
Maison >développement back-end >Tutoriel Python >Python explore les données du film Douban et extrait les modules de valeur XPath et LXML (code)
Python explore les données du film Douban et extrait les modules de valeur XPath et LXML (code)

- 不言avant
- 2018-09-28 14:45:343941parcourir
Ce que cet article vous apporte concerne l'exploration par Python des données du film Douban et l'extraction des valeurs des modules XPath et LXML (code). Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer. aide.
Outils : Python 3.6.5, outils de développement PyCharm, système d'exploitation Windows 10, Google Chrome
Objectif : explorer le titre, l'adresse du lien du film dans le classement des films Douban, Photos, nombre de critiques, notes, etc.
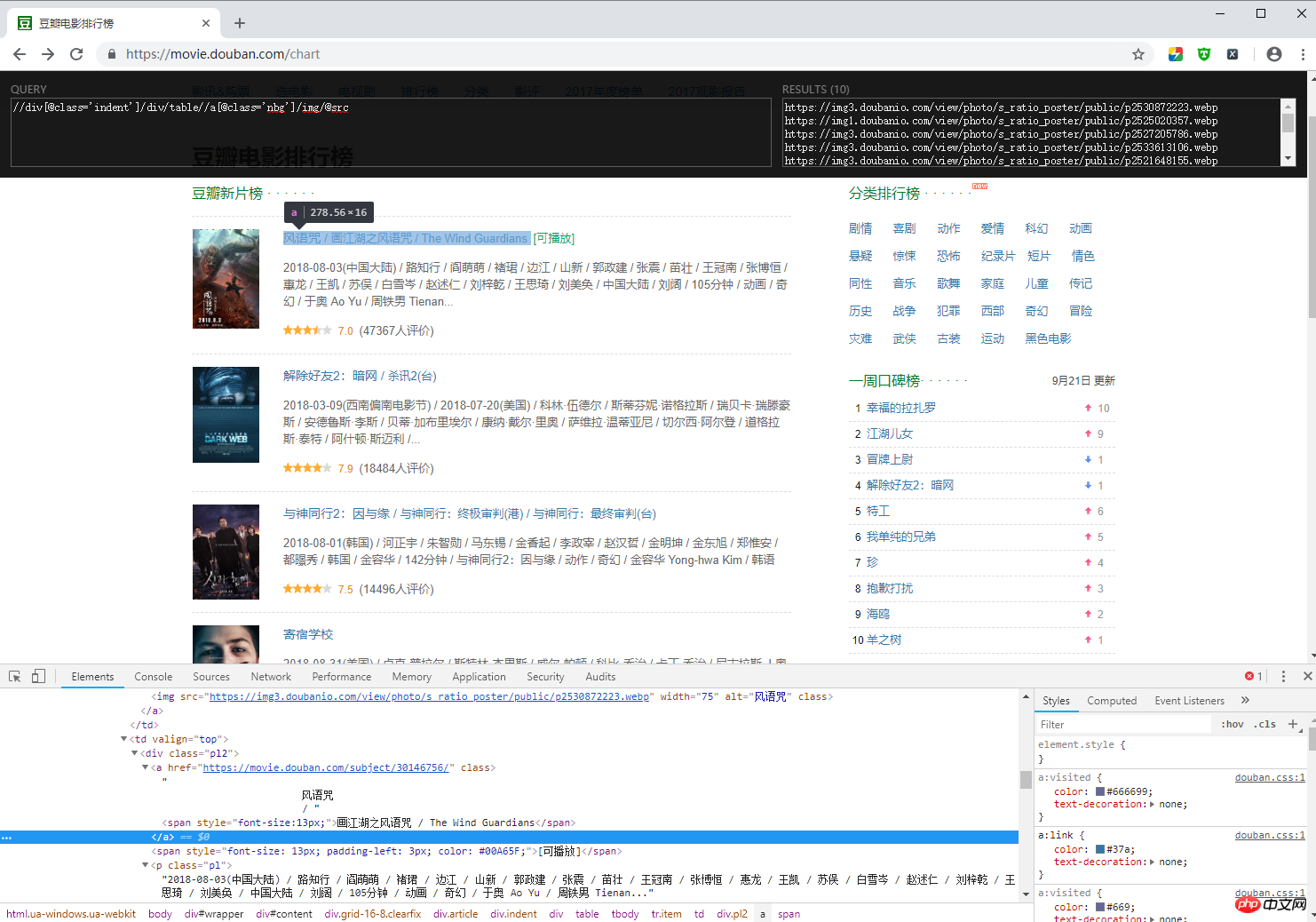
Site Web : https://movie.douban.com/chart
Points de grammaire :
Syntaxe xpath :
Google Chrome installe le plug-in XPath Helper : Aidez-nous à localiser les données des éléments
1 Sélectionnez le nœud (étiquette)
(1. ), /html/ head/meta : peut sélectionner toutes les balises méta sous html
(2), //li : toutes les balises li de la page actuelle
(3), /html/head//link : Toutes les balises de lien sous l'en-tête
2 // : Vous pouvez sélectionner à partir de n'importe quel nœud
(1), //li : Toutes les balises li de la page actuelle
(2), /html/head//link : head Toutes les balises de lien sous
3. Le but du symbole @
(1) Sélectionnez un élément spécifique : //p[ @class ='feed']/ul/li, sélectionnez li sous ul sous p de class='feed'
(2), a/@href : Sélectionnez la valeur href d'un
4. Obtenez le texte
( 1), /a/text() : Récupère le texte sous un
(2), /a//text() : Récupère tout le texte sous un Text
Exemple :
Syntaxe lxml :
1 Installation : pip install lxml
2. >
depuis lxml import etree
element = etree.HTML("chaîne html")
element.xpath("")
Code :
from lxml import etree
import requests
url = "https://movie.douban.com/chart"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"
}
response = requests.get(url,headers=headers)
html_str = response.content.decode()
#print(html_str)
html = etree.HTML(html_str)
print(html)
#1.获取所有的电影的URL地址
#url_list = html.xpath("//div[@class='indent']/div/table//div[@class='pl2']/a/@href")
#print(url_list)
#2.所有图片的地址
#img_list = html.xpath("//div[@class='indent']/div/table//a[@class='nbg']/img/@src")
#print(img_list)
ret1 = html.xpath("//div[@class='indent']/div/table")
print(ret1)
for table in ret1:
item = {}
item["title"] = table.xpath(".//div[@class='pl2']/a/text()")[0].replace("/","").strip()
item["href"] = table.xpath(".//div[@class='pl2']/a/@href")[0]
item["img"] = table.xpath(".//a[@class='nbg']/img/@src")[0]
item["comment_num"] = table.xpath(".//span[@class='pl']/text()")[0]
item["rating_num"] = table.xpath(".//span[@class='rating_nums']/text()")[0]
print(item)Effet de fonctionnement :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Exemple du processus d'exploration de la musique qq avec Python
- Tutoriel d'exemple d'article d'exploration Python
- Méthode d'exploration Python pour le partage de données sur le site Web de logements d'occasion d'Anjuke
- Prendre l'exemple de la récupération des commentaires Taobao pour expliquer comment Python analyse dynamiquement les données générées par ajax (classique)