
Maison >Périphériques technologiques >IA >Comment l'apprentissage automatique non supervisé peut-il bénéficier à l'automatisation industrielle ?
Comment l'apprentissage automatique non supervisé peut-il bénéficier à l'automatisation industrielle ?

- PHPzavant
- 2023-04-08 17:21:011717parcourir
Les environnements industriels modernes regorgent de capteurs et de composants intelligents, et tous ces appareils produisent ensemble une richesse de données. Ces données, inexploitées aujourd’hui dans la plupart des usines, alimentent une variété de nouvelles applications passionnantes. En fait, selon IBM, une usine moyenne génère 1 To de données de production chaque jour. Cependant, seulement 1 % environ des données sont transformées en informations exploitables.

Le Machine Learning (ML) est une technologie fondamentale conçue pour exploiter ces données et débloquer d'énormes quantités de valeur. À l’aide de données de formation, les systèmes d’apprentissage automatique peuvent créer des modèles mathématiques qui apprennent à un système à effectuer des tâches spécifiques sans instructions explicites.
ML utilise des algorithmes qui agissent sur les données pour prendre des décisions en grande partie sans intervention humaine. La forme d'apprentissage automatique la plus courante dans l'automatisation industrielle est l'apprentissage automatique supervisé, qui utilise de grandes quantités de données historiques étiquetées par des humains pour former des modèles (c'est-à-dire la formation d'algorithmes supervisés par des humains).
Cela est utile pour les problèmes bien connus tels que les défauts de roulements, les défauts de lubrification ou les défauts de produits. Là où l'apprentissage automatique supervisé échoue, c'est lorsque suffisamment de données historiques ne sont pas disponibles, que l'étiquetage prend trop de temps ou est trop coûteux, ou que les utilisateurs ne savent pas exactement ce qu'ils recherchent dans les données. C’est là qu’intervient l’apprentissage automatique non supervisé.
L'apprentissage automatique non supervisé vise à fonctionner sur des données non étiquetées à l'aide d'algorithmes efficaces pour reconnaître des modèles et identifier les anomalies dans les données. Un apprentissage automatique non supervisé correctement appliqué sert une variété de cas d'utilisation de l'automatisation industrielle, de la surveillance de l'état et des tests de performances à la cybersécurité et à la gestion des actifs.
Apprentissage supervisé vs apprentissage non supervisé
L'apprentissage automatique supervisé est plus facile à réaliser que l'apprentissage automatique non supervisé. Avec un modèle correctement entraîné, il peut fournir des résultats très cohérents et fiables. L'apprentissage automatique supervisé peut nécessiter de grandes quantités de données historiques - car il est nécessaire d'inclure tous les cas pertinents, c'est-à-dire que pour détecter les défauts des produits, les données doivent contenir un nombre suffisant de cas de produits défectueux. L’étiquetage de ces ensembles de données massifs peut prendre du temps et être coûteux. De plus, former des modèles est un art. Cela nécessite de grandes quantités de données, correctement organisées, pour produire de bons résultats.
De nos jours, le processus d'analyse comparative de différents algorithmes de ML a été considérablement simplifié à l'aide d'outils comme AutoML. Dans le même temps, une contrainte excessive du processus de formation peut aboutir à un modèle qui fonctionne bien sur l'ensemble de formation mais qui fonctionne mal sur les données réelles. Un autre inconvénient majeur est que l’apprentissage automatique supervisé n’est pas très efficace pour identifier des tendances inattendues dans les données ou découvrir de nouveaux phénomènes. Pour ces types d’applications, l’apprentissage automatique non supervisé peut fournir de meilleurs résultats.
Techniques courantes d'apprentissage automatique non supervisé
Comparé à l'apprentissage automatique supervisé, l'apprentissage automatique non supervisé ne fonctionne que sur des entrées non étiquetées. Il fournit des outils puissants d’exploration des données afin de découvrir des modèles et des corrélations inconnus sans aide humaine. La possibilité d'opérer sur des données non étiquetées permet d'économiser du temps et de l'argent et permet à l'apprentissage automatique non supervisé d'opérer sur les données dès que l'entrée est générée.
L'inconvénient est que l'apprentissage automatique non supervisé est plus complexe que l'apprentissage automatique supervisé. Cela coûte plus cher, nécessite un niveau d’expertise plus élevé et nécessite souvent plus de données. Sa sortie a tendance à être moins fiable que le ML supervisé et nécessite finalement une supervision humaine pour des résultats optimaux.
Trois formes importantes de techniques d'apprentissage automatique non supervisées sont le clustering, la détection d'anomalies et la réduction de la dimensionnalité des données.
Clustering
Comme son nom l'indique, le clustering implique l'analyse d'un ensemble de données pour identifier les caractéristiques partagées entre les données et regrouper les instances similaires. Le clustering étant une technique de ML non supervisée, l’algorithme (plutôt qu’un humain) détermine les critères de classement. Par conséquent, le clustering peut conduire à des découvertes surprenantes et constitue un excellent outil d’exploration de données.
Pour donner un exemple simple : imaginez que trois personnes soient invitées à trier des fruits dans un département de production. L’un peut trier par type de fruit – agrumes, fruits à noyau, fruits tropicaux, etc. ; un autre peut trier par couleur et un troisième par forme ; Chaque méthode met en évidence un ensemble différent de caractéristiques.
Le clustering peut être divisé en plusieurs types. Les plus courants sont :
Clustering exclusif : Une instance de données est exclusivement affectée à un cluster.
Clustering flou ou superposé (Fuzzy Clustering) : Une instance de données peut être attribuée à plusieurs clusters. Par exemple, les oranges sont à la fois des agrumes et des fruits tropicaux. Dans le cas d'algorithmes ML non supervisés fonctionnant sur des données non étiquetées, il est possible d'attribuer une probabilité qu'un bloc de données appartienne correctement au groupe A par rapport au groupe B.
Clustering hiérarchique : Cette technique consiste à construire une structure hiérarchique de données clusterisées plutôt qu'un ensemble de clusters. Les oranges sont des agrumes, mais elles font également partie du plus grand groupe de fruits sphériques et peuvent être absorbées par tous les groupes de fruits.
Examinons un ensemble d'algorithmes de clustering les plus populaires :
- K-means
L'algorithme K-means classe les données en K clusters, où la valeur de K est prédéterminée par l'utilisateur. Au début du processus, l'algorithme attribue de manière aléatoire K points de données comme centroïdes pour K clusters. Ensuite, il calcule la moyenne entre chaque point de données et le centre de gravité de son cluster. Cela entraîne le recours aux données vers le cluster. À ce stade, l’algorithme recalcule le centroïde et répète le calcul de la moyenne. Il répète le processus de calcul des centroïdes et de réorganisation des clusters jusqu'à ce qu'il atteigne une solution constante (voir Figure 1).

Figure 1 : L'algorithme K-means divise l'ensemble de données en K clusters en sélectionnant d'abord au hasard K points de données comme centroïdes, puis en attribuant aléatoirement les instances restantes parmi les clusters.
L'algorithme K-means est simple et efficace. Il est très utile pour la reconnaissance de formes et l’exploration de données. L’inconvénient est que cela nécessite une connaissance avancée de l’ensemble de données pour optimiser la configuration. Il est également affecté de manière disproportionnée par les valeurs aberrantes.
- K-median
L'algorithme K-median est un proche parent des K-means. Il utilise essentiellement le même processus, sauf qu'au lieu de calculer la moyenne de chaque point de données, il calcule la médiane. L’algorithme est donc moins sensible aux valeurs aberrantes.
Voici quelques cas d'utilisation courants de l'analyse de cluster :
- Le clustering est très efficace pour des cas d'utilisation comme la segmentation. Ceci est souvent associé à l’analyse client. Elle peut également être appliquée aux classes d'actifs, non seulement pour analyser la qualité et les performances des produits, mais également pour identifier les modèles d'utilisation susceptibles d'avoir un impact sur les performances et la durée de vie des produits. Ceci est utile pour les entreprises OEM qui gèrent des « flottes » d'actifs, tels que des robots mobiles automatisés dans des entrepôts intelligents ou des drones pour l'inspection et la collecte de données.
- Il peut être utilisé pour la segmentation d'images dans le cadre d'opérations de traitement d'images.
- L'analyse cluster peut également être utilisée comme étape de prétraitement pour aider à préparer les données pour les applications ML supervisées.
Détection des anomalies
La détection des anomalies est essentielle pour une variété de cas d'utilisation, de la détection des défauts à la surveillance de l'état en passant par la cybersécurité. Il s’agit d’une tâche clé de l’apprentissage automatique non supervisé. Il existe plusieurs algorithmes de détection d'anomalies utilisés dans l'apprentissage automatique non supervisé. Jetons un coup d'œil à deux des plus populaires :
- Algorithme de forêt d'isolement
L'approche standard de la détection d'anomalies consiste à établir un ensemble d'algorithmes normaux. valeurs , puis analysez chaque élément de données pour voir si et dans quelle mesure elle s'écarte de la valeur normale. Il s'agit d'un processus très chronophage lorsque l'on travaille avec des ensembles de données massifs comme ceux utilisés en ML. L’algorithme de forêt d’isolement adopte l’approche opposée. Il définit les valeurs aberrantes comme n’étant ni courantes ni très différentes des autres instances de l’ensemble de données. Par conséquent, ils sont plus facilement isolés du reste de l’ensemble de données sur d’autres instances.
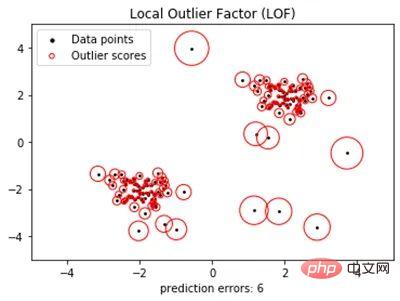
L'algorithme de forêt d'isolement a les besoins en mémoire les plus faibles et le temps requis est linéairement lié à la taille de l'ensemble de données. Ils peuvent gérer des données de grande dimension même si elles impliquent des attributs non pertinents. Facteur de valeurs aberrantes locales (LOF) qui se trouvent à une courte distance des grands clusters sont susceptibles d'être des valeurs aberrantes. Les points qui semblent éloignés ne le sont peut-être pas. L'algorithme LOF est conçu pour faire cette distinction.
- LOF définit une valeur aberrante comme un point de données dont l'écart de densité locale est beaucoup plus grand que ses points de données voisins (voir Figure 2). Bien que, comme K-means, cela nécessite une configuration utilisateur préalable, il peut être très efficace. Il peut également être appliqué à la détection de nouveauté lorsqu'il est utilisé comme algorithme semi-supervisé et formé uniquement sur des données normales.
- Maintenance prédictive : la plupart des équipements industriels sont conçus pour durer avec un temps d'arrêt minimal. Les données historiques disponibles sont donc souvent limitées. Étant donné que le ML non supervisé peut détecter un comportement anormal même dans des ensembles de données limités, il peut potentiellement identifier des déficiences de développement dans ces cas. Ici aussi, il peut être utilisé pour la gestion de flotte, en fournissant une alerte précoce en cas de défauts tout en minimisant la quantité de données à examiner.
- Assurance qualité/inspection : des machines mal utilisées peuvent produire des produits de qualité inférieure. L’apprentissage automatique non supervisé peut être utilisé pour surveiller les fonctions et les processus afin de signaler toute anomalie. Contrairement aux processus d’assurance qualité standard, cela peut se faire sans étiquetage ni formation.
- Identification des anomalies d'images : Ceci est particulièrement utile en imagerie médicale pour identifier des pathologies dangereuses.
- Cybersécurité : L'un des plus grands défis en matière de cybersécurité est que les menaces évoluent constamment. Dans ce cas, la détection d’anomalies via ML non supervisé peut être très efficace. Une technique de sécurité standard consiste à surveiller les flux de données. Si un automate qui envoie normalement des commandes à d'autres composants commence soudainement à recevoir un flux constant de commandes provenant d'appareils ou d'adresses IP atypiques, cela pourrait indiquer une intrusion. Mais que se passe-t-il si le code malveillant provient d’une source fiable (ou si un acteur malveillant usurpe une source fiable) ? L'apprentissage non supervisé peut détecter les mauvais acteurs en recherchant un comportement atypique dans les appareils recevant des commandes.
- Analyse des données de test : les tests jouent un rôle essentiel dans la conception et la production. Les deux plus grands défis impliqués sont le volume considérable de données impliquées et la capacité à analyser les données sans introduire de biais inhérent. L’apprentissage automatique non supervisé peut résoudre ces deux défis. Cela peut s'avérer particulièrement avantageux lors du processus de développement ou du dépannage en production, lorsque l'équipe de test n'est même pas sûre de ce qu'elle recherche.
Réduction de la dimensionnalité
Le Machine Learning est basé sur de grandes quantités de données, souvent de très grandes quantités. C'est une chose de filtrer un ensemble de données comportant dix à plusieurs dizaines de fonctionnalités. Les ensembles de données comportant des milliers de fonctionnalités (et ils existent certainement) peuvent être écrasants. Par conséquent, la première étape du ML peut être la réduction de la dimensionnalité afin de réduire les données aux fonctionnalités les plus significatives.
Un algorithme couramment utilisé pour la réduction de dimensionnalité, la reconnaissance de formes et l'exploration de données est l'analyse en composantes principales (ACP). Une discussion détaillée de cet algorithme dépasse le cadre de cet article. Cela peut sans doute aider à identifier des sous-ensembles de données mutuellement orthogonaux, c'est-à-dire qu'ils peuvent être supprimés de l'ensemble de données sans affecter l'analyse principale. PCA a plusieurs cas d'utilisation intéressants :
- Prétraitement des données : lorsqu'il s'agit d'apprentissage automatique, la philosophie souvent énoncée est que plus c'est mieux. Cela dit, parfois, plus c'est plus, surtout dans le cas de données non pertinentes/redondantes. Dans ces cas, l’apprentissage automatique non supervisé peut être utilisé pour supprimer les fonctionnalités inutiles (dimensions des données), accélérant ainsi le temps de traitement et améliorant les résultats. Dans le cas des systèmes visuels, l’apprentissage automatique non supervisé peut être utilisé pour réduire le bruit.
- Compression d'image : la PCA est très efficace pour réduire la dimensionnalité d'un ensemble de données tout en conservant des informations significatives. Cela rend l'algorithme très efficace pour la compression d'images.
- Reconnaissance de modèles : les mêmes fonctionnalités décrites ci-dessus rendent la PCA utile pour des tâches telles que la reconnaissance faciale et d'autres reconnaissances d'images complexes.
L'apprentissage automatique non supervisé n'est ni meilleur ni pire que l'apprentissage automatique supervisé. Pour le bon projet, cela peut être très efficace. Cela dit, la meilleure règle de base est de rester simple, de sorte que l’apprentissage automatique non supervisé n’est généralement utilisé que pour des problèmes que l’apprentissage automatique supervisé ne peut pas résoudre.
Réfléchissez aux questions suivantes pour déterminer quelle approche d'apprentissage automatique est la meilleure pour votre projet :
- Quel est le problème ?
- Qu'est-ce qu'une analyse de rentabilisation ? Quel est le but de la quantification ? À quelle vitesse le projet fournira-t-il un retour sur investissement ? Comment cela se compare-t-il à l’apprentissage supervisé ou à d’autres solutions plus traditionnelles ?
- Quels types de données d'entrée sont disponibles ? Combien en avez-vous ? Est-ce pertinent par rapport à la question à laquelle vous souhaitez répondre ? Existe-t-il un processus qui produit déjà des données étiquetées, par exemple, existe-t-il un processus d'assurance qualité qui identifie les produits défectueux ? Existe-t-il une base de données de maintenance qui enregistre les pannes d'équipement ?
- Est-il adapté à l'apprentissage automatique non supervisé ?
Enfin, voici quelques conseils pour vous aider à réussir :
- Faites vos devoirs et élaborez une stratégie avant de démarrer un projet.
- Commencez petit et corrigez les bugs à plus petite échelle.
- Assurez-vous que la solution est évolutive, vous ne voulez pas vous retrouver dans le purgatoire des projets pilotes.
- Envisagez de travailler avec un partenaire. Tous les types d’apprentissage automatique nécessitent une expertise. Trouvez les bons outils et partenaires pour automatiser. Ne réinventez pas la roue. Vous pouvez payer pour développer les compétences nécessaires en interne, ou vous pouvez consacrer vos ressources à la fourniture des produits et services que vous maîtrisez le mieux tout en laissant vos partenaires et votre écosystème gérer le gros du travail.
Les données collectées en milieu industriel peuvent constituer une ressource précieuse, mais seulement si elles sont exploitées de manière appropriée. L’apprentissage automatique non supervisé peut être un outil puissant pour analyser des ensembles de données afin d’en extraire des informations exploitables. L’adoption de cette technologie peut s’avérer difficile, mais elle peut offrir un avantage concurrentiel significatif dans un monde difficile.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI