
Maison >Périphériques technologiques >IA >L'image n'est pas cohérente avec le code. Une erreur a été trouvée dans l'article de Transformer : elle aurait dû être signalée 1 000 fois.
L'image n'est pas cohérente avec le code. Une erreur a été trouvée dans l'article de Transformer : elle aurait dû être signalée 1 000 fois.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-25 15:01:06918parcourir
En 2017, l'équipe de Google Brain a proposé de manière créative l'architecture Transformer dans son article « Attention Is All You Need ». Depuis, cette recherche a été piratée et est devenue la plus populaire dans le domaine de la PNL. Aujourd'hui, l'un des modèles est largement utilisé dans diverses tâches linguistiques et a obtenu de nombreux résultats SOTA.
De plus, Transformer, qui a ouvert la voie dans le domaine de la PNL, a rapidement balayé des domaines tels que la vision par ordinateur (CV) et la reconnaissance vocale, et a réalisé de grandes réalisations en matière de classification d'images, de détection de cibles, de reconnaissance vocale, etc. Obtenez de bons résultats dans la tâche. # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 # # # : https://arxiv.org/pdf/1706.03762.pdf
Depuis son lancement, Transformer est devenu le module central de nombreux modèles, tels que tout le monde connaît Les transformateurs sont inclus dans BERT, T5, etc. Même ChatGPT, devenu populaire récemment, s'appuie sur Transformer, qui a déjà été breveté par Google. 
Source de l'image :https://patentimages.storage.googleapis.com/05/e8/f1/cd8eed389b7687/US10452978.pdf
De plus, une série de Les modèles publiés par OpenAI GPT (Generative Pre-trained Transformer), avec Transformer dans son nom, montrent que Transformer est le cœur du modèle de la série GPT. 
En 6 ans, le modèle basé sur Transformer n'a cessé de grandir et de se développer. Mais maintenant, quelqu'un a découvert une erreur dans le document original de Transformer.
Le diagramme et le code de l'architecture du transformateur sont "incohérents"
La personne qui a découvert l'erreur était un chercheur bien connu en apprentissage automatique et en IA et Sebastian Raschka, éducateur en chef en IA de Lightning AI. Il a souligné que le schéma d'architecture de l'article original de Transformer était incorrect, plaçant une normalisation de couche (LN) entre les blocs résiduels, ce qui n'était pas cohérent avec le code. Le schéma d'architecture du transformateur est le suivant à gauche, le côté droit de l'image montre la couche Post-LN Transformer (extrait de l'article "Sur la normalisation des couches dans l'architecture du transformateur" [1]).La partie de code incohérente est la suivante. La ligne 82 écrit la séquence d'exécution "layer_postprocess_sequence="dan"", ce qui signifie que le post-traitement exécute dropout, résidu_add et layer_norm dans l'ordre. Si add&norm au milieu gauche de l'image ci-dessus est compris comme : add est au-dessus de la norme, c'est-à-dire norm d'abord puis add, alors le code est effectivement incohérent avec l'image.
Code adresse :
https:/ /github.com/tensorflow/tensor2tensor/commit/f5c9b17e617ea9179b7d84d36b1e8162cb369f25#diff-76e2b94ef16871bdbf46bf04dfe7f1477bafb884748f08197c9cf1b10a4dd78e…# 🎜🎜# 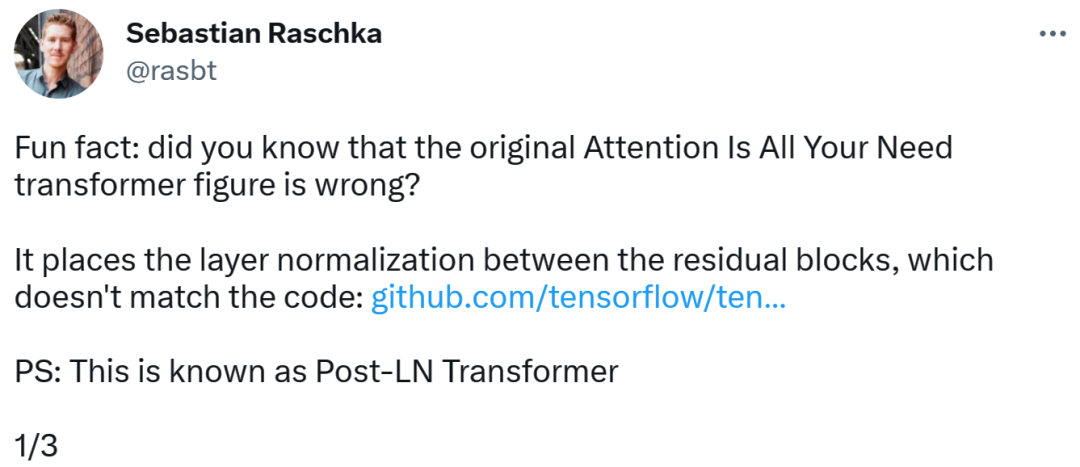
De meilleurs dégradés peuvent être obtenus lorsque la normalisation des couches est placée dans la connexion résiduelle avant l'attention et les couches entièrement connectées.
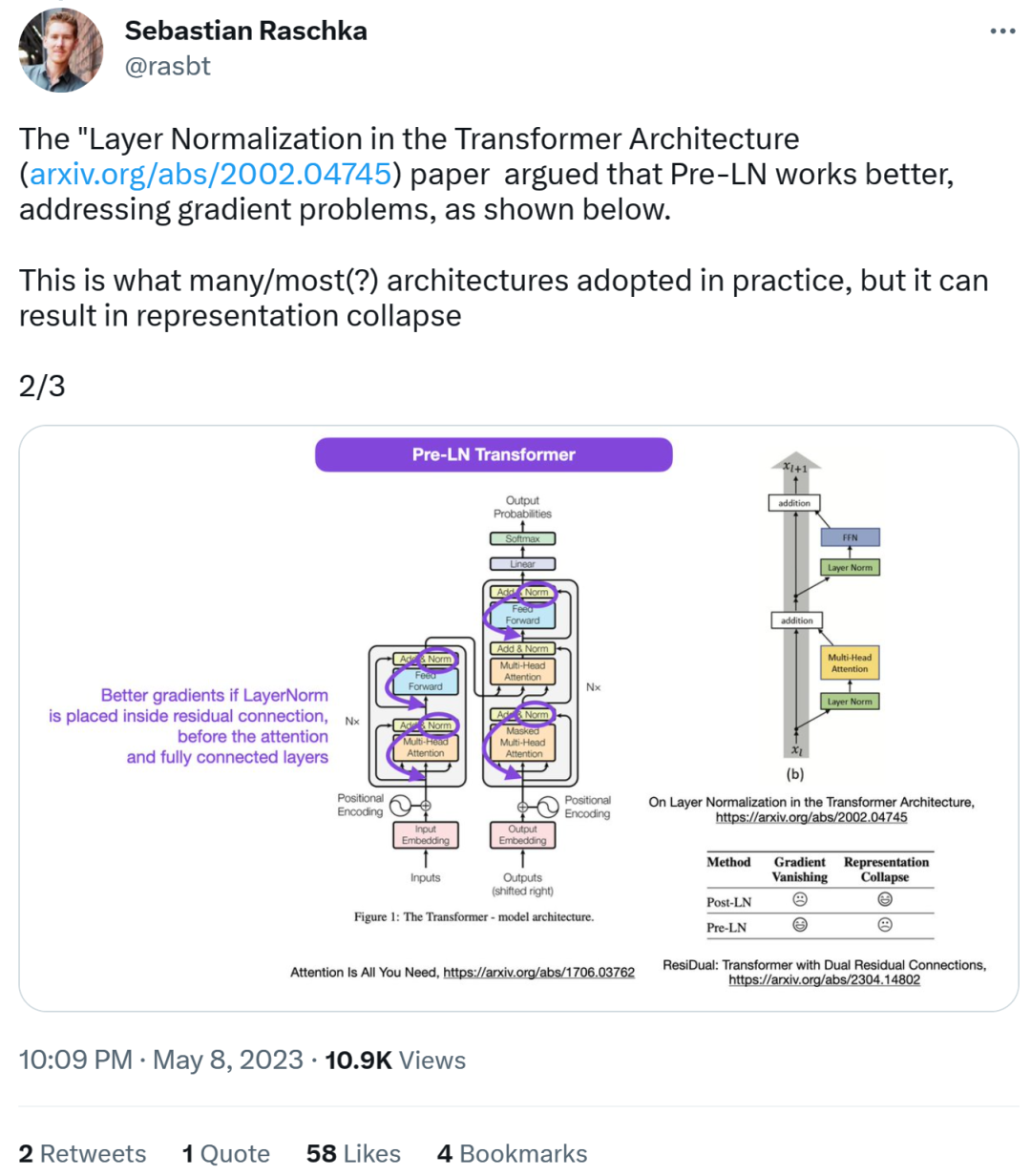
Donc, alors que le débat sur le Post-LN ou le Pré-LN demeure On continue, mais un autre article combine ces deux points, à savoir « ResiDual : Transformer with Dual Residual Connections »[2].
Concernant la découverte de Sébastien, certains pensent que l'on rencontre souvent des papiers incohérents avec le code ou les résultats. La plupart sont honnêtes, mais parfois c'est étrange. Compte tenu de la popularité de l’article de Transformer, cette incohérence aurait dû être mentionnée mille fois.
Sebastian a répondu que, pour être honnête, le code "le plus original" est effectivement cohérent avec le schéma d'architecture, mais la version de code soumise en 2017 a été modifiée et n'a pas été modifiée. Mettre à jour le diagramme d'architecture. Donc, c'est vraiment déroutant. Comme l'a dit un internaute : « Le pire dans la lecture de code, c'est que vous trouverez souvent de petits changements comme celui-ci, et vous ne savez pas s'ils sont intentionnels ou non. Vous ne pouvez même pas le tester parce que vous n'en avez pas assez. puissance de calcul pour entraîner le modèle.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI