
Maison >développement back-end >Tutoriel Python >Exemple du processus d'exploration de la musique qq avec Python
Exemple du processus d'exploration de la musique qq avec Python

- 零下一度original
- 2017-07-18 15:28:284254parcourir
1. Avant-propos
Il y a encore beaucoup de musique sur qq music. Parfois, j'ai envie de télécharger de la bonne musique, mais. Il y a un processus de connexion ennuyeux à chaque fois lors du téléchargement à partir d’une page Web. Voici donc un robot d'exploration qqmusic. Au moins, je pense que la chose la plus importante pour un robot d'exploration de boucles for est de trouver l'URL de l'élément à explorer. Commencez à regarder ci-dessous (ne vous moquez pas de moi si je me trompe)
<br>
2. Python explore les singles musicaux QQ.
Une vidéo du MOOC que j'ai regardée auparavant donnait une bonne explication des étapes générales pour écrire un robot. Nous suivrons également cela.
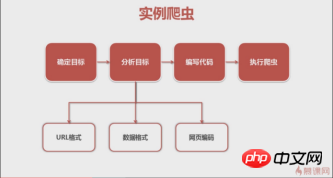
Étapes du robot
1. Déterminer la cible
Tout d'abord, nous devons clarifier notre objectif. Cette fois, nous avons exploré les singles du chanteur de QQ Music Andy Lau.
(Encyclopédie Baidu) -> Cible d'analyse (stratégie : format d'url (plage), format de données, encodage de page Web) -> Écrire du code ->
2. Cible d'analyseLien de la chanson :
À partir de la capture d'écran de gauche, vous pouvez savoir que les célibataires utilisent la pagination pour organiser les informations sur la chanson. 30 articles, un total de 30 pages. En cliquant sur le numéro de page ou sur le ">" à l'extrême droite, vous passerez à la page suivante. Le navigateur enverra une requête ajax asynchrone au serveur. À partir du lien, vous pouvez voir les paramètres start et num, qui représentent le. respectivement l'indice de départ de la chanson (la capture d'écran est la 2ème page, l'indice de départ est 30) et une page renvoie 30 éléments, et le serveur répond en renvoyant les informations de la chanson au format json (MusicJsonCallbacksinger_track({"code":0,"data": {"list":[{"Flisten_count1":. .....]})), si vous souhaitez simplement obtenir des informations sur la chanson uniquement, vous pouvez directement fusionner la demande de lien et analyser les données au format json renvoyées. Ici, nous n'utilisons pas la méthode d'analyse directe du format de données. J'utilise la méthode Python Selenium. Une fois que chaque page d'informations uniques est obtenue et analysée, cliquez sur ">" pour passer à la page suivante et continuer l'analyse jusqu'à ce que toutes les informations soient trouvées. est analysée et enregistrée. Enfin, demandez le lien de chaque single pour obtenir des informations détaillées sur chaque single. 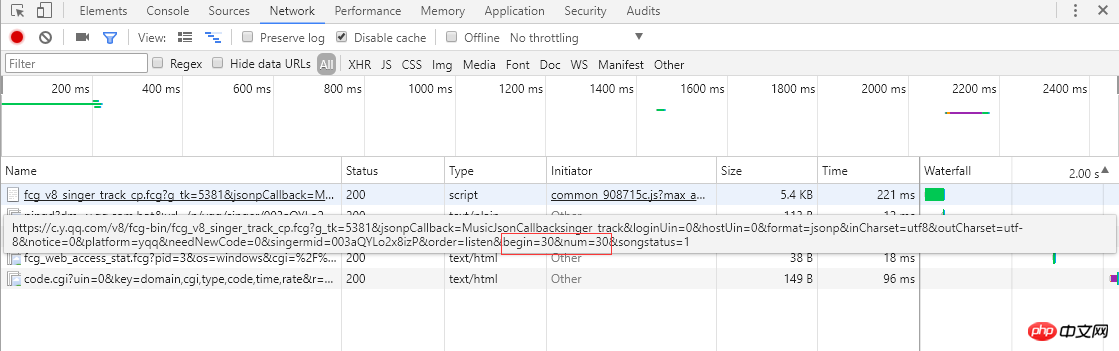
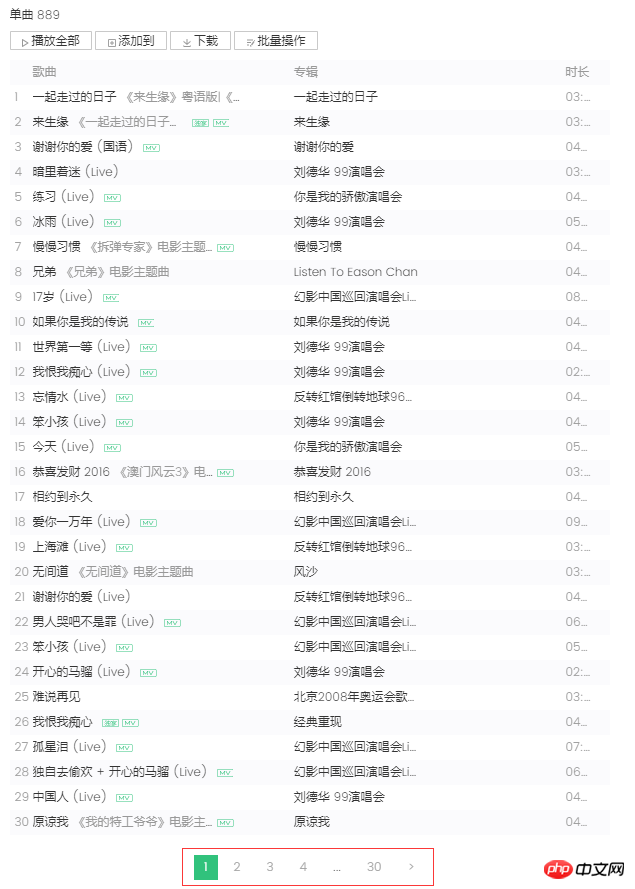
1. ) Téléchargez le contenu de la page Web. Ici, nous utilisons la bibliothèque standard Urllib de Python et encapsulons une méthode de téléchargement :
def download(url, user_agent='wswp', num_retries=2):
if url is None:
return None
print('Downloading:', url)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
request = urllib.request.Request(url, headers=headers) # 设置用户代理wswp(Web Scraping with Python)
try:
html = urllib.request.urlopen(request).read().decode('utf-8')
except urllib.error.URLError as e:
print('Downloading Error:', e.reason)
html = None
if num_retries > 0:
if hasattr(e, 'code') and 500 <= e.code < 600:
# retry when return code is 5xx HTTP erros
return download(url, num_retries-1) # 请求失败,默认重试2次,
return html2) Analyser le contenu de la page Web. plug-in de fête BeautifulSoup, Pour plus de détails, veuillez vous référer à l'API BeautifulSoup. <br>
def music_scrapter(html, page_num=0):
try:
soup = BeautifulSoup(html, 'html.parser')
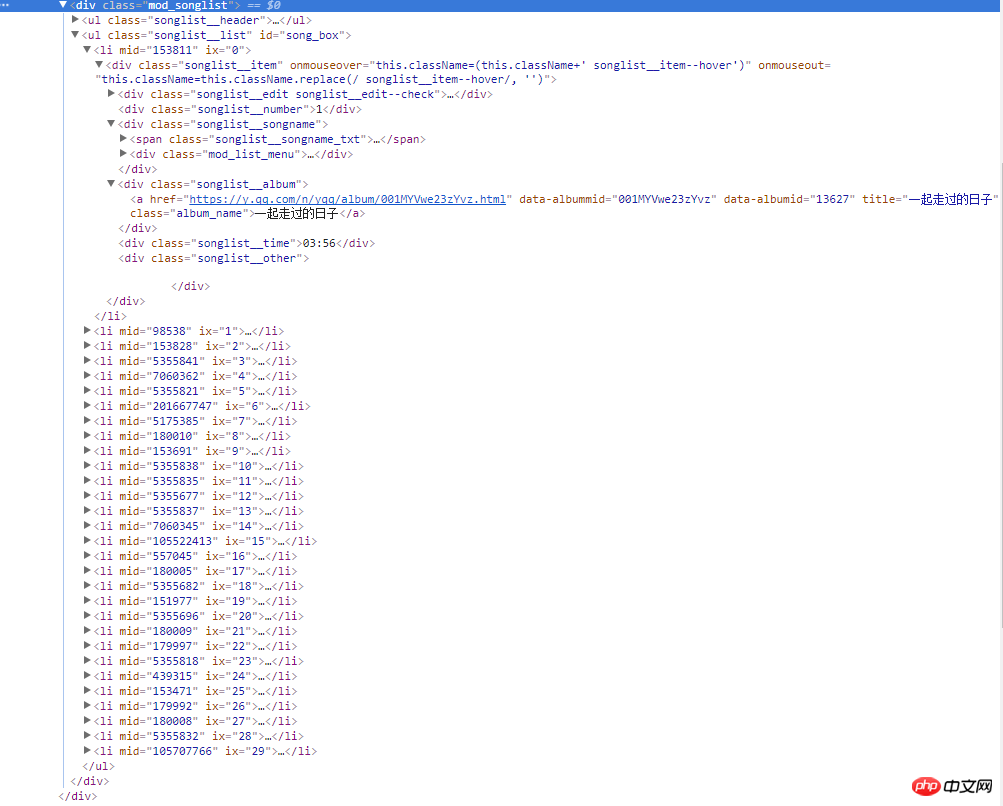
mod_songlist_div = soup.find_all('div', class_='mod_songlist')
songlist_ul = mod_songlist_div[1].find('ul', class_='songlist__list')
'''开始解析li歌曲信息'''
lis = songlist_ul.find_all('li')
for li in lis:
a = li.find('div', class_='songlist__album').find('a')
music_url = a['href'] # 单曲链接
urls.add_new_url(music_url) # 保存单曲链接
# print('music_url:{0} '.format(music_url))
print('total music link num:%s' % len(urls.new_urls))
next_page(page_num+1)
except TimeoutException as err:
print('解析网页出错:', err.args)
return next_page(page_num + 1)
return None
def get_music():
try:
while urls.has_new_url():
# print('urls count:%s' % len(urls.new_urls))
'''跳转到歌曲链接,获取歌曲详情'''
new_music_url = urls.get_new_url()
print('url leave count:%s' % str( len(urls.new_urls) - 1))
html_data_info = download(new_music_url)
# 下载网页失败,直接进入下一循环,避免程序中断
if html_data_info is None:
continue
soup_data_info = BeautifulSoup(html_data_info, 'html.parser')
if soup_data_info.find('div', class_='none_txt') is not None:
print(new_music_url, ' 对不起,由于版权原因,暂无法查看该专辑!')
continue
mod_songlist_div = soup_data_info.find('div', class_='mod_songlist')
songlist_ul = mod_songlist_div.find('ul', class_='songlist__list')
lis = songlist_ul.find_all('li')
del lis[0] # 删除第一个li
# print('len(lis):$s' % len(lis))
for li in lis:
a_songname_txt = li.find('div', class_='songlist__songname').find('span', class_='songlist__songname_txt').find('a')
if 'https' not in a_songname_txt['href']: #如果单曲链接不包含协议头,加上
song_url = 'https:' + a_songname_txt['href']
song_name = a_songname_txt['title']
singer_name = li.find('div', class_='songlist__artist').find('a').get_text()
song_time =li.find('div', class_='songlist__time').get_text()
music_info = {}
music_info['song_name'] = song_name
music_info['song_url'] = song_url
music_info['singer_name'] = singer_name
music_info['song_time'] = song_time
collect_data(music_info)
except Exception as err: # 如果解析异常,跳过
print('Downloading or parse music information error continue:', err.args)4. Exécuter le robot
<span style="font-size: 16px;">爬虫跑起来了,一页一页地去爬取专辑的链接,并保存到集合中,最后通过get_music()方法获取单曲的名称,链接,歌手名称和时长并保存到Excel文件中。</span><br><span style="font-size: 14px;"><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/001/a1138f33f00f8d95b52fbfe06e562d24-4.png" class="lazy" alt="" style="max-width:90%" style="max-width:90%"><strong><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/001/9282b5f7a1dc4a90cee186c16d036272-5.png" class="lazy" alt=""></strong></span>3. crawler Obtenez le résumé des singles de QQ Music
<br>
1 Le single utilise la pagination. Passer à la page suivante consiste à obtenir des données au format json du serveur via une requête ajax asynchrone et. le restituer aux pages et aux liens de la barre d'adresse du navigateur reste inchangé et ne peut pas être demandé via des liens épissés. Au début, j'ai pensé à simuler des requêtes ajax via la bibliothèque Python Urllib, mais j'ai ensuite pensé à utiliser Selenium. Selenium peut très bien simuler le fonctionnement réel du navigateur, et le positionnement des éléments de la page est également très pratique. Il simule un clic sur la page suivante, en changeant constamment de pagination unique, puis en analysant le code source de la page Web via BeautifulSoup pour obtenir l'unique. information.
Le gestionnaire de liens 2.url utilise une structure de données de collection pour enregistrer des liens uniques. Pourquoi utiliser des collections ? Étant donné que plusieurs singles peuvent provenir du même album (l'URL de l'album est la même), cela peut réduire le nombre de demandes.
class UrlManager(object):<br> def __init__(self):<br> self.new_urls = set() # 使用集合数据结构,过滤重复元素<br> self.old_urls = set() # 使用集合数据结构,过滤重复元素3. Il est très pratique de lire et d'écrire Excel via le plug-in tiers Python
def add_new_url(self, url):<br> if url is None:<br> return<br> if url not in self.new_urls and url not in self.old_urls:<br> self.new_urls.add(url)<br><br> def add_new_urls(self, urls):<br> if urls is None or len(urls) == 0:<br> return<br> for url in urls:<br> self.add_new_url(url)<br><br> def has_new_url(self):<br> return len(self.new_urls) != 0<br><br> def get_new_url(self):<br> new_url = self.new_urls.pop()<br> self.old_urls.add(new_url)<br> return new_url<br><br>openpyxl
, et les informations uniques. peut être bien enregistré via des fichiers Excel debout.
4. Post-scriptumdef write_to_excel(self, content):<br> try:<br> for row in content:<br> self.workSheet.append([row['song_name'], row['song_url'], row['singer_name'], row['song_time']])<br> self.workBook.save(self.excelName) # 保存单曲信息到Excel文件<br> except Exception as arr:<br> print('write to excel error', arr.args)<br><br>
Enfin, je dois célébrer. Après tout, j'ai réussi à explorer les informations uniques de QQ Music. Supprimé. Cette fois, nous avons réussi à explorer le single, Selenium était indispensable. Cette fois, nous n'avons utilisé que quelques fonctions simples de Selenium. Nous en apprendrons davantage sur Selenium à l'avenir, non seulement en termes de robots d'exploration mais également d'automatisation de l'interface utilisateur.
Points qui doivent être optimisés à l'avenir :
1 Il existe de nombreux liens de téléchargement, et il sera lent à télécharger un par un. utilisez le téléchargement simultané multithread plus tard.
2. La vitesse de téléchargement est trop rapide. Afin d'éviter que le serveur désactive l'IP et le problème des accès trop fréquents au même nom de domaine par la suite, il existe un mécanisme d'attente, et il y a une attente entre chaque intervalle de demande.
3. L'analyse des pages Web est un processus important. Les expressions régulières, BeautifulSoup et lxml peuvent être utilisées. Actuellement, la bibliothèque BeautifulSoup est utilisée. comme lxml. Ce qui suit va essayer d'utiliser lxml.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!