
Maison >Périphériques technologiques >IA >Apprentissage automatique : ne sous-estimez pas la puissance des modèles arborescents
Apprentissage automatique : ne sous-estimez pas la puissance des modèles arborescents

- WBOYavant
- 2023-04-18 19:10:011731parcourir
En raison de leur complexité, les réseaux de neurones sont souvent considérés comme le « Saint Graal » pour résoudre tous les problèmes d’apprentissage automatique. Les méthodes basées sur les arbres, en revanche, n’ont pas reçu autant d’attention, principalement en raison de l’apparente simplicité de ces algorithmes. Cependant, ces deux algorithmes peuvent sembler différents, mais ils sont comme les deux faces d’une même pièce, les deux sont importants.

Tree Model VS Neural Network
Les méthodes basées sur les arbres sont généralement meilleures que les réseaux de neurones. Essentiellement, les méthodes basées sur les arbres et les méthodes basées sur les réseaux neuronaux sont placées dans la même catégorie car elles abordent toutes deux le problème par une déconstruction étape par étape, plutôt que de diviser l'ensemble des données à travers des frontières complexes telles que des machines à vecteurs de support ou une régression logistique. .
Évidemment, les méthodes arborescentes segmentent progressivement l'espace des fonctionnalités selon différentes fonctionnalités pour optimiser le gain d'informations. Ce qui est moins évident, c’est que les réseaux de neurones abordent également les tâches de la même manière. Chaque neurone surveille une partie spécifique de l'espace des fonctionnalités (avec plusieurs chevauchements). Lorsque l’entrée pénètre dans cet espace, certains neurones sont activés.
Les réseaux de neurones examinent ce modèle pièce par pièce dans une perspective probabiliste, tandis que les méthodes basées sur les arbres adoptent une perspective déterministe. Quoi qu’il en soit, les performances des deux dépendent de la profondeur du modèle, puisque leurs composants sont associés à différentes parties de l’espace des fonctionnalités.
Un modèle qui contient trop de composants (nœuds dans le cas des modèles arborescents, neurones dans le cas des réseaux de neurones) sera surajusté, tandis qu'un modèle avec trop peu de composants ne peut tout simplement pas donner de prédictions significatives. (Les deux commencent par mémoriser des points de données, plutôt que d'apprendre à généraliser.)
Pour comprendre plus intuitivement comment les réseaux de neurones divisent l'espace des fonctionnalités, vous pouvez lire cet article présentant le théorème d'approximation universelle : https://medium.com/analytics -vidhya/vous-ne-comprenez-pas-les-réseaux-neuraux-jusqu'à-vous-comprenez-la-théorie-de-l'approximation-universelle-85b3e7677126.
Bien qu'il existe de nombreuses variantes puissantes d'arbres de décision tels que Random Forest, Gradient Boosting, AdaBoost et Deep Forest, d'une manière générale, les méthodes basées sur les arbres sont essentiellement des versions simplifiées des réseaux de neurones.
Les méthodes basées sur les arbres résolvent le problème pièce par pièce à travers des lignes verticales et horizontales pour minimiser l'entropie (optimiseur et perte). Les réseaux de neurones utilisent des fonctions d’activation pour résoudre les problèmes pièce par pièce.
Les méthodes basées sur les arbres sont déterministes plutôt que probabilistes. Cela apporte quelques simplifications intéressantes comme la sélection automatique des fonctionnalités.
Les nœuds de condition activés dans l'arbre de décision sont similaires aux neurones activés (flux d'informations) dans le réseau neuronal.
Le réseau neuronal transforme l'entrée en ajustant les paramètres et guide indirectement l'activation des neurones suivants. Les arbres de décision ajustent explicitement les paramètres pour guider le flux d'informations. (C'est le résultat du déterminisme versus probabiliste.)
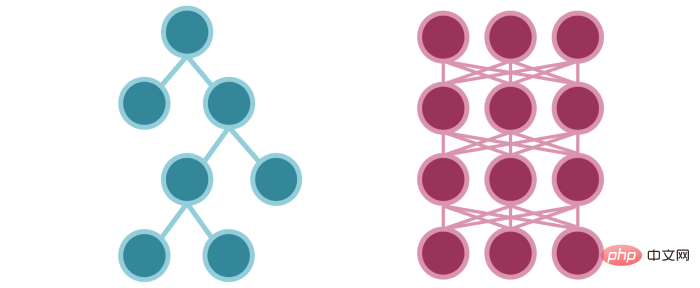
L'information circule de la même manière dans les deux modèles, mais de manière plus simple dans le modèle arborescent.
Sélection de 1 et de 0 dans les modèles arborescents VS Sélection probabiliste de réseaux de neurones
Bien sûr, il s'agit d'une conclusion abstraite et peut même être controversée. Certes, il existe de nombreux obstacles à l’établissement de ce lien. Quoi qu’il en soit, il s’agit d’un élément important pour comprendre quand et pourquoi les méthodes arborescentes sont meilleures que les réseaux de neurones.
Il est naturel que les arbres de décision fonctionnent avec des données structurées sous forme tabulaire ou tabulaire. La plupart des gens conviennent que l'utilisation de réseaux de neurones pour effectuer une régression et des prédictions sur des données tabulaires est excessive, c'est pourquoi certaines simplifications sont apportées ici. Le choix des 1 et des 0, plutôt que des probabilités, est la principale source de différence entre les deux algorithmes. Par conséquent, les méthodes arborescentes peuvent être appliquées avec succès à des situations où les probabilités ne sont pas requises, comme les données structurées.
Par exemple, les méthodes basées sur les arbres affichent de bonnes performances sur l'ensemble de données MNIST car chaque nombre possède plusieurs fonctionnalités essentielles. Il n'est pas nécessaire de calculer des probabilités et le problème n'est pas très complexe, c'est pourquoi un modèle d'ensemble d'arbres bien conçu peut fonctionner aussi bien, voire mieux, que les réseaux de neurones convolutifs modernes.
En général, les gens ont tendance à dire que « les méthodes basées sur les arbres se souviennent simplement des règles », ce qui est correct. Les réseaux de neurones sont identiques, sauf qu’ils peuvent mémoriser des règles plus complexes basées sur des probabilités. Plutôt que de donner explicitement une prédiction vrai/faux pour une condition telle que x>3, le réseau neuronal amplifie l'entrée à une valeur très élevée, ce qui donne une valeur sigmoïde de 1 ou génère une expression continue.
D'un autre côté, étant donné que les réseaux de neurones sont si complexes, on peut faire beaucoup de choses avec eux. Les couches convolutives et récurrentes sont des variantes exceptionnelles des réseaux de neurones car les données qu'elles traitent nécessitent souvent les nuances des calculs de probabilité.
Il existe très peu d'images pouvant être modélisées avec des uns et des zéros. Les valeurs de l'arbre de décision ne peuvent pas gérer des ensembles de données avec de nombreuses valeurs intermédiaires (par exemple 0,5), c'est pourquoi il fonctionne bien sur l'ensemble de données MNIST où les valeurs de pixels sont presque toutes noires ou blanches mais les pixels d'autres ensembles de données ne le sont pas (par exemple ImageNet). . De même, le texte contient trop d’informations et trop d’anomalies pour être exprimées en termes déterministes.
C'est pourquoi les réseaux de neurones sont principalement utilisés dans ces domaines, et pourquoi la recherche sur les réseaux de neurones a stagné au début (avant le début du 21e siècle), lorsque de grandes quantités de données d'images et de textes n'étaient pas disponibles. D'autres utilisations courantes des réseaux de neurones se limitent aux prédictions à grande échelle, telles que les algorithmes de recommandation de vidéos YouTube, qui sont très volumineux et doivent utiliser des probabilités.
L'équipe de science des données de toute entreprise utilisera probablement des modèles arborescents au lieu de réseaux de neurones, à moins qu'elle ne construise une application lourde comme le flou de l'arrière-plan d'une vidéo Zoom. Mais dans les tâches quotidiennes de classification métier, les méthodes arborescentes allègent ces tâches en raison de leur nature déterministe, et leurs méthodes sont les mêmes que celles des réseaux de neurones.
Dans de nombreuses situations pratiques, la modélisation déterministe est plus naturelle que la modélisation probabiliste. Par exemple, pour prédire si un utilisateur achètera un article sur un site de commerce électronique, un modèle arborescent est un bon choix car les utilisateurs suivent naturellement un processus de prise de décision basé sur des règles. Le processus de prise de décision d'un utilisateur pourrait ressembler à ceci :
- Ai-je déjà eu une expérience d'achat positive sur cette plateforme ? Si c'est le cas, continuez.
- Ai-je besoin de cet article maintenant ? (Par exemple, dois-je acheter des lunettes de soleil et un maillot de bain pour l'hiver ?) Si oui, continuez.
- Sur la base des données démographiques de mes utilisateurs, s'agit-il d'un produit que je souhaite acheter ? Si oui, continuez.
- Est-ce que ce truc est trop cher ? Sinon, continuez.
- D'autres clients ont-ils suffisamment évalué ce produit pour que je me sente à l'aise de l'acheter ? Si oui, continuez.
De manière générale, les humains suivent des processus de prise de décision structurés et fondés sur des règles. Dans ces cas, la modélisation probabiliste n’est pas nécessaire.
Conclusion
- Il est préférable de considérer les méthodes arborescentes comme des versions réduites des réseaux de neurones, permettant un moyen plus simple d'effectuer la classification des fonctionnalités, l'optimisation, le transfert de flux d'informations, etc.
- La principale différence d'utilisation entre les méthodes basées sur les arbres et les méthodes de réseau neuronal réside dans les structures de données déterministes (0/1) et probabilistes. Les données structurées (tabulaires) peuvent être mieux modélisées à l'aide de modèles déterministes.
- Ne sous-estimez pas la puissance de la méthode des arbres.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI