


User profiling algorithms: history, current situation and future

1. Introduction to user portraits
A portrait is a structured description of the user that is understandable by humans and readable and written by machines. It not only provides personalized services, but also plays an important role in the company's strategic decision-making and business analysis.
1. Classification of portraits
According to the data source, it is divided into social general knowledge category and domain knowledge category. General social portraits can be divided into static and dynamic categories according to the time dimension. The most common static general social portraits include demographic characteristics, such as gender, household registration, graduation school, etc. These contents are displayed over a relatively long period of time. The windows are relatively static. In addition to using it in pictures, it is also often used in demography, demography, sociology, etc. Dynamic social general portraits are more important, also known as life stage portraits. For example, e-commerce, people's income will continue to change with career development, and their shopping tendencies will also change, so these life stage portraits It is of great practical value.
In addition to the above-mentioned general portraits, companies may build more domain knowledge portraits. Domain knowledge portraits can be divided into semi-static and dynamic from the time dimension, and can be further subdivided into long-term, cyclical, short-term and future attribute portraits. These time dimension portraits are entangled with conceptual fields, which include behavioral models, interest models, and intention models.
The behavioral model mainly tracks users’ cyclical behaviors, such as what users do during their commute every morning, what they do after get off work in the evening, what they do during the week, and what they do on weekends. What to wait for some cyclical behavior. The interest model performs a certain joint modeling and sorting of tags within domain knowledge. For example, users can obtain some operation logs after interacting with platform products such as APPs. The logs can be correlated and parsed to extract some structured and labeled data. We They can be divided into categories, given a certain weight, and finally sorted to form a certain interest profile. It should be noted that the intention model is more of a future tense and is a prediction of the user's future intention. But how to predict the possible intentions of new users before they interact? This problem is more biased towards real-time and future portraits, and also has higher requirements for the overall infrastructure structure of portrait data.

2. User portrait basic application architecture
After understanding the concept and general classification of images, Next, we briefly introduce the basic application framework of user portraits. The entire framework can be divided into four levels. The first is data collection, the second is data preprocessing, the third is the construction and updating of portraits based on these processed data, and finally the application layer. A usage protocol is defined in the application layer to allow downstream users to Various applications can use images more conveniently, quickly and efficiently.
We can find from this framework that user profiling applications and user profiling algorithms need to understand a particularly broad and complex connotation, because what we face is not only simple, label It requires various preprocessing methods to obtain high-quality data, and then build a more confident portrait. This will involve various aspects such as data mining, machine learning, knowledge graphs, and statistical learning. The difference between user portraits and traditional search recommendation algorithms is that we need to work closely with domain experts to continuously build higher-quality portraits in iterations and cycles.

## 2. Traditional users based on ontology Portrait
User portrait is a concept established through in-depth analysis of user behavior data and information. By understanding users’ interests, preferences and behavior patterns, we can better provide users with personalized services and experiences.
In the early days, user portraits mainly relied on knowledge graphs, which originated from the concept of ontology. Ontology, on the other hand, belongs to the category of philosophy. First of all, the definition of ontology is very similar to the definition of portrait. It is a conceptual system that is understandable by humans and readable and writable by machines. Of course, the complexity of this conceptual system itself can be very high. It is composed of entities, attributes, relationships and axioms. The advantage of user portraits based on Ontology is that it is easy to classify users and content, and it is convenient to produce data reports that can be intuitively understood by humans, and then make decisions based on the relevant conclusions of the reports. This is why this method is chosen in the non-deep learning era. A technical form.
Next, we will introduce some basic concepts in Ontology. To build an Ontology, you must first conceptualize domain knowledge, that is, construct entities, attributes, relationships, and axioms, and process them into machine-readable formats, such as RDF and OWL. Of course, you can also use some simpler data formats, or even degenerate Ontology into a relational database or graph database that can store, read, write, and analyze data. The way to obtain this kind of portrait is generally to build it through domain experts, or to enrich and refine it based on some existing industry standards. For example, the product labeling system adopted by Taobao actually draws on the country’s public standards for various manufacturing commodity industries, and enriches and iterates on this basis.

The following figure is a very simple Ontology example, which contains 3 nodes. The entity in the figure is an interest tag in the entertainment field. For example, there are many movies on platforms such as Netflix. Each movie has a unique ID, and each movie has its own attributes, such as title and starring role. This entity also belongs to a crime-themed series, and a crime series Belongs to a subgenre of action movies. Based on this visual diagram, we write an RDF text document as shown on the right side of the figure below. In this document, in addition to the entity attribute relationships that we can intuitively understand, some axioms are also defined, such as the constraint that "has title" can only act on For the basic conceptual domain of movies, if there are other conceptual domains, such as using the director of the movie as an entity to build it into the Ontology, the movie director cannot have the attribute "has title". The above is a brief introduction to ontology.

In the early days of user profiling based on ontology, a method similar to TF-IDF was used to calculate the weight of the constructed structured tags. . TF-IDF was mainly used in the search field or text subject field in the past. It mainly calculated the weight of a certain search term or subject word. When applied to user portraits, it only needs to be slightly restricted and deformed, such as in the previous example. TF is to count the number of movies or short videos that users watch under this category of tags. IDF is to first count the number of movies or short videos that users watch under each category of tags and the total number of all historical views, and then calculate it according to the formula in the figure. IDF and TF *IDF. The calculation method of TF-IDF is very straightforward and stable, and it is also interpretable and easy to use.
But its shortcomings are also obvious: TF-IDF is very sensitive to tag granularity, but is insensitive to the ontology structure itself. It may overemphasize unpopular interests and In situations that lead to trivial solutions, for example, if a user only occasionally watches a certain video under a certain tag, TF will be very small and IDF will be extremely large. TF-IDF may become a value close to its popular interests. More importantly, we need to update and adjust user portraits over time, and the traditional TF-IDF method is not suitable for this situation. Therefore, researchers have proposed a new method to directly construct weighted user portraits based on ontology's structured expression to meet the needs of dynamic updates.

This algorithm starts from the leaf category of Ontology, uses the user's media consumption behavior under the corresponding label to update the weight. The weight is initialized to 0, and then proceeds based on the fbehavior function defined by the user's behavior. renew. The fbehavior function will give different implicit feedback signals based on the different levels of user consumption, such as clicks, additional purchases and orders in the e-commerce field, or playback and completion in the video field. At the same time, we will also give feedback signals of different strengths to different user behaviors. For example, in e-commerce consumption behavior, ordering > purchasing > clicks, in video consumption, higher playback completion, higher playback duration, etc. A stronger fbehavior value will also be set.
After the leaf class target signature weight is updated, the parent class weight needs to be updated. It should be noted that when updating the parent class, an attenuation coefficient less than 1 needs to be defined. Because, as shown in the figure, users may be interested in the subcategory of "World War II" in "War", but may not be interested in other war themes. This attenuation coefficient can be customized as a hyperparameter. This definition emphasizes the equality of the contribution of each subcategory's interest to the parent category. The reciprocal of the number of subcategory labels can also be used as the attenuation coefficient, so that more emphasis is placed on niche interests. Interest, for example, some large parent category nodes contain subcategory themes that are broad and not closely related. The audience between them depends on the number of works. Usually, the number of such works will be very large, and the decay speed can be set appropriately to be faster. , and the smaller sub-category labels may be of some niche interests and there are not many works. The relationship between the sub-category topics will be relatively close, and the attenuation speed can be set appropriately to be smaller. In short, we can set the attenuation coefficient based on these domain knowledge attributes defined in Ontology.

The above method can achieve the update effect of structured tags, and it can basically equal or even surpass the TF-IDF effect, but it lacks one Time scale attribute, that is, how to construct a portrait that is more sensitive to time scale.
We first thought that we could further adjust the update of the weight itself. When you need to distinguish long-term and short-term user portraits, you can add a sliding window to the weight and define a time decay coefficient a (between 0-1). The function of the sliding window is to only focus on user behavior within the window period, and do not focus on the user behavior before the window. The reason is that the user's long-term interests will also change slowly with the change of life stage. For example, the user may like a certain type of movie for one or two years, and then no longer like it.
In addition, you may also observe that this formula is similar to the Adam gradient update method that drives momentum. We adjust the size of a to make the weight update more focused to a certain extent. in history or the present. Specifically, when given a smaller a, it will focus more on the present, and then the historical accumulation will have a greater attenuation.

The above methodologies are limited to the information that the user has received, but we usually encounter a large number of tags being lost. , as well as user cold start or situations where the user may not be exposed to this type of content but it does not mean that the user does not like it. In these cases, interest completion and interest inference are required.
The most basic method is to use collaborative filtering in the recommendation system to complete the portrait. Suppose there is a label matrix. The horizontal axis is the user and the vertical axis is each label. This is a very large matrix. The elements inside are the user's interest in this tag. These elements can be 0 or 1, or they can be interest weights. Of course, this matrix can also be transformed to adapt to the demographic portrait. For example, the label can be expressed as whether it is a student, or whether it is a professional, or what kind of occupation, etc. You can also use a coding method to construct this matrix. You can also apply matrix decomposition to obtain matrix decomposition, and then complete the missing eigenvalues. At this time, the optimization goal is as shown in the figure below.
As you can see from this formula, the original matrix is M, the completion matrix is It may be close, and we also hope that X is a low-rank matrix, because we assume that the interests of a large number of users are similar. Under the assumption of similar users, the label matrix must be low-rank. Finally, regularize this matrix Complete the goal of non-negative matrix factorization. This method can actually be solved using the stochastic gradient descent method we are most familiar with.

Of course, in addition to using matrix decomposition to infer missing attributes or interests, traditional machine learning methods can also be used. It is still assumed that similar users will have similar interests. At this time, KNN classification or regression can be used to infer interests. The specific method is to establish the user's nearest neighbor relationship map, and then add the tags or tags with the largest number of neighbors among the user's k nearest neighbors. The weighted mean is assigned to the user's missing attributes. The neighbor relationship graph can be built by yourself, or it can be a ready-made neighbor graph structure, such as the user portrait of a social network, or the business portrait of the B-side - the enterprise map.

The above is an introduction to Ontology’s construction of traditional portraits. The value of the traditional portrait construction algorithm is that it is very simple, direct, easy to understand, and easy to implement. At the same time, its effect is good, so it will not be completely replaced by higher-order algorithms, especially when we need to debug the portrait. A class of traditional algorithms will have greater convenience.
##3. Profiling Algorithm & Deep Learning
1 . The value of deep learning algorithms to profiling algorithms
After entering the era of deep learning, everyone hopes to further improve the effect of profiling algorithms by combining deep learning algorithms. What is the value of deep learning to profiling algorithms?
First of all, there must be stronger user representation capabilities. In the field of deep learning and machine learning, there is a special category - representation learning, or metric learning, this learning method It can help us build very powerful user representations. The second is a simpler modeling process. We can use the end-to-end approach of deep learning to simplify the modeling process. In many cases, we only need to construct features, do some feature engineering, and then treat the neural network as a black box. Features are input and labels or other supervision information are defined at the output without paying attention to the details.
Again, based on the powerful expression ability of deep learning, we have also achieved higher accuracy in many tasks. Then, deep learning can also uniformly model multi-modal data. In the era of traditional algorithms, we need to spend a lot of energy on data preprocessing. For example, the extraction of video type tags mentioned above requires very complex preprocessing. First, cut off the video, then extract the subject, and then identify the faces in it one by one. Add the corresponding tags, and finally build the portrait. With deep learning, when you want a unified user or item expression, you can directly process multi-modal data end-to-end.
Finally, we want to reduce costs as much as possible during iterations. As mentioned in the previous article, the difference between the iteration of the profiling algorithm and the iteration of other types of algorithms such as search promotion is that it requires a lot of manual participation. Sometimes the most reliable data is the data that is annotated by people, or collected through questionnaires and other methods. The cost of obtaining this data is quite high, so how to obtain data with more annotation value at a lower cost? This problem also has more ideas and solutions in the era of deep learning.

2. Structured label prediction based on deep learning
C-HMCNN is an Ontology structure It is a classic deep learning method for label prediction. It is not a fancy network structure, but defines an algorithm framework suitable for labels, especially for structured label classification or prediction.
The core is to flatten hierarchical structured labels and then predict them. As shown on the right side of the figure below, the network directly gives the prediction probabilities of the three labels A\B\C , there is no need to consider the level, depth, etc. of the structure. Its Loss formula design can also punish results that violate structured tags as much as possible. The formula first uses the classic cross-entropy Loss for leaf categories B and C, and max(yB for parent categories pB, yCpC) to constrain the structural information, and only predict the parent category A when the subcategory is predicted to be true, using 1- max(pB, pC) to express, when the parent class target label is false, the prediction of the sub-category is forced to be as close to 0 as possible, thereby achieving structured Label constraints. The advantage of this modeling is that calculating Loss is very simple. It predicts all labels equally and can almost ignore the depth information of the label tree.
The last thing to mention is that this method requires each label to be 0 or 1. For example, PB only represents the user's like or dislike, and cannot be set to a multiple category. Because multi-class LOSS constraints are more difficult to establish, the model is equivalent to flattening all labels when modeling, and then making predictions of 0 and 1. One problem that may arise from flattening is that when the parent label in the label tree structure has a large number of sub-labels, it will face a very large-scale multi-label classification problem. The general way to deal with it is to use some means to filter out in advance the user may not be aware of it. Interest tags.

3. Lookalike based on representation learning
In the application of user portraits, lookalike Thoughts are often used. In portrait downstream applications, lookalike can be used to target potential user groups for advertisements. Lookalike can also be used to find some users who are missing target attributes based on seed users, and then the corresponding missing attributes of these users can be replaced or expressed with seed users.
What the application of Lookalike needs most is a powerful representation learner. As shown in the figure below, there are three types of representation modeling methods that are most commonly used.
The first is a multi-classification method. If we have multiple classification label portrait data, we can learn more targeted representations with supervised signals, targeting what we want. The representations trained to predict a certain class of labels are very valuable for directional label missing predictions.
The second is the AE (auto encoder) paradigm. The model structure is in an hourglass form. There is no need to pay attention to supervision information, but only need to find an encoding mode and encode the user first. , and then perform information compression and representation in the middle waist area. This paradigm is more reliable when there is not enough supervision data.
The third is the graph paradigm. At present, graph networks such as GNN and GCN are used in more and more fields, including in portraits, and GNN can be based on maximum likelihood. The method performs unsupervised training, and can also perform supervised training with label information, and is better than the multi-classification paradigm. Because in addition to expressing label information, the graph structure can also embed more graph structure information. When there is no displayed graph structure, there are many ways to construct a graph. For example, swing i2i, a well-known recommendation algorithm in the e-commerce field, constructs a bipartite graph based on users' joint purchases or joint viewing records. Such graph structures are also very rich. The semantic information can help us learn better user representations. After we have rich representations, we can select some seed users to use nearest neighbor search to expand the circle, and then use the expanded users to infer the missing tags, or target.

It is very easy to perform nearest neighbor retrieval on small-scale applications, but on extremely large-scale data, such as hundreds of millions of months On a large platform with active users, KNN retrieval for these users is a very time-consuming task. Therefore, the most commonly used method at present is approximate nearest neighbor retrieval. Its characteristic is to exchange accuracy for efficiency, while ensuring an accuracy of close to 99%. The time is compressed to 1/1000, 1/10000, or even 1/100000 of the original violent search.
Currently, the effective methods of approximate nearest neighbor retrieval are vector retrieval algorithms based on graph indexes. These methods have been pushed to a climax in the current era of large models, that is, some time ago One of the most popular concepts in large models is RAG (Retrieval Enhancement Generation). The core method adopted by retrieval enhancement for text retrieval is vector retrieval. The most commonly used method is graph-based vector retrieval. The most widely used methods include HNSW, NSG and SSG, the original open source code and implementation links of the latter two are also shown in the figure below.

4. Portrait iteration based on active learning
In the process of portrait iteration, still There are some blind spots that cannot be covered. For example, there are some user profiles with low consumption behavior that cannot be well positioned. In the end, many methods will still fall back to manual collection. However, we have so many low-activity users. If we can only select more valuable and representative users for labeling, we can collect more valuable data. Therefore, we have introduced an active learning framework. Implementing low-cost portrait iteration on uncertain learning.
Firstly, based on the existing annotated data, a classification model with uncertainty prediction is trained. The method used is the classic method in the field of probabilistic learning-Bayesian network. The characteristic of Bayesian network is that when predicting, it can not only give the probability, but also predict the uncertainty of the prediction result.
Bayesian network is very easy to implement, as shown on the right side of the figure below. Just add some special layers to the original network structure. We add some drop out in the middle of these networks. layer to randomly discard some parameters of the feedforward network. The Bayesian network contains multiple sub-networks, each of which has exactly the same network parameters. However, due to the characteristics of the dropout layer, the probability of each network parameter being randomly dropped is different when randomly dropped. Finally, the network is trained for inference. Drop out is also retained when using drop out, which is different from how drop out is used in other fields. In other fields, drop out is only performed during training, and all parameters are applied during inference. Only when the logit and probability values are finally calculated, the scale doubling of a predicted value caused by drop out is restored.
The difference between Bayesian networks is that all drop out randomness must be retained during feedforward inference, so that each network will give a different probability of this label , and then find the mean of this set of probabilities. This mean is actually the result of a vote and the probability value we want to predict. At the same time, we calculate the variance of this set of probability values to express the uncertainty of the prediction. . When a sample undergoes different drop out parameter expressions, the final probability value obtained is different. The greater the variance of the probability value, the smaller the probability certainty in the learning process. Finally, label prediction samples with high uncertainty can be manually labeled, and for labels with high certainty, the results of machine labeling can be directly used. Then keep returning to the first step of the active learning framework to cycle. The above is the basic framework of active learning.

5. Portrait annotation/prediction based on large model world knowledge
In the era of large models, World knowledge of large models can also be introduced for portrait annotation. The following figure gives two simple examples. On the left, a large model is used to annotate user portraits, and the user's viewing history is organized in a certain sequence to form a prompt. You will see that the large model can provide a very detailed analysis, such as What genres, directors, actors, etc. the user may like. On the right is a large model that analyzes the title of a product and gives the product title for the large model to guess which category it belongs to.
Here we have discovered that a big problem is that the output of the large model is unstructured, a relatively primitive text expression, and requires some post-processing. For example, it is necessary to perform entity recognition, relationship recognition, rule mining, entity alignment, etc. on the output of a large model, and these post-processing belong to the basic application rules in the category of knowledge graph or ontology.
Why does using the world knowledge of a large model for portrait annotation have better results, and can even replace part of the labor force? Because large models are trained on a wide range of open network knowledge, while recommendation systems, search engines, etc. only have some historical interaction data between users and product libraries in their own closed platforms. These data are actually ID-based. System logs, many of which are interrelated, are difficult to interpret through the closed knowledge in the existing platform, but the world knowledge of the large model can help us fill in the knowledge that is missing in the closed system, thereby helping us to draw a better portrait labeling or prediction. The large model can even be understood as a high-quality abstract depiction of the conceptual system of the world itself. These conceptual systems are very suitable for portraits and labeling systems.

#4. Summary and Outlook
Finally, let’s briefly summarize the current limitations of user portraits and the future development direction.
The first question is how to further improve the accuracy of the existing portraits. The factors that hinder the improvement of accuracy include the following aspects. The first is the unification from virtual ID to natural person. In reality, a user has multiple devices to log in to the same account, and may also have multiple ports and multiple channels to log in. For example, a user Log in to different APPs, but these APPs belong to the same group. Can we connect natural persons within the group, map all virtual IDs to the same person, and then identify it?
The second is the issue of subject identification for family shared accounts. This problem is very common in the video field, especially in the field of long videos. We often encounter some bad cases. For example, the user is obviously an adult around 40 years old, but the recommendations are all cartoons. In fact, a family shares an account, and everyone Personal interests are different. In response to this situation, can we use some means to identify the current time and behavior patterns, so as to update the portrait quickly and in real time, then determine who the current subject is, and then provide targeted personalized services.
The third is real-time intention prediction in multi-scenario linkage. We found that when the platform has developed to a certain stage, its search and promotion images are still relatively fragmented. For example, sometimes a user has just stepped into a recommended scene and is now ready to search. Can we give a better one based on the real-time intention of the recommended scene just now? If you search for recommended words, or have just searched for something, can you use this intent to spread and predict some other categories of things that the user may want to see, and do intent prediction.
The transition from closed ontology to open ontology is also an issue that needs to be solved urgently in the field of imaging. For a long time, some relatively solid industry standards were used to define ontology, but now the ontology of many systems is completely open to incremental updates, such as short video platforms, and the various tags of short videos themselves. Users and platforms continue to grow and explode spontaneously under the joint creation. There are many hot words and hot tags that continue to emerge as time goes by. How to improve the timeliness of images on open Ontology, remove noise, and then explore more and use some methods to help us improve the accuracy of images is also a question worth studying.
Finally, in the era of deep learning, how to improve interpretability in profiling algorithms, especially profiling algorithms that apply deep learning, and how to better enable large models to be used in profiling implemented in the algorithm, these will be the directions of future research.

The above is the content shared this time, thank you all!
5. Q & A
#Q1: The link between portrait processing and practical application is very long. The acceptance effect of AB test in actual business There may be many questions. Does Mr. Fu Cong have any experience to share in the AB test of portraits?
A1: The application link for portraits is indeed relatively long. If your portrait mainly serves algorithms, then there is indeed a gap in accuracy loss from the accuracy of the portrait to the downstream models. I actually don’t particularly recommend doing the portrait AB test. I think a better way to apply it is to go to the operators, and use it in user selection and advertising fixed investment and other application scenarios that are more operational in nature, such as coupons for big sales. Conduct AB Test in scenarios such as targeted delivery. Because their effects are directly based on your portrait, you can consider this kind of application-side collaborative online AB test with a relatively short link. In addition, I might suggest that in addition to AB test, we also consider another test method - cross-validation, to recommend to a user the sorting results based on the images before and after optimization, and then let the user evaluate which one is better. For example, we can now see that some large model manufacturers will let the model output two results, and then let users decide which large model produces better text. In fact, I think cross-checking like this may be more effective, and it is directly related to the portrait itself.
Q2: Is there drop out on the Bayesian network test set?
A2: It does not mean that there is drop out on the test set, but it means that when we test inference, we will still retain the random characteristics of drop out in the network for random inference. .
Q3: Considering privacy and security issues, how to use the results of large models when customer data cannot be exported.
A3: Frankly speaking, there is currently no very good solution in the industry. But there may be two ways. One is to consider a mutually trusted third party to do the inference deployment of localized large models. Another, and also a recent, new concept is called federated network, which is not federated learning. You can take a look at some of the possibilities contained in federated networks.
Q4: In addition to labeling, are there any other combinations you can mention when combined with large models?
A4: In addition to annotation, there is also some analysis and reasoning from users. Based on existing portraits, we can infer the user's next intention, or we can collect a large amount of user data and use a large model to analyze some regional or other user patterns under constraints. In fact, there are some open source demos for this, you can explore this direction.
The above is the detailed content of User profiling algorithms: history, current situation and future. For more information, please follow other related articles on the PHP Chinese website!

 What is Data Formatting in Excel? - Analytics VidhyaApr 14, 2025 am 11:05 AM
What is Data Formatting in Excel? - Analytics VidhyaApr 14, 2025 am 11:05 AMIntroduction Handling data efficiently in Excel can be challenging for analysts. Given that crucial business decisions hinge on accurate reports, formatting errors can lead to significant issues. This article will help you und
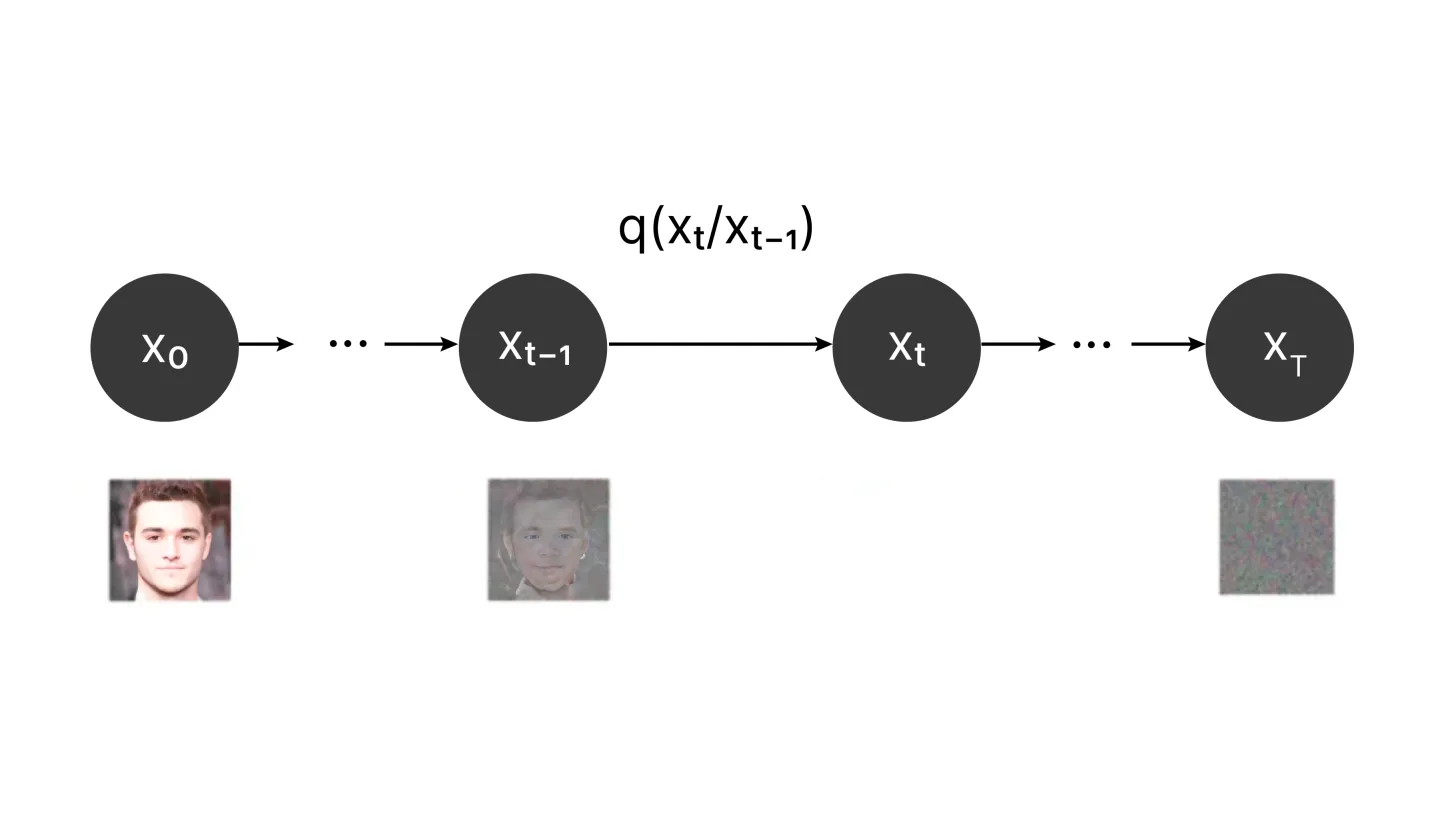 What are Diffusion Models?Apr 14, 2025 am 11:00 AM
What are Diffusion Models?Apr 14, 2025 am 11:00 AMDive into the World of Diffusion Models: A Comprehensive Guide Imagine watching ink bloom across a page, its color subtly diffusing until a captivating pattern emerges. This natural diffusion process, where particles move from high to low concentrati
 What is Heuristic Function in AI? - Analytics VidhyaApr 14, 2025 am 10:51 AM
What is Heuristic Function in AI? - Analytics VidhyaApr 14, 2025 am 10:51 AMIntroduction Imagine navigating a complex maze – your goal is to escape as quickly as possible. How many paths exist? Now, picture having a map that highlights promising routes and dead ends. That's the essence of heuristic functions in artificial i
 A Comprehensive Guide on Backtracking AlgorithmApr 14, 2025 am 10:45 AM
A Comprehensive Guide on Backtracking AlgorithmApr 14, 2025 am 10:45 AMIntroduction The backtracking algorithm is a powerful problem-solving technique that incrementally builds candidate solutions. It's a widely used method in computer science, systematically exploring all possible avenues before discarding any potenti
 5 Best YouTube Channels to Learn Statistics for FreeApr 14, 2025 am 10:38 AM
5 Best YouTube Channels to Learn Statistics for FreeApr 14, 2025 am 10:38 AMIntroduction Statistics is a crucial skill, applicable far beyond academia. Whether you're pursuing data science, conducting research, or simply managing personal information, a grasp of statistics is essential. The internet, and especially distance
 AvBytes: Key Developments and Challenges in Generative AI - Analytics VidhyaApr 14, 2025 am 10:36 AM
AvBytes: Key Developments and Challenges in Generative AI - Analytics VidhyaApr 14, 2025 am 10:36 AMIntroduction Hey there, AI enthusiasts! Welcome to The AV Bytes, your friendly neighborhood source for all things AI. Buckle up, because this week has been a wild ride in the world of AI! We’ve got some mind-blowing stuff t
 Self Hosting RAG Applications On Edge Devices with LangchainApr 14, 2025 am 10:35 AM
Self Hosting RAG Applications On Edge Devices with LangchainApr 14, 2025 am 10:35 AMIntroduction In the second part of our series on building a RAG application on a Raspberry Pi, we’ll expand on the foundation we laid in the first part, where we created and tested the core pipeline. In the first part, we crea
 Cursor AI: Why You Should Try It Once? - Analytics VidhyaApr 14, 2025 am 10:22 AM
Cursor AI: Why You Should Try It Once? - Analytics VidhyaApr 14, 2025 am 10:22 AMIntroduction After Andrej Karpathy’s viral tweet,“English has become the new programming language,” here is another trending tweet on X saying, “Future be like Tab Tab Tab.”You might be wondering


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

WebStorm Mac version
Useful JavaScript development tools

Notepad++7.3.1
Easy-to-use and free code editor

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

