
Maison >Périphériques technologiques >IA >Réseau de perception pour l'estimation de la profondeur, de l'attitude et de la route dans des scénarios de conduite communs
Réseau de perception pour l'estimation de la profondeur, de l'attitude et de la route dans des scénarios de conduite communs

- PHPzavant
- 2023-04-08 22:11:071880parcourir
L'article d'arXiv « JPerceiver : Joint Perception Network for Depth, Pose and Layout Estimation in Driving Scenes », mis en ligne le 22 juillet, rend compte des travaux du professeur Tao Dacheng de l'Université de Sydney, en Australie, et du Beijing JD Research Institute.

L'estimation de la profondeur, l'odométrie visuelle (VO) et l'estimation de la disposition des scènes en vue à vol d'oiseau (BEV) sont trois tâches clés pour la perception des scènes de conduite, qui constituent la base de la planification des mouvements et de la navigation dans la conduite autonome. Bien que complémentaires, ils se concentrent généralement sur des tâches distinctes et abordent rarement les trois simultanément.
Une approche simple consiste à le faire indépendamment de manière séquentielle ou parallèle, mais il y a trois inconvénients, à savoir 1) les résultats de profondeur et de VO sont affectés par le problème d'ambiguïté d'échelle inhérent 2) la disposition BEV est généralement estimée séparément pour la route et ; véhicule, tout en ignorant la relation explicite de superposition-sous-couche ; 3) Bien que la carte de profondeur soit un indice géométrique utile pour déduire la disposition de la scène, la disposition BEV est en fait prédite directement à partir de l'image de face sans utiliser aucune information relative à la profondeur.
Cet article propose un cadre de perception commun JPerceiver pour résoudre ces problèmes et estimer simultanément la profondeur perçue à l'échelle, la disposition VO et BEV à partir de séquences vidéo monoculaires. Utilisez la transformation géométrique à vue croisée (CGT) pour propager l'échelle absolue du tracé de la route à la profondeur et à la VO sur la base d'une perte d'échelle soigneusement conçue. Dans le même temps, un module cross-view and cross-modal transfer (CCT) est conçu pour utiliser des indices de profondeur pour raisonner sur la disposition des routes et des véhicules grâce à des mécanismes d'attention.
JPerceiver est formé à une méthode d'apprentissage multitâche de bout en bout, dans laquelle les modules de perte d'échelle CGT et CCT favorisent le transfert de connaissances entre les tâches et facilitent l'apprentissage des fonctionnalités pour chaque tâche. Le code et le modèle peuvent être téléchargéshttps://github.com/sunnyHelen/JPerceiver.
Comme le montre la figure, JPerceiver se compose de trois réseaux : profondeur, attitude et tracé de la route , qui sont tous basés sur une architecture codeur-décodeur. Le réseau de profondeur vise à prédire la carte de profondeur Dt de la trame courante It, où chaque valeur de profondeur représente la distance entre un point 3D et la caméra. Le but du réseau de poses est de prédire la transformation de pose Tt→t+m entre la trame courante It et sa trame adjacente It+m. L'objectif du réseau routier est d'estimer le tracé BEV Lt du cadre actuel, c'est-à-dire l'occupation sémantique des routes et des véhicules dans le plan cartésien vu de dessus. Les trois réseaux sont optimisés conjointement lors de la formation.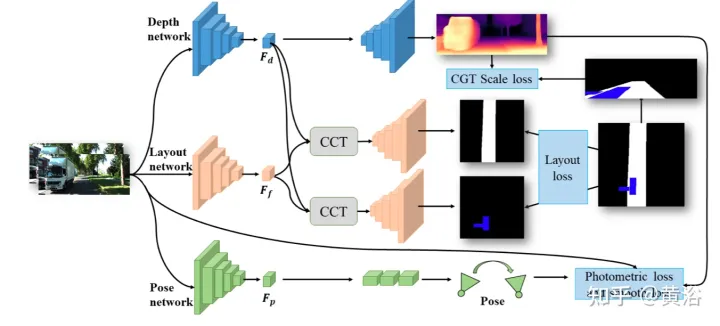
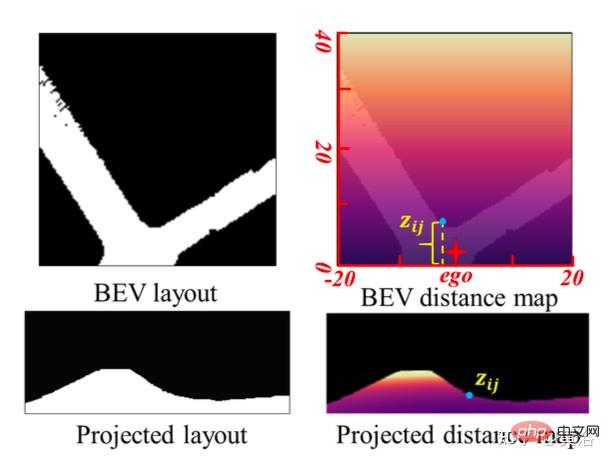
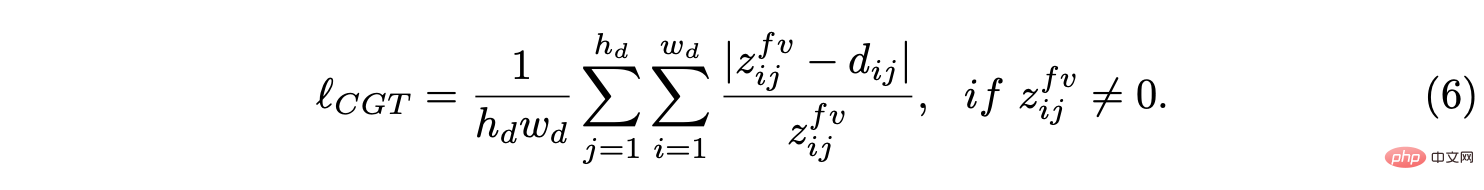
CCT- CV et CCT-CM du module cross-view et du module cross-modal.
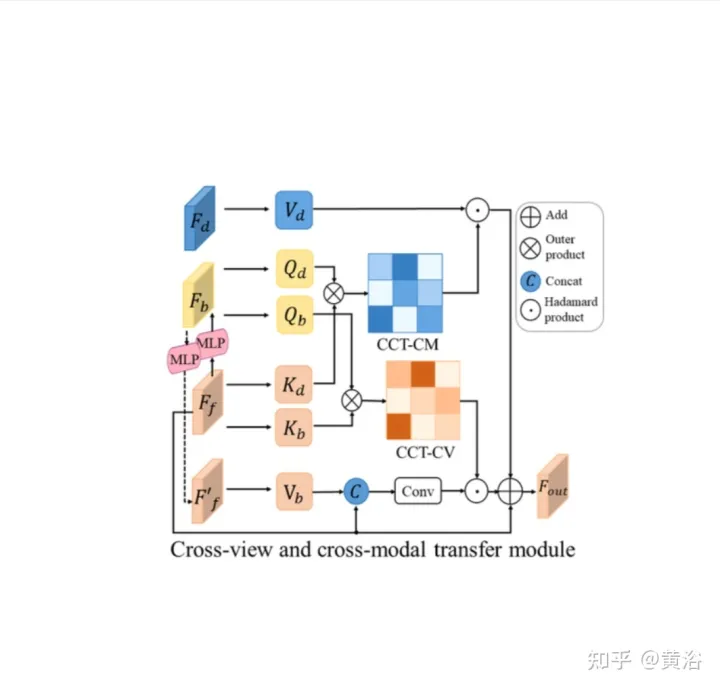
En CCT, Ff et Fd sont extraits par l'encodeur de la branche perceptuelle correspondante, tandis que Fb est obtenu par une projection de vue MLP pour convertir Ff en BEV, et une perte de cycle contrainte par le même MLP pour le reconvertir en Ff′.
Dans CCT-CV, le mécanisme d'attention croisée est utilisé pour découvrir la correspondance géométrique entre la vue avant et les caractéristiques BEV, puis guide le raffinement des informations de vue avant et prépare l'inférence BEV. Afin d'utiliser pleinement les fonctionnalités d'image de vue avant, Fb et Ff sont projetés sur des correctifs : Qbi et Kbi, respectivement en tant que requête et clé.
En plus d'utiliser les fonctionnalités de vue avant, CCT-CM est également déployé pour imposer des informations géométriques 3D à partir de Fd. Puisque Fd est extrait de l’image de vue avant, il est raisonnable d’utiliser Ff comme pont pour réduire l’écart intermodal et apprendre la correspondance entre Fd et Fb. Fd joue le rôle de valeur, obtenant ainsi de précieuses informations géométriques 3D liées aux informations BEV et améliorant encore la précision de l'estimation du tracé routier.
Dans le processus d'exploration d'un cadre d'apprentissage commun pour prédire simultanément différentes dispositions, il existe de grandes différences dans les caractéristiques et la distribution des différentes catégories sémantiques. Pour les fonctionnalités, le tracé de la route dans les scénarios de conduite doit généralement être connecté, tandis que les différentes cibles de véhicules doivent être segmentées.
Pour la distribution, plus de scènes de routes droites sont observées que de scènes de virage, ce qui est raisonnable dans des ensembles de données réels. Cette différence et ce déséquilibre augmentent la difficulté de l'apprentissage de la disposition BEV, en particulier la prédiction conjointe de différentes catégories, car une simple perte d'entropie croisée (CE) ou une perte L1 échoue dans ce cas. Plusieurs pertes de segmentation, notamment la perte CE basée sur la distribution, la perte IoU basée sur la région et la perte de limite, sont combinées en une perte hybride pour prédire la disposition de chaque catégorie.
Les résultats expérimentaux sont les suivants :
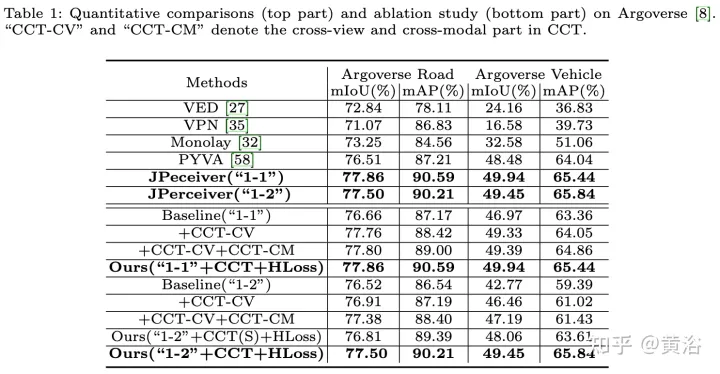
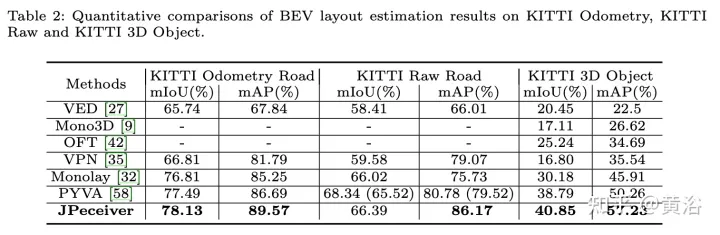
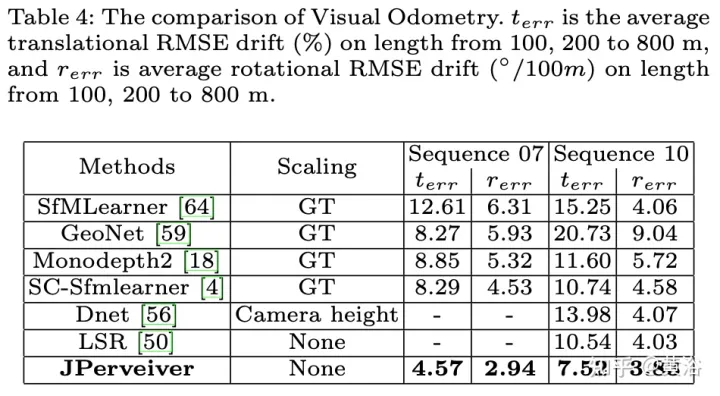
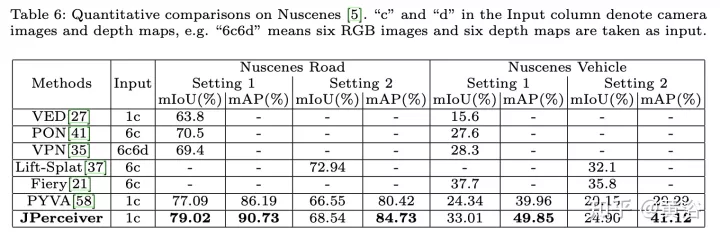
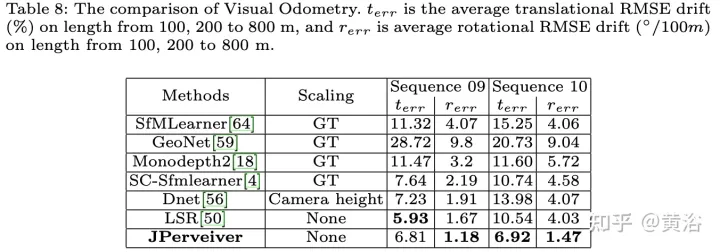
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI