
Maison >Périphériques technologiques >IA >Utilisé pour la pré-formation auto-supervisée SOTA !
Utilisé pour la pré-formation auto-supervisée SOTA !

- 王林avant
- 2023-09-15 09:53:071416parcourir

Idée de thèse :
l'encodage automatique masqué est devenu un paradigme de pré-formation réussi pour les modèles Transformer de texte, d'images et, plus récemment, de nuages de points. Les ensembles de données brutes sur les voitures conviennent à la pré-formation auto-supervisée car ils sont généralement moins coûteux à collecter que l'annotation pour des tâches telles que la détection d'objets 3D (OD). Cependant, le développement d’auto-encodeurs masqués pour les nuages de points s’est uniquement concentré sur les données synthétiques et intérieures. Par conséquent, les méthodes existantes ont adapté leurs représentations et modèles en nuages de points petits et denses avec une densité de points uniforme. Dans ce travail, nous étudions l'autoencodage masqué sur des nuages de points dans des contextes automobiles, qui sont clairsemés et dont la densité peut varier considérablement entre différents objets d'une même scène. À cette fin, cet article propose Voxel-MAE, un schéma simple de pré-entraînement à l'auto-codage masqué conçu pour la représentation des voxels. Cet article pré-entraîne un squelette de détecteur d'objets 3D basé sur Transformer pour reconstruire les voxels masqués et distinguer les voxels vides des voxels non vides. Notre méthode améliore les performances 3D OD de 1,75 mAP et 1,05 NDS sur l'ensemble de données complexe nuScenes. De plus, nous montrons qu'en utilisant Voxel-MAE pour la pré-formation, nous n'avons besoin que de 40 % de données annotées pour surpasser les données équivalentes avec initialisation aléatoire.
Principales contributions :
Cet article propose Voxel-MAE (une méthode de déploiement de pré-entraînement auto-supervisé de style MAE sur des nuages de points voxélisés), et l'exécute sur le grand ensemble de données de nuages de points automobiles nuScenes. . La méthode présentée dans cet article est le premier programme de pré-formation auto-supervisé utilisant le réseau fédérateur de nuage de points automobile Transformer.
Cet article adapte notre méthode de représentation des voxels et utilise un ensemble unique de tâches de reconstruction pour capturer les caractéristiques des nuages de points voxélisés.
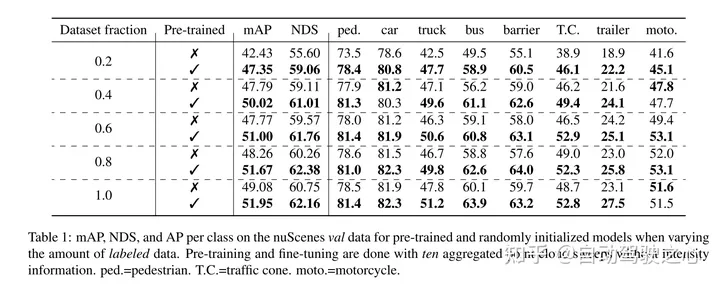
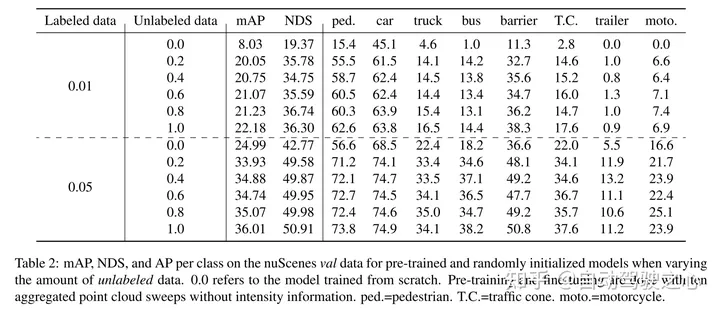
Cet article prouve que notre méthode est efficace en matière de données et réduit le besoin de données annotées. Avec une pré-formation, cet article surpasse les données entièrement supervisées en utilisant seulement 40 % des données annotées.
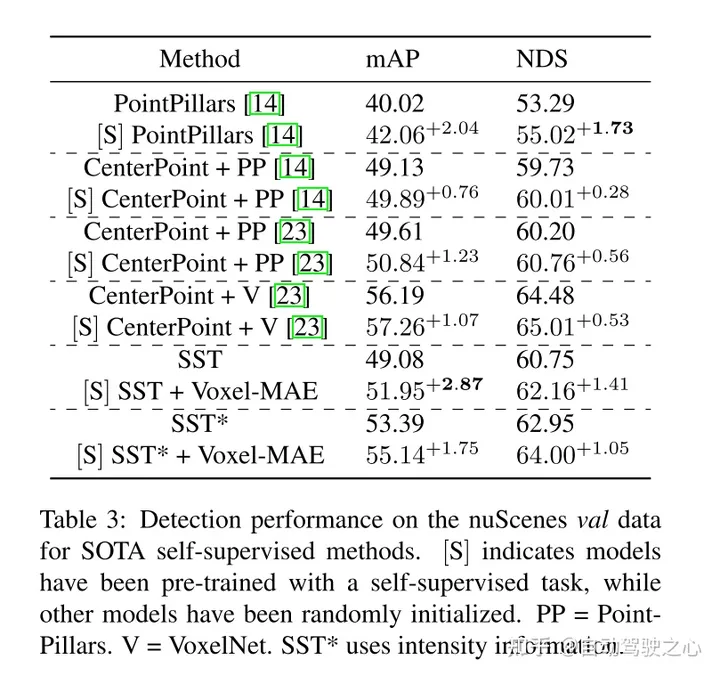
De plus, cet article révèle que Voxel-MAE améliore les performances des détecteurs basés sur transformateur de 1,75 point de pourcentage dans mAP et de 1,05 point de pourcentage dans NDS, améliorant ainsi ses performances par rapport aux méthodes auto-supervisées existantes.
Conception de réseau :
Le but de ce travail est d'étendre la pré-formation de style MAE aux nuages de points voxélisés. L'idée principale est toujours d'utiliser un encodeur pour créer une représentation latente riche à partir d'observations partielles de l'entrée, puis d'utiliser un décodeur pour reconstruire l'entrée d'origine, comme le montre la figure 2. Après la pré-formation, l'encodeur est utilisé comme épine dorsale du détecteur d'objets 3D. Cependant, en raison des différences fondamentales entre les images et les nuages de points, certaines modifications sont nécessaires pour une formation efficace de Voxel-MAE.
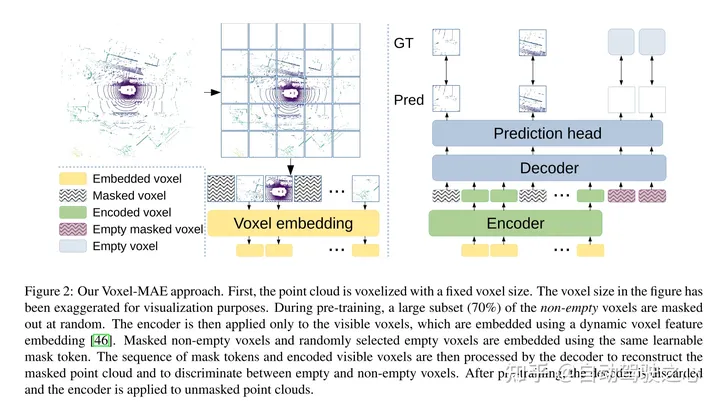
Figure 2 : Méthode Voxel-MAE de cet article. Tout d’abord, le nuage de points est voxélisé avec une taille de voxel fixe. Les tailles de voxels dans les figures ont été exagérées à des fins de visualisation. Avant l'entraînement, une grande partie (70 %) des voxels non vides sont masqués de manière aléatoire. L'encodeur est ensuite appliqué uniquement aux voxels visibles, intégrant ces voxels à l'aide de l'intégration de fonctionnalités de voxels dynamiques [46]. Les voxels non vides masqués et les voxels vides sélectionnés au hasard sont intégrés à l'aide des mêmes jetons de masque apprenables. Le décodeur traite ensuite la séquence de jetons de masque et la séquence codée de voxels visibles pour reconstruire le nuage de points masqué et distinguer les voxels vides des voxels non vides. Après le pré-entraînement, le décodeur est abandonné et l'encodeur est appliqué au nuage de points non masqué.

Figure 1 : MAE (à gauche) divise l'image en patchs de taille fixe qui ne se chevauchent pas. Les méthodes de modélisation de points masqués existantes (au milieu) créent un nombre fixe de patchs de nuages de points en utilisant l'échantillonnage des points les plus éloignés et les k voisins les plus proches. Notre méthode (à droite) utilise des voxels non superposés et un nombre dynamique de points.
Résultats expérimentaux :
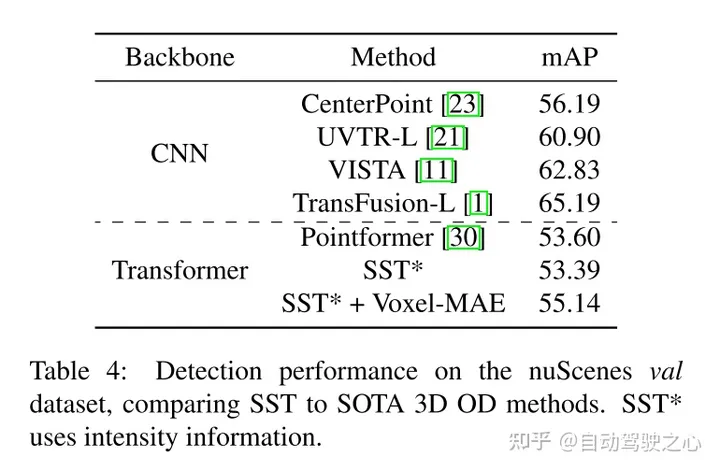
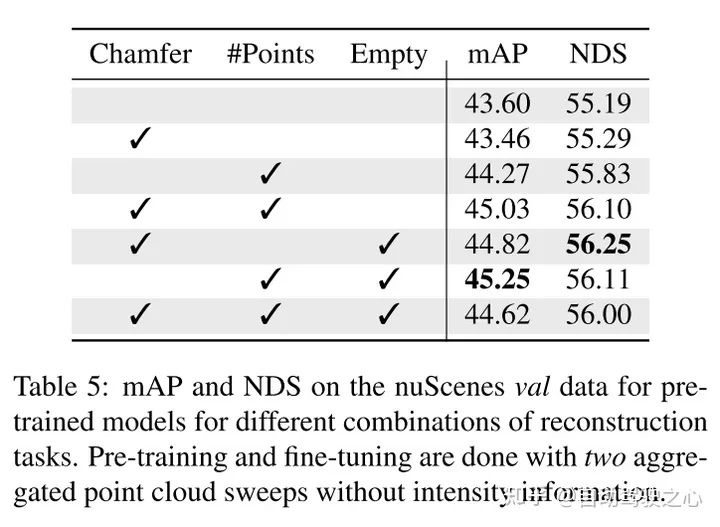
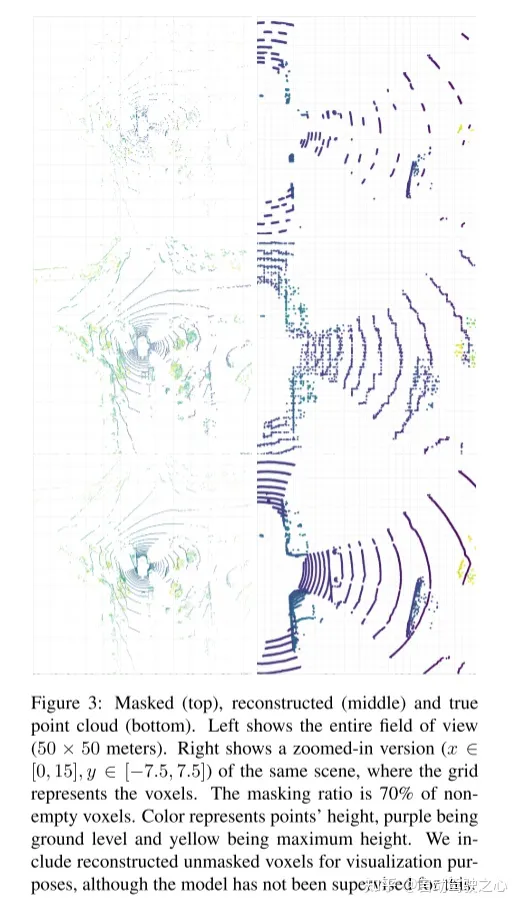
引用:
Hess G, Jaxing J, Svensson E, et al. Auto-encodeur masqué pour la pré-formation auto-supervisée sur les nuages de points lidar[C]//Actes de la conférence d'hiver IEEE/CVF sur les applications de la vision par ordinateur. 2023 : 350-359.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quelles sont la plupart des technologies de commutation utilisées dans les WAN ?
- Quelles sont les trois étapes franchies par le développement de la technologie de gestion de bases de données ?
- Un article pour comprendre la perception lidar et fusion visuelle de la conduite autonome
- Qu'est-ce qu'un radar multiéléments