
Maison >Périphériques technologiques >IA >Quelles sont les méthodes efficaces et les méthodes de base communes pour la prédiction de trajectoires piétonnes ? Partage des meilleurs articles de conférence !
Quelles sont les méthodes efficaces et les méthodes de base communes pour la prédiction de trajectoires piétonnes ? Partage des meilleurs articles de conférence !

- 王林avant
- 2023-10-17 11:13:012158parcourir
La prédiction de trajectoire a été à l'honneur ces deux dernières années, mais l'essentiel se concentre sur la direction de la prédiction de trajectoire des véhicules. Aujourd'hui, Autonomous Driving Heart partagera avec vous l'algorithme de prédiction de trajectoire des piétons sur NeurIPS - SHENet, le mouvement humain. modèle dans les scènes restreintes. Se conforme généralement à des lois limitées dans une certaine mesure. Sur la base de cette hypothèse, SHENet prédit la trajectoire future d'une personne en apprenant des règles de scène implicites. L'article a été autorisé comme original par Autonomous Driving Heart !
Compréhension personnelle de l'auteur
En raison du caractère aléatoire et subjectif du mouvement humain, prédire la trajectoire future d'une personne reste actuellement un problème difficile. Cependant, en raison des contraintes de la scène (telles que les plans d'étage, les routes et les obstacles) et de l'interactivité d'humain à humain ou d'humain à objet, les schémas de mouvement humain dans les scènes contraintes se conforment généralement dans une certaine mesure à des lois limitées. Ainsi, dans ce cas, la trajectoire de l’individu devrait également suivre l’une de ces lois. En d’autres termes, la trajectoire ultérieure d’une personne est susceptible d’avoir été parcourue par d’autres. Sur la base de cette hypothèse, l'algorithme de cet article (SHENet) prédit la trajectoire future d'une personne en apprenant des règles de scène implicites. Plus précisément, nous appelons l’histoire de la scène les régularités inhérentes à la dynamique passée des personnes et des environnements dans une scène. Les informations historiques sur la scène sont ensuite divisées en deux catégories : les trajectoires historiques des groupes et les interactions entre les individus et l'environnement. Pour exploiter ces deux types d'informations pour la prédiction de trajectoire, cet article propose un nouveau cadre Scene History Mining Network (SHENet), dans lequel l'histoire de la scène est exploitée de manière simple et efficace. En particulier, deux composants de la conception sont : le module de bibliothèque de trajectoires de groupe, qui est utilisé pour extraire des trajectoires de groupe représentatives en tant que candidats pour des parcours futurs, et le module d'interaction intermodale, qui est utilisé pour modéliser l'interaction entre la trajectoire passée d'un individu ; et son environnement immédiat, pour le raffinement de la trajectoire. De plus, afin d'atténuer l'incertitude sur la véritable trajectoire causée par le caractère aléatoire et la subjectivité du mouvement humain mentionné ci-dessus, SHENet intègre la fluidité dans le processus de formation et les indicateurs d'évaluation. Enfin, nous l'avons vérifié sur différents ensembles de données expérimentales et avons démontré d'excellentes performances par rapport aux méthodes SOTA.
Introduction
La Prédiction de Trajectoire Humaine (HTP) vise à prédire le parcours futur d'une personne cible à partir de clips vidéo. Ceci est crucial pour le transport intelligent, car cela permet aux véhicules de détecter à l’avance le statut des piétons, évitant ainsi d’éventuelles collisions. Les systèmes de surveillance dotés de fonctions HTP peuvent aider le personnel de sécurité à prédire les voies de fuite possibles des suspects. Bien que de nombreux travaux aient été réalisés ces dernières années, peu sont suffisamment fiables et généralisables aux applications dans des scénarios du monde réel, principalement en raison de deux défis liés à cette tâche : le caractère aléatoire et la subjectivité du mouvement humain. Cependant, dans des scénarios concrets et contraints, les défis ne sont pas absolument insolubles. Comme le montre la figure 1, compte tenu des vidéos précédemment capturées dans cette scène, la trajectoire future de la personne cible (encadré rouge) devient plus prévisible car le modèle de mouvement de l'humain se conforme généralement à plusieurs lois fondamentales que la personne cible dans cette scène suivra. Par conséquent, pour prédire les trajectoires, nous devons d’abord comprendre ces modèles. Nous soutenons que ces régularités sont implicitement codées dans les trajectoires humaines historiques (Figure 1 à gauche), les trajectoires passées individuelles, les environnements environnants et les interactions entre eux (Figure 1 à droite), que nous appelons histoires de scènes.

Figure 1 : Diagramme schématique de l'utilisation de l'histoire de la scène : trajectoires de groupe historiques et interactions individuelles avec l'environnement pour la prédiction de la trajectoire humaine.
Nous divisons les informations historiques en deux catégories : les trajectoires historiques de groupe (HGT) et les interactions individu-environnement (ISI). HGT fait référence à la représentation groupée de toutes les trajectoires historiques dans une scène. La raison pour laquelle on utilise HGT est que, étant donné une nouvelle personne cible dans la scène, son chemin est plus susceptible d'avoir plus de similitude, de subjectivité et de régularité avec l'une des trajectoires du groupe qu'avec n'importe quelle instance unique de la trajectoire historique en raison de le hasard mentionné ci-dessus. Cependant, les trajectoires de groupe sont moins pertinentes pour les états passés des individus et les environnements correspondants, et peuvent également affecter les trajectoires futures des individus. L'ISI doit utiliser davantage les informations historiques en extrayant des informations contextuelles. Les méthodes existantes considèrent rarement la similarité entre les trajectoires passées des individus et les trajectoires historiques. La plupart des tentatives explorent uniquement l'interaction entre l'individu et l'environnement, où beaucoup d'efforts sont consacrés à la modélisation de la trajectoire individuelle, des informations sémantiques de l'environnement et des relations entre elles. Bien que MANTRA utilise un encodeur formé de manière reconstruction pour modéliser la similarité et que MemoNet simplifie la similarité en stockant l'intention des trajectoires historiques, ils effectuent tous deux des calculs de similarité au niveau de l'instance plutôt qu'au niveau du groupe, ce qui le rend sensible aux capacités du codeur qualifié. Sur la base de l'analyse ci-dessus, nous proposons un cadre simple mais efficace, Scene History Mining Network (SHENet), pour utiliser conjointement HGT et ISI pour HTP. En particulier, le cadre se compose de deux composants principaux : (i) le module Group Trajectory Base (GTB) et (ii) le module Cross-Modal Interaction (CMI). GTB construit des trajectoires de groupe représentatives à partir de toutes les trajectoires individuelles historiques et propose des chemins candidats pour la prédiction de trajectoires futures. CMI code séparément les trajectoires individuelles observées et l'environnement environnant et modélise leur interaction à l'aide d'un transformateur multimodal pour affiner les trajectoires candidates recherchées.
De plus, pour atténuer l'incertitude des deux caractéristiques ci-dessus (c'est-à-dire le caractère aléatoire et la subjectivité), nous introduisons le lissage de courbe (CS) dans le processus de formation et les métriques d'évaluation actuelles, les erreurs de déplacement moyennes et finales (c'est-à-dire ADE et FDE), obtenant ainsi deux nouveaux indicateurs CS-ADE et CS-FDE. De plus, pour faciliter le développement de la recherche HTP, nous avons collecté un nouvel ensemble de données stimulant avec différents modèles de mouvement nommé PAV. Cet ensemble de données est obtenu en sélectionnant des vidéos avec des vues de caméra fixes et des mouvements humains complexes à partir de l'ensemble de données MOT15.
Les apports de ce travail peuvent être résumés comme suit : 1) Nous introduisons l'histoire de groupe pour rechercher des trajectoires individuelles de HTP. 2) Nous proposons un cadre simple mais efficace, SHENet, qui utilise conjointement deux types d'histoires de scènes (c'est-à-dire les trajectoires historiques des groupes et les interactions individu-environnement) pour le HTP. 3) Nous avons construit un nouvel ensemble de données PAV stimulant. De plus, compte tenu du caractère aléatoire et de la subjectivité des modèles de mouvements humains, une nouvelle fonction de perte et deux nouveaux indicateurs sont proposés pour obtenir de meilleures performances HTTP de base. 4) Nous avons mené des expériences complètes sur ETH, UCY et PAV pour démontrer les performances supérieures de SHENet et l'efficacité de chaque composant.
Travail connexe
Méthodes unimodalesLes méthodes unimodales reposent sur l'apprentissage de la régularité des mouvements individuels à partir de trajectoires passées pour prédire les trajectoires futures. Par exemple, Social LSTM modélise les interactions entre trajectoires individuelles grâce au module de pooling social. STGAT utilise un module d'attention pour apprendre les interactions spatiales et attribuer une importance raisonnable aux voisins. PIE utilise un module d'attention temporelle pour calculer l'importance des trajectoires observées à chaque pas de temps.
Méthode multimodaleDe plus, la méthode multimodale examine également l'impact des informations environnementales sur les HTP. SS-LSTM propose un module d'interaction de scène pour capturer les informations globales de la scène. Trajectron++ utilise des structures graphiques pour modéliser des trajectoires et interagir avec les informations environnementales et d'autres individus. MANTRA exploite la mémoire externe pour modéliser les dépendances à long terme. Il stocke en mémoire les trajectoires historiques d’un seul agent et code les informations environnementales pour affiner les trajectoires recherchées à partir de cette mémoire.
Différences par rapport aux travaux antérieursLes approches monomodales et multimodales utilisent des aspects uniques ou partiels de l'histoire de la scène, ignorant les trajectoires historiques des groupes. Dans notre travail, nous intégrons les informations sur l'historique des scènes de manière plus complète et proposons des modules dédiés pour gérer respectivement différents types d'informations. Les principales différences entre notre méthode et les travaux antérieurs, en particulier les méthodes basées sur la mémoire et les méthodes basées sur le clustering, sont les suivantes : i) MANTRA et MemoNet considèrent les trajectoires individuelles historiques, tandis que notre proposition SHENet se concentre sur les trajectoires de groupe historiques, qui dans différentes situations sont plus universelles. scénarios. ii) Il existe également des travaux qui regroupent les personnes-voisins pour la prédiction de trajectoire ; regroupent les trajectoires en un nombre fixe de catégories pour la classification des trajectoires ; notre SHENet génère des trajectoires représentatives comme référence pour la prédiction de trajectoire individuelle.
Méthode
Introduction générale
L'architecture du réseau d'exploration d'histoire de scène proposé (SHENet) est illustrée à la figure 2. Il se compose de deux composants principaux : le module de bibliothèque de trajectoires de groupe (GTB) et le module d'interaction intermodale. (CMI). Formellement, étant donné toutes les trajectoires , images de scène dans la vidéo observée de la scène et les trajectoires passées de la personne cible au dernier pas de temps, où représente la position de la p-ième personne au pas de temps t , SHENet est nécessaire pour prédire La position future du piéton dans la trame suivante est aussi proche que possible de la trajectoire de la vérité terrain. Le GTB proposé compresse d'abord en trajectoires de groupe représentatives. Ensuite, utilisez la trajectoire observée comme clé pour rechercher la trajectoire du groupe représentatif la plus proche en tant que trajectoire future candidate. Dans le même temps, les trajectoires passées et les images de scène sont transmises respectivement au codeur de trajectoire et au codeur de scène pour générer respectivement des caractéristiques de trajectoire et des caractéristiques de scène. Les caractéristiques codées sont introduites dans un transformateur multimodal pour apprendre le décalage par rapport à la trajectoire de vérité terrain. En ajoutant à , on obtient la prédiction finale . Lors de la phase d'entraînement, si la distance à est supérieure au seuil, la trajectoire de la personne (c'est-à-dire et ) sera ajoutée à la bibliothèque de trajectoires. Une fois la formation terminée, la banque est fixée pour l'inférence.
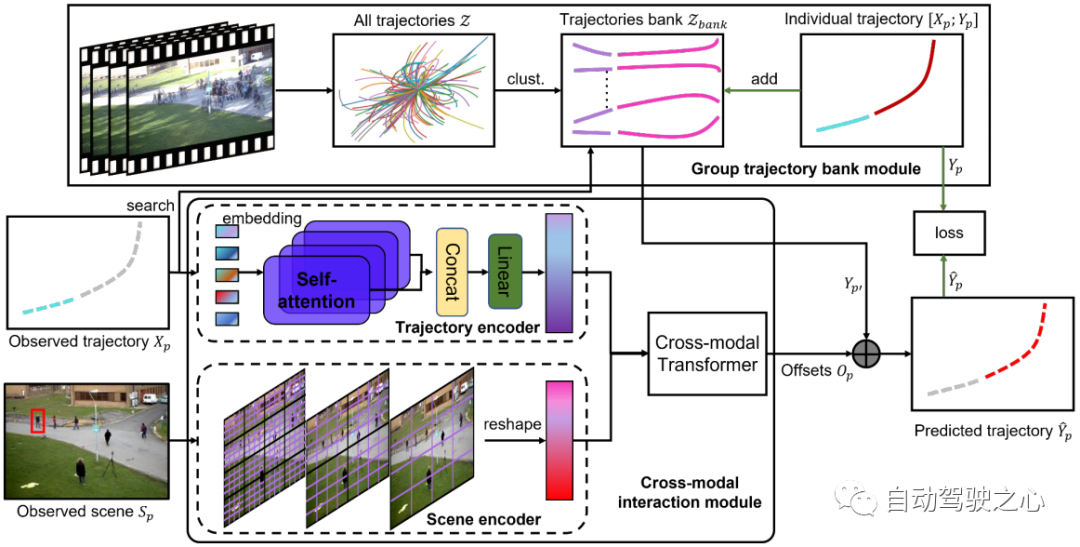
Figure 2 : L'architecture de SHENet se compose de deux composants : le module Group Trajectory Library (GTB) et le Cross-Modal Interaction Module (CMI). GTB regroupe toutes les trajectoires historiques dans un ensemble de trajectoires de groupes représentatifs et fournit des candidats pour la prédiction de trajectoire finale. Dans la phase de formation, GTB peut intégrer la trajectoire de la personne cible dans la bibliothèque de trajectoires de groupe en fonction de l'erreur de la trajectoire prédite pour étendre les capacités d'expression. CMI prend la trajectoire passée de la personne cible et de la scène observée comme entrée respectivement de l'encodeur de trajectoire et de l'encodeur de scène pour l'extraction de caractéristiques, puis modélise efficacement l'interaction entre la trajectoire passée et son environnement via le convertisseur multimodal et le raffinement. est effectué pour fournir des trajectoires candidates.
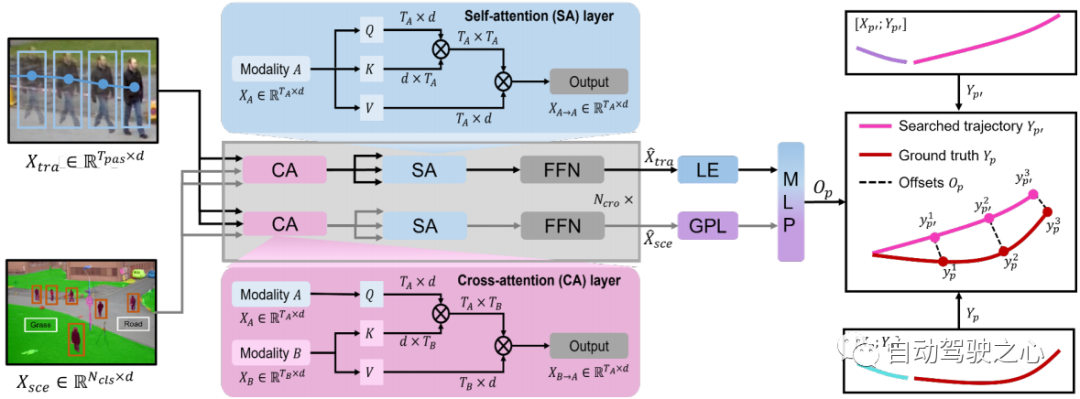
Figure 3 : Illustration d'un transformateur multimodal. Des caractéristiques de trajectoire et des caractéristiques de scène sont entrées dans le transformateur multimodal pour apprendre le décalage entre la trajectoire de recherche et la trajectoire de vérité terrain.
Module de bibliothèque de trajectoires de groupe
Le module de bibliothèque de trajectoires de groupe (GTB) est utilisé pour créer des trajectoires de groupe représentatives dans la scène. Les fonctions principales de GTB sont l'initialisation bancaire, la recherche de trajectoire et la mise à jour de trajectoire.
Initialisation de la bibliothèque de trajectoiresEn raison de la redondance d'un grand nombre de trajectoires enregistrées, nous ne les utilisons pas simplement, mais générons un ensemble de trajectoires clairsemées et représentatives comme valeur initiale de la bibliothèque de trajectoires. Plus précisément, nous représentons les trajectoires dans les données d'entraînement comme et divisons chacune en une paire de trajectoires d'observation et de trajectoires futures , divisant ainsi en un ensemble d'observation et un ensemble futur correspondant . Ensuite, nous calculons la distance euclidienne entre chaque paire de trajectoires dans , et obtenons des clusters de trajectoires grâce à l'algorithme de clustering K-médoïdes. Les membres initiaux de sont la moyenne des trajectoires appartenant au même cluster (voir Algorithme 1, étape 1). Chaque trajectoire représente le modèle de mouvement d’un groupe de personnes.
Recherche et mise à jour de trajectoireDans la bibliothèque de trajectoires de groupe, chaque trajectoire peut être considérée comme une paire passé-futur. Numériquement, , où représente la combinaison de la trajectoire passée et de la trajectoire future, et est le nombre de paires passé-futur dans . Étant donné une trajectoire , nous utilisons l'observé comme clé pour calculer son score de similarité avec les trajectoires passées en et trouvons la trajectoire représentative en fonction du score de similarité maximum (voir Algorithme 1, étape 2). La fonction de similarité peut être exprimée comme suit :
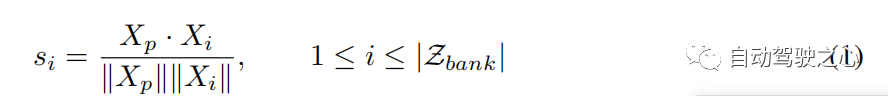
En ajoutant le décalage (voir équation 2) à la trajectoire représentative , nous obtenons la trajectoire prédite de l'observateur (voir figure 2). Bien que la bibliothèque de trajectoires initiale fonctionne bien dans la plupart des cas, afin d'améliorer la généralisation de la bibliothèque (voir Algorithme 1, étape 3), nous décidons s'il faut mettre à jour en fonction du seuil de distance θ.
Module d'interaction cross-modale
Ce module se concentre sur l'interaction entre les trajectoires passées individuelles et les informations environnementales. Il se compose de deux encodeurs monomodaux pour apprendre respectivement les informations sur le mouvement humain et la scène, et d'un transformateur multimodal pour modéliser leur interaction.
Trajectory EncoderTrajectory Encoder utilise une structure d'attention multi-têtes de Transformer Network, qui possède une couche Self-Attention (SA). La couche SA capture le mouvement humain à différents pas de temps avec la taille de et projette les caractéristiques de mouvement de la dimension à , où est la dimension d'intégration de l'encodeur de trajectoire. Par conséquent, nous utilisons un encodeur de trajectoire pour obtenir une représentation du mouvement humain : .
Encodeur de scène Étant donné que le Swin Transformer pré-entraîné a des performances convaincantes en matière de représentation des fonctionnalités, nous l'adoptons comme encodeur de scène. Il extrait les caractéristiques sémantiques de la scène de taille , où ( dans l'encodeur de scène pré-entraîné) est le nombre de classes sémantiques, telles que les personnes et les routes, et et sont les résolutions spatiales. Afin de permettre aux modules suivants de fusionner facilement la représentation du mouvement et les informations sur l'environnement, nous modifions à nouveau les caractéristiques sémantiques de taille () à () et les projetons de dimension () à () à travers des couches perceptuelles multicouches. En conséquence, nous obtenons une représentation de scène à l'aide d'un encodeur de scène .
Transformateur multimodal L'encodeur monomodal extrait les caractéristiques de sa propre modalité, ignorant l'interaction entre le mouvement humain et les informations environnementales. Un transformateur cross-modal avec couches vise à affiner les trajectoires candidates en apprenant cette interaction (voir Section 3.2). Nous adoptons une structure à deux flux : l’un est utilisé pour capturer les mouvements humains importants qui sont contraints par les informations environnementales, et l’autre est utilisé pour sélectionner les informations environnementales liées aux mouvements humains. La couche d'attention croisée (CA) et la couche d'auto-attention (SA) sont les principaux composants du convertisseur multimodal (voir Figure 3). Afin de capturer les mouvements humains importants affectés par l'environnement et d'obtenir des informations environnementales liées aux mouvements, la couche CA traite une modalité comme une requête et l'autre modalité comme la clé et la valeur qui interagissent avec les deux modalités. La couche SA est utilisée pour promouvoir de meilleures connexions internes et calculer la similarité entre les éléments (requête) et d'autres éléments (clé) dans le mouvement contraint par la scène ou les informations environnementales liées au mouvement. Par conséquent, nous obtenons la représentation multimodale via le transformateur cross-modal(). Pour prédire le décalage entre la trajectoire de recherche et la trajectoire réelle , on prend le dernier élément (LE) de et le de la sortie après la couche de pooling global (GPL). Le décalage peut être exprimé comme suit :
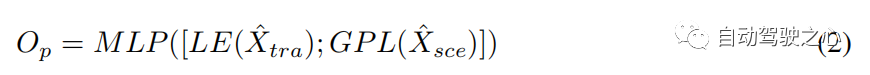
.
Dans l'ensemble de données PAV le plus complexe, nous utilisons une perte de régression par lissage de courbe (CS), qui contribue à réduire l'impact des biais individuels. Il calcule le MSE après avoir lissé la trajectoire. La perte CS peut être exprimée comme suit : où CS représente la fonction de lissage de courbe [2].
Expérience
Configuration expérimentaleEnsemble de données Nous évaluons notre méthode sur les ensembles de données ETH, UCY, PAV et Stanford Drone Dataset (SDD). Les méthodes monomodales se concentrent uniquement sur les données de trajectoire. Cependant, les méthodes multimodales doivent prendre en compte les informations sur la scène.
Par rapport à l'ensemble de données ETH/UCY, PAV est plus difficile avec plusieurs modes de mouvement, notamment PETS09-S2L1 (PETS), ADL-Rundle-6 (ADL) et Venice-2 (VENICE), qui sont des captures de caméras statiques et fournit suffisamment de traces pour les tâches HTP. Nous divisons les vidéos en ensemble de formation (80 %) et ensemble de tests (20 %), et PETS/ADL/VENICE contient respectivement 2 370/2 935/4 200 séquences de formation et 664/306/650 séquences de test. Nous utilisons descadres d'observation pour prédire les futurs cadres afin de pouvoir comparer les résultats de prédiction à long terme de différentes méthodes.
Contrairement aux ensembles de données ETH/UCY et PAV, le SDD est un ensemble de données à grande échelle capturé à partir d'une vue plongeante d'un campus universitaire. Il se compose de plusieurs agents en interaction (par exemple les piétons, les cyclistes et les voitures) et de différents scénarios (par exemple les trottoirs et les intersections). Suite à des travaux antérieurs, nous utilisons les 8 dernières images pour prédire les 12 futures images.
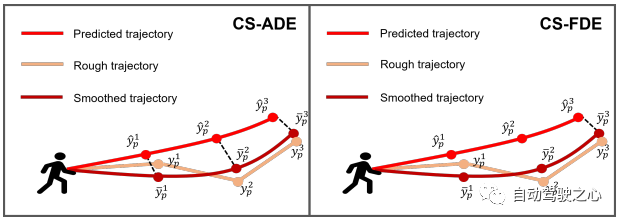
Figure 4 : Illustration de nos métriques proposées CS-ADE et CS-FDE.

Figure 5 : Visualisation de quelques échantillons après lissage de la courbe.
Métriques d'évaluation Pour les ensembles de données ETH et UCY, nous utilisons les métriques standard de HTP : erreur de déplacement moyenne (ADE) et erreur de déplacement final (FDE). ADE est l'erreur moyenne entre la trajectoire prédite et la trajectoire réelle à tous les pas de temps, et FDE est l'erreur entre la trajectoire prédite et la trajectoire réelle au pas de temps final. La trajectoire en PAV présente une certaine instabilité (par exemple des virages serrés). Par conséquent, une prévision raisonnable peut produire à peu près la même erreur qu’une prévision irréaliste utilisant les mesures traditionnelles ADE et FDE (voir la figure 7(a)). Afin de se concentrer sur le modèle et la forme de la trajectoire elle-même et de réduire l'impact du caractère aléatoire et de la subjectivité, nous proposons CS-Metric : CS-ADE et CS-FDE (illustré dans la figure 4). CS-ADE est calculé comme suit :
où CS est la fonction de lissage de courbe, définie de la même manière que Lcs dans la section 3.4. Semblable à CS-ADE, CS-FDE calcule l'erreur de déplacement finale après le lissage de la trajectoire :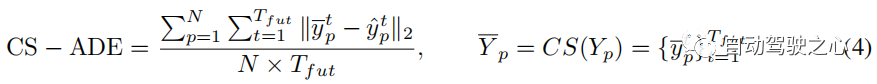
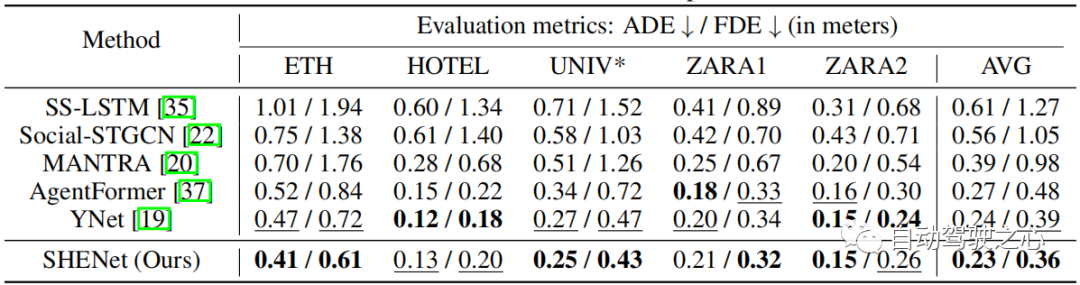
Dans SHENet, la taille initiale de la bibliothèque de trajectoires de groupe est définie sur. L'encodeur de trajectoire et l'encodeur de scène ont tous deux 4 couches d'auto-attention (SA). Le transformateur multimodal comporte 6 couches SA et des couches Cross Attention (CA). Nous définissons toutes les dimensions d'intégration sur 512. Pour l'encodeur de trajectoire, il apprend des informations sur le mouvement humain de taille ( en ETH/UCY, en PAV). Pour l'encodeur de scène, il génère des caractéristiques sémantiques de taille 150 × 56 × 56. Nous changeons la taille de 150 × 56 × 56 à 150 × 3136 et les projetons des dimensions 150 × 3136 à 150 × 512. Nous entraînons le modèle pendant 100 époques sur 4 GPU NVIDIA Quadro RTX 6000 et utilisons l'optimiseur Adam avec un taux d'apprentissage fixe de 1e − 5. Ablation ExperimentDans le tableau 1, nous évaluons chaque composant de SHENet, y compris le module Group Trajectory Library (GTB) et le module Cross-Modal Interaction (CMI), qui contient l'encodeur de trajectoire (TE), le serveur d'encodage de scène ( SE) et les modules d'interaction multimodale (CMI).
Impact du GTB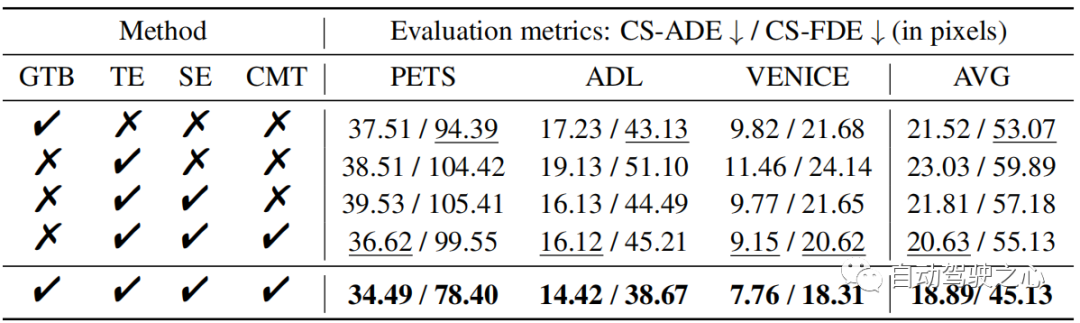
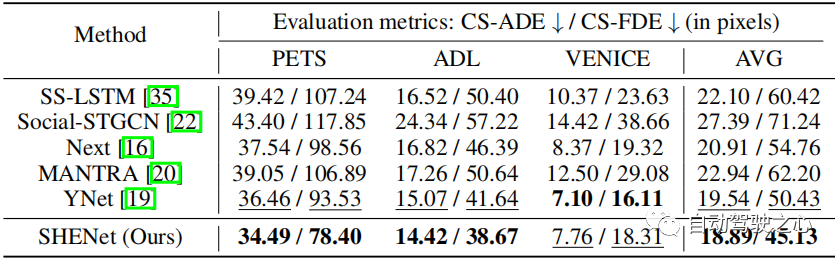
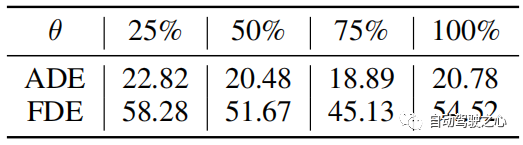
Nous étudions dans un premier temps les performances du GTB. Par rapport au CMI (c'est-à-dire TE, SE et CMT), le GTB améliore le FDE sur PETS de 21,2 %, ce qui constitue une amélioration significative et illustre l'importance du GTB. Cependant, le GTB seul (tableau 1, ligne 1) ne suffit pas et est même légèrement moins performant que le CMI. Par conséquent, nous avons exploré le rôle des différentes parties du module CMI. Influence de TE et SE Pour évaluer les performances de TE et SE, nous concaténons les caractéristiques de trajectoire extraites de TE et les caractéristiques de scène extraites de SE (ligne 3 dans le tableau 1), et comparons les petits mouvements améliorent les performances de l'ADL. et VENISE (par rapport à l'utilisation de TE seul. Cela montre que l'intégration d'informations environnementales dans la prédiction de trajectoire peut améliorer la précision des résultats. Effet du CMT Par rapport à la troisième ligne du tableau 1, le CMT (tableau 1) peut améliorer considérablement performances du modèle, il surpasse notamment TE et SE en série sur PETS, avec une amélioration de 7,4% en moyenne par rapport au GTB seul, augmenté de 12,2% . Comparez notre modèle avec les méthodes de pointe sur l'ensemble de données ETH/UCY : SS-LSTM, Social-STGCN, MANTRA, AgentFormer, YNet. Les résultats sont résumés dans le tableau 2. Notre modèle réduit le FDE moyen de 0,39 à 0,36, soit une amélioration de 7,7 % par rapport à la méthode de pointe YNet. En particulier, lorsque la trajectoire subit de grands mouvements, notre modèle surpasse considérablement les méthodes précédentes sur l'ETH, améliorant respectivement l'ADE et le FDE de 12,8 % et 15,3 %. Tableau 2 : Comparaison des méthodes de pointe (SOTA) sur le jeu de données ETH/UCY. * indique que nous utilisons un ensemble plus petit que l'approche unimodale. Évaluez en utilisant le meilleur du top 20. Tableau 3 : Comparaison avec les méthodes SOTA sur l'ensemble de données PAV. Pour évaluer les performances de notre modèle en prédiction à long terme, nous avons mené des expérimentations sur PAV avec frames d'observation et futures frames par trajectoire. Le tableau 3 montre la comparaison des performances avec les méthodes HTP précédentes : SS-LSTM, Social-STGCN, Next, MANTRA, YNet. Par rapport aux derniers résultats de YNet, les SHENet CS-ADE et CS-FDE proposés réalisent une amélioration moyenne de 3,3 % et 10,5 %, respectivement. Étant donné que YNet prédit les cartes thermiques des trajectoires, il fonctionne mieux lorsque les trajectoires comportent de petits mouvements (comme VENISE). Néanmoins, notre méthode est toujours compétitive à VENISE et nettement meilleure que les autres méthodes sur PETS avec des mouvements et des intersections plus importants. En particulier, notre méthode améliore CS-FDE de 16,2% sur PETS par rapport à YNet. Nous avons également fait d'énormes progrès dans les mesures ADE/FDE traditionnelles. Le seuil de distance θθ permet de déterminer la mise à jour de la bibliothèque de trajectoires. Les valeurs typiques de θ sont définies en fonction de la longueur de la trajectoire. La valeur absolue de l’erreur de prédiction est généralement plus grande lorsque la trajectoire de vérité terrain est plus longue en pixels. Cependant, leurs erreurs relatives sont comparables. Par conséquent, lorsque les erreurs convergent, θ est fixé à 75 % de l’erreur d’apprentissage. Dans les expériences, nous définissons θ = 25 dans PETS et θ = 6 dans ADL. L'« erreur de formation de 75 % » est obtenue à partir des résultats expérimentaux, comme le montre le tableau 4. Tableau 4 : Comparaison des différents paramètres θ sur l'ensemble de données PAV. Les résultats sont la moyenne des trois cas. Tableau 5 : Comparaison du numéro de cluster initial K sur l'ensemble de données PAV. K Nombre de clusters dans le point central Nous avons étudié l'effet de la définition de différents nombres de clusters initiaux K, comme le montre le tableau 5. Nous pouvons remarquer que le nombre initial de clusters n'est pas sensible aux résultats de la prédiction, surtout lorsque le nombre initial de clusters est compris entre 24 et 36. Par conséquent, nous pouvons fixer K à 32 dans l’expérience. Analyse de la complexité bancaire La complexité temporelle de la recherche et de la mise à jour est respectivement O(N) et O(1). Leur complexité spatiale est O(N). Le nombre de trajectoires de groupe N≤1000. La complexité temporelle du processus de clustering est ββ et la complexité spatiale est ββ. β est le nombre de trajectoires de regroupement. est le nombre de clusters, est le nombre d'itérations de la méthode de clustering. Figure 6 : Visualisation qualitative de notre approche et de nos méthodes de pointe. La ligne bleue est la trajectoire observée. Les lignes rouges et vertes montrent les trajectoires prédites et réelles. Figure 7 : Visualisation qualitative sans/avec CS. La figure 6 montre les résultats qualitatifs de SHENet et d'autres méthodes. En revanche, nous sommes surpris de constater que dans le cas extrêmement difficile où une personne marche jusqu’au bord de la route puis fait demi-tour (courbe verte), toutes les autres méthodes ne le gèrent pas bien, alors que notre proposition SHENet peut toujours le gérer. Cela doit être attribué au rôle de notre module de bibliothèque de trajectoires de groupes historiques spécialement conçu. De plus, contrairement à la méthode basée sur la mémoire MANTRA [20], nous recherchons les trajectoires des groupes, et pas seulement des individus. Ceci est plus polyvalent et peut être appliqué à des scénarios plus difficiles. La figure 7 comprend des résultats qualitatifs pour YNet et notre SHENet sans/avec courbe lissage (CS). La première ligne montre les résultats en utilisant la perte MSE . Affectés par des trajectoires passées avec un certain bruit (comme des virages brusques et brusques), les points de trajectoire prédits par YNet se regroupent et ne peuvent pas présenter une direction claire, tandis que notre méthode peut fournir des chemins potentiels basés sur des trajectoires de groupe historiques. Les deux prédictions sont visuellement différentes, mais les erreurs numériques (ADE/FDE) sont approximativement les mêmes. En revanche, les résultats qualitatifs de notre proposition de perte de CS sont présentés dans la deuxième rangée de la figure 7. On peut voir que le CS proposé réduit considérablement l'impact du caractère aléatoire et de la subjectivité et produit des prédictions raisonnables grâce à YNet et à notre méthode. Cet article propose SHENet, une nouvelle approche qui exploite pleinement l'historique des scénarios HTP. SHENet comprend un module GTB pour construire une bibliothèque de trajectoires de groupe basée sur toutes les trajectoires historiques et récupérer les trajectoires représentatives des personnes observées à partir de la bibliothèque ; il comprend également un module CMI (interaction entre le mouvement humain et les informations environnementales) pour affiner cette trajectoire représentative. Nous obtenons des performances SOTA sur le benchmark HTP, et notre approche démontre des améliorations significatives et une généralité dans des scénarios difficiles. Cependant, il existe encore certains aspects inexplorés dans le cadre actuel, comme le processus de construction des banques qui se concentre actuellement uniquement sur le mouvement humain. Les travaux futurs comprennent une exploration plus approfondie de la bibliothèque de trajectoires à l’aide d’informations interactives (informations sur les mouvements humains et la scène). Lien original : https://mp.weixin.qq.com/s/GE-t4LarwXJu2MC9njBInQComparaison avec SOTA
Analyse



Résultats qualitatifs
Conclusion

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- La compréhension du langage naturel est un domaine d'application important de l'intelligence artificielle. Quel est son objectif ?
- Quels sont les principaux moteurs du développement de l'intelligence artificielle ?
- Comment s'appelle l'intelligence artificielle d'Oppo ?
- Réseau de perception pour l'estimation de la profondeur, de l'attitude et de la route dans des scénarios de conduite communs
- Smart App Control sur Windows 11 : comment l'activer ou le désactiver