiques. L’existence de la fonction de valeur contribue également à réduire les erreurs d’optimisation des politiques et à améliorer l’efficacité de la formation.
4. Prend en charge les espaces d'action continus et discrets
A2C peut s'adapter à différents types d'espaces d'action, y compris les actions continues et discrètes, et est très polyvalent. Cela fait de l'A2C un algorithme d'apprentissage par renforcement largement applicable qui peut être appliqué à une variété de tâches, du contrôle du robot à l'optimisation du gameplay
5. Entraînement parallèle
A2C peut être facilement parallélisé pour tirer pleinement parti du multicœur serveurs de traitement et ressources informatiques distribuées. Cela signifie que davantage de données empiriques peuvent être collectées en moins de temps, améliorant ainsi l'efficacité de la formation.
Bien que les méthodes Acteur-Critique présentent certains avantages, elles sont également confrontées à certains défis, tels que le réglage des hyperparamètres et l'instabilité potentielle de l'entraînement. Cependant, avec des réglages appropriés et des techniques telles que la relecture d'expérience et les réseaux cibles, ces défis peuvent être atténués dans une large mesure, faisant de l'Acteur-Critique une méthode précieuse d'apprentissage par renforcement

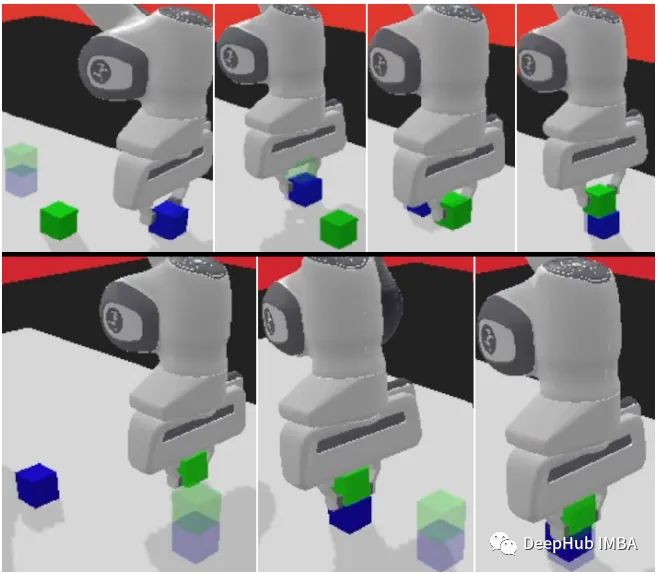
panda-gym
panda-gym est développé sur la base du moteur PyBullet et encapsule 6 tâches telles que atteindre, pousser, glisser, choisir et placer, empiler et retourner autour du bras robotique panda. Il est principalement inspiré. par OpenAI Fetch.
Nous utiliserons panda-gym comme exemple pour montrer le code ci-dessous
1 Installez la bibliothèque
Tout d'abord, nous devons initialiser le code de l'environnement d'apprentissage par renforcement :
. !apt-get install -y \libgl1-mesa-dev \libgl1-mesa-glx \libglew-dev \xvfb \libosmesa6-dev \software-properties-common \patchelf !pip install \free-mujoco-py \pytorch-lightning \optuna \pyvirtualdisplay \PyOpenGL \PyOpenGL-accelerate\stable-baselines3[extra] \gymnasium \huggingface_sb3 \huggingface_hub \ panda_gym
2. Importez la bibliothèque
import os import gymnasium as gym import panda_gym from huggingface_sb3 import load_from_hub, package_to_hub from stable_baselines3 import A2C from stable_baselines3.common.evaluation import evaluate_policy from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize from stable_baselines3.common.env_util import make_vec_env
3. Créez l'environnement d'exécution
env_id = "PandaReachDense-v3" # Create the env env = gym.make(env_id) # Get the state space and action space s_size = env.observation_space.shape a_size = env.action_space print("\n _____ACTION SPACE_____ \n") print("The Action Space is: ", a_size) print("Action Space Sample", env.action_space.sample()) # Take a random action
4. Normalisation des observations et des récompenses
Un bon moyen d'optimiser l'apprentissage par renforcement est de normaliser les fonctionnalités d'entrée. Nous calculons la moyenne mobile et l'écart type des entités d'entrée via le wrapper. Normalisez également les récompenses en ajoutant norm_reward = True
env = make_vec_env(env_id, n_envs=4) env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10.)
5. Créez un modèle A2C
Nous utilisons des agents officiels formés par l'équipe Stable-Baselines3
model = A2C(policy = "MultiInputPolicy",env = env,verbose=1)
6, Entraînez-vous A2C
model.learn(1_000_000) # Save the model and VecNormalize statistics when saving the agent model.save("a2c-PandaReachDense-v3") env.save("vec_normalize.pkl")
7. Agent
from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize # Load the saved statistics eval_env = DummyVecEnv([lambda: gym.make("PandaReachDense-v3")]) eval_env = VecNormalize.load("vec_normalize.pkl", eval_env) # We need to override the render_mode eval_env.render_mode = "rgb_array" # do not update them at test time eval_env.training = False # reward normalization is not needed at test time eval_env.norm_reward = False # Load the agent model = A2C.load("a2c-PandaReachDense-v3") mean_reward, std_reward = evaluate_policy(model, eval_env) print(f"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}")
Résumé
Dans "panda-gym", la combinaison efficace du bras robotique Panda et de l'environnement GYM nous permet d'effectuer facilement un apprentissage par renforcement du bras robotique localement,
Acteur-Critique L'architecture dans laquelle l'agent apprend à apporter des améliorations incrémentielles à chaque pas de temps contraste avec une fonction de récompense clairsemée (dans laquelle le résultat est binaire), ce qui rend la méthode Acteur-Critique particulièrement adaptée à ce type de tâche.
En combinant de manière transparente l'apprentissage des politiques et l'estimation de la valeur, l'agent robot est capable de manipuler habilement l'effecteur du bras robotique et d'atteindre avec précision la position cible spécifiée. Cela fournit non seulement une solution pratique pour des tâches telles que le contrôle des robots, mais a également le potentiel de transformer une variété de domaines qui nécessitent une prise de décision agile et éclairée
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Résumé des bibliothèques d'apprentissage automatique couramment utilisées en Python
- Introduction aux bibliothèques d'apprentissage automatique et d'apprentissage profond couramment utilisées en python (partage de résumé)
- Comment l'intelligence artificielle et l'apprentissage automatique auront un impact sur l'avenir des soins de santé
- Les essentiels du machine learning : comment éviter le surapprentissage ?
- Des souris marchant dans le labyrinthe à AlphaGo battant les humains, le développement de l'apprentissage par renforcement