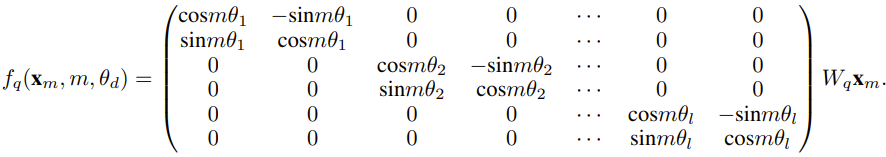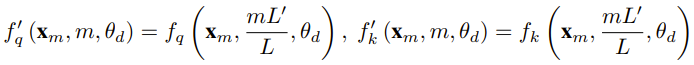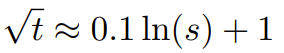Les grands modèles de langage (LLM) basés sur des transformateurs ont démontré leur puissante capacité à effectuer un apprentissage contextuel (ICL) et sont presque devenus le seul choix pour de nombreuses tâches de traitement du langage naturel (NLP). Le mécanisme d'auto-attention de Transformer permet à la formation d'être hautement parallélisée, permettant ainsi de traiter de longues séquences de manière distribuée. La longueur de la séquence utilisée pour la formation LLM est appelée sa fenêtre contextuelle.
La fenêtre contextuelle de Transformer détermine directement la quantité d'espace dans lequel les exemples peuvent être fournis, limitant ainsi ses capacités ICL. Si la fenêtre contextuelle du modèle est limitée, il y a moins de place pour fournir au modèle des exemples robustes sur lesquels effectuer l'ICL. De plus, d'autres tâches telles que la synthèse sont également gravement entravées lorsque la fenêtre contextuelle du modèle est particulièrement courte. En termes de nature du langage lui-même, l'emplacement du jeton est crucial pour une modélisation efficace, et l'attention personnelle n'encode pas directement les informations de localisation en raison de son parallélisme. L'architecture Transformer introduit un codage positionnel pour résoudre ce problème. L'architecture originale du Transformer utilisait un codage de position sinusoïdale absolue, qui a ensuite été amélioré en un codage de position absolue apprenable. Depuis lors, les schémas de codage de position relative ont encore amélioré les performances du transformateur. Actuellement, les codages de position relative les plus populaires sont T5 Relative Bias, RoPE, XPos et ALiBi. L'encodage positionnel présente une limitation récurrente : l'impossibilité de généraliser à la fenêtre contextuelle vue lors de l'entraînement. Bien que certaines méthodes telles que ALiBi aient la capacité de faire une généralisation limitée, aucune méthode ne s'est encore généralisée à des séquences significativement plus longues que sa longueur pré-entraînée. Certains résultats de recherches ont tenté de surmonter ces limites. Par exemple, certaines recherches proposent de modifier légèrement RoPE via une interpolation positionnelle (PI) et d'affiner une petite quantité de données pour étendre la longueur du contexte. Il y a deux mois, Bowen Peng de Nous Research a partagé une solution sur Reddit, qui consiste à mettre en œuvre une « interpolation compatible NTK » en incorporant des pertes haute fréquence. NTK fait ici référence à Neural Tangent Kernel. Il prétend que le RoPE étendu compatible NTK peut étendre considérablement la fenêtre contextuelle du modèle LLaMA (plus de 8k) sans aucun réglage fin et avec un impact minimal sur la perplexité. Récemment, un article connexe rédigé par lui et trois autres collaborateurs a été publié !
- Papier : https://arxiv.org/abs/2309.00071
- Modèle : https://github.com/jquesnelle/yarn
Dans ce papier, ils ont fait deux améliorations de l'interpolation compatible NTK, qui se concentrent sur différents aspects :
- Méthode d'interpolation dynamique NTK, qui peut être utilisée pour les modèles pré-entraînés sans réglage fin.
- Méthode d'interpolation NTK partielle, le modèle peut atteindre les meilleures performances lorsqu'il est affiné avec une petite quantité de données contextuelles plus longues.
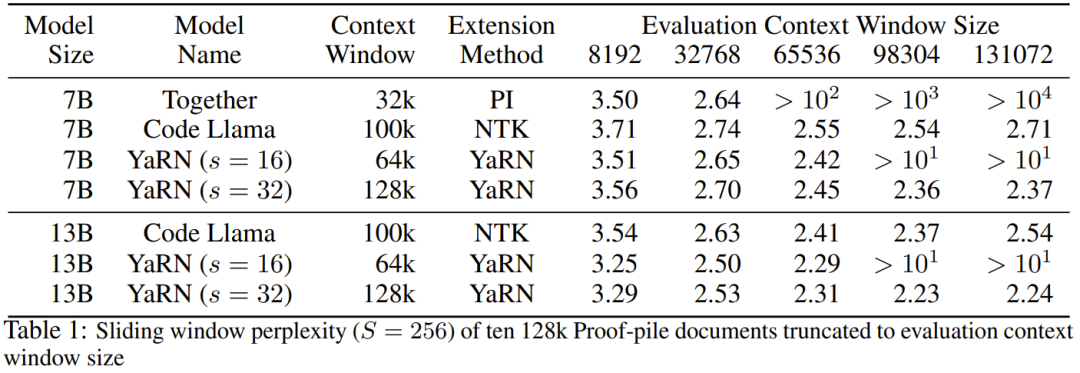
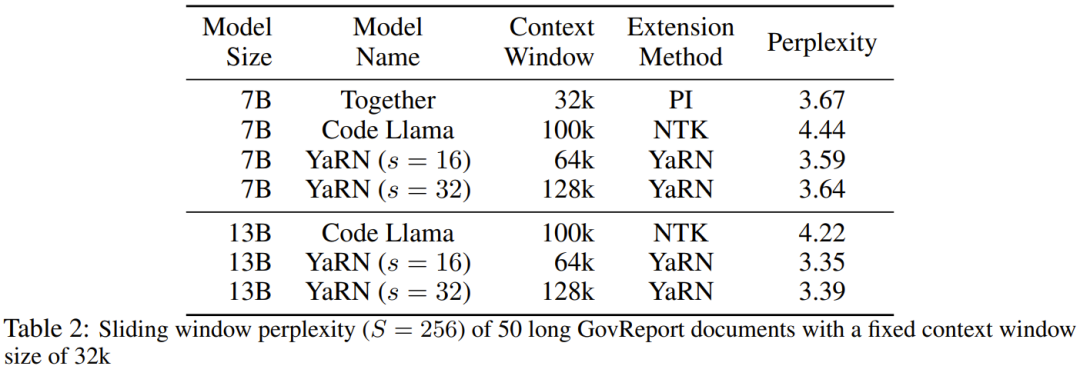
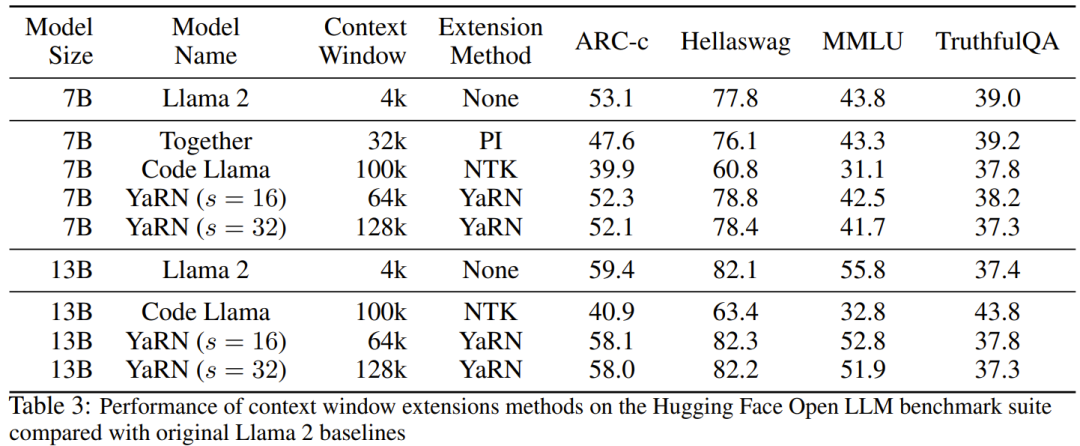
Le chercheur a déclaré qu'avant la naissance de cet article, certains chercheurs utilisaient déjà l'interpolation compatible NTK et l'interpolation NTK dynamique pour certains modèles open source. Les exemples incluent Code Llama (qui utilise l'interpolation compatible NTK) et Qwen 7B (qui utilise l'interpolation NTK dynamique). Dans cet article, sur la base des résultats de recherches antérieures sur l'interpolation compatible NTK, l'interpolation dynamique NTK et l'interpolation NTK partielle, les chercheurs ont proposé YaRN (Yet another RoPE extensioN method), une méthode qui peut étendre efficacement l'utilisation de la rotation. La méthode de fenêtre contextuelle du modèle Rotary Position Embeddings (RoPE) peut être utilisée pour les modèles des séries LLaMA, GPT-NeoX et PaLM. L'étude a révélé que YaRN peut actuellement atteindre les meilleures performances d'expansion de la fenêtre de contexte en utilisant uniquement des échantillons représentatifs qui représentent environ 0,1 % de la taille des données de pré-entraînement du modèle d'origine pour un réglage précis. Rotary Position Embeddings (RoPE) a été introduite pour la première fois par l'article "RoFormer: Enhanced transformer with Rotary position embedding" et constitue également la base de YaRN.En termes simples, RoPE peut être écrit comme suit : Pour un LLM pré-entraîné avec une longueur de contexte fixe, si l'interpolation positionnelle (PI) est utilisée pour étendre la longueur du contexte, elle peut être exprimée comme suit : On peut voir que PI étendra également toutes les dimensions de RoPE. Les chercheurs ont découvert que les limites d'interpolation théoriques décrites dans l'article de PI étaient insuffisantes pour prédire la dynamique complexe entre les intégrations internes RoPE et LLM. Les principaux problèmes d'IP découverts et résolus par les chercheurs seront décrits ci-dessous afin que les lecteurs puissent comprendre le contexte, les causes et les raisons de la résolution de diverses nouvelles méthodes dans YaRN. Perte d'informations haute fréquence - Interpolation compatible NTK Si vous regardez RoPE uniquement du point de vue du codage de l'information, selon la théorie du noyau tangent neuronal (NTK), si la dimension d'entrée est faible et l'intégration correspondante manque de composants haute fréquence, il est alors difficile pour les réseaux neuronaux profonds d'apprendre des informations haute fréquence. Pour résoudre le problème de la perte d'informations haute fréquence lors de l'intégration de l'interpolation pour RoPE, Bowen Peng a proposé une interpolation compatible NTK dans l'article Reddit ci-dessus. Cette approche n'étend pas chaque dimension du RoPE de manière égale, mais répartit plutôt la pression d'interpolation sur plusieurs dimensions en élargissant moins les hautes fréquences et davantage les basses fréquences. Lors des tests, les chercheurs ont constaté que cette approche surpassait l'IP en termes de mise à l'échelle de la taille du contexte du modèle sans réglage fin. Cependant, cette approche présente un inconvénient majeur : comme il ne s'agit pas simplement d'un schéma d'interpolation, certaines dimensions sont extrapolées dans certaines valeurs "extérieures", donc le réglage fin à l'aide de l'interpolation compatible NTK n'est pas aussi efficace que PI. De plus, en raison de l'existence de valeurs « extérieures », le facteur d'expansion théorique ne peut pas décrire avec précision le véritable degré d'expansion du contexte. En pratique, pour une extension de longueur de contexte donnée, la valeur d'extension s doit être légèrement supérieure à la valeur d'extension attendue. Perte de distance locale relative - interpolation NTK partielle Pour l'intégration RoPE, il y a une observation intéressante : étant donné une taille de contexte L, il existe une dimension d dans laquelle la longueur d'onde λ est plus longue que la pré- La plus grande longueur de contexte observée pendant la formation (λ > L), indiquant que les intégrations de certaines dimensions peuvent être inégalement réparties dans le domaine en rotation. L'interpolation compatible PI et NTK traite toutes les dimensions cachées RoPE de la même manière (comme si elles avaient le même effet sur le réseau). Mais les chercheurs ont découvert grâce à des expériences qu’Internet traite certaines dimensions différemment que d’autres. Comme mentionné précédemment, étant donné une longueur de contexte L, certaines dimensions ont des longueurs d'onde λ supérieures ou égales à L. Puisque lorsque la longueur d'onde d'une dimension cachée est supérieure ou égale à L, toutes les paires de positions coderont une distance spécifique, les chercheurs émettent donc l'hypothèse que les informations de position absolue sont conservées lorsque la longueur d'onde est plus courte, le réseau ne peut obtenir que la position relative ; informations sur le poste. Lors de l'étirement de toutes les dimensions de RoPE à l'aide de l'échelle d'expansion s ou de la valeur de changement de base b', tous les jetons se rapprocheront les uns des autres car le produit scalaire de deux vecteurs tournés d'une plus petite quantité sera plus grand. Cette extension peut sérieusement nuire à la capacité du LLM à comprendre les petites relations locales entre ses intégrations internes. Les chercheurs ont émis l’hypothèse que cette compression entraînerait une confusion du modèle quant à l’ordre de position des jetons à proximité, nuisant ainsi aux capacités du modèle. Pour résoudre ce problème, sur la base des phénomènes observés par les chercheurs, ils ont choisi de ne pas interpoler du tout les dimensions de fréquence plus élevée. Ils ont également proposé que pour toutes les dimensions d, les dimensions de r β ne soient pas du tout interpolées (toujours extrapolées). Grâce à la technique décrite dans cette section, une méthode appelée interpolation NTK partielle est née. Cette méthode améliorée surpasse les précédentes méthodes d'interpolation compatibles PI et NTK et fonctionne à la fois sur des modèles non réglés et affinés. Étant donné que cette méthode évite d'extrapoler des dimensions où le domaine de rotation est inégalement réparti, tous les problèmes de réglage fin des méthodes précédentes sont évités. Mise à l'échelle dynamique - Interpolation NTK dynamique Lors de la mise à l'échelle de la taille du contexte sans réglage fin à l'aide de la méthode d'interpolation RoPE, nous nous attendons à ce que le modèle se dégrade lentement sur des tailles de contexte plus longues, plutôt que de mettre à l'échelle les degrés. complètement dégradé sur toute la taille du contexte lorsqu'il dépasse la valeur requise.Dans la méthode NTK dynamique, le degré d'expansion s est calculé dynamiquement. Pendant le processus d'inférence, lorsque la taille du contexte est dépassée, le degré d'expansion s est modifié dynamiquement, ce qui permet à tous les modèles de se dégrader lentement lorsqu'ils atteignent la limite du contexte d'entraînement L au lieu de planter soudainement. Augmenter la similarité cosinus minimale moyenne pour les longues distances - YaRN Même si le problème de distance locale décrit précédemment est résolu, afin d'éviter l'extrapolation, une interpolation plus grande au seuil α doit être la distance. Intuitivement, cela ne semble pas poser de problème, car la distance globale ne nécessite pas une grande précision pour distinguer les positions des jetons (c'est-à-dire que le réseau a seulement besoin de savoir approximativement si le jeton se trouve au début, au milieu ou à la fin de la séquence). Cependant, les chercheurs ont découvert que puisque la distance minimale moyenne se rapproche à mesure que le nombre de jetons augmente, cela rendra la distribution du softmax d'attention plus pointue (c'est-à-dire réduira l'entropie moyenne du softmax d'attention). En d’autres termes, à mesure que l’impact de l’atténuation longue distance est réduit par l’interpolation, le réseau « accorde plus d’attention » à davantage de jetons. Ce changement de distribution peut conduire à une dégradation de la qualité des résultats du LLM, ce qui constitue un autre problème sans rapport avec la question précédente. Étant donné que l'entropie dans la distribution softmax de l'attention diminue lors de l'interpolation des intégrations RoPE vers des tailles de contexte plus longues, nous visons à inverser cette diminution d'entropie (c'est-à-dire augmenter la "température" du logit de l'attention). Cela peut être fait en multipliant la matrice d'attention intermédiaire par la température t > 1 avant d'appliquer softmax, mais comme l'intégration RoPE est codée comme une matrice de rotation, il est possible d'étendre simplement la longueur de l'intégration RoPE d'un facteur constant √t . Cette technique « d'expansion de longueur » permet la recherche sans modifier le code d'attention, ce qui simplifie grandement l'intégration avec les pipelines de formation et d'inférence existants et a une complexité temporelle de seulement O(1). Étant donné que ce schéma d'interpolation RoPE interpole de manière inégale sur les dimensions RoPE, il est difficile de calculer une solution analytique pour l'échelle de température requise t par rapport au degré d'expansion s. Heureusement, les chercheurs ont découvert grâce à des expériences qu'en minimisant la perplexité, tous les modèles LLaMA suivent à peu près la même courbe d'ajustement : Les chercheurs ont découvert cette formule sur LLaMA 7B, 13B, 33B et 65B. Ils ont constaté que cette formule fonctionnait également bien pour les modèles LLaMA 2 (7B, 13B et 70B), avec des différences subtiles. Cela suggère que cette propriété d'augmentation de l'entropie est commune et se généralise à différents modèles et données de formation. Cette dernière modification a abouti à la méthode YaRN. La nouvelle méthode surpasse toutes les méthodes précédentes dans des scénarios affinés ou non, sans nécessiter aucune modification du code d'inférence. Seul l’algorithme utilisé pour générer les plongements RoPE doit en premier lieu être modifié. YaRN est si simple qu'il peut être facilement implémenté dans toutes les bibliothèques d'inférence et de formation, y compris la compatibilité avec Flash Attention 2. L'expérience montre que YaRN peut étendre avec succès la fenêtre contextuelle de LLM. De plus, ils ont obtenu ce résultat après une formation de seulement 400 étapes, ce qui représente environ 0,1 % du corpus de pré-formation original du modèle, une diminution significative par rapport aux travaux précédents. Cela montre que la nouvelle méthode est très efficace sur le plan informatique et n’entraîne aucun coût d’inférence supplémentaire. Pour évaluer le modèle résultant, les chercheurs ont calculé la perplexité des documents longs et les ont notés sur des critères existants, et ont constaté que la nouvelle méthode surpassait toutes les autres méthodes d'expansion de fenêtre contextuelle. Tout d'abord, les chercheurs ont évalué les performances du modèle lorsque la fenêtre contextuelle était augmentée. Le tableau 1 résume les résultats expérimentaux. Le tableau 2 montre la perplexité finale sur 50 documents GovReport non censurés (d'une longueur d'au moins 16 000 jetons). Pour tester la dégradation des performances du modèle lors de l'utilisation d'extensions de contexte, les chercheurs ont évalué le modèle à l'aide de la suite Hugging Face Open LLM Leaderboard et l'ont comparé au modèle de base LLaMA 2 et aux modèles compatibles PI et NTK accessibles au public. sont des scores comparés. Le tableau 3 résume les résultats expérimentaux. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!