
Maison >Périphériques technologiques >IA >Les nouveaux travaux du professeur Ma Yi : le ViT en boîte blanche parvient à réaliser une « émergence partitionnée », l'ère de l'apprentissage profond empirique touche-t-elle à sa fin ?
Les nouveaux travaux du professeur Ma Yi : le ViT en boîte blanche parvient à réaliser une « émergence partitionnée », l'ère de l'apprentissage profond empirique touche-t-elle à sa fin ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-09-14 14:45:081515parcourir
Le modèle visuel de base basé sur Transformer a montré des performances très puissantes dans diverses tâches en aval, telles que la segmentation et la détection, et des modèles tels que DINO ont émergé avec des attributs de segmentation sémantique après une formation auto-supervisée.
Il est étrange que le modèle visuel Transformer ne montre pas de capacités d'émergence similaires après avoir été entraîné à la classification supervisée
Récemment, l'équipe du professeur Ma Yi a étudié un modèle basé sur l'architecture Transformer pour explorer l'émergence. La capacité de segmentation est-elle simplement le résultat d'un mécanisme d'apprentissage auto-supervisé complexe, ou si la même émergence peut être obtenue dans des conditions plus générales en concevant de manière appropriée l'architecture du modèle

Lien du code : https://github .com/Ma-Lab -Berkeley/CRATE
Veuillez cliquer sur le lien suivant pour consulter l'article : https://arxiv.org/abs/2308.16271
Après des expériences approfondies, les chercheurs ont démontré CRATE en utilisant le modèle Transformer en boîte blanche. sa conception modélise et poursuit explicitement la structure de faible dimension dans la distribution des données, les propriétés de segmentation au niveau entier et partiel émergent avec des formulations d'entraînement peu supervisées
Grâce à une analyse hiérarchique à grain fin, nous tirons une conclusion importante : les propriétés émergentes confirment fortement les capacités mathématiques de conception des réseaux en boîte blanche. Sur la base de ce résultat, nous avons proposé une méthode pour concevoir un modèle de base en boîte blanche, non seulement performant, mais également totalement interprétable mathématiquement.
Le professeur Ma Yi a également déclaré que la recherche sur l'apprentissage profond évoluera progressivement de La conception empirique se tourne vers des conseils théoriques.

Les propriétés émergentes de CRATE en boîte blanche
La capacité émergente de segmentation de DINO fait référence à la capacité du modèle DINO à segmenter les phrases d'entrée en fragments plus petits lors du traitement des tâches linguistiques et à effectuer une analyse sur chaque fragment. Traitement indépendant . Cette capacité permet au modèle DINO de mieux comprendre les structures de phrases complexes et les informations sémantiques, améliorant ainsi ses performances dans le domaine du traitement du langage naturel.
L'apprentissage des représentations dans les systèmes intelligents vise à intégrer la nature multimodale et de grande dimension des le monde Transformez les données sensorielles (images, langage, parole) sous une forme plus compacte tout en conservant leur structure de base de faible dimension, permettant une reconnaissance (telle que la classification), un regroupement (telle que la segmentation) et un suivi efficaces.
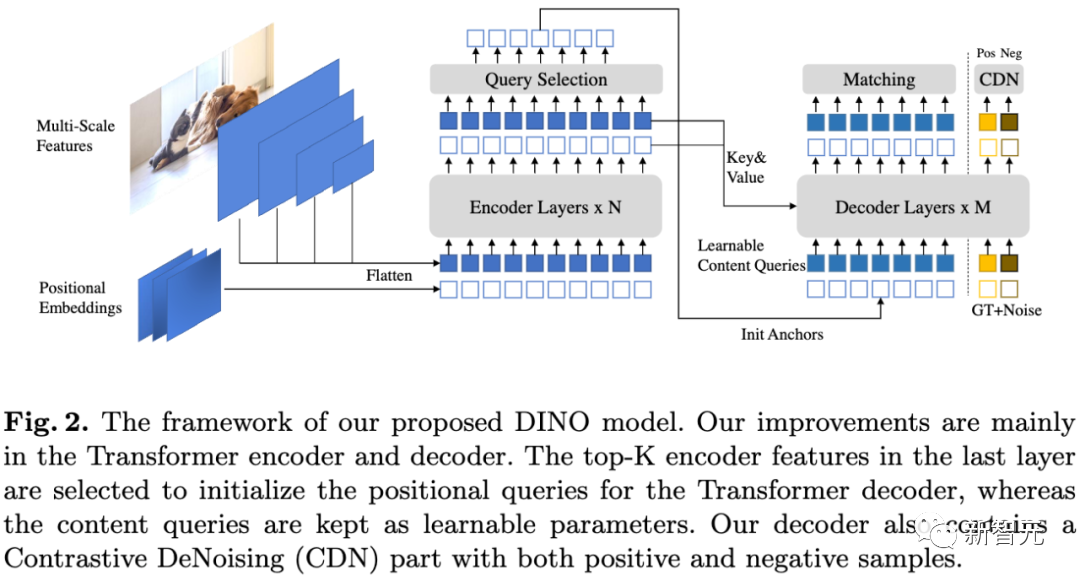
La formation des modèles d'apprentissage profond adopte généralement une approche basée sur les données, en saisissant des données à grande échelle et en apprenant de manière auto-supervisée
Parmi les modèles visuels de base, le modèle DINO montre des résultats surprenants Capacité émergente, les ViT peuvent reconnaître des informations de segmentation sémantique explicites même sans formation supervisée à la segmentation. Le modèle DINO de l'architecture Transformer auto-supervisée a bien fonctionné à cet égard
Les travaux suivants ont étudié comment utiliser ces informations de segmentation dans le modèle DINO et atteint des performances de pointe dans les tâches en aval telles que la segmentation. et la détection. Il existe également des travaux qui prouvent que les caractéristiques de l'avant-dernière couche des ViT formés avec DINO sont fortement liées aux informations de saillance dans l'entrée visuelle, telles que la distinction des limites du premier plan, de l'arrière-plan et des objets, améliorant ainsi les performances de segmentation d'image et autres. tâches.
Afin de mettre en évidence les attributs de segmentation, DINO doit combiner habilement les méthodes d'apprentissage auto-supervisé, de distillation des connaissances et de moyenne de poids pendant le processus de formation
Il n'est pas clair si chaque composant introduit dans DINO est utile pour la segmentation. Bien que DINO utilise également l’architecture ViT comme épine dorsale, le comportement d’émergence de segmentation n’a pas été observé dans les modèles ViT supervisés ordinaires entraînés sur des tâches de classification.
Émergence de CRATE
Sur la base du succès de DINO, les chercheurs ont voulu explorer si des pipelines d'apprentissage auto-supervisés complexes sont nécessaires pour obtenir des propriétés émergentes dans des modèles visuels de type Transformer.
Les chercheurs pensent qu'un moyen prometteur de promouvoir les propriétés de segmentation dans les modèles Transformer consiste à concevoir l'architecture du modèle Transformer en tenant compte de la structure des données d'entrée, qui représente également la profondeur des méthodes classiques d'apprentissage de la représentation avec l'intégration moderne de l'apprentissage basée sur les données. cadres.

Par rapport au modèle actuel de Transformer, cette méthode de conception peut également être appelée modèle de Transformer en boîte blanche.
Sur la base des travaux antérieurs du groupe du professeur Ma Yi, les chercheurs ont mené des expériences approfondies sur le modèle CRATE d'architecture boîte blanche, prouvant que la conception en boîte blanche de CRATE est à l'origine de l'émergence d'attributs de segmentation dans les graphiques d'auto-attention.
Ce qui doit être reformulé est : Évaluation qualitative
Les chercheurs ont utilisé la méthode de carte d'attention basée sur les jetons [CLS] pour expliquer et visualiser le modèle et ont découvert que la matrice requête-clé-valeur dans CRATE c'est pareil
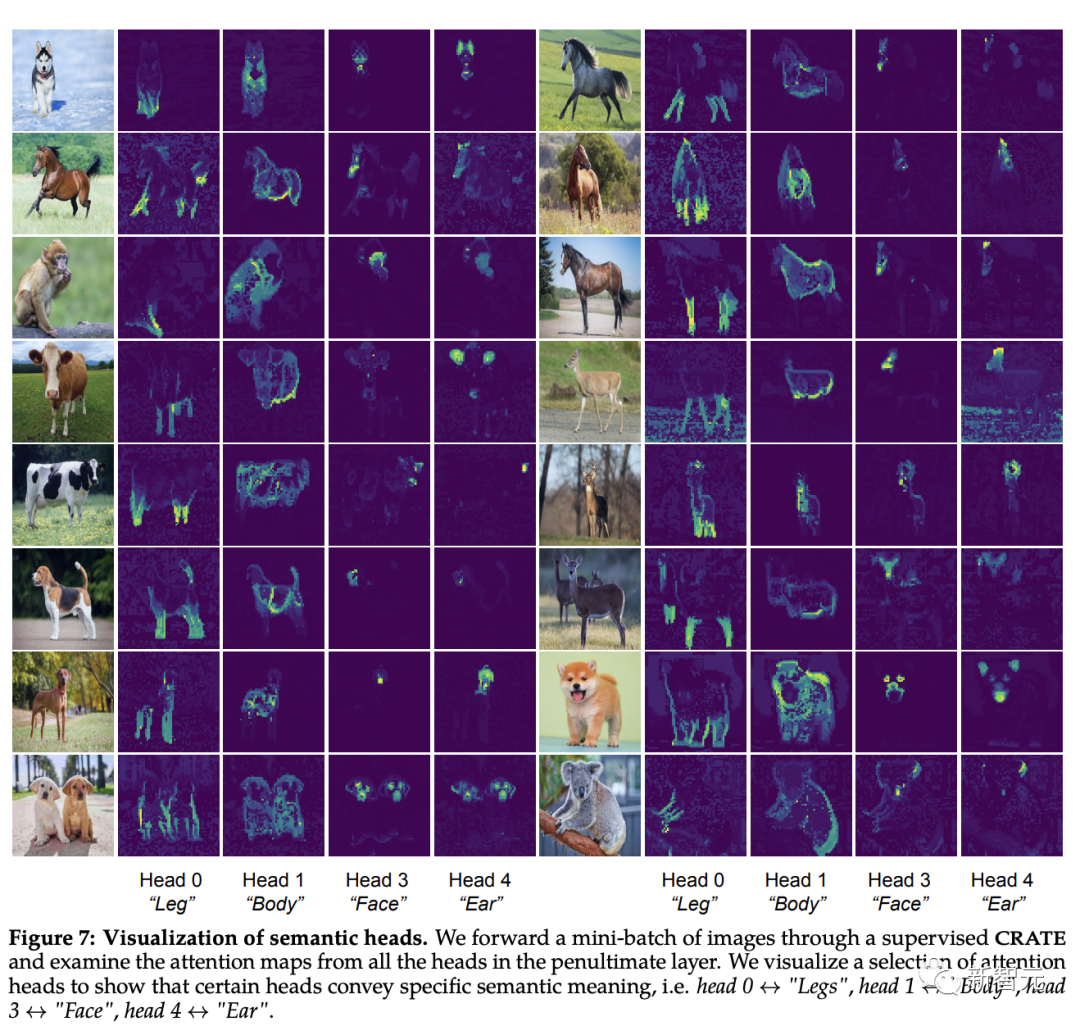
On peut observer que la carte d'auto-attention du modèle CRATE peut correspondre à la sémantique de l'image d'entrée. Le réseau interne du modèle effectue une segmentation sémantique claire sur chaque image. A obtenu un effet similaire au modèle DINO.
Le ViT ordinaire ne présente pas de propriétés de segmentation similaires lorsqu'il est formé sur des tâches de classification supervisées

Sur la base de recherches antérieures sur l'apprentissage d'images visuelles de fonctionnalités profondes par blocs, les chercheurs ont comparé CRATE et ViT. le modèle a été étudié à l'aide de l'analyse en composantes principales (ACP). On peut constater que CRATE peut toujours capturer les limites des objets dans les images sans formation supervisée par segmentation.
 De plus, les composants principaux indiquent également l'alignement des caractéristiques de pièces similaires entre les jetons et les objets, comme le canal rouge correspondant aux jambes du cheval
De plus, les composants principaux indiquent également l'alignement des caractéristiques de pièces similaires entre les jetons et les objets, comme le canal rouge correspondant aux jambes du cheval
, tandis que la visualisation PCA du modèle ViT supervisé est assez mal structurée .
Évaluation quantitative
Les chercheurs ont utilisé des techniques de segmentation et de détection d'objets existantes pour évaluer les propriétés de segmentation émergentes de CRATEComme le montre le graphique d'auto-attention, CRATE utilise des limites claires pour capturer explicitement les objets. sémantique au niveau. Afin de mesurer quantitativement la qualité de la segmentation, les chercheurs utilisent des cartes d'auto-attention pour générer des masques de segmentation et les comparent au mIoU (rapport moyen d'intersection sur union) entre eux et les masques réels.
Les résultats expérimentaux montrent que CRATE surpasse considérablement ViT en termes de scores visuels et mIOU, ce qui montre que la représentation interne de CRATE est plus efficace pour la tâche de génération de masques de segmentation
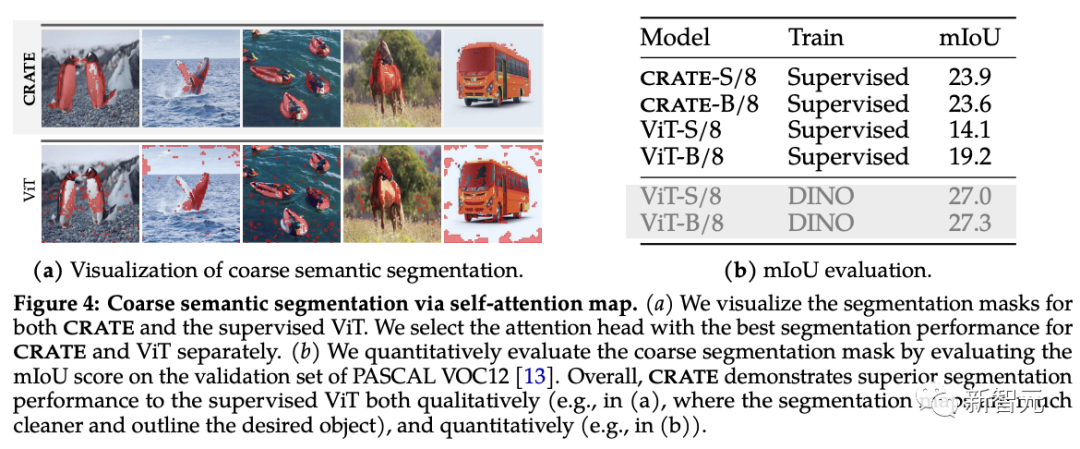
Afin de vérifier et d'évaluer davantage les riches informations sémantiques capturées par CRATE, les chercheurs ont adopté MaskCut, une méthode efficace de détection et de segmentation d'objets, pour obtenir un modèle d'évaluation automatisé sans annotation manuelle, qui peut être basé sur les jetons appris par les représentations CRATE pour extraire des segmentations plus fines à partir d'images.
Comme on peut le voir dans les résultats de segmentation sur COCO val2017, la représentation interne avec CRATE est meilleure que la ViT supervisée dans les indicateurs de détection et de segmentation MaskCut avec des fonctionnalités ViT supervisées est meilleure dans certains cas. est même impossible de générer un masque divisé. 
Analyse en boîte blanche des capacités de segmentation de CRATE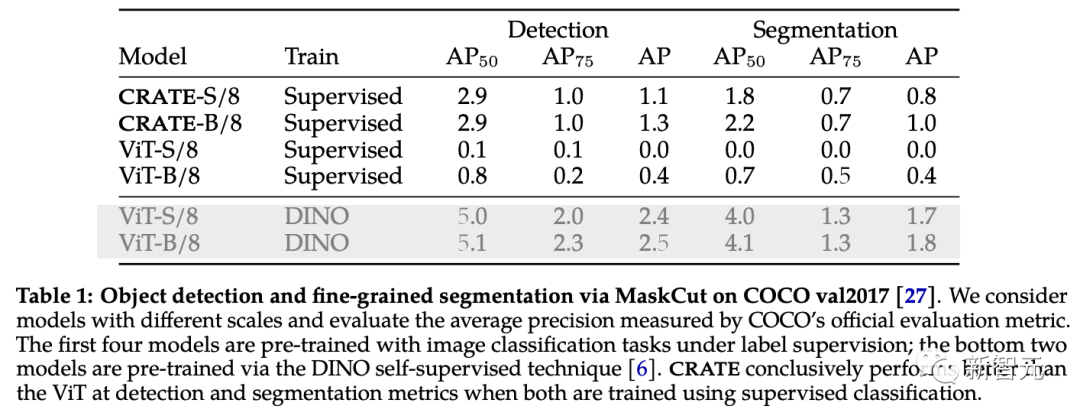
Le rôle de la profondeur dans CRATE
La conception de chaque couche de CRATE suit le même objectif conceptuel : optimiser la réduction du taux clairsemé et convertir le distribution de jetons sous une forme compacte et structurée. Après réécriture : La conception de chaque niveau de CRATE suit le même concept : optimiser la réduction du taux clairsemé et transformer la distribution des tokens en une forme compacte et structurée En supposant que l'émergence des capacités de segmentation sémantique dans CRATE est similaire à "Représentant des groupes de jetons appartenant à des catégories sémantiques similaires dans Z", on s'attend à ce que les performances de segmentation de CRATE puissent s'améliorer à mesure que la profondeur augmente.
Pour tester cela, les chercheurs ont utilisé le pipeline MaskCut pour évaluer quantitativement les performances de segmentation dans les représentations internes sur différentes couches ; tout en appliquant la visualisation PCA pour comprendre comment les segmentations émergent avec la profondeur.
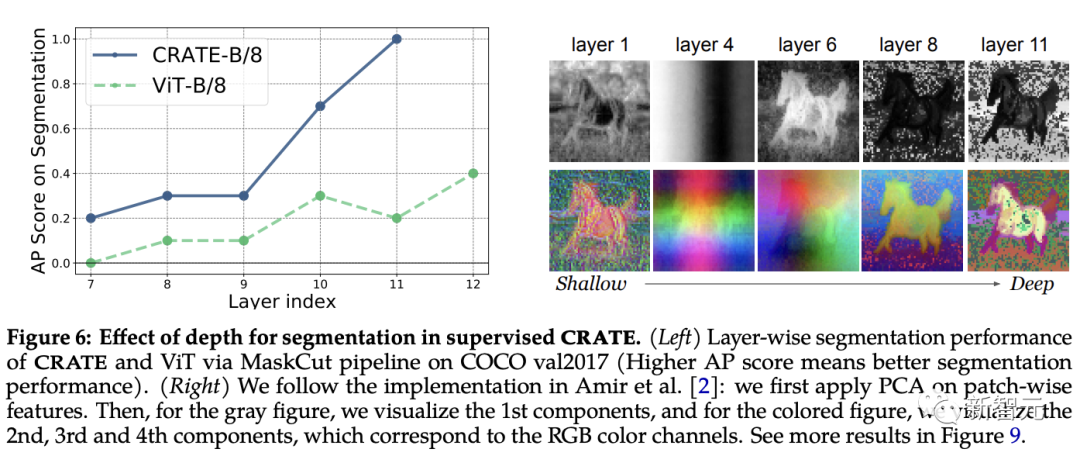
Les résultats expérimentaux montrent que le score de segmentation s'améliore lors de l'utilisation de représentations provenant de couches plus profondes, ce qui est très cohérent avec la conception d'optimisation incrémentielle de CRATE.
En revanche, même si les performances de ViT-B/8 s'améliorent légèrement dans les couches ultérieures, son score de segmentation est nettement inférieur à celui de CRATE, et les résultats PCA montrent que les représentations extraites des couches profondes de CRATE accordent progressivement plus d'attention au premier plan. objets et est capable de capturer des détails au niveau de la texture.
Expérience de fusion de CRATE
Le bloc d'attention (MSSA) et le bloc MLP (ISTA) dans CRATE sont différents du bloc d'attention dans ViT
Afin d'étudier chaque composant pour l'impact Parmi les propriétés de segmentation émergentes de CRATE, les chercheurs ont sélectionné trois variantes de CRATE : CRATE, CRATE-MHSA et CRATE-MLP. Ces variantes représentent respectivement le bloc d'attention (MHSA) et le bloc MLP dans ViT
Les chercheurs ont appliqué les mêmes paramètres de pré-entraînement sur l'ensemble de données ImageNet-21k, puis ont appliqué une évaluation de segmentation grossière et une évaluation de segmentation de masque pour comparer quantitativement les performances. de différents modèles.
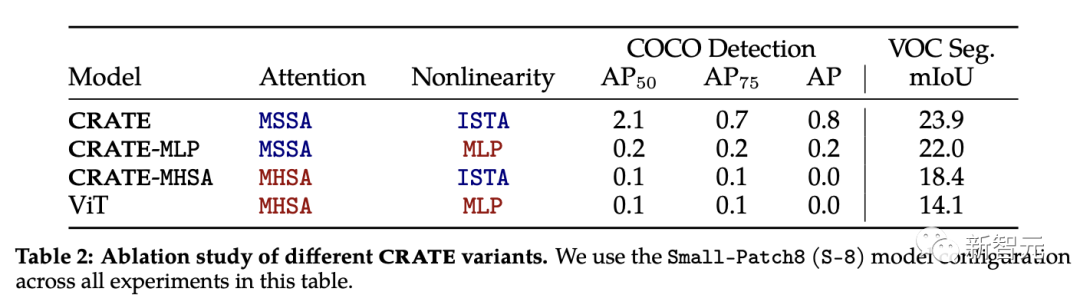
Selon les résultats expérimentaux, CRATE surpasse considérablement les autres architectures de modèles dans toutes les tâches. Il convient de noter que bien que la différence architecturale entre MHSA et MSSA soit faible, le simple remplacement de MHSA dans ViT par MSSA dans CRATE peut améliorer considérablement les performances de ViT en segmentation grossière (c'est-à-dire les performances de VOC Seg). Cela prouve encore une fois l'efficacité de la conception de la boîte blanche
Le contenu qui doit être réécrit est : l'identification des attributs sémantiques de l'en-tête d'attention
[CLS] La carte d'auto-attention entre le le jeton et le jeton du bloc image sont visibles. Dans un masque de segmentation clair, selon l'intuition, chaque tête d'attention devrait être capable de capter une partie des caractéristiques des données.
Les chercheurs ont d'abord saisi des images dans le modèle CRATE, puis ont demandé à des humains d'inspecter et de sélectionner quatre têtes d'attention qui semblaient avoir une signification sémantique ; ils ont ensuite effectué une visualisation de la carte d'auto-attention sur ces têtes d'attention sur d'autres images d'entrée.
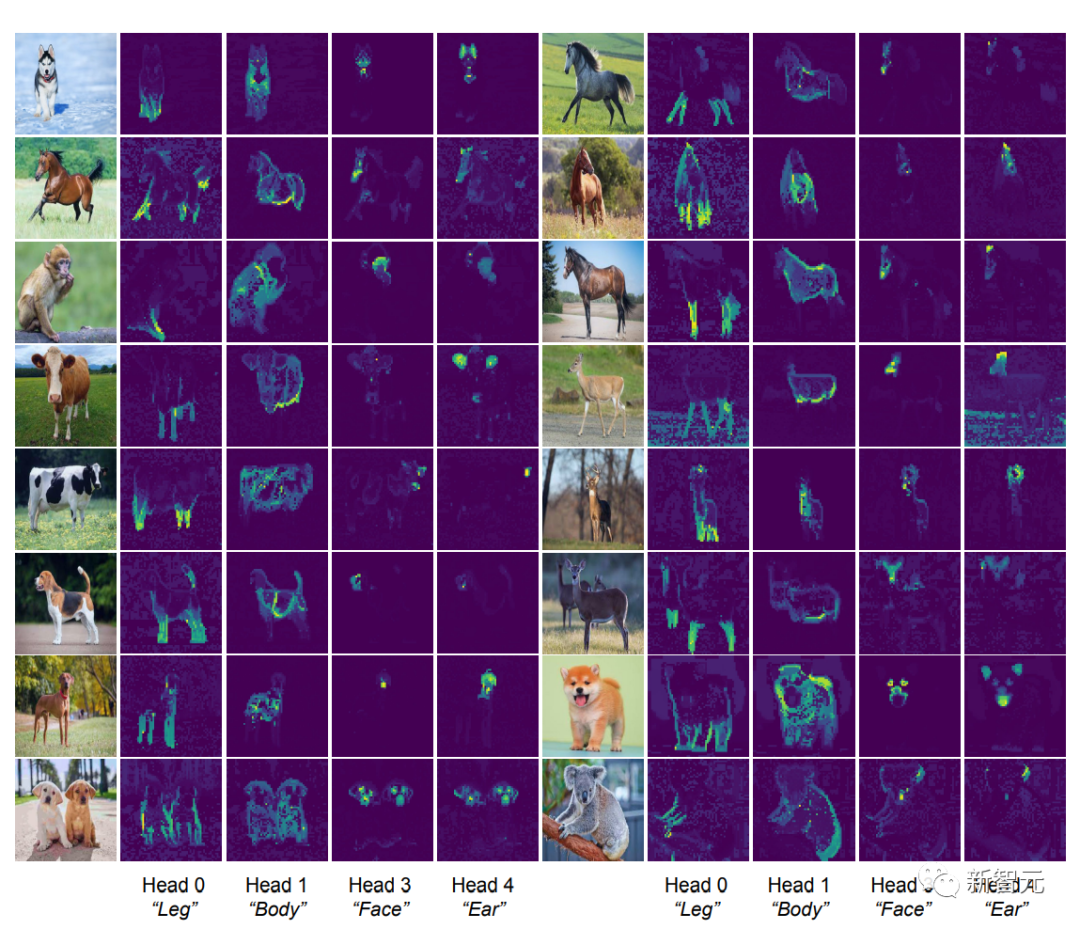
On peut constater que chaque tête d'attention peut capturer différentes parties de l'objet, et même différentes sémantiques. Par exemple, la tête d'attention de la première colonne peut capturer les pattes de différents animaux, tandis que la tête d'attention de la dernière colonne peut capturer les oreilles et la tête
Depuis le modèle de pièce déformable (modèle de pièce déformable) et cette capacité à analyser l'entrée visuelle dans des hiérarchies partie-tout est un objectif des architectures de reconnaissance depuis la sortie des réseaux de capsules, et le modèle CRATE conçu en boîte blanche a également cette capacité.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Qu'est-ce que le modèle de données relationnelles
- Comment supprimer des modèles redondants dans ZBrush
- Combien de types de modèles de boîtes CSS existe-t-il ?
- Dernières avancées dans les modèles clairsemés ! Ma Yi + LeCun unissent leurs forces : apprentissage non supervisé « boîte blanche »
- Pourquoi l'autosurveillance est-elle efficace ? La thèse de doctorat de Princeton de 243 pages « Comprendre l'apprentissage par représentation auto-supervisé » explique de manière exhaustive les trois types de méthodes : l'apprentissage contrastif, la modélisation du langage et l'auto-prédiction.