
Maison >développement back-end >Tutoriel Python >Méthode d'exploration Python pour le partage de données sur le site Web de logements d'occasion d'Anjuke
Méthode d'exploration Python pour le partage de données sur le site Web de logements d'occasion d'Anjuke

- 小云云original
- 2018-01-09 13:20:283763parcourir
Cet article vous propose principalement un article Python pour explorer les données du site de logements anciens d'Anjuke (explication avec exemples). L'éditeur pense que c'est plutôt bien, alors je vais le partager avec vous maintenant et le donner comme référence. Suivons l'éditeur pour y jeter un œil, j'espère que cela pourra aider tout le monde.
Commençons maintenant la rédaction officielle du robot d'exploration. Tout d'abord, nous devons analyser la structure du site Web à explorer : en tant qu'étudiant du Henan, jetons un coup d'œil aux informations sur les logements d'occasion à Zhengzhou ! 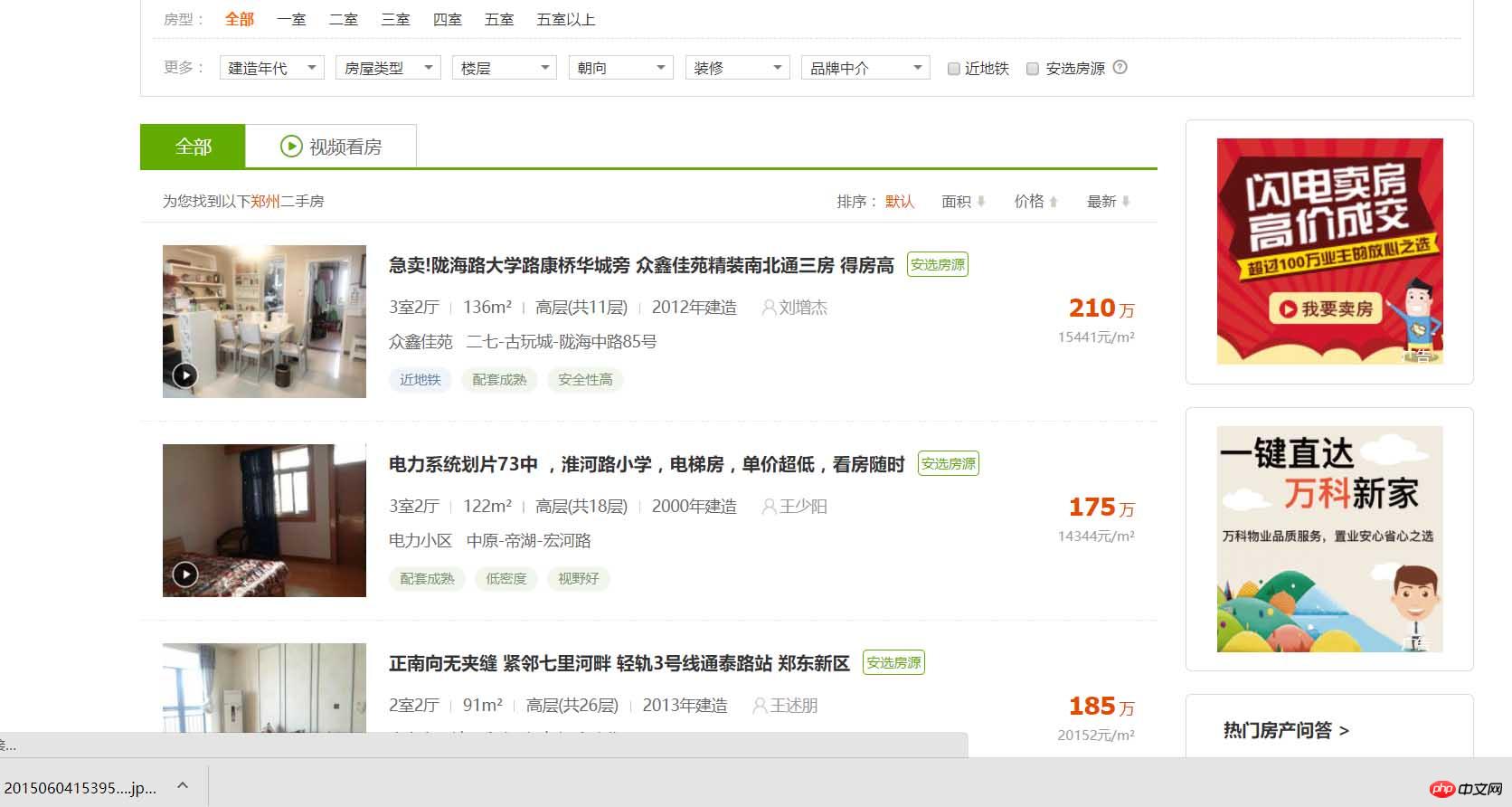
Dans la page ci-dessus, nous pouvons voir les informations sur la propriété une par une. À partir de ce qui précède, nous pouvons voir les informations sur la propriété une par une sur la page Web. Vous y trouverez :
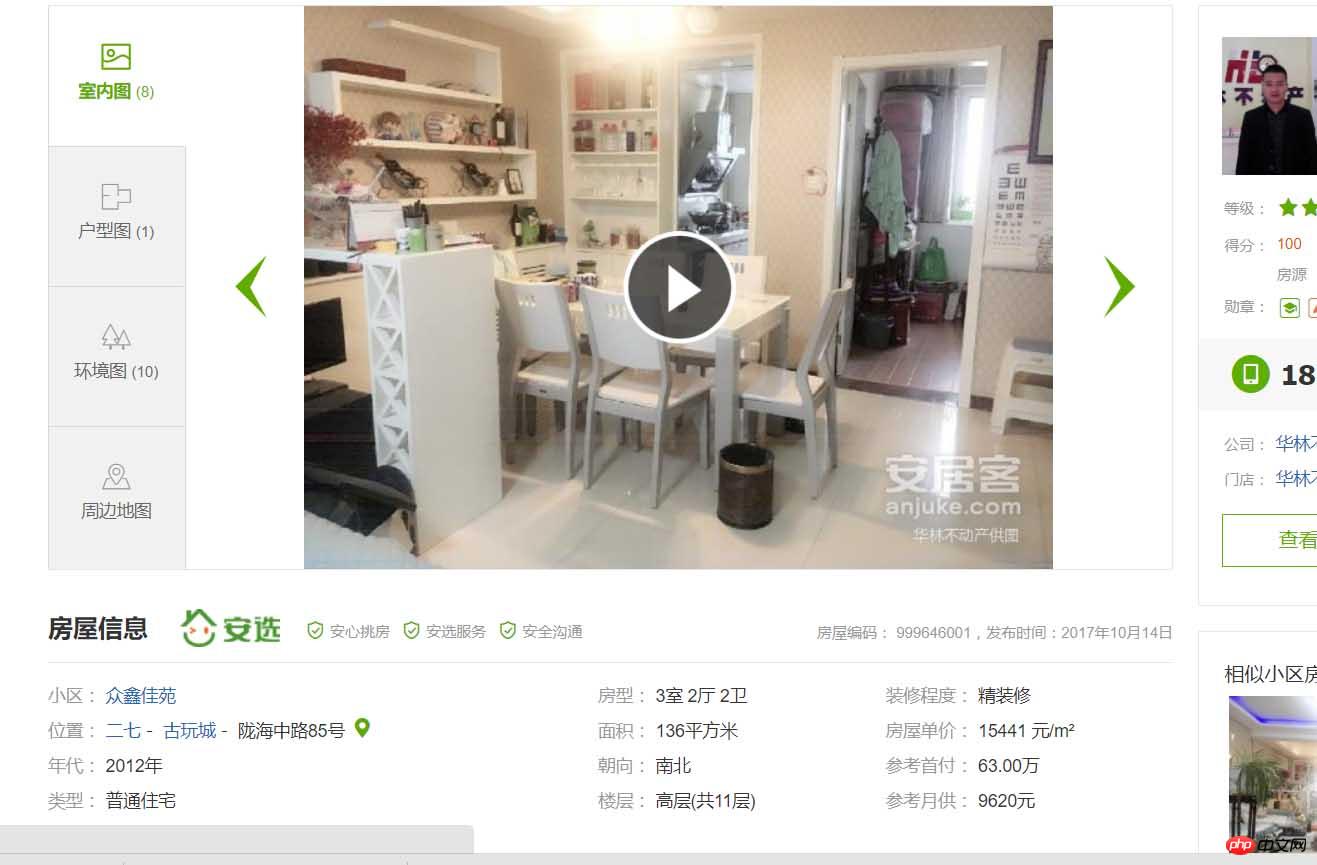
Détails de la propriété. D'ACCORD! Alors qu'allons-nous faire ? C'est-à-dire obtenir toutes les informations sur les logements d'occasion à Zhengzhou et les enregistrer dans la base de données. À quoi servent-elles en tant que géographe, je n'entrerai pas dans les détails. cette fois. D'accord, commençons officiellement. Tout d'abord, j'utilise les modules requêtes et BeautifulSoup dans python3.6 pour explorer la page. Tout d'abord, le module requêtes fait la requête :
# 网页的请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
# url链接
url = 'https://zhengzhou.anjuke.com/sale/'
response = requests.get(url, headers=header)
print(response.text)exécution Ensuite, vous obtiendrez le code html de ce site
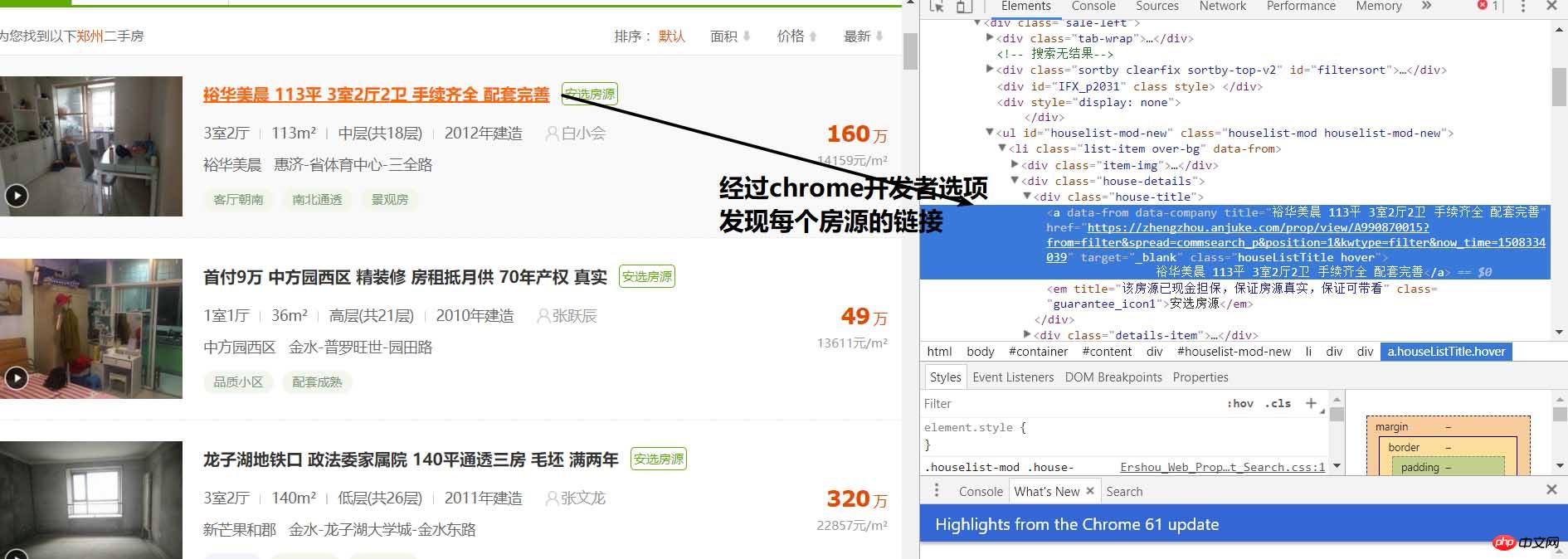 Grâce à l'analyse, nous pouvons obtenir que chaque maison est dans la balise li de class="list-item" , alors nous pouvons l'utiliser selon BeautifulSoup Extraire le package
Grâce à l'analyse, nous pouvons obtenir que chaque maison est dans la balise li de class="list-item" , alors nous pouvons l'utiliser selon BeautifulSoup Extraire le package 
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup = BeautifulSoup(response.text, 'html.parser')
result_li = soup.find_all('li', {'class': 'list-item'})
for i in result_li:
print(i) peut réduire encore la quantité de code en imprimant, d'accord, continuez à extraire
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup = BeautifulSoup(response.text, 'html.parser')
result_li = soup.find_all('li', {'class': 'list-item'})
# 进行循环遍历其中的房源详细列表
for i in result_li:
# 由于BeautifulSoup传入的必须为字符串,所以进行转换
page_url = str(i)
soup = BeautifulSoup(page_url, 'html.parser')
# 由于通过class解析的为一个列表,所以只需要第一个参数
result_href = soup.find_all('a', {'class': 'houseListTitle'})[0]
print(result_href.attrs['href'])De cette façon, nous pouvons voir les URL une par une. Vous n'aimez pas ça 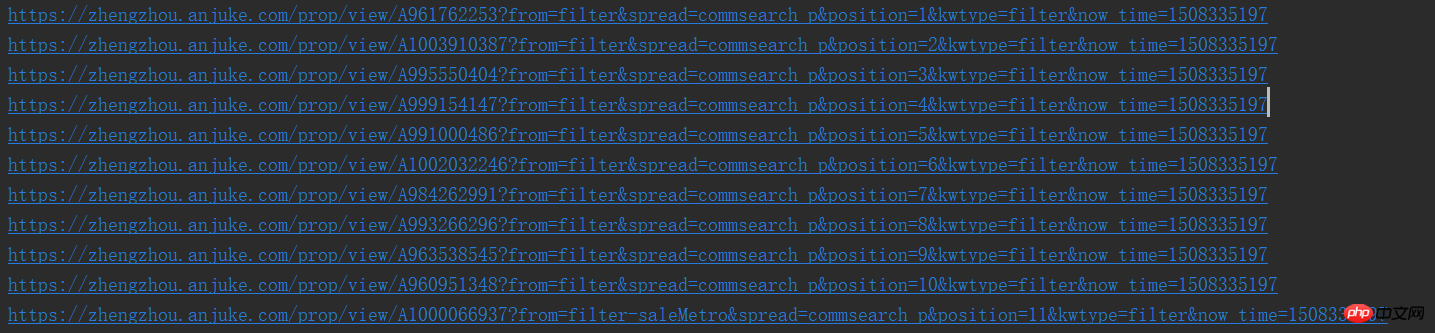
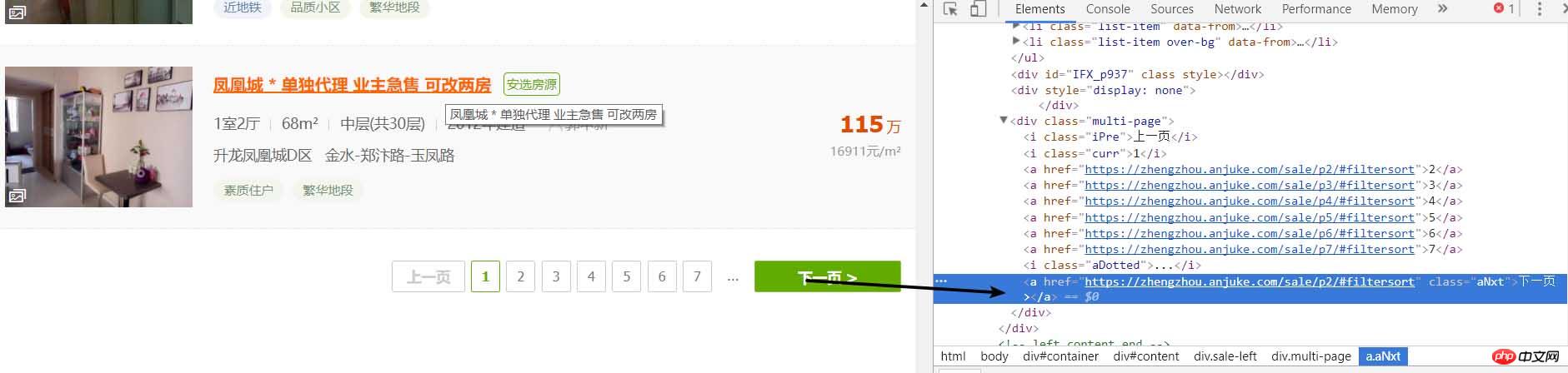
# 进行下一页的爬取
result_next_page = soup.find_all('a', {'class': 'aNxt'})
if len(result_next_page) != 0:
print(result_next_page[0].attrs['href'])
else:
print('没有下一页了') Parce que quand il y a la page suivante, il y a une balise a dans la page Web, sinon, elle deviendra une balise i, donc cela fera l'affaire. Par conséquent, nous pouvons l'améliorer et encapsuler ce qui précède dans une fonction . import requests
from bs4 import BeautifulSoup
# 网页的请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
def get_page(url):
response = requests.get(url, headers=header)
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup = BeautifulSoup(response.text, 'html.parser')
result_li = soup.find_all('li', {'class': 'list-item'})
# 进行下一页的爬取
result_next_page = soup.find_all('a', {'class': 'aNxt'})
if len(result_next_page) != 0:
# 函数进行递归
get_page(result_next_page[0].attrs['href'])
else:
print('没有下一页了')
# 进行循环遍历其中的房源详细列表
for i in result_li:
# 由于BeautifulSoup传入的必须为字符串,所以进行转换
page_url = str(i)
soup = BeautifulSoup(page_url, 'html.parser')
# 由于通过class解析的为一个列表,所以只需要第一个参数
result_href = soup.find_all('a', {'class': 'houseListTitle'})[0]
# 先不做分析,等一会进行详细页面函数完成后进行调用
print(result_href.attrs['href'])
if __name__ == '__main__':
# url链接
url = 'https://zhengzhou.anjuke.com/sale/'
# 页面爬取函数调用
get_page(url) Bon alors commençons à parcourir les pages détaillées Hé, le courant va être coupé à chaque tournant, quel piège dans l'université, je' Je joindrai d'abord les résultats, j'en ajouterai d'autres quand je serai libre,
import requests
from bs4 import BeautifulSoup
# 网页的请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
def get_page(url):
response = requests.get(url, headers=header)
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup_idex = BeautifulSoup(response.text, 'html.parser')
result_li = soup_idex.find_all('li', {'class': 'list-item'})
# 进行循环遍历其中的房源详细列表
for i in result_li:
# 由于BeautifulSoup传入的必须为字符串,所以进行转换
page_url = str(i)
soup = BeautifulSoup(page_url, 'html.parser')
# 由于通过class解析的为一个列表,所以只需要第一个参数
result_href = soup.find_all('a', {'class': 'houseListTitle'})[0]
# 详细页面的函数调用
get_page_detail(result_href.attrs['href'])
# 进行下一页的爬取
result_next_page = soup_idex.find_all('a', {'class': 'aNxt'})
if len(result_next_page) != 0:
# 函数进行递归
get_page(result_next_page[0].attrs['href'])
else:
print('没有下一页了')
# 进行字符串中空格,换行,tab键的替换及删除字符串两边的空格删除
def my_strip(s):
return str(s).replace(" ", "").replace("\n", "").replace("\t", "").strip()
# 由于频繁进行BeautifulSoup的使用,封装一下,很鸡肋
def my_Beautifulsoup(response):
return BeautifulSoup(str(response), 'html.parser')
# 详细页面的爬取
def get_page_detail(url):
response = requests.get(url, headers=header)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# 标题什么的一大堆,哈哈
result_title = soup.find_all('h3', {'class': 'long-title'})[0]
result_price = soup.find_all('span', {'class': 'light info-tag'})[0]
result_house_1 = soup.find_all('p', {'class': 'first-col detail-col'})
result_house_2 = soup.find_all('p', {'class': 'second-col detail-col'})
result_house_3 = soup.find_all('p', {'class': 'third-col detail-col'})
soup_1 = my_Beautifulsoup(result_house_1)
soup_2 = my_Beautifulsoup(result_house_2)
soup_3 = my_Beautifulsoup(result_house_3)
result_house_tar_1 = soup_1.find_all('dd')
result_house_tar_2 = soup_2.find_all('dd')
result_house_tar_3 = soup_3.find_all('dd')
'''
文博公寓,省实验中学,首付只需70万,大三房,诚心卖,价可谈 270万
宇泰文博公寓 金水-花园路-文博东路4号 2010年 普通住宅
3室2厅2卫 140平方米 南北 中层(共32层)
精装修 19285元/m² 81.00万
'''
print(my_strip(result_title.text), my_strip(result_price.text))
print(my_strip(result_house_tar_1[0].text),
my_strip(my_Beautifulsoup(result_house_tar_1[1]).find_all('p')[0].text),
my_strip(result_house_tar_1[2].text), my_strip(result_house_tar_1[3].text))
print(my_strip(result_house_tar_2[0].text), my_strip(result_house_tar_2[1].text),
my_strip(result_house_tar_2[2].text), my_strip(result_house_tar_2[3].text))
print(my_strip(result_house_tar_3[0].text), my_strip(result_house_tar_3[1].text),
my_strip(result_house_tar_3[2].text))
if __name__ == '__main__':
# url链接
url = 'https://zhengzhou.anjuke.com/sale/'
# 页面爬取函数调用
get_page(url)Depuis que j'écrivais du code en bloguant, j'ai apporté quelques modifications dans la get_page fonction, c'est-à-dire que l'appel récursif pour la page suivante doit être placé après la fonction et encapsulé. Les deux fonctions ne sont pas introduites, et les données ne sont pas écrites sur mysql, je vais donc continuer à suivre plus tard, merci !!!Recommandations associées : Tutoriel d'exemple d'article d'exploration Python
10 articles recommandés sur Python crawling
Partager un crawl Python Comment faire des commentaires populaires sur NetEase Cloud Music
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!