
Maison >développement back-end >Tutoriel Python >Tutoriel d'exemple d'article d'exploration Python
Tutoriel d'exemple d'article d'exploration Python
- 巴扎黑original
- 2017-08-07 17:37:451966parcourir
Cet article vous présente principalement les informations pertinentes sur l'utilisation de Python pour explorer des articles sur un site Web en prose. L'introduction de l'article est très détaillée et a une certaine valeur de référence et d'apprentissage pour tous les amis qui en ont besoin peuvent y jeter un œil ci-dessous.
Cet article vous présente principalement le contenu pertinent sur les articles du réseau de prose d'exploration Python. Il est partagé pour votre référence et votre étude. Jetons un coup d'œil à l'introduction détaillée :
<.>Le rendu est le suivant :

Configurer python 2.7
bs4 requestsInstaller à l'aide de pip
sudo pip install bs4
sudo pip install requestsUne brève explication de l'utilisation de bs4. Puisqu'il explore des pages Web, j'ai une brève explication de l'utilisation de bs4. présentera find et find_all. La différence entre find et find_all est que ce qui est renvoyé est différent. Find renvoie la première balise correspondante et le contenu de la balise find_all renvoie une liste
Par exemple, nous écrivons un test.html pour tester la différence entre find et find_all.
Le contenu est :
<html> <head> </head> <body> <p id="one"><a></a></p> <p id="two"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >abc</a></p> <p id="three"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a></p> <p id="four"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >four<p>four p</p><p>four p</p><p>four p</p> a</a></p> </body> </html>
from bs4 import BeautifulSoup import lxml if __name__=='__main__': s = BeautifulSoup(open('test.html'),'lxml') print s.prettify() print "------------------------------" print s.find('p') print s.find_all('p') print "------------------------------" print s.find('p',id='one') print s.find_all('p',id='one') print "------------------------------" print s.find('p',id="two") print s.find_all('p',id="two") print "------------------------------" print s.find('p',id="three") print s.find_all('p',id="three") print "------------------------------" print s.find('p',id="four") print s.find_all('p',id="four") print "------------------------------"
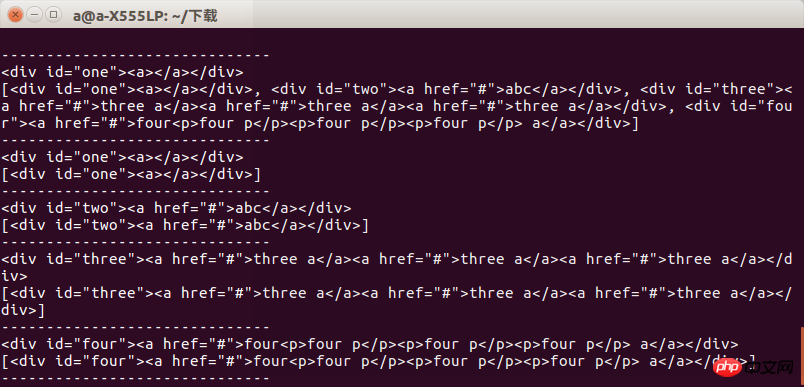
Nous devons donc faire attention à ce que nous voulons lors de son utilisation, sinon une erreur se produira
L'étape suivante. est d'obtenir des informations sur la page Web via des demandes. Je ne comprends pas très bien les autres. Pourquoi écrire entendu et autres choses
J'accède directement à la page Web, j'obtiens plusieurs pages Web secondaires classées de Prose Network ? via la méthode get, puis passez un test de groupe pour explorer toutes les pages Web
def get_html():
url = "https://www.sanwen.net/"
two_html = ['sanwen','shige','zawen','suibi','rizhi','novel']
for doc in two_html:
i=1
if doc=='sanwen':
print "running sanwen -----------------------------"
if doc=='shige':
print "running shige ------------------------------"
if doc=='zawen':
print 'running zawen -------------------------------'
if doc=='suibi':
print 'running suibi -------------------------------'
if doc=='rizhi':
print 'running ruzhi -------------------------------'
if doc=='nove':
print 'running xiaoxiaoshuo -------------------------'
while(i<10):
par = {'p':i}
res = requests.get(url+doc+'/',params=par)
if res.status_code==200:
soup(res.text)
i+=i. ce n'est pas 200. Le problème qui en résulte est que l'erreur ne sera pas affichée et que le contenu analysé sera perdu. Ensuite, j'ai analysé la page Web de Sanwen.net/rizhi/&p=1res.status_code
La valeur maximale de p est de 10. Je ne comprends pas. La dernière fois que j'ai exploré le disque, il y avait 100 pages. . Oubliez-le et analysez-le plus tard. Récupérez ensuite le contenu de chaque page via la méthode get.
Après avoir obtenu le contenu de chaque page, vous analysez l'auteur et le titre. Le code est comme ça
def soup(html_text): s = BeautifulSoup(html_text,'lxml') link = s.find('p',class_='categorylist').find_all('li') for i in link: if i!=s.find('li',class_='page'): title = i.find_all('a')[1] author = i.find_all('a')[2].text url = title.attrs['href'] sign = re.compile(r'(//)|/') match = sign.search(title.text) file_name = title.text if match: file_name = sign.sub('a',str(title.text))
La dernière étape consiste à obtenir le contenu en prose. Grâce à l'analyse de chaque page, nous obtenons l'adresse de l'article, puis obtenons directement le contenu. Je voulais à l'origine l'obtenir un par un en le modifiant. l'adresse Web, ce qui évite des ennuis.
def get_content(url): res = requests.get('https://www.sanwen.net'+url) if res.status_code==200: soup = BeautifulSoup(res.text,'lxml') contents = soup.find('p',class_='content').find_all('p') content = '' for i in contents: content+=i.text+'\n' return content
f = open(file_name+'.txt','w') print 'running w txt'+file_name+'.txt' f.write(title.text+'\n') f.write(author+'\n') content=get_content(url) f.write(content) f.close()
f = open(file_name+'.txt','w') print 'running w txt'+file_name+'.txt' f.write(title.text+'\n') f.write(author+'\n') content=get_content(url) f.write(content) f.close()
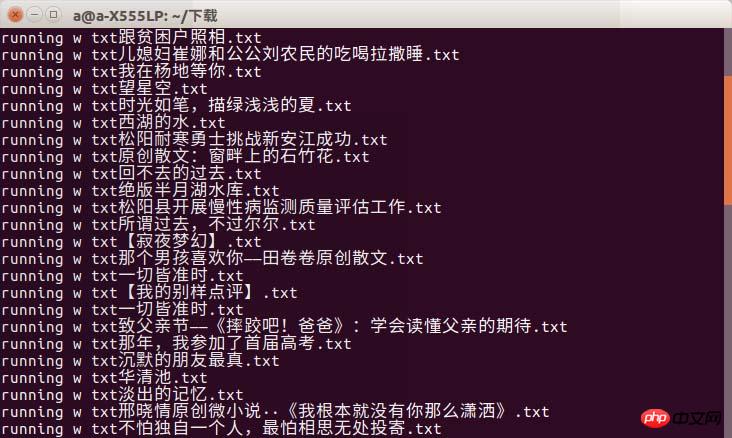
Il peut y avoir un phénomène de timeout. Je peux seulement dire que vous devez choisir une bonne connexion Internet lorsque vous allez à l'université !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!