
Maison >Périphériques technologiques >IA >LeCun soutient le chef-d'œuvre de cinq ans du professeur Ma Yi : un transformateur boîte blanche entièrement interprétable mathématiquement dont les performances ne sont pas inférieures à celles de ViT.
LeCun soutient le chef-d'œuvre de cinq ans du professeur Ma Yi : un transformateur boîte blanche entièrement interprétable mathématiquement dont les performances ne sont pas inférieures à celles de ViT.

- PHPzavant
- 2023-06-10 08:39:311480parcourir
Au cours des dix dernières années, le développement rapide de l'IA est principalement dû aux progrès de la pratique de l'ingénierie. La théorie de l'IA n'a pas encore joué de rôle dans le développement d'algorithmes. une boîte noire.
Avec la popularité de ChatGPT, les capacités de l'IA ont été constamment exagérées et mises en avant, au point même de menacer et de kidnapper la société. La conception de l'architecture du Transformer est devenue transparente. . Sans tarder !

Récemment, l'équipe du professeur Ma Yi a publié les derniers résultats de recherche et a conçu un mathématiques entièrement utilisable. a expliqué le modèle Transformer en boîte blanche CRATE, et atteint des performances proches de ViT sur l'ensemble de données du monde réel ImageNet-1K.
Lien du code : https://github.com/Ma-Lab-Berkeley/CRATE
Lien papier : https://arxiv.org/abs/2306.01129
Dans cet article, les chercheurs pensent que l'objectif de l'apprentissage de la représentation est de compresser et de transformer la distribution des données (telles que les collections de jetons) pour prendre en charge un mélange de distributions gaussiennes de basse dimension sur des sous-espaces incohérents. La qualité de la représentation finale peut être déterminée par le taux de parcimonie. . Mesuré par la fonction objective unifiée de réduction du taux clairsemé.
De ce point de vue, les modèles de réseaux profonds populaires tels que Transformer peuvent naturellement être considérés comme réalisant des schémas itératifs pour optimiser progressivement la cible.
En particulier, les résultats montrent que le bloc Transformateur standard peut être dérivé d'une optimisation alternée de parties complémentaires de cet objectif : l'opérateur d'auto-attention multi-têtes peut être considéré comme L'étape de descente de gradient compresse l'ensemble de jetons en minimisant le taux de codage avec perte, et le perceptron multicouche ultérieur peut être considéré comme essayant de disperser la représentation du jeton.
Cette découverte a également favorisé la conception d'une série d'architectures de réseau profond de type transformateur en boîte blanche qui sont entièrement interprétables mathématiquement. Bien que la conception soit simple, les résultats expérimentaux le montrent. Ainsi, ces réseaux ont en effet appris à optimiser les objectifs de conception : compresser et fragmenter les représentations d'ensembles de données visuelles du monde réel à grande échelle tels qu'ImageNet, et atteindre des performances proches de celles des modèles Transformer (ViT) hautement sophistiqués.
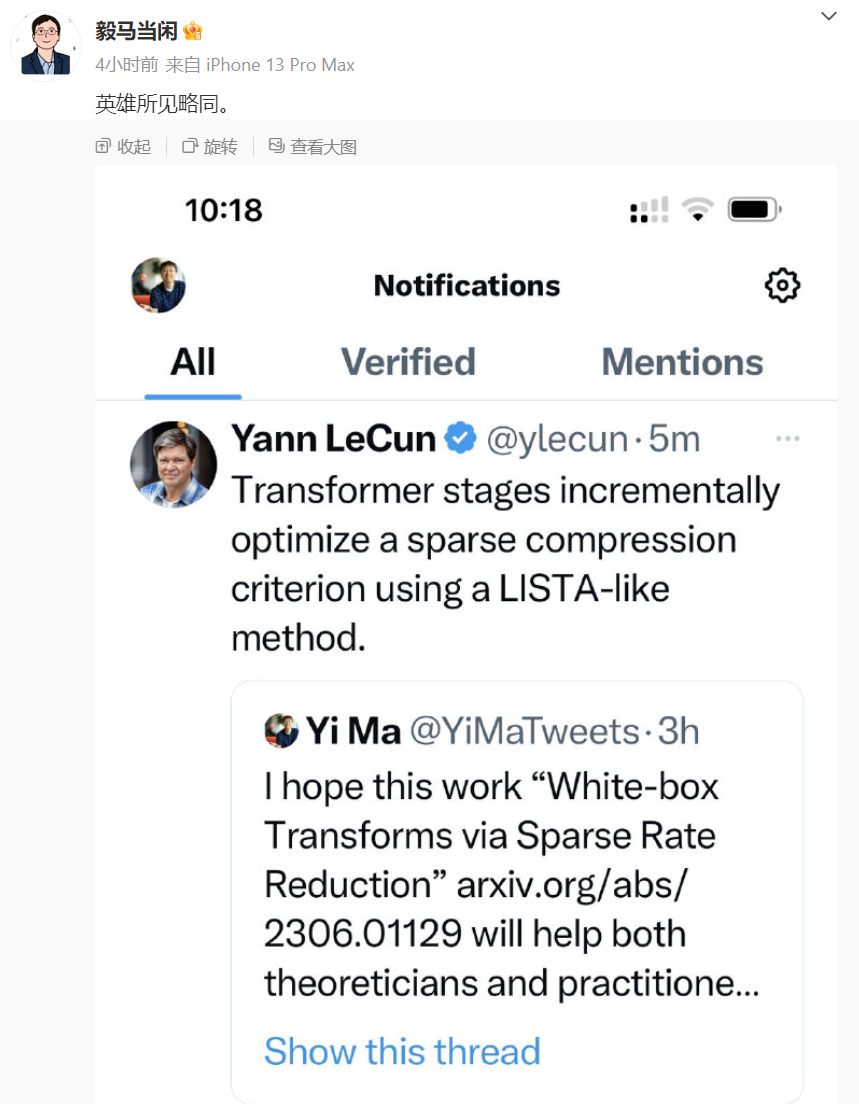
Yann LeCun, lauréat du prix Turing, est également d'accord avec le travail du professeur Ma Yi et estime que Transformer utilise une méthode similaire à LISTA (Learned Iterative Shrinkage and Thresholding Algorithm) pour optimiser progressivement les compression.
Le professeur Ma Yi a obtenu un double baccalauréat en automatisation et mathématiques appliquées de l'Université Tsinghua en 1995 et un baccalauréat en mathématiques appliquées en 1997. Master en EECS de l'Université de Californie à Berkeley, ainsi qu'une maîtrise en mathématiques et un doctorat en EECS en 2000.

En 2018, le professeur Ma Yi a rejoint le département de génie électrique et d'informatique de l'Université de Californie à Berkeley , et a rejoint Hong Kong en janvier de cette année. Il a été doyen de l'Institut de science des données de l'université et a récemment pris la direction du département d'informatique de l'université de Hong Kong.
Les principales orientations de recherche sont la vision par ordinateur 3D, les modèles basse dimensionnelle de données haute dimension, l'optimisation de l'évolutivité et l'apprentissage automatique. Les sujets de recherche récents incluent la géométrie 3D à grande échelle. la structure et l'interaction de la reconstruction ainsi que la relation entre les modèles de faible dimension et les réseaux profonds.
Laissez Transformer devenir une boîte blanche
L'objectif principal de cet article est d'utiliser un cadre plus unifié pour concevoir une structure de réseau similaire à Transformateur. Cela se traduit par une interprétabilité mathématique et de bonnes performances pratiques.
À cette fin, les chercheurs ont proposé d'apprendre une séquence de mappages incrémentiels pour obtenir la représentation la moins compressée et la plus clairsemée des données d'entrée (jeu de jetons), optimiser un système unifié. fonction objective, c’est-à-dire la réduction du taux de rareté.

Ce cadre unifie trois méthodes apparemment différentes : "Modèle de transformateur et auto-attention", "Modèle de diffusion et réduction du bruit" et "Modèles de recherche de structure et réduction de débit", et montre que les couches de réseau profondes de type transformateur peut être naturellement dérivé du déploiement de schémas d’optimisation itératifs pour optimiser progressivement les objectifs de réduction de la parcimonie. Les chercheurs ont utilisé un modèle idéalisé de distribution de jetons pour montrer que si vers le bas, une fois la série de sous-espaces dimensionnels débruitée de manière itérative, la fonction de notation correspondante prendra une forme explicite similaire à l'opérateur d'auto-attention dans Transformer.
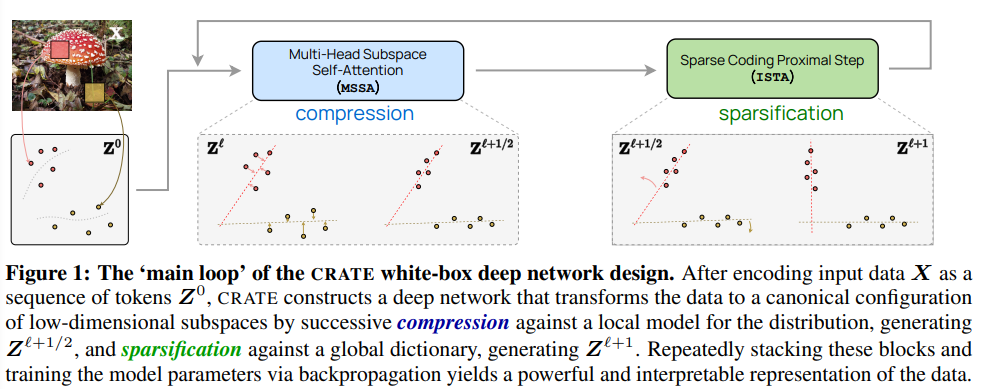
Les chercheurs ont dérivé la couche d'auto-attention à plusieurs têtes comme une étape de descente de gradient dépliée pour minimiser la partie du taux de codage avec perte de la réduction du débit, Cela démontre une autre façon d'interpréter la couche d'auto-attention comme une représentation de jeton compressée.
MLP via des algorithmes itératifs de rétrécissement-seuil (ISTA) pour le codage clairsemé
Les chercheurs ont montré qu'un perceptron multicouche suivant une couche d'auto-attention multi-têtes dans un bloc Transformer peut être interprété comme ( et peut être remplacé par) une couche qui optimise progressivement le reste cible de réduction du taux de parcimonie en construisant des jetons pour représenter un codage clairsemé.CRATE
Sur la base de la compréhension ci-dessus, les chercheurs ont créé une nouvelle architecture de transformateur en boîte blanche CRATE (Coding RAte réduction TransformEr). La fonction objectif d'apprentissage, l'architecture d'apprentissage en profondeur et la représentation finale apprise peuvent toutes être expliquées mathématiquement, où chaque couche effectue une étape de l'algorithme de minimisation alternée pour optimiser l'objectif de réduction de la parcimonie.
On peut remarquer que CRATE a choisi la manière de construire la plus simple possible à chaque étape de la construction. Tant que la partie nouvellement construite conserve le même rôle conceptuel, elle peut être directement remplacée et par une nouvelle. Architecture de boîte blanche.
Partie expérimentaleLes objectifs expérimentaux des chercheurs ne sont pas seulement de rivaliser avec d'autres Transformers bien conçus en utilisant la conception de base, mais incluent également :
1. -performances finales Contrairement aux réseaux de boîte noire conçus de manière empirique, les réseaux conçus en boîte blanche peuvent examiner l'architecture profonde et
vérifier que les couches du réseau appris remplissent effectivement leurs objectifs de conception, c'est-à-dire optimiser progressivement les objectifs.
2. Bien que l'architecture CRATE soit simple, les résultats expérimentaux devraient
vérifier l'énorme potentiel de cette architecture, c'est-à-dire qu'elle peut atteindre des performances correspondant au modèle Transformer hautement sophistiqué sur des ensembles de données réelles à grande échelle. et tâches
sur des ensembles de données réelles à grande échelle. et tâches
Architecture du modèle
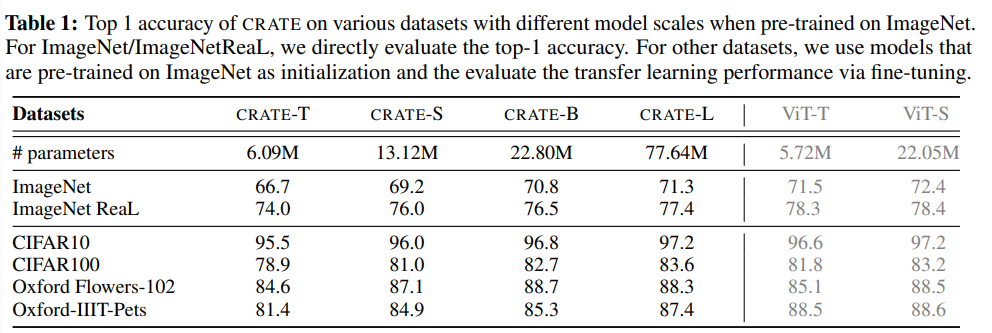
En modifiant la dimension du jeton, le nombre de têtes et le nombre de couches, les chercheurs ont créé quatre modèles CRATE de différentes tailles, représentés par CRATE-Tiny, CRATE-Small, CRATE- Base et CRATE-Large
ensembles de données et optimisation Cet article considère principalement ImageNet-1K comme plate-forme de test et utilise l'optimiseur Lion pour entraîner des modèles CRATE avec différentes tailles de modèle. Les performances d'apprentissage par transfert de CRATE ont également été évaluées : le modèle formé sur ImageNet-1K a été utilisé comme modèle pré-entraîné, puis utilisé sur plusieurs ensembles de données en aval couramment utilisés (CIFAR10/100, Oxford Flowers, Oxford- IIT-Pets) Affinez CRATE. La couche de CRATE a-t-elle atteint ses objectifs de conception ? À mesure que l'indice de couche augmente, on peut voir que les termes de compression et de sparsification du modèle CRATE-Small sont améliorés dans la plupart des cas, et l'augmentation de la mesure de parcimonie de la dernière couche est due à la couche linéaire supplémentaire pour la classification. Les résultats montrent que CRATE correspond bien à l'objectif de conception original : une fois appris, il apprend essentiellement à compresser et à disperser la représentation progressivement à travers ses couches. Après avoir mesuré les termes de compression et de sparsification sur des modèles CRATE d'autres tailles et des points de contrôle de modèles intermédiaires, on peut constater que les résultats expérimentaux sont toujours très cohérents. Les modèles avec plus de couches ont tendance à optimiser la cible plus efficacement, vérifier Améliorer la compréhension préalable des rôles de chaque couche. Comparaison des performances Les performances empiriques du réseau proposé sont étudiées en mesurant la plus haute précision sur ImageNet-1K et les performances d'apprentissage par transfert sur plusieurs ensembles de données en aval largement utilisés. Étant donné que l'architecture conçue utilise le partage de paramètres à la fois dans le bloc d'attention (MSSA) et dans le bloc MLP (ISTA), les paramètres du modèle CRATE-Base (22,08 millions) et ViT-Small (22,05 millions) Les quantités sont similaires. On peut voir que lorsque le nombre de paramètres du modèle est similaire, le réseau proposé dans l'article atteint ImageNet-1K et des performances d'apprentissage de transfert similaires à celles de ViT, mais la conception de CRATE est plus simple et plus interprétable. De plus, CRATE peut continuer à évoluer selon les mêmes hyperparamètres d'entraînement, c'est-à-dire améliorer continuellement les performances en augmentant la taille du modèle, tout en augmentant directement la taille de ViT sur ImageNet-1K ne conduit pas toujours à des résultats cohérents. Améliorations des performances. C'est-à-dire que malgré sa simplicité, le réseau CRATE peut déjà apprendre la compression et la représentation clairsemée requises sur des ensembles de données réelles à grande échelle, et obtenir de meilleurs résultats sur diverses tâches telles que la classification et l'apprentissage par transfert comparable. performances des réseaux de transformateurs techniques (tels que ViT). 

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI