

 Technology peripheralsAITaskWeaver: an open source framework that facilitates data analysis and industry customization to build excellent Agent solutions
Technology peripheralsAITaskWeaver: an open source framework that facilitates data analysis and industry customization to build excellent Agent solutionsTaskWeaver: an open source framework that facilitates data analysis and industry customization to build excellent Agent solutions

Data analysis has always been a key tool in modern society, helping us deeply understand the essence, discover patterns and guide decision-making. However, the data analysis process is often complex and time-consuming, so we expect an intelligent assistant that can interact directly with the data. With the development of large language models (LLM), virtual assistants and intelligent agents such as Copilot have emerged one after another, and their performance in natural language understanding and generation is amazing. Unfortunately, however, existing agent frameworks still face difficulties in handling complex data structures (such as DataFrame, ndarray, etc.) and introducing domain knowledge, which is exactly the core requirement in data analysis and professional fields.
In order to better solve the bottleneck problem of voice assistants when performing tasks, Microsoft launched an Agent framework called TaskWeaver. The framework is code-first and can intelligently convert users' natural language requests into executable code, while supporting multiple data structures and dynamic plug-in selection. In addition, TaskWeaver can also be professionally adapted according to the planning process in different fields, fully utilizing the potential of large language models. As an open source framework, TaskWeaver provides customizable examples and plug-ins that can incorporate knowledge in specific fields, allowing users to easily create personalized virtual assistants. The launch of TaskWeaver will effectively improve the intelligence level of voice assistants and meet users' growing needs for personalized virtual assistants.

- Thesis: TaskWeaver: A Code-First Agent Framework
- Thesis address: https ://export.arxiv.org/abs/2311.17541
The TaskWeaver project has been open sourced on GitHub and appeared on the GitHub trending list on the day of release. Currently, the project has received 2.9k stars and has received good response. In addition, there are also some practical cases on social platforms such as LinkedIn, such as using TaskWeaver for SAP data analysis. These cases demonstrate the utility and value of TaskWeaver.

- Project homepage: https://microsoft.github.io/TaskWeaver/
- Project address: https://github.com/microsoft/TaskWeaver
##Story example
Tracking the hidden secrets in sales data
Xiaoya is a business analyst, and one of her jobs is from Look for anomalies in recent sales data and guide the company to adjust sales strategies based on those anomalies. All sales data is securely stored in a SQL database. She hopes to be able to easily extract and analyze data through natural language communication with an AI assistant. Of particular importance is the fact that in the sales world, anomalies are unique, so she hopes the AI assistant can employ customized anomaly detection algorithms to solve this problem. The following is the chat record between Xiaoya and the AI assistant (Figure 1), showing the interaction between them. Xiaoya: Hello, I need help extracting sales data from the database and analyzing it. AI assistant: OK, I will extract the corresponding data from the database right away. I will present the extracted data to you later for confirmation. Xiaoya: Thank you very much. (After awhile) AI assistant: I have extracted the sales data from the database. The following is an overview of the data, please confirm. (Overview of data displayed by AI assistant) Xiaoya: The data looks good, please continue with anomaly detection and analysis. AI Assistant: Got it. I'll perform the analysis using our custom anomaly detection algorithm and show you intuitive visualizations as soon as possible. (After awhile) AI Assistant: Analysis completed. Please view the following visualization results. (AI assistant displays visual results) Xiaoya: Thank you very much for your help! These results are very valuable to me. AI Assistant: Glad to help you. If you have any further questions or need further analysis, feel free to let me know. Xiaoya: Of course, thank you for your support.

Figure 1. Conversation transcript in the story example
What skills are required for the Agent framework?
Through the above-mentioned Xiaoya’s story, we have sorted out several core capabilities that the Agent framework should have:
1. Plug-in support: In the above story, the Agent needs to get data from the database and then use the specified anomaly detection algorithm. In order to accomplish these tasks, the smart assistant needs to be able to define and call custom plugins, such as the "query_database" plugin and the "anomaly_detection" plugin.
2. Rich data structure support: Agent needs to process complex data structures, such as arrays, matrices, table data, etc., thus Smoothly perform advanced data processing such as prediction, clustering, and more. Furthermore, this data should be passed seamlessly between different plugins. However, most existing agent frameworks convert the intermediate results of data analysis into text in Prompt, or save them as local files first and then read them when needed. However, these practices are prone to errors and exceeding the Prompt word limit.
3. Stateful execution: Agent often needs to interact with the user for multiple rounds of iterations, and generate and execute code based on user input. . Therefore, the execution state of these codes should be preserved throughout the session until the session ends.
4. Reason first and then act (ReAct) : Agent should have the ability of ReAct, that is, observe reasoning first and then take action. This is very necessary in some scenarios where uncertainty exists. For example, in the above example, since the data schema (schema) in the database is usually diverse, the Agent must first obtain the data schema information and understand which columns are appropriate (and confirm with the user), and then the corresponding columns can be name is input into the anomaly detection algorithm.
5. Generate arbitrary code: Sometimes, the predefined plug-in cannot satisfy the user's request, and the Agent should be able to generate code to deal with it. Temporary needs of users. In the above example, the Agent needs to generate code to visualize the detected anomalies, and this process is achieved without the help of any plug-ins.
6. Integrate domain knowledge: Agent should provide a systematic solution to integrate knowledge in specific fields. This will help LLM with better planning and accurate invocation of tools, thereby producing reliable results, especially in industry-tailored scenarios.
Revealing the core architecture of TaskWeaver
Figure 2 shows the overall architecture of TaskWeaver, including Planner, Code Interpreter Interpreter), and memory module (Memory).
The planner is like the brain of the system. It has two core responsibilities: 1) Make plans, that is, split the user's needs into subtasks and send these subtasks one by one to Code interpreter, and self-adjust the plan as needed during the entire plan execution process; 2) Respond to the user, it will convert the feedback results of the code interpreter into answers that are easy for the user to understand and send them to the user.
The code interpreter is mainly composed of two components: the code generator (Code Generator) will receive subtasks sent by the planner, combined with existing available plug-ins and domain-specific tasks Example to generate the corresponding code block; the code executor (Code Executor) is responsible for executing the generated code and maintaining the execution state throughout the session. Because of this, complex data structures can be passed in memory without going through prompts or the file system. It's like programming in Python in Jupyter Notebook, where the user enters a snippet of code into a cell, and the internal state of the program is preserved during sequential execution and can be referenced by subsequent processes. In terms of implementation, in each session, the code executor will have an independent Python process to execute the code, thus supporting multiple users at the same time.
The memory module mainly stores useful information during the operation of the entire system, such as execution results, etc., and can be written and read by different modules. Short-term memory mainly includes communication records between the user and TaskWeaver in the current session, as well as communication records between modules. Long-term memory includes domain knowledge that can be customized by the user in advance, as well as some experiences summarized during the interaction process, etc.
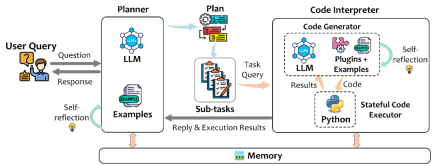
Figure 2. TaskWeaver overall architecture diagram
In addition to the basic architecture, TaskWeaver also has many unique designs. For example, session compression reduces text size, allowing for more conversation turns, and dynamic plug-in selection automatically picks appropriate plug-ins based on user requests, allowing for the integration of more custom plug-ins. In addition, TaskWeaver also supports the experience saving function, which can be triggered by users entering commands during use. It will summarize the user's experience and lessons in the current session, avoid repeating mistakes in the next session, and achieve true personalization. In terms of security, TaskWeaver is also carefully designed. For example, users can specify a whitelist of Python modules. If the generated code references modules outside the whitelist, an error will be triggered, thereby reducing security risks.
The specific process of TaskWeaver
Figure 3 shows us part of the process of TaskWeaver completing the aforementioned sample tasks.
First, the planner receives user input and generates specific plans based on the functional descriptions of each module and planning examples. The plan contains four subtasks, the first of which is to extract data from the database and describe the data schema.
The code generator then generates a piece of code based on its capability description and the definition of all related plug-ins. This code calls the sql_pull_data plugin to save the data into a DataFrame and provide a description of the data schema.
Finally, the generated code will be sent to the code executor for execution, and the completed results will be sent to the planner to update the plan or proceed to the next subtask. The execution results in the figure show that there are two columns in the DataFrame, namely date and value. The planner can further confirm with the user whether these columns are correct, or directly proceed to the next step of calling the anomaly_detection plug-in.

Figure 3. TaskWeaver internal workflow
How to inject domain knowledge into TaskWeaver?
In large model applications, the main purpose of integrating domain-specific knowledge is to improve the generalization performance of LLM in industry customization. TaskWeaver provides three ways to inject domain knowledge into the model:
-
Customize using plug-ins: Users can customize Integrate domain knowledge in the form of plug-ins. Plug-ins can come in many forms, such as calling an API, grabbing data from a specific database, or running a specific machine learning algorithm or model. Plug-in customization is relatively straightforward. You only need to provide basic information about the plug-in (including plug-in name, function description, input parameters and return values) and Python implementation.
-
Customize using examples: TaskWeaver also provides users with a systematic interface ( in YAML format) to teach LLM how to respond to user requests. Specifically, examples can be divided into two types, used for planning in the planner and code programming in the code generator.
- Save experience: TaskWeaver supports users to summarize and store the current session process as long-term memory . Users can “teach” TaskWeaver their domain knowledge as conversations and then save the conversations as experiences. In the subsequent use process, you can better complete professional field problems by dynamically loading experience.
#How to use TaskWeaver?
The complete code for TaskWeaver is now open source on GitHub. Currently, three solutions are supported for use, namely command line startup, web service, and import in the form of Python library. After a simple installation, users only need to configure a few key parameters, such as LLM API address, key, and model name, to easily start the TaskWeaver service.

Figure 4. Command line startup interface
Figure 5. TaskWeaver running example
TaskWeaver is a new Agent framework solution designed to meet the needs of data analysis and industry customization scenarios. By converting user language into programming language, "talking to data" will no longer be a dream, but a reality.
The above is the detailed content of TaskWeaver: an open source framework that facilitates data analysis and industry customization to build excellent Agent solutions. For more information, please follow other related articles on the PHP Chinese website!

 One Prompt Can Bypass Every Major LLM's SafeguardsApr 25, 2025 am 11:16 AM
One Prompt Can Bypass Every Major LLM's SafeguardsApr 25, 2025 am 11:16 AMHiddenLayer's groundbreaking research exposes a critical vulnerability in leading Large Language Models (LLMs). Their findings reveal a universal bypass technique, dubbed "Policy Puppetry," capable of circumventing nearly all major LLMs' s
 5 Mistakes Most Businesses Will Make This Year With SustainabilityApr 25, 2025 am 11:15 AM
5 Mistakes Most Businesses Will Make This Year With SustainabilityApr 25, 2025 am 11:15 AMThe push for environmental responsibility and waste reduction is fundamentally altering how businesses operate. This transformation affects product development, manufacturing processes, customer relations, partner selection, and the adoption of new
 H20 Chip Ban Jolts China AI Firms, But They've Long Braced For ImpactApr 25, 2025 am 11:12 AM
H20 Chip Ban Jolts China AI Firms, But They've Long Braced For ImpactApr 25, 2025 am 11:12 AMThe recent restrictions on advanced AI hardware highlight the escalating geopolitical competition for AI dominance, exposing China's reliance on foreign semiconductor technology. In 2024, China imported a massive $385 billion worth of semiconductor
 If OpenAI Buys Chrome, AI May Rule The Browser WarsApr 25, 2025 am 11:11 AM
If OpenAI Buys Chrome, AI May Rule The Browser WarsApr 25, 2025 am 11:11 AMThe potential forced divestiture of Chrome from Google has ignited intense debate within the tech industry. The prospect of OpenAI acquiring the leading browser, boasting a 65% global market share, raises significant questions about the future of th
 How AI Can Solve Retail Media's Growing PainsApr 25, 2025 am 11:10 AM
How AI Can Solve Retail Media's Growing PainsApr 25, 2025 am 11:10 AMRetail media's growth is slowing, despite outpacing overall advertising growth. This maturation phase presents challenges, including ecosystem fragmentation, rising costs, measurement issues, and integration complexities. However, artificial intell
 'AI Is Us, And It's More Than Us'Apr 25, 2025 am 11:09 AM
'AI Is Us, And It's More Than Us'Apr 25, 2025 am 11:09 AMAn old radio crackles with static amidst a collection of flickering and inert screens. This precarious pile of electronics, easily destabilized, forms the core of "The E-Waste Land," one of six installations in the immersive exhibition, &qu
 Google Cloud Gets More Serious About Infrastructure At Next 2025Apr 25, 2025 am 11:08 AM
Google Cloud Gets More Serious About Infrastructure At Next 2025Apr 25, 2025 am 11:08 AMGoogle Cloud's Next 2025: A Focus on Infrastructure, Connectivity, and AI Google Cloud's Next 2025 conference showcased numerous advancements, too many to fully detail here. For in-depth analyses of specific announcements, refer to articles by my
 Talking Baby AI Meme, Arcana's $5.5 Million AI Movie Pipeline, IR's Secret Backers RevealedApr 25, 2025 am 11:07 AM
Talking Baby AI Meme, Arcana's $5.5 Million AI Movie Pipeline, IR's Secret Backers RevealedApr 25, 2025 am 11:07 AMThis week in AI and XR: A wave of AI-powered creativity is sweeping through media and entertainment, from music generation to film production. Let's dive into the headlines. AI-Generated Content's Growing Impact: Technology consultant Shelly Palme


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

Dreamweaver CS6
Visual web development tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

SublimeText3 Linux new version
SublimeText3 Linux latest version

SublimeText3 Mac version
God-level code editing software (SublimeText3)

