
Maison >Périphériques technologiques >IA >Pratique de l'architecture back-end du robot d'entretien IA
Pratique de l'architecture back-end du robot d'entretien IA

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-08 17:21:041811parcourir
01 Introduction
Le robot d'entretien IA utilise la capacité de dialogue vocal homme-machine de la plate-forme sémantique vocale intelligente Lingxi pour simuler plusieurs cycles de communication vocale entre les recruteurs et les demandeurs d'emploi, obtenant ainsi l'effet d'un entretien en ligne. Cet article décrit en détail la composition de l'architecture back-end, la conception du moteur de dialogue, la stratégie d'estimation de la demande de ressources et les méthodes d'optimisation des performances de service du robot d'entretien IA. Le robot d'entretien IA est en ligne depuis plus d'un an et a reçu des millions de demandes d'entretien, améliorant considérablement l'efficacité du recrutement des recruteurs et l'expérience d'entretien des demandeurs d'emploi.
02 Contexte du projet
58 City Life Service Platform comprend quatre grandes entreprises établies : l'immobilier, l'automobile, le recrutement et les services de proximité (pages jaunes). La plateforme connecte un grand nombre d'utilisateurs du côté C et des commerçants du côté B, et les commerçants du côté B peuvent publier sur la plateforme Différents types d'informations (nous les appelons « posts ») telles que le logement, la disponibilité des voitures, les emplois et les services de vie. La plateforme distribue ces messages aux utilisateurs du côté C pour qu'ils puissent les parcourir. les aidant ainsi à obtenir les informations dont ils ont besoin et en aidant les commerçants du côté B à distribuer et à diffuser des informations pour acquérir des clients cibles afin d'améliorer l'efficacité des commerçants du côté B dans l'acquisition de clients cibles et d'améliorer l'expérience utilisateur du côté C. continue d'innover en matière de produits dans des domaines tels que les recommandations personnalisées et les connexions intelligentes.
Prenons l'exemple du recrutement. Affectée par l'épidémie en 2020, la méthode traditionnelle d'entretien de recrutement hors ligne a été fortement impactée. Le nombre de demandes d'entretien en ligne de demandeurs d'emploi via WeChat, vidéo, etc. recrutement L'intervieweur ne peut établir une chaîne d'entretien vidéo en ligne qu'avec un seul demandeur d'emploi à la fois, ce qui entraîne un faible taux de réussite de la mise en relation entre le demandeur d'emploi et le recruteur. Afin d'améliorer l'expérience utilisateur des demandeurs d'emploi et d'améliorer l'efficacité des entretiens pour les recruteurs, 58.com TEG AI Lab a collaboré avec plusieurs départements tels que le métier de recrutement pour créer un outil intelligent d'entretien de recrutement : la Magic Interview Room. Le produit se compose principalement de trois parties : le client, la communication audio et vidéo et le robot d'entretien IA (voir : Personnes | Li Zhong : le robot d'entretien IA crée un recrutement intelligent).
Cet article se concentrera principalement sur le robot d'entretien IA. Le robot d'entretien IA utilise la capacité de dialogue vocal homme-machine de la plate-forme sémantique vocale intelligente Lingxi pour simuler plusieurs cycles de communication vocale entre les recruteurs et les demandeurs d'emploi. l'effet des entretiens en ligne. D'une part, cela peut résoudre le problème selon lequel un recruteur ne peut répondre qu'à la demande d'entretien en ligne d'un seul demandeur d'emploi, améliorant ainsi l'efficacité du travail du recruteur. D'autre part, cela peut répondre aux exigences des demandeurs d'emploi de mener des entretiens vidéo indépendamment ; de l'heure et du lieu, tout en modifiant les CV personnels du traditionnel L'introduction de la description textuelle est convertie en une auto-présentation vidéo plus intuitive et plus vivante. Cet article décrit en détail l'architecture back-end du robot d'entretien IA, la conception du moteur de dialogue vocal homme-machine, comment estimer les besoins en ressources pour faire face à l'expansion du trafic et comment optimiser les performances du service pour assurer la stabilité. et la disponibilité du service global de robot d'entretien IA.
03 Architecture back-end du robot d'entretien IA
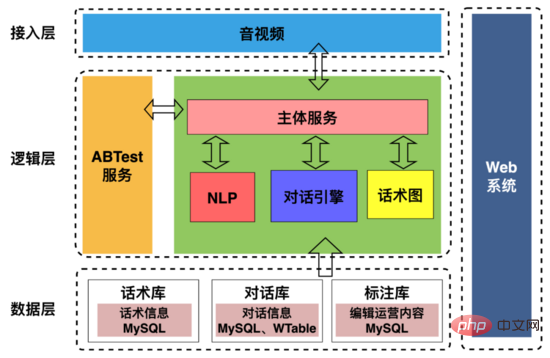
L'architecture du robot d'entretien IA est présentée dans la figure ci-dessus, comprenant :
1 Couche d'accès : principalement utilisée pour gérer les interactions avec l'amont et l'aval, y compris celles convenues. communication avec les terminaux audio et vidéo Protocole ; extraire les portraits des utilisateurs lors des entretiens, extraire les informations de la chronologie des interactions des utilisateurs du robot et les envoyer au service de recrutement.
2. Couche logique : principalement utilisée pour gérer l'interaction de dialogue entre le robot et l'utilisateur, notamment la synthèse du texte de la question du robot en données vocales et son envoi à l'utilisateur, en posant des questions à l'utilisateur afin que le robot puisse « parler » ; après que l'utilisateur a répondu, les données vocales de réponse de l'utilisateur sont segmentées via VAD (Voice Activity Detection), et la parole diffusée en continu est reconnue comme du texte, de sorte que le robot puisse « l'entendre », le moteur de dialogue détermine le contenu de la réponse en fonction de la réponse de l'utilisateur ; répond au texte et aux compétences conversationnelles, puis synthétise le discours et l'envoie à l'utilisateur, réalisant ainsi la « communication » entre le robot et l'utilisateur.
3. Couche de données : stocke les données de base telles que les diagrammes vocaux, les enregistrements de conversations et les informations d'annotation.
4. Système Web : configurez visuellement la structure du discours, les stratégies de dialogue et annotez les données de dialogue d'entretien.
04 Le processus global d'interaction entre le robot d'entretien IA et l'utilisateur
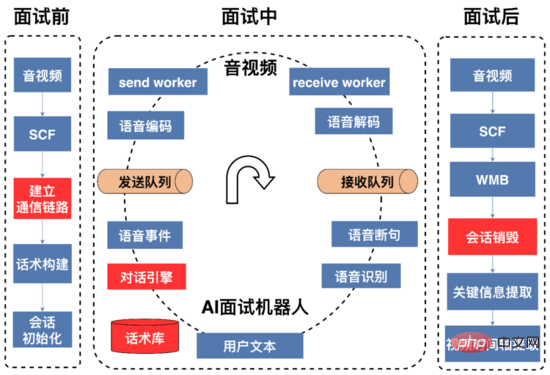
Un processus complet d'entretien IA est présenté dans la figure ci-dessus, qui peut être divisé en trois étapes : avant l'entretien, pendant l'entretien et après l'entretien. entretien.
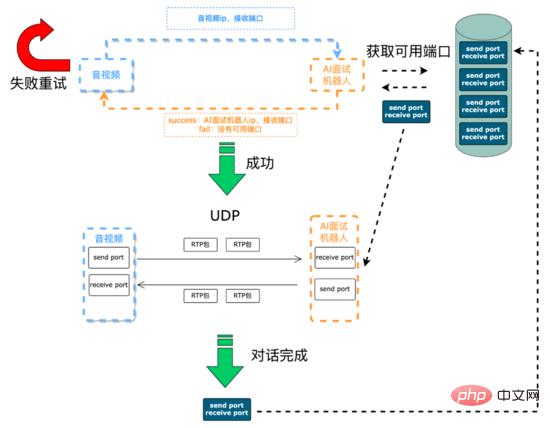
Avant l'entretien : L'essentiel est d'établir les liens de communication et d'initialiser les ressources. Les signaux vocaux entre le robot d'entretien IA et les terminaux audio et vidéo sont transmis via UDP L'IP et les ports nécessaires à la communication entre l'audio et. la vidéo et le robot d'entretien IA doivent être maintenus de manière dynamique. L'extrémité audio et vidéo lance une demande d'interview via l'interface SCF (SCF est un framework RPC développé indépendamment par 58). D'une part, la requête obtient dynamiquement les ressources IP et de port du robot d'interview AI en temps réel pour les suivantes. collecte audio et vidéo du processus d'entretien. Le signal vocal est envoyé au robot IA. D'autre part, le robot IA reçoit l'adresse IP et le port qui doivent être envoyés en réponse au signal vocal de l'utilisateur. Étant donné que SCF prend en charge l'équilibrage de charge, la demande d'interview initiée par l'extrémité audio et vidéo sera envoyée de manière aléatoire au service du robot d'interview AI Sur une certaine machine du cluster, le robot d'interview AI sur cette machine obtient l'adresse IP et. port du terminal audio et vidéo via les paramètres de transmission transparents SCF. Ensuite, le service du robot d'interview AI essaie d'abord de sélectionner dans la file d'attente des ports disponibles (créée lors de l'initialisation du service). d'un port d'envoi et d'un port de réception) dans une structure de données de file d'attente qui stocke les paires de ports disponibles. Si l'acquisition réussit, le service transmettra l'adresse IP et le port de cette machine via l'interview SCF. L'interface de requête est renvoyée à l'audio. et la vidéo se termine, et les deux parties peuvent alors établir une communication UDP. Une fois l'interview terminée, le service poussera la paire de ports vers la file d'attente des ports disponibles. Si l'obtention de la paire de ports échoue, le service renverra un code d'échec de communication au terminal audio et vidéo via l'interface SCF. Le terminal audio et vidéo peut réessayer ou abandonner la demande d'interview.
Établir le processus de communication :
Dans le processus de transmission du signal vocal, nous utilisons le protocole RTP comme protocole multimédia audio dans le système. Le protocole RTP, Real-time Transport Protocol, fournit des services de transmission en temps réel de bout en bout pour diverses données multimédia telles que la voix, l'image, le fax, etc. qui doivent être transmises en temps réel sur IP. Les messages RTP se composent de deux parties : l'en-tête et la charge utile.
En-tête RTP :
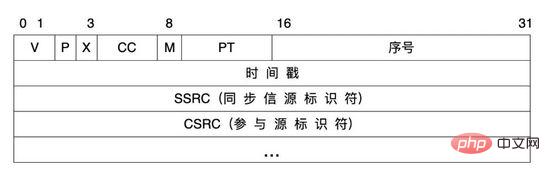
Explication de l'attribut :
Attribut |
explication |
| V |
Le numéro de version de la version du protocole RTP, comptabilité pour 2 chiffres, le numéro de version actuel du protocole est 2 |
P |
fill flag, qui occupe 1 bit. Si P=1, alors la queue du message est remplie d'un ou plusieurs 8- supplémentaires. tableaux de bits, qui ne sont pas valides Une partie de la charge |
X |
Drapeau d'extension, occupe 1 bit, si le nombre de marques |
M |
, représentant 1 position, différentes charges utiles ont des significations différentes pour la vidéo. audio, il marque le début d’une session. |
PT |
Le type de charge utile, qui occupe 7 bits, est utilisé pour décrire le type de charge utile dans le message RTP, comme l'audio, l'image, etc. Dans les médias en streaming, il est principalement utilisé pour distinguer les flux audio et le flux vidéo est facile à analyser pour le client. |
Le numéro de séquence |
occupe 16 bits et sert à identifier le numéro de séquence du message RTP envoyé par l'expéditeur. Chaque fois qu'un message est envoyé, le numéro de séquence augmente de 1. Lorsque le protocole support de couche inférieure utilise UDP, ce champ peut être utilisé pour vérifier la perte de paquets lorsque l'état du réseau n'est pas bon. Dans le même temps, la gigue du réseau peut être utilisée pour réorganiser les données. |
L'horodatage |
occupe 32 bits, reflétant le temps d'échantillonnage du premier octet du message RTP. Le récepteur peut utiliser l'horodatage pour calculer le retard et la gigue du retard, et effectuer un contrôle de synchronisation. |
SSRC |
permet d'identifier la source de synchronisation. Cette identification peut être sélectionnée aléatoirement. Deux sources de synchronisation participant à la même vidéoconférence ne peuvent pas avoir le même SSRC |
|
CSRC . |
Chaque identifiant CSRC occupe 32 bits et peut en avoir de 0 à 15. Chaque CSRC identifie toutes les sources privilégiées contenues dans la charge utile du message RTP. |
Pendant l'entretien : au cours de ce processus, le robot d'entretien IA envoie d'abord une déclaration d'ouverture. Le texte de la déclaration d'ouverture est synthétisé en données vocales via tts (Text To Speech). à l'adresse IP et au port convenus du terminal audio et vidéo. Les utilisateurs répondent de manière pertinente en fonction des questions qu'ils entendent ; le robot d'interview AI décode le flux vocal de l'utilisateur reçu et le convertit en texte via la segmentation vad et la reconnaissance vocale en streaming. Le moteur de dialogue détermine le contenu de la réponse en fonction du texte de réponse de l'utilisateur et du diagramme d'état de la structure vocale. Le robot d'entretien IA interagit en permanence avec l'utilisateur jusqu'à la fin de la conversation ou jusqu'à ce que l'utilisateur raccroche l'entretien.
Après l'entretien : Une fois que le robot d'entretien IA reçoit la demande audio et vidéo pour la fin de l'entretien, le robot d'entretien IA recyclera les ressources appliquées lors de la phase de préparation de l'entretien telles que les ports, les fils de discussion, etc. ; construire le portrait de l'utilisateur (impliquant l'heure d'arrivée la plus rapide de l'utilisateur, des informations telles que si vous avez occupé le poste, votre âge, etc.) sont fournies au recruteur pour permettre aux commerçants de filtrer, d'enregistrer et de stocker la conversation d'entretien.
Plan d'enregistrement :
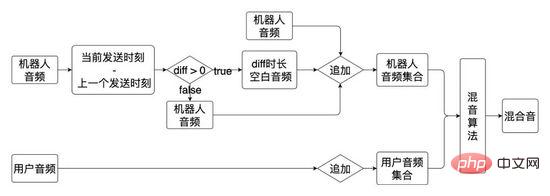
05 Fonction principale du moteur de dialogue
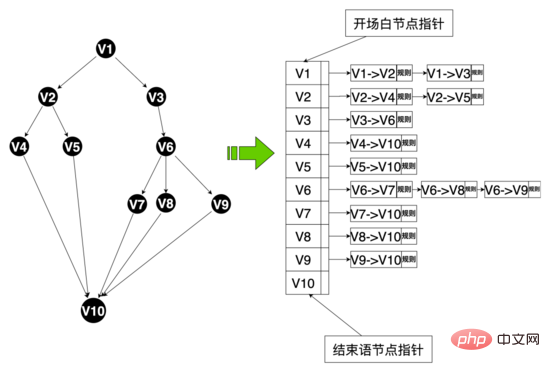
Dans l'ensemble du processus d'entretien, le robot d'entretien IA et l'interaction de l'utilisateur sont pilotés par le moteur de dialogue basé sur le processus de conversation, où la conversation est dirigée graphe acyclique. Initialement, le graphe de dialogue était un dialogue à deux branches (bords de tous les nœuds
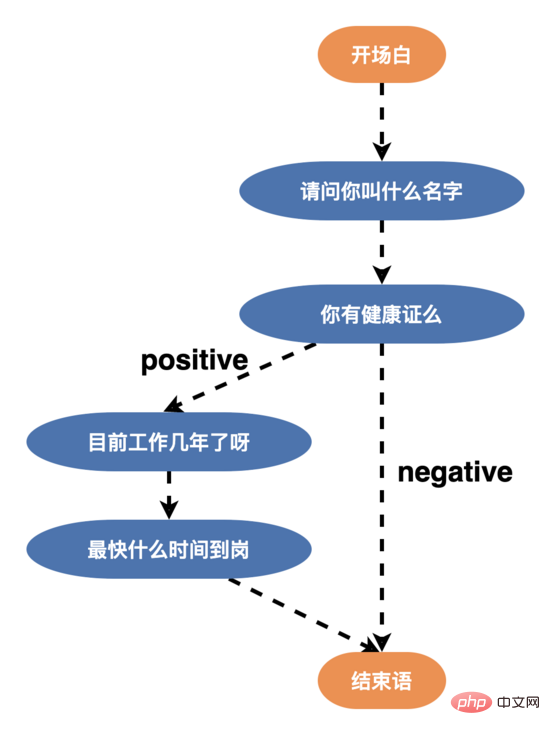
Par conséquent, afin d'améliorer la volonté des utilisateurs de parler et d'améliorer les capacités de dialogue intelligent du robot, nous avons reconstruit la structure de la parole et conçu une parole multi-branches (bord d'un nœud >= 3), comme indiqué ci-dessous, l'utilisateur peut répondre aux différentes compétences vocales des utilisateurs de manière personnalisée en fonction de leur âge, de leur éducation et de leur personnalité. Après le lancement de la nouvelle structure vocale, le taux de réussite des entretiens a dépassé 50 %.
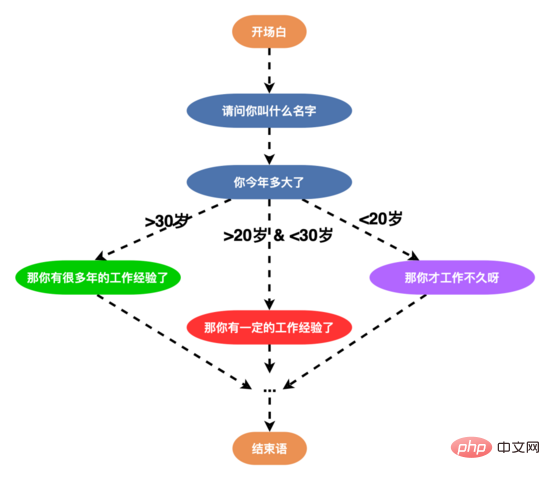
Dans le même temps, afin de concevoir la stratégie de dialogue de manière plus fine, nous avons conçu une chaîne de stratégie au niveau du nœud sur la chaîne de stratégie, qui peut personnaliser une stratégie de dialogue personnalisée pour un seul nœud. pour répondre à des besoins de dialogue personnalisé.
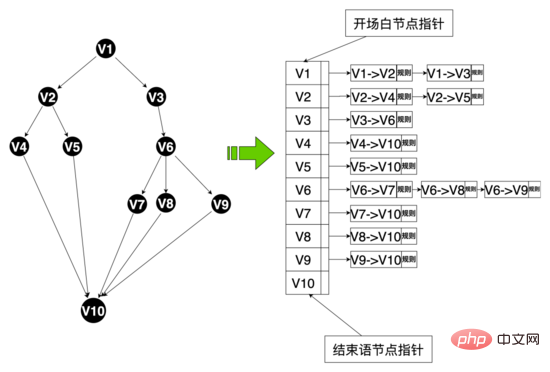
Niveau de données : Afin de réaliser une parole multibranche, nous avons repensé la structure des données liée à la parole et extrait certaines entités de données, notamment : la table vocale, le nœud vocal, le bord de la parole, etc. Les nœuds Hua Shu sont liés à Hua Shu via les numéros Hua Shu, et en même temps conservent le texte Hua Shu et d'autres attributs maintiennent la relation topologique entre les nœuds, y compris les nœuds de début et de fin. via les numéros de bord. Le bord atteint la régularité, le corpus et d'autres règles, et vous pouvez utiliser l'ID de bord pour personnaliser vos propres règles pour ce bord. La chaîne de politiques lie différentes politiques via le numéro de chaîne de politiques, et les mots et nœuds lient différentes chaînes de politiques via le numéro de chaîne de politiques.
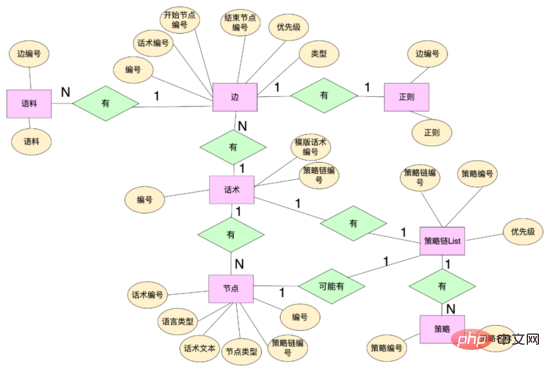
Les concepts d'arêtes, de nœuds, de classes vocales et de classes d'état de la parole sont abstraits. Les arêtes et les nœuds sont des mappages de la couche de données telles que la régularité et le corpus. les classes vocales sont conservées. Informations clés telles que le nœud d'ouverture et le graphe vocal. Le graphe vocal est un mappage de la topologie vocale entière. Il maintient le mappage entre les nœuds et l'ensemble des nœuds et des bords à partir de ce nœud. maintient l'état actuel de la parole, y compris la classe Hua Shu et le nœud actuel, le système peut obtenir toutes les arêtes à partir de ce nœud à partir du graphique Hua Shu basé sur le nœud actuel de Hua Shu (similaire à une liste de contiguïté) et faire correspondre les règles sur différents bords en fonction de la réponse actuelle de l'utilisateur. S'il y a un succès, alors le graphe vocal circulera vers le nœud final du bord touché, et le contenu de la réponse du robot sera obtenu à partir de ce nœud, et la structure vocale sera couler.
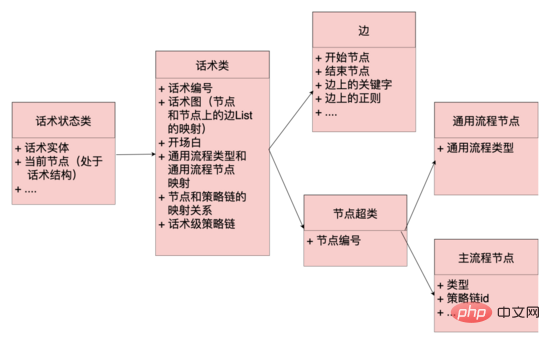
Structure des données du diagramme :
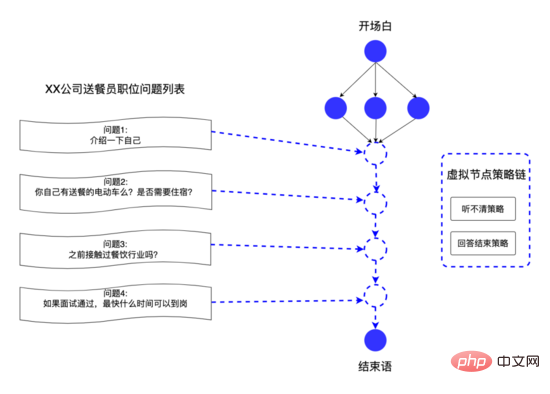
Grâce à la structure de données ci-dessus, la plate-forme système peut répondre rapidement aux besoins de personnalisation du discours du côté commercial. Par exemple, le recruteur peut personnaliser les questions pour chaque poste de recrutement. Nous résumons ces questions dans des nœuds virtuels dans le discours et utilisons le virtuel. bords pour connecter les nœuds virtuels Connectez-vous pour fournir des questions d'entretien personnalisées pour différents postes afin d'obtenir l'effet de milliers de personnes.
06 Pratique d'optimisation des performances des services
La salle d'entretien magique a obtenu de bons résultats après sa mise en ligne. Par conséquent, le côté commercial espère se développer rapidement. Le robot d'entretien IA doit prendre en charge plus d'un millier de personnes en ligne. en même temps. Par conséquent, nous partons de la gestion des ressources et de l'estimation des ressources. En nous concentrant sur quatre aspects, y compris les tests et la surveillance des performances, les performances du service de robot d'entretien IA ont été efficacement améliorées. le service optimisé pour recevoir des demandes d'entretien en même temps est 20 fois supérieur à celui d'avant optimisation.
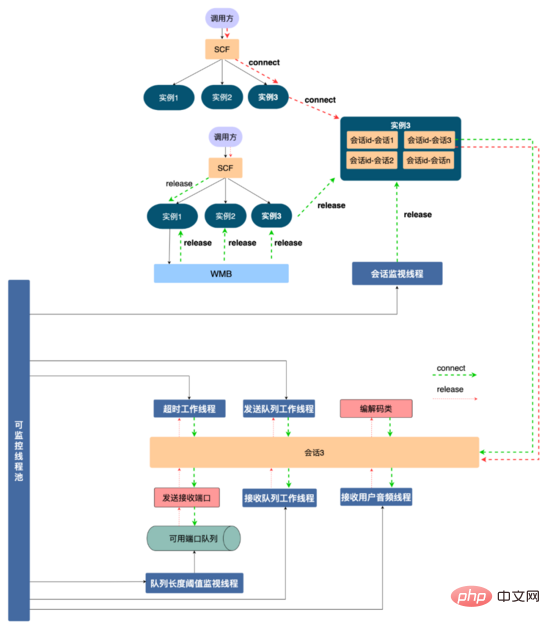
Solution de gestion des ressources : Afin de mieux gérer les ressources utilisées dans le service et d'éviter l'épuisement des ressources, nous avons conçu la solution de gestion des ressources comme indiqué ci-dessous. Tout d'abord, le robot d'interview IA et l'audio et la vidéo s'accordent sur un protocole de communication via SCF. Étant donné que SCF est équilibré en charge, la demande de l'appelant sera envoyée de manière aléatoire à une certaine machine du cluster. atteint l'instance de service 1. Le protocole de communication peut L'interaction de cette interview est liée à l'instance. Ensuite, le concept de session est abstrait (le niveau de code est une classe de session et chaque session est un thread Les ressources demandées). dans cette interview, comme les ports d'envoi et de réception, la programmation La classe de décodage et diverses ressources de thread sont enregistrées dans la session, et le code garantit que les ressources enregistrées sur la session seront libérées lorsque la session sera libérée. les entretiens vidéo réalisent l'isolation des ressources grâce à l'isolation des threads, facilitant ainsi la gestion des ressources.
Dans le même temps, l'instance de session est liée au conteneur de session via l'identifiant de session (convenu par l'appelant via le protocole de communication, qui est globalement unique). Lorsque l'utilisateur raccroche, SCF est appelé pour libérer des ressources. En raison du caractère aléatoire de SCF, la demande peut atteindre l'instance de service 3. Il n'y a pas de session d'entretien de ce type sur l'instance 3. Afin de libérer des ressources, nous utilisons WMB (Wuba Tongcheng). file d'attente de messages auto-développée) ) Diffusez ce message de libération de ressource, le corps du message contient l'identifiant de session, toutes les instances de service consommeront ce message, l'instance de service 1 contient l'identifiant de session, recherchez la session liée à l'identifiant de session, appelez la version de ressource fonction de la session, utilisera La ressource est libérée (les instances restantes rejetteront le message).
Si la demande de publication n'est pas exécutée pour une raison quelconque, le conteneur de session dispose d'un thread de surveillance de session qui peut analyser le cycle de vie de toutes les sessions dans le conteneur de session et définir un cycle de vie maximum pour la session (par exemple 10 minutes). Si la session expire, déclenchez activement le recyclage des ressources de session et libérez les ressources de session. Dans le même temps, pour les ressources limitées telles que les threads et les ports demandés dans la session, nous utilisons une gestion centralisée, utilisons le pool de threads pour gérer les threads de manière centralisée, mettons tous les ports disponibles dans une file d'attente et surveillons les ports restants dans la file d'attente. pour assurer la stabilité du service et sa disponibilité.
Estimation des ressources machine :
Ressources limitées |
Problèmes de goulot d'étranglement |
Ressources temporaires demandées par la session |
Si les ressources temporaires peuvent être recyclées à temps, telles que les ports, les threads, les codecs et autres ressources. |
Bande passante du réseau de la machine |
1000 Mo/s >> 2500 * 32 Ko/s |
Ressources du disque dur de la machine |
Stratégie d'élimination des problèmes personnalisés du commerçant |
Thread |
Indicateurs tels que la taille de la tâche, le temps d'exécution de la tâche et le nombre de threads créés dans la file d'attente du pool de threads |
Expérience de performances :
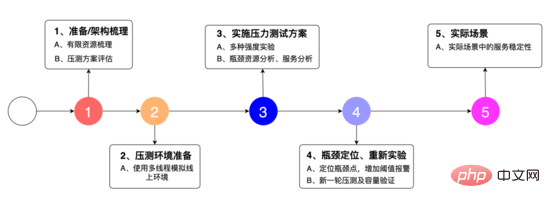
Nous avons conçu le plan expérimental comme indiqué dans l'image ci-dessus : 1. Pour trier l'architecture du système, découvrir les ressources limitées et organiser le plan de test de résistance 2. Utiliser la simulation multithread. lignes Sur l'environnement, 3. Il s'agit d'une variété de tests de résistance, d'analyses des ressources goulots d'étranglement et d'analyses des services. 4. Localisez les points de goulot d'étranglement, ajoutez des alarmes de seuil et retestez. 5. La stabilité du service dans des scénarios réels.
Stress test : nous avons ensuite effectué un test de stress et essayé divers tests de volume de requêtes de force. Lors de l'utilisation de 2 500 requêtes/min pour tester l'interface, nous avons constaté que le principal goulot d'étranglement du service est la mémoire tas du service. Comme vous pouvez le voir sur l'image ci-dessous, la mémoire tas du service atteint rapidement 100 % et l'interface ne répond plus. Après avoir vidé la mémoire tas, nous avons constaté qu'il y avait des centaines d'objets DialingInfo dans la mémoire tas. Chaque objet occupait 18,75 Mo. En regardant le code, nous pouvons voir que cet objet est utilisé pour stocker le contenu de la conversation entre l'IA. interviewer le robot et l'utilisateur.Les deux objets allRobotVoiceBuffer et allUserVoiceBuffer en occupent chacun la moitié. La taille de la mémoire de allRobotVoiceBuffer est destinée à stocker les informations vocales du robot (format de stockage : tableau d'octets), et allUserVoiceBuffer est destinée à stocker les informations vocales de l'utilisateur.
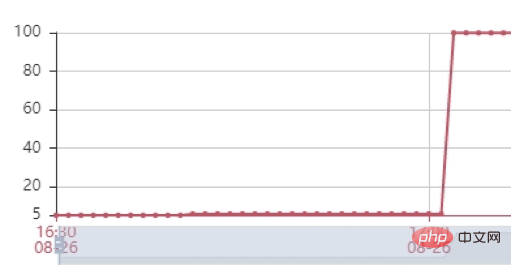
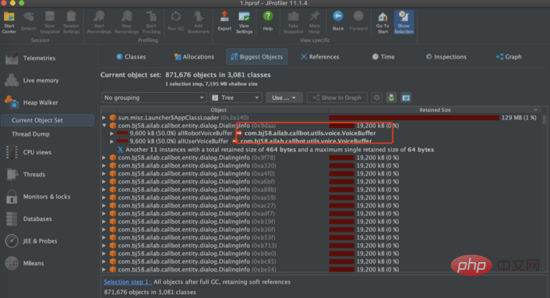
En regardant le code, vous pouvez constater que les deux objets allRobotVoiceBuffer et allUserVoiceBuffer occupent conjointement 18,75 Mo lors de l'initialisation du service (cette valeur est due au fait que 5 minutes de données audio doivent être stockées). Déterminez si la taille d'initialisation est raisonnable. En analysant les données d'appel historiques de Magic Interview Room, on peut voir que 63% des utilisateurs n'ont pas répondu à la première question du robot et ont directement raccroché l'interview. réduisez la taille de la mémoire initiale de ces deux objets et changez allRobotVoiceBuffer à 0,47 Mo (cette valeur est la taille de la première question audio du robot), allUserVoiceBuffer est de 0 Mo en même temps, puisque les deux objets allRobotVoiceBuffer et allUserVoiceBuffer peuvent être étendus en même temps. ms, si le contenu de la conversation dépasse la taille de l'objet, l'expansion peut être réalisée sans affecter le service. Après modification, nous utilisons toujours 2 500 minutes/demande, le service peut réaliser un garbage collection stable.
Surveillance fine :
Type d'indicateur |
Vue d'ensemble |
|
Indicateurs critiques de service | Volume de demande, volume de réussite, volume d'échec, Là Il y a 13 indicateurs tels que l'absence de port disponible |
Indicateurs de ressources |
La longueur de la file d'attente du port disponible est inférieure au seuil, les problèmes de personnalisation du cache dépassent le seuil, etc. 5 indicateurs |
Indicateurs de processus |
Échec de la construction des mots, échec de la livraison des informations clés, échec de la livraison du calendrier, etc. 52 indicateurs |
Indicateurs de suivi du pool de threads |
Nombre de fils de discussion demandés à créer, nombre de tâches en cours d'exécution, temps moyen des tâches 6 indicateurs |
Indicateurs de session de questions et réponses de position |
Exception dans l'obtention de réponses vocales, temps moyen d'échauffement des réponses, etc. 9 indicateurs |
Indicateurs ASR |
18 indicateurs dont la durée moyenne de reconnaissance vocale auto-développée, l'échec de reconnaissance auto-développé, etc. |
Indicateurs Vad |
nombre d'appels, consommation de temps maximale, etc . 4 indicateurs |
07 Résumé
Cet article présente principalement l'architecture back-end du robot d'entretien IA, l'ensemble du processus d'interaction entre le robot d'entretien IA et l'utilisateur, le noyau. fonctions du moteur de dialogue et pratiques d’optimisation des performances des services. À l'avenir, nous continuerons à soutenir l'itération fonctionnelle et l'optimisation des performances du projet Magic Interview Room, et à mettre en œuvre davantage le robot d'entretien IA dans différentes entreprises.
Références
1. RTP : un protocole de transport pour les applications en temps réel A rejoint 58.com en décembre 2016 et est actuellement principalement engagé dans des travaux de R&D back-end liés à l'interaction vocale. Diplômé d'une maîtrise de l'Université de technologie de Chine du Nord en 2016. Il a travaillé chez Bianlifeng et China Electronics, engagé dans le développement back-end.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI