
Maison >Périphériques technologiques >IA >Des souris marchant dans le labyrinthe à AlphaGo battant les humains, le développement de l'apprentissage par renforcement
Des souris marchant dans le labyrinthe à AlphaGo battant les humains, le développement de l'apprentissage par renforcement

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-09 21:49:08938parcourir
Quand il s’agit d’apprentissage par renforcement, l’adrénaline de nombreux chercheurs monte de manière incontrôlable ! Il joue un rôle très important dans les systèmes d’IA de jeu, les robots modernes, les systèmes de conception de puces et d’autres applications.
Il existe de nombreux types d'algorithmes d'apprentissage par renforcement, mais ils sont principalement divisés en deux catégories : « basés sur un modèle » et « sans modèle ».
Dans une conversation avec TechTalks, le neuroscientifique et auteur de "The Birth of Intelligence" Daeyeol Lee a discuté de différents modèles d'apprentissage par renforcement chez les humains et les animaux, de l'intelligence artificielle et de l'intelligence naturelle, ainsi que des orientations de recherche futures.

Apprentissage par renforcement sans modèle
À la fin du 19e siècle, la « loi de l'effet » proposée par le psychologue Edward Thorndike est devenue la base de l'apprentissage par renforcement sans modèle. Thorndike a proposé que les comportements qui ont un impact positif dans une situation spécifique sont plus susceptibles de se reproduire dans cette situation, tandis que les comportements qui ont un impact négatif sont moins susceptibles de se reproduire.
Thorndike a exploré cette « loi de l'effet » dans une expérience. Il a placé un chat dans une boîte labyrinthe et a mesuré le temps qu'il lui fallait pour s'échapper de la boîte. Pour s'échapper, le chat doit actionner une série de gadgets, tels que des cordes et des leviers. Thorndike a observé que lorsque le chat interagissait avec la boîte à puzzle, il apprenait des comportements qui l'aidaient à s'échapper. Au fil du temps, le chat s'échappe de plus en plus vite de la boîte. Thorndike a conclu que les chats peuvent apprendre des récompenses et des punitions que leur comportement leur apporte. La « loi de l’effet » a ensuite ouvert la voie au behaviorisme. Le behaviorisme est une branche de la psychologie qui tente d'expliquer le comportement humain et animal en termes de stimuli et de réponses. La « loi de l’effet » constitue également la base de l’apprentissage par renforcement sans modèle. Dans l’apprentissage par renforcement sans modèle, un agent perçoit le monde puis entreprend des actions tout en mesurant les récompenses.
Dans l'apprentissage par renforcement sans modèle, il n'y a pas de connaissance directe ni de modèle mondial. Les agents RL doivent expérimenter directement les résultats de chaque action par essais et erreurs.
Apprentissage par renforcement basé sur des modèles
La « loi de l'effet » de Thorndike est restée populaire jusque dans les années 1930. Un autre psychologue de l'époque, Edward Tolman, a découvert une idée importante en explorant comment les rats ont rapidement appris à naviguer dans les labyrinthes. Au cours de ses expériences, Tolman s'est rendu compte que les animaux pouvaient en apprendre davantage sur leur environnement sans renforcement.
Par exemple, lorsqu'une souris est lâchée dans un labyrinthe, elle explorera librement le tunnel et comprendra progressivement la structure de l'environnement. Si le rat est ensuite réintroduit dans le même environnement et reçoit des signaux de renforcement, comme chercher de la nourriture ou trouver une sortie, il peut atteindre l'objectif plus rapidement qu'un animal qui n'a pas exploré le labyrinthe. Tolman appelle cela « l’apprentissage latent », qui devient la base de l’apprentissage par renforcement basé sur un modèle. « L'apprentissage latent » permet aux animaux et aux humains de se former une représentation mentale de leur monde, de simuler des scénarios hypothétiques dans leur esprit et de prédire les résultats.
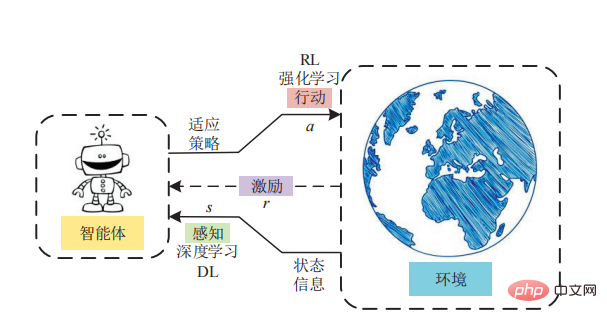
L'avantage de l'apprentissage par renforcement basé sur un modèle est qu'il élimine le besoin pour l'agent d'effectuer des essais et des erreurs dans l'environnement. Il convient de souligner que l’apprentissage par renforcement basé sur des modèles a été particulièrement efficace dans le développement de systèmes d’intelligence artificielle capables de maîtriser des jeux de société tels que les échecs et le Go, peut-être parce que les environnements de ces jeux sont déterministes.

Basé sur un modèle VS sans modèle
De manière générale, l'apprentissage par renforcement basé sur un modèle prendra beaucoup de temps et peut être fatal s'il est extrêmement sensible au facteur temps. "Sur le plan informatique, l'apprentissage par renforcement basé sur un modèle est beaucoup plus complexe", a déclaré Lee. "Vous devez d'abord obtenir le modèle, effectuer une simulation mentale, puis trouver la trajectoire du processus neuronal et ensuite agir. Cependant, L'apprentissage par renforcement basé sur un modèle n'est pas nécessairement plus complexe que le RL sans modèle. « Lorsque l'environnement est très complexe, s'il peut être modélisé avec un modèle relativement simple (qui peut être obtenu rapidement), alors la simulation sera beaucoup plus simple. et rentable.
Plusieurs modes d'apprentissage
En fait, ni l'apprentissage par renforcement basé sur un modèle ni l'apprentissage par renforcement sans modèle ne sont une solution parfaite. Chaque fois que vous voyez un système d'apprentissage par renforcement résoudre un problème complexe, il est probable qu'il utilise à la fois un apprentissage par renforcement basé sur un modèle et sans modèle, et peut-être encore plus de formes d'apprentissage. La recherche en neurosciences montre que les humains et les animaux disposent de multiples façons d’apprendre et que le cerveau bascule constamment entre ces modes à tout moment. Ces dernières années, la création de systèmes d’intelligence artificielle combinant plusieurs modèles d’apprentissage par renforcement a suscité un intérêt croissant. Des recherches récentes menées par des scientifiques de l'UC San Diego montrent que la combinaison de l'apprentissage par renforcement sans modèle et de l'apprentissage par renforcement basé sur un modèle peut permettre d'obtenir des performances supérieures dans les tâches de contrôle. "Si vous regardez un algorithme complexe comme AlphaGo, il comporte à la fois des éléments RL sans modèle et des éléments RL basés sur un modèle", a déclaré Lee. "Il apprend les valeurs d'état en fonction de la configuration de la carte. Il s'agit essentiellement d'un RL sans modèle, mais une recherche avancée basée sur un modèle est également effectuée.
Malgré des réalisations significatives, les progrès en matière d'apprentissage par renforcement restent lents. Une fois qu'un modèle RL est confronté à un environnement complexe et imprévisible, ses performances commencent à se dégrader.
Lee a déclaré : "Je pense que notre cerveau est un monde complexe d'algorithmes d'apprentissage, et ils ont évolué pour gérer de nombreuses situations différentes." En plus de basculer constamment entre les modes, le cerveau parvient également à les maintenir et à les mettre à jour à tout moment, même lorsqu'ils ne sont pas activement impliqués dans la prise de décision.
Le psychologue Daniel Kahneman a déclaré : « Maintenir différents modules d'apprentissage et les mettre à jour simultanément contribuera à améliorer l'efficacité et la précision des systèmes d'intelligence artificielle.
Nous aussi Une autre chose qui doit être fait. Il faut être clair sur la façon d'appliquer le bon biais inductif dans les systèmes d'IA pour garantir qu'ils apprennent les bonnes choses de manière rentable. Des milliards d’années d’évolution ont donné aux humains et aux animaux le biais inductif nécessaire pour apprendre efficacement en utilisant le moins de données possible. Le biais inductif peut être compris comme la synthèse des règles des phénomènes observés dans la vie réelle, puis l'imposition de certaines contraintes sur le modèle, qui peuvent jouer le rôle de sélection de modèle, c'est-à-dire la sélection d'un modèle plus cohérent avec les règles réelles de l'espace des hypothèses. "Nous obtenons très peu d'informations de l'environnement. En utilisant ces informations, nous devons généraliser", a déclaré Lee. "La raison est que le cerveau a un biais inductif, et il existe un biais de généralisation à partir d'un petit ensemble d'exemples. C'est un problème. produit de l'évolution." , de plus en plus de neuroscientifiques s'y intéressent. " Cependant, si le biais inductif est facile à comprendre dans les tâches de reconnaissance d'objets, il devient obscur dans des problèmes abstraits tels que la construction de relations sociales. À l'avenir, il nous reste encore beaucoup de choses à savoir ~~~
Référence :
https://thenextweb.com/news/everything-you-need -pour- en savoir plus sur l'apprentissage par renforcement sans modèle et basé sur un modèle
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI