
Maison >Périphériques technologiques >IA >Que la puissance de calcul ne devienne plus un goulot d'étranglement, méthode d'optimisation d'inférence matérielle hétérogène d'apprentissage automatique de Xiaohongshu
Que la puissance de calcul ne devienne plus un goulot d'étranglement, méthode d'optimisation d'inférence matérielle hétérogène d'apprentissage automatique de Xiaohongshu

- PHPzavant
- 2023-09-08 12:33:061547parcourir

De nombreuses entreprises combinent le développement de la puissance de calcul des GPU pour explorer des solutions aux problèmes d'apprentissage automatique qui leur conviennent. Par exemple, Xiaohongshu commencera la transformation basée sur GPU du modèle de recherche de promotion en 2021 pour améliorer les performances et l'efficacité de l'inférence. Au cours du processus de migration, nous avons également été confrontés à certaines difficultés, telles que la manière de migrer en douceur vers du matériel hétérogène, la manière de développer nos propres solutions basées sur les scénarios commerciaux et l'architecture en ligne de Xiaohongshu, etc. Dans le cadre de la tendance mondiale à la réduction des coûts et à l'amélioration de l'efficacité, l'informatique hétérogène est devenue une direction prometteuse, qui peut améliorer les performances informatiques en combinant différents types de processeurs (tels que CPU, GPU, FPGA, etc.) pour obtenir une meilleure efficacité et réduire les coûts.
1.Contexte
Les services modèles de recommandation, de publicité, de recherche et d'autres scénarios principaux de Xiaohongshu sont uniformément portés par l'architecture d'inférence intermédiaire. Avec le développement continu des activités de Xiaohongshu, l'échelle des modèles pour des scénarios tels que la recherche promotionnelle augmente également. En prenant comme exemple le modèle principal de scénarios de recommandation raffinés, depuis le début de 2020, l'algorithme a lancé une modélisation d'intérêt complet et la durée moyenne des enregistrements de comportement historique des utilisateurs a été multipliée par environ 100. La structure du modèle a également subi plusieurs séries d'itérations depuis la multi-tâche initiale, et la complexité de la structure du modèle a également continué d'augmenter. Ces changements ont entraîné une multiplication par 30 du nombre d'opérations en virgule flottante. l'inférence de modèle et une multiplication par 5 environ de l'accès à la mémoire du modèle.
 Photos
Photos
2. Aperçu de l'architecture du service de modèle
Caractéristiques du modèle :Prenons comme exemple le modèle principal recommandé de Xiaohongshu fin 2022. Ce modèle a une parcimonie suffisante. Une partie de la structure est composée de caractéristiques de valeur continue et d'opérations matricielles, et il existe également des paramètres clairsemés à grande échelle tels que Les caractéristiques clairsemées d'un seul modèle peuvent atteindre 1 To, cependant, grâce à une optimisation relativement efficace de la structure du modèle. , la partie dense est contrôlée dans la limite de 10 Go et peut être placée dans la mémoire vidéo. Chaque fois que l'utilisateur glisse Xiaohongshu, le total des FLOP calculés atteint 40B et le délai d'attente est contrôlé dans les 300 ms (hors traitement des fonctionnalités, avec recherche).
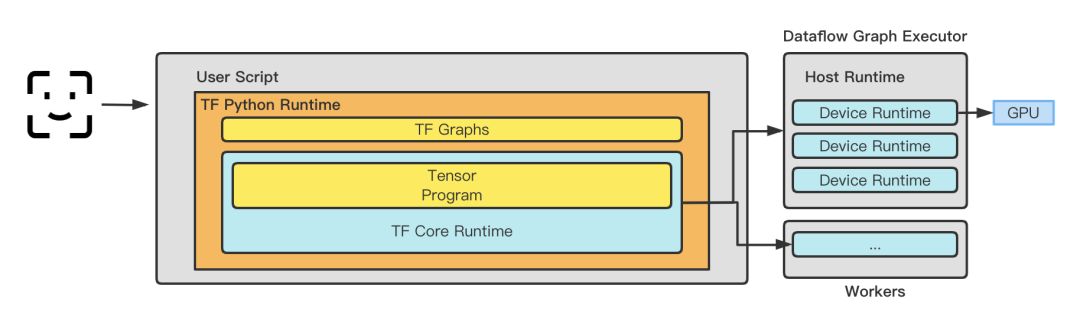
Cadre d'inférence : Avant 2020, Xiaohongshu a adopté le cadre TensorFlow Serving comme cadre de service en ligne. Après 2020, il a été progressivement intégré au service Lambda auto-développé basé sur TensorFlowCore. TensorFlow Serving effectue une copie mémoire de TensorProto -> CTensor avant d'entrer dans le graphique pour garantir l'exactitude et la fiabilité de l'inférence du modèle. Cependant, à mesure que l’entreprise s’étend, les opérations de copie de mémoire auront un impact sur les performances du modèle. Le framework développé par Xiaohongshu élimine les copies inutiles grâce à l'optimisation, tout en conservant les fonctionnalités enfichables d'exécution, les capacités de planification de graphiques et les capacités d'optimisation, et jette les bases de l'utilisation ultérieure de différents frameworks d'optimisation tels que TRT, BLADE et TVM. Il semble désormais que choisir l'auto-recherche au bon moment soit un choix judicieux. Dans le même temps, afin de minimiser le coût de la transmission des données, le cadre d'inférence entreprend également une partie de la mise en œuvre de l'extraction et de la transformation des caractéristiques. l'estimation ici. Le stockage périphérique auto-développé est déployé du côté proche du service, ce qui résout le problème de coût lié à l'extraction des données de l'extrémité distante.
Caractéristiques du modèle : Xiaohongshu ne construit pas sa propre salle informatique. Toutes les machines sont achetées auprès de fournisseurs de cloud. Par conséquent, la décision de choisir différents modèles dépend en grande partie du type de machines qui peuvent être achetées. Le calcul de l'inférence de modèle n'est pas un pur calcul GPU. Pour trouver un ratio matériel raisonnable, en plus de prendre en compte le GPUCPU, cela implique également des problèmes tels que la bande passante, la bande passante mémoire et le délai de communication entre nombres.
 Photos
Photos
Fonctionnalités GPU
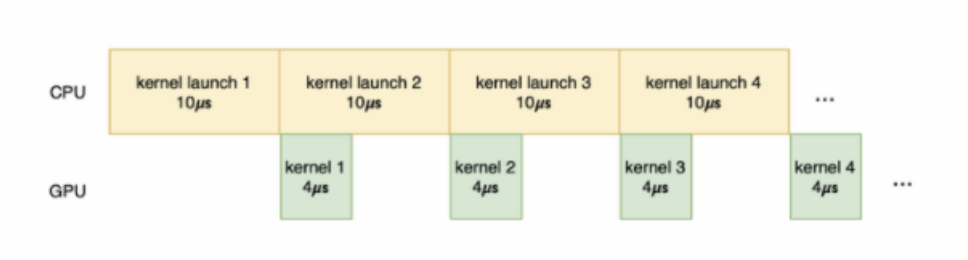
Fonctionnalités GPU :Ici, les problèmes rencontrés par Xiaohongshu et d'autres sociétés sont les mêmes. L'exécution du noyau GPU peut être divisée en les étapes suivantes : Transmission de données, noyau. démarrage, calcul du noyau et transmission des résultats. Parmi eux, la transmission de données consiste à transférer les données de la mémoire hôte vers la mémoire du noyau GPU ; le démarrage du noyau consiste à transférer le code du noyau du côté hôte vers le côté GPU, et le démarrage du noyau sur le GPU consiste à exécuter réellement le code ; les résultats du calcul du code du noyau ; la transmission des résultats s'effectue vers Les résultats du calcul sont transférés de la mémoire GPU vers la mémoire hôte. Si une grande quantité de temps est consacrée à la transmission des données et au démarrage du noyau, et que le travail fourni au noyau pour le calcul n'est pas lourd et que le temps de calcul réel est très court, l'utilisation du GPU ne sera pas améliorée et même un fonctionnement à vide se produira. .
 Photos
Photos
Cadre de service estimé
3.Pratique d'optimisation du GPU
3.1 Optimisation du système
3.1.1 Machine physique
En termes d'optimisation de la machine physique, certaines idées d'optimisation conventionnelles peuvent être adoptées. L'objectif principal est de réduire le coût des autres systèmes. frais généraux autres que le GPU, réduisant les intermédiaires de virtualisation pour réaliser des bénéfices. De manière générale, un ensemble d'optimisations du système peut améliorer les performances de 1 à 2 %. D'après notre pratique, l'optimisation doit être combinée avec les capacités réelles des fournisseurs de cloud.
Quantity Isolation des interruptions : isolez les interruptions du GPU pour éviter les interruptions d'autres appareils affectant les performances de calcul du GPU.
Quantity Mise à niveau de la version du noyau : améliorez la stabilité et la sécurité du système, améliorez la compatibilité et les performances des pilotes GPU.
Quantity Transmission transparente des instructions : transmettez de manière transparente les instructions du GPU directement à l'appareil physique pour accélérer la vitesse de calcul du GPU.
3.1.2 Virtualisation et conteneurs
Dans les situations multi-cartes, liez un seul pod à un nœud NUMA spécifique, augmentant ainsi la vitesse de transfert de données entre le CPU et le GPU.
Quantity CPU NUMA Affinity, l'affinité fait référence aux accès à la mémoire qui sont plus rapides et ont une latence plus faible du point de vue du CPU. Comme mentionné précédemment, la mémoire locale connectée directement au CPU est plus rapide. Par conséquent, le système d'exploitation peut allouer de la mémoire locale en fonction du processeur où se trouve la tâche pour améliorer la vitesse d'accès et les performances. Ceci est basé sur les considérations d'affinité NUMA du processeur et essayer d'exécuter la tâche dans le nœud NUMA local. Dans le scénario Xiaohongshu, la surcharge d’accès à la mémoire sur le processeur n’est pas minime. Permettre au processeur de se connecter directement à la mémoire locale peut permettre d'économiser beaucoup de temps consacré à l'exécution du noyau sur le processeur, laissant suffisamment d'espace pour le GPU.
Quantity En contrôlant l'utilisation du CPU à 70%, le délai peut être réduit de 200 ms -> 150 ms.
3.1.3 Miroir
Optimisation de la compilation. Différents processeurs ont des capacités de prise en charge différentes pour les niveaux d'instruction, et les modèles achetés par différents fournisseurs de cloud sont également différents. Une idée relativement simple consiste à compiler l’image avec différents jeux d’instructions dans différents scénarios matériels. Lors de la mise en œuvre des opérateurs, un grand nombre d'opérateurs disposent déjà d'instructions telles que AVX512. En prenant comme exemple le modèle Intel(R) Xeon(R) Platinum 8163 + 2 A10 d'Alibaba Cloud, nous compilons, optimisons et ajustons le jeu d'instructions approprié en fonction des caractéristiques du modèle et du jeu d'instructions pris en charge dans l'ensemble, par rapport aux performances non performantes. Avec l'optimisation des instructions, le débit du processeur sur ce modèle est augmenté de 10 %.
# Intel(R) Xeon(R) Platinum 8163 for ali intelbuild:intel --copt=-march=skylake-avx512 --copt=-mmmx --copt=-mno-3dnow --copt=-mssebuild:intel --copt=-msse2 --copt=-msse3 --copt=-mssse3 --copt=-mno-sse4a --copt=-mcx16build:intel --copt=-msahf --copt=-mmovbe --copt=-maes --copt=-mno-sha --copt=-mpclmulbuild:intel --copt=-mpopcnt --copt=-mabm --copt=-mno-lwp --copt=-mfma --copt=-mno-fma4build:intel --copt=-mno-xop --copt=-mbmi --copt=-mno-sgx --copt=-mbmi2 --copt=-mno-pconfigbuild:intel --copt=-mno-wbnoinvd --copt=-mno-tbm --copt=-mavx --copt=-mavx2 --copt=-msse4.2build:intel --copt=-msse4.1 --copt=-mlzcnt --copt=-mrtm --copt=-mhle --copt=-mrdrnd --copt=-mf16cbuild:intel --copt=-mfsgsbase --copt=-mrdseed --copt=-mprfchw --copt=-madx --copt=-mfxsrbuild:intel --copt=-mxsave --copt=-mxsaveopt --copt=-mavx512f --copt=-mno-avx512erbuild:intel --copt=-mavx512cd --copt=-mno-avx512pf --copt=-mno-prefetchwt1build:intel --copt=-mno-clflushopt --copt=-mxsavec --copt=-mxsavesbuild:intel --copt=-mavx512dq --copt=-mavx512bw --copt=-mavx512vl --copt=-mno-avx512ifmabuild:intel --copt=-mno-avx512vbmi --copt=-mno-avx5124fmaps --copt=-mno-avx5124vnniwbuild:intel --copt=-mno-clwb --copt=-mno-mwaitx --copt=-mno-clzero --copt=-mno-pkubuild:intel --copt=-mno-rdpid --copt=-mno-gfni --copt=-mno-shstk --copt=-mno-avx512vbmi2build:intel --copt=-mavx512vnni --copt=-mno-vaes --copt=-mno-vpclmulqdq --copt=-mno-avx512bitalgbuild:intel --copt=-mno-movdiri --copt=-mno-movdir64b --copt=-mtune=skylake-avx512
3.2 Optimisation informatique
3.2.1 Exploitez pleinement la puissance de calcul
weight Optimisation informatique, vous devez d'abord bien comprendre les performances du matériel et les comprendre en profondeur. Dans le scénario Xiaohongshu, comme le montre la figure ci-dessous, nous avons rencontré deux problèmes principaux :
1. Il existe de nombreux accès à la mémoire sur le processeur et la fréquence des défauts de page mémoire est élevée, ce qui entraîne un gaspillage des ressources du processeur et un niveau élevé. latence des requêtes.
2. Dans les services d'inférence en ligne, les calculs ont généralement deux caractéristiques : la taille du lot d'une seule requête est petite et l'échelle de concurrence d'un seul service est grande. Une petite taille de lot empêchera le noyau d'utiliser pleinement la puissance de calcul du GPU. Le temps d'exécution du noyau GPU est généralement plus court, ce qui ne peut pas couvrir entièrement la surcharge de lancement du noyau, et même le temps de lancement du noyau est plus long que le temps d'exécution du noyau. Dans TensorFlow, un seul noyau de lancement de Cuda Stream devient un goulot d'étranglement, entraînant une utilisation du GPU seulement à 50 % dans les scénarios d'inférence. De plus, pour les scénarios de petits modèles (réseaux denses simples), il n’est pas rentable de remplacer le CPU par le GPU, ce qui limite la complexité du modèle.
 Photos
Photos
Quantity: Pour résoudre les deux problèmes ci-dessus, nous avons pris les mesures suivantes :
1. Pour résoudre le problème de la fréquence élevée des défauts de page mémoire, nous utilisons la bibliothèque jemalloc pour optimiser le recyclage de la mémoire. et activez-le la fonction de pages géantes transparentes du système d'exploitation. De plus, pour les caractéristiques spéciales d'accès à la mémoire de lambda, nous concevons des structures de données spéciales et optimisons les stratégies d'allocation de mémoire pour éviter autant que possible la fragmentation de la mémoire. Dans le même temps, nous avons directement contourné l'interface tf_serving et appelé directement TensorFlow, réduisant ainsi la sérialisation et la désérialisation des données. Ces optimisations ont amélioré le débit de plus de 10 % dans les scénarios de réglage fin de la page d'accueil et du flux, et réduit la latence de 50 % dans la plupart des scénarios publicitaires.
 Images
Images
sont compatibles avec le format tensorflow :: Tensor et sont copiées à zéro avant de transmettre les fonctionnalités à tensorflow :: SessionRun
2. En réponse au problème du flux Cuda unique de TensorFlow, nous prenons en charge les fonctions Multi Streams et Multi Contexts, évitant ainsi les goulots d'étranglement des performances causés par les verrouillages mutex et augmentant avec succès l'utilisation du GPU à plus de 90 %. Dans le même temps, nous utilisons la fonction Cuda MPS fournie par Nvidia pour réaliser le multiplexage par répartition spatiale du GPU (prenant en charge plusieurs exécutions de noyau en même temps), améliorant encore l'utilisation du GPU. Sur cette base, le modèle de classement de Search a été implémenté avec succès sur GPU. Nous l’avons également mis en œuvre avec succès dans d’autres secteurs d’activité, notamment la mise en page de la page d’accueil, la publicité, etc. Le tableau suivant est une situation d'optimisation dans le scénario de classement de recherche.
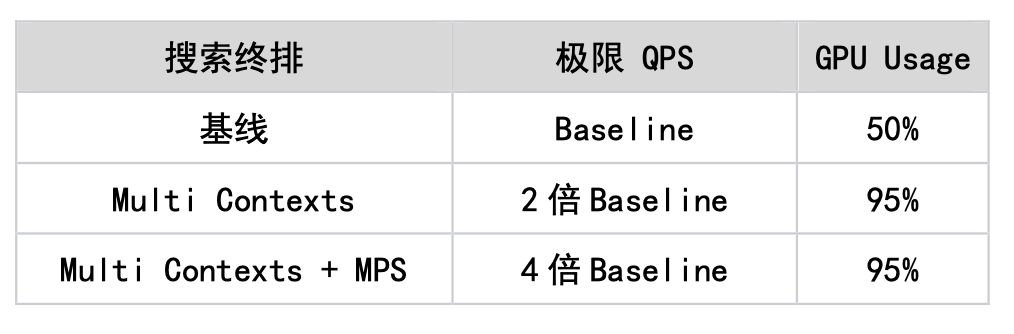 Images
Images
3. Technologie de fusion Op/Kernel : générez des opérateurs Tensorflow plus performants grâce à des outils d'écriture manuscrite ou de compilation et d'optimisation de graphiques, en utilisant pleinement le cache du CPU et la mémoire partagée du GPU pour améliorer le débit du système.
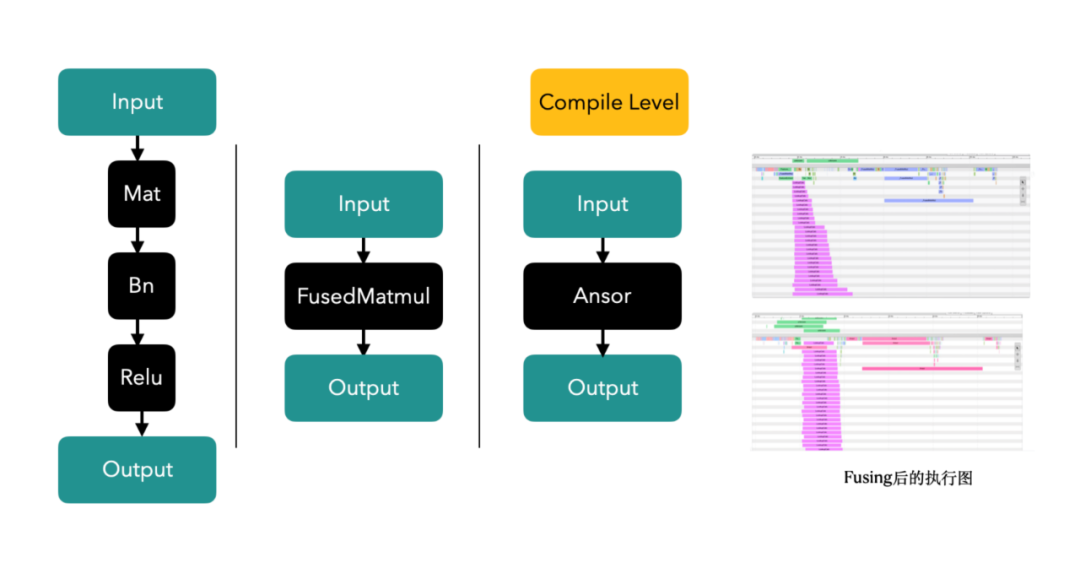 Photos
Photos
Dans le scénario d'afflux, les opérateurs sont fusionnés et vous pouvez voir qu'un seul appel dure 12 ms -> 5 ms
3.2.2 Éviter le gaspillage de puissance de calcul
1. Lien système Il y a de la place pour l'optimisation
a Calcul préliminaire : lors du traitement des calculs côté utilisateur, le tri préliminaire doit calculer un grand nombre de billets. Par exemple, en prenant comme exemple les sorties, environ 5 000 billets doivent être calculés. et lambda a un traitement de découpage pour eux. Afin d'éviter les calculs répétés, les calculs côté utilisateur de la ligne initiale sont déplacés parallèlement à la phase de rappel, de sorte que le calcul du vecteur utilisateur soit réduit de plusieurs répétitions à une seule fois, 40 % des machines sont optimisées dans le scénario de rangée approximative.
2. Formation intégrée au processus d'inférence :
a Prétraitement du calcul : une partie du calcul peut être traitée à l'avance par gel du graphique. Lors du raisonnement, il n’est pas nécessaire de répéter les calculs.
b. Optimisation du gel du modèle de sortie : lorsque le modèle est généré, tous les paramètres sont générés avec le graphique lui-même pour générer un graphique gelé (graphique gelé) et effectuer des calculs de prétraitement. De nombreux opérateurs de variable précalculés peuvent être convertis en opérateurs Const (GPU). utilisation diminuée de 12%)
c. Calculs fusionnés dans les scénarios d'inférence : Chaque lot ne contient qu'un seul utilisateur, c'est-à-dire qu'il y a un grand nombre de calculs répétés côté utilisateur, avec possibilité de fusion
d. Division de l'opérateur GPU : déplacez tous les opérateurs après la recherche vers le GPU, en évitant la copie de données entre le CPU et le GPU
e Copie de données GPU vers CPU : emballez les données et copiez-les une fois
f Calcul BilinearNet Implémentation cuda du sous-GPU : Accélérez les calculs via GPU pour améliorer les performances
g. Opérateurs partiels basés sur GPU : omettez CPU -> Copie GPU
h : En implémentant une nouvelle couche MLP, selon un objectif, réduisez le. nombre de fois entrant dans le GPU (N -> 1), augmentez la quantité de calcul pour un calcul (réutilisez la capacité de concurrence du petit cœur du GPU)
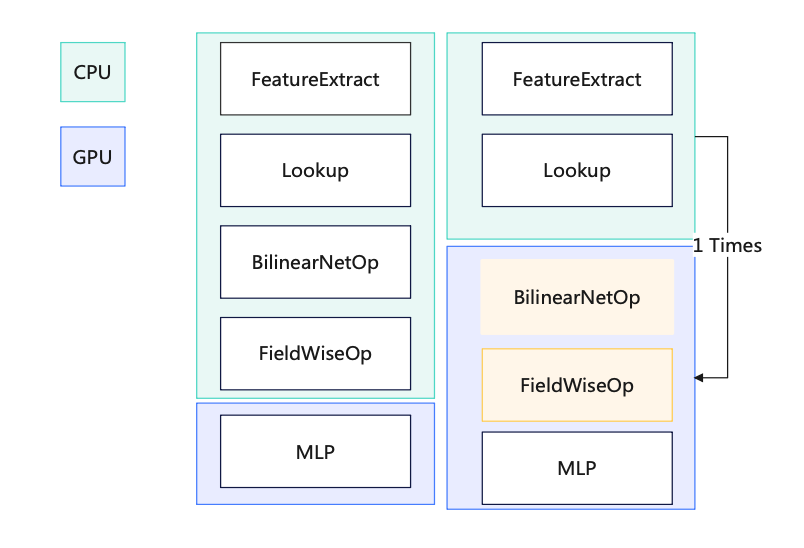 Pictures
Pictures
3.2.3 Puissance de calcul dynamique tout au long de la journée
Quantity La rétrogradation de l'informatique dynamique améliore l'efficacité de l'utilisation des ressources tout au long de la journée et ajuste automatiquement la charge lambda avec un retour négatif au deuxième niveau pour réaliser des tests de résistance à zone unique. Il n'est pas nécessaire de préparer manuellement la rétrogradation avant.
Quantity Des scénarios commerciaux majeurs tels que le classement raffiné sortant, le tri préliminaire sortant, le tri raffiné entrant, le tri préliminaire des entrées internes et la recherche ont tous été lancés.
Quantity Résolu le problème de capacité dans plusieurs secteurs d'activité, atténué efficacement l'augmentation linéaire des ressources provoquée par la croissance de l'entreprise et amélioré considérablement la robustesse du système. Dans les métiers après le lancement de la fonction, il n'y a pas eu d'accidents P3 ou supérieur provoqués par une forte baisse du taux de réussite instantané.
Quantity Améliorez considérablement l'efficacité de l'utilisation des ressources tout au long de la journée. En prenant comme exemple le réglage fin du flux (comme le montre la figure ci-dessous), le nombre de cœurs de processeur utilisés pendant les trois jours de vacances du 1er mai de 10h00 à 20h00. 24h00 maintient une ligne plate de 50 cœurs (le tramage correspond à la version finale)
 Photos
Photos
3.2.4 Changement vers un meilleur matériel
weight Les performances du GPU A10 sont 1,5 fois. celui du GPU T4, et le modèle A10 est équipé d'un CPU ( icelake , 10 nm) est une génération plus récente que le modèle T4 (skylake, 14 nm), et le prix n'est que 1,2 fois celui du modèle T4. Nous envisagerons également d'utiliser des modèles tels que l'A30 en ligne à l'avenir.
3.3 Optimisation des images
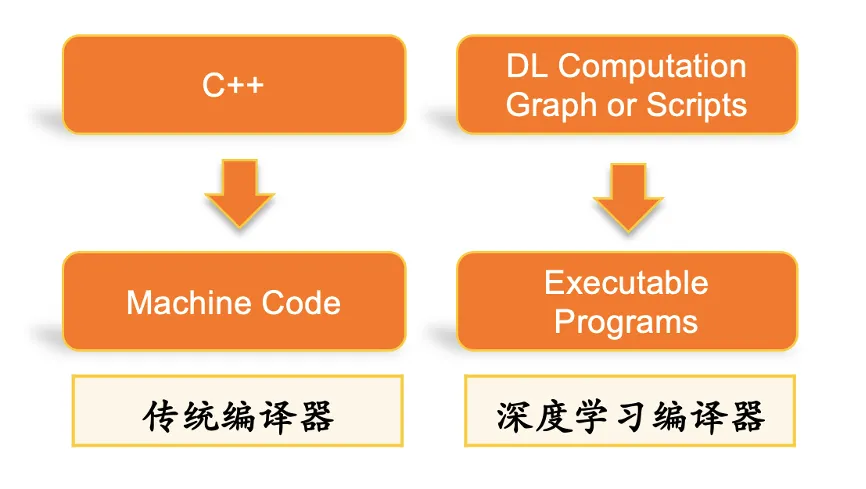 Pictures
Pictures
3.3.1 Optimisation de la compilation automatique de la pile DL
weight BladeDISC est le dernier compilateur d'apprentissage profond de formes dynamiques open source d'Alibaba basé sur MLIR. La partie d'optimisation automatique des graphiques de Xiaohongshu provient de ce framework (la bibliothèque d'accélération d'inférence Blade est open source Apache 2.0, peut être utilisée sur n'importe quel cloud et n'a aucun droit de propriété intellectuelle. risque). Ce cadre fournit une optimisation de la compilation de graphiques TF (y compris Dynamic Shape Compiler, une optimisation de sous-graphes clairsemés) et peut également superposer notre propre optimisation d'opérateur personnalisée, qui peut mieux s'adapter à nos scénarios commerciaux. Dans l'inférence sur une seule machine du test de résistance, le QPS peut être augmenté de 20 %.
Quantity Technologies clés de ce framework
(1) Infrastructure MLIR
MLIR, Multi-Level Intermediate Representation (Multi-Level Intermediate Representation), est un projet open source initié par Google. Son objectif est de fournir une infrastructure IR multi-niveaux flexible et extensible et une bibliothèque d'utilitaires de compilateur, fournissant un cadre unifié pour les développeurs de compilateurs et d'outils linguistiques.
La conception de MLIR est influencée par LLVM, mais contrairement à LLVM, MLIR se concentre principalement sur la conception et l'extension de la représentation intermédiaire (IR). MLIR fournit une conception IR multi-niveaux qui peut prendre en charge le processus de compilation des langages de haut niveau au matériel de bas niveau, et fournit une prise en charge d'infrastructure riche et une architecture de conception modulaire, permettant aux développeurs d'étendre facilement les fonctions de MLIR. De plus, MLIR possède également de fortes capacités de collage et peut être intégré à différents langages et outils de programmation. MLIR est une puissante infrastructure de compilateur et une bibliothèque d'outils qui fournit aux développeurs de compilateurs et d'outils linguistiques un langage de représentation intermédiaire unifié et flexible qui peut faciliter l'optimisation de la compilation et la génération de code.
(2) Compilation de forme dynamique
Les limites de la forme statique signifient que la forme de chaque entrée et sortie doit être déterminée à l'avance lors de l'écriture d'un modèle d'apprentissage en profondeur, et elles ne peuvent pas être modifiées au moment de l'exécution. Cela limite la flexibilité et l'évolutivité des modèles d'apprentissage profond, nécessitant ainsi un compilateur d'apprentissage profond prenant en charge les formes dynamiques.
3.3.2 Ajustement de la précision
Quantity L'un des moyens d'obtenir la quantification est d'utiliser FP16
Optimisation du calcul FP16 : le remplacement des calculs FP32 par FP16 dans la couche MLP peut réduire considérablement l'utilisation du GPU (relativement 13 % de diminution )
Dans le processus d'ajustement du FP16, le choix de la méthode de la boîte blanche pour l'optimisation de précision signifie que nous pouvons contrôler plus finement quelles couches utilisent des calculs de faible précision, et pouvons continuellement ajuster et optimiser en fonction de l'expérience. Cette méthode nécessite une compréhension et une analyse relativement approfondies de la structure du modèle, et des ajustements ciblés peuvent être effectués en fonction des caractéristiques et des exigences de calcul du modèle pour obtenir des performances de coût plus élevées.
En revanche, la méthode de la boîte noire est relativement simple. Elle ne nécessite pas de comprendre la structure interne du modèle, il suffit de définir un certain seuil de tolérance pour compléter l'optimisation de la précision. L'avantage de cette méthode est qu'elle est simple à utiliser et qu'elle a des exigences relativement faibles pour les étudiants modèles, mais elle peut sacrifier certaines performances et précision.
Par conséquent, le choix de la méthode boîte blanche ou boîte noire pour l'optimisation de la précision doit être déterminé en fonction de la situation spécifique. Si vous devez rechercher des performances et une précision plus élevées et disposer d’une expérience et de capacités techniques suffisantes, l’approche boîte blanche peut être plus adaptée. Si la simplicité de fonctionnement et la rapidité des itérations sont plus importantes, alors l’approche boîte noire peut s’avérer plus pratique.
4. Résumé
De 2021 à fin 2022, après l'optimisation de ce projet, la puissance de calcul d'inférence de Xiaohongshu a été multipliée par 30, les indicateurs clés des utilisateurs ont augmenté de plus de 10 % et, dans le même temps, les ressources du cluster ont été économisé de plus de 50 % de manière cumulative. À notre avis, la voie de développement de Xiaohongshu dans le domaine de la technologie de l'IA devrait être orientée par les besoins des entreprises et équilibrer le développement de la technologie et des affaires : tout en parvenant à l'innovation technologique, le coût, l'efficacité et la durabilité doivent également être pris en compte. Voici quelques réflexions au cours du processus d'optimisation :
Optimisez l'algorithme et améliorez les performances du système. C'est la mission principale de l'équipe d'apprentissage automatique de Xiaohongshu. L'optimisation des algorithmes et l'amélioration de la systématisation peuvent mieux répondre aux besoins de l'entreprise et améliorer l'expérience utilisateur. Cependant, lorsque les ressources sont limitées, l’équipe doit clarifier les objectifs de l’optimisation et éviter une sur-optimisation.
Construisez une infrastructure et améliorez les capacités de traitement des données. L'infrastructure est très essentielle pour prendre en charge les applications d'IA. Xiaohongshu peut envisager d'investir davantage dans la construction d'infrastructures, notamment dans les capacités de calcul et de stockage, les centres de données et l'architecture réseau. En outre, il est également très important d’améliorer les capacités de traitement des données afin de mieux prendre en charge les applications d’apprentissage automatique et de science des données.
Améliorer la densité des talents de l'équipe et la structure organisationnelle. Une excellente équipe de machine learning a besoin de talents possédant des compétences et des parcours différents, notamment des data scientists, des ingénieurs algorithmiques, des ingénieurs logiciels, etc. ; l'optimisation de la structure organisationnelle contribue également à améliorer l'efficacité de l'équipe et les capacités d'innovation.
Coopération gagnant-gagnant et innovation ouverte. Xiaohongshu continue de coopérer avec d'autres entreprises, institutions universitaires et communautés open source pour promouvoir conjointement le développement de la technologie de l'IA, ce qui aide Xiaohongshu à obtenir plus de ressources et de connaissances et à devenir une organisation plus ouverte et innovante.
Cette solution amène l'architecture d'apprentissage automatique de Xiaohongshu au plus haut niveau du secteur. À l'avenir, nous continuerons à promouvoir la mise à niveau des moteurs, à réduire les coûts et à accroître l'efficacité, à introduire de nouvelles technologies pour améliorer la productivité de l'apprentissage automatique de Xiaohongshu et à intégrer davantage les scénarios commerciaux réels de Xiaohongshu, en passant de l'optimisation d'un module unique à l'optimisation du système complet. et en outre, introduire les caractéristiques différentielles personnalisées du trafic côté entreprise pour atteindre l'objectif ultime de réduction des coûts et d'amélioration de l'efficacité. Nous attendons avec impatience que des personnes ayant de nobles idéaux nous rejoignent !
5. Équipe
Zhang Chulan (Du Zeyu) : Département de technologie commerciale
diplômé de l'Université normale de Chine orientale, chef de l'équipe du moteur de commercialisation, principalement responsable de la création de services en ligne commercialisés.
Lu Guang (Peng Peng) : Département de distribution intelligente
est diplômé de l'Université Jiao Tong de Shanghai, ingénieur moteur d'apprentissage automatique, principalement responsable de l'optimisation des GPU Lambda.
Ian (Chen Jianxin) : Département de distribution intelligente
est diplômé de l'Université des postes et télécommunications de Pékin, ingénieur moteur d'apprentissage automatique, principalement responsable du serveur de paramètres Lambda et de l'optimisation du GPU.
Aka Yu (Liu Zhaoyu) : Département de distribution intelligente
est diplômé de l'Université de Tsinghua et est ingénieur en moteurs d'apprentissage automatique. Il est principalement responsable de la recherche et de l'exploration connexes en direction des moteurs de fonctionnalités.
Remerciements particuliers à : Tous les étudiants du département Distribution Intelligente
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Jetez un œil à l'algorithme d'apprentissage automatique Sklearn de Python
- Comment l'apprentissage automatique non supervisé peut-il bénéficier à l'automatisation industrielle ?
- Comment utiliser l'apprentissage automatique pour analyser les sentiments
- Apprentissage automatique : ne sous-estimez pas la puissance des modèles arborescents
- Méthode de configuration pour l'utilisation de RStudio pour le développement de modèles d'apprentissage automatique sur les systèmes Linux