
Home >Technology peripherals >AI >FlashOcc: New ideas for occupancy prediction, new SOTA in accuracy, efficiency and memory usage!
FlashOcc: New ideas for occupancy prediction, new SOTA in accuracy, efficiency and memory usage!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-11-28 11:21:501076browse
Original title: FlashOcc: Fast and Memory-Efficient Occupancy Prediction via Channel-to-Height Plugin
Paper link: https://arxiv.org/pdf/2311.12058.pdf
Author unit: Dalian University of Technology Houmo AI University of Adelaide

Thesis idea:
In view of being able to alleviate the problem of 3D target detection Occupancy prediction has become a key component of autonomous driving systems due to the ubiquitous long-tail shortcomings and missing capabilities of complex shapes. However, the processing of three-dimensional voxel-level representations inevitably introduces significant overhead in terms of memory and computation, hindering the deployment of occupancy prediction methods to date. Contrary to the trend of making models larger and more complex, this paper argues that an ideal framework should be deployment-friendly across different chips while maintaining high accuracy. To this end, this paper proposes a plug-and-play paradigm, FlashOCC, to consolidate fast and memory-efficient occupancy prediction while maintaining high accuracy. In particular, our FlashOCC makes two improvements based on contemporary voxel-level occupancy prediction methods. First, features are preserved in BEV, enabling the use of efficient 2D convolutional layers for feature extraction. Secondly, channel-to-height transformation is introduced to promote the output logits of BEV to 3D space. This paper applies FlashOCC to various occupancy prediction baselines on the challenging Occ3D-nuScenes benchmark and conducts extensive experiments to verify its effectiveness. Results confirm that our plug-and-play paradigm outperforms previous state-of-the-art methods in terms of accuracy, runtime efficiency, and memory cost, demonstrating its deployment potential. The code will be available for use.
Network design:
Inspired by sub-pixel convolution technology [26], we replace image upsampling with channel rearrangement to achieve channel-to-space Feature transformation. In this study, we aim to achieve channel-to-height feature conversion efficiently. Considering the development of BEV perception tasks, where each pixel in the BEV representation contains information about the corresponding columnar object in the height dimension, we intuitively utilize channel-to-height transformation to flatten the BEV features. Reshape into 3D voxel-level occupancy logits. Therefore, our research focuses on enhancing existing models in a generic and plug-and-play manner rather than developing novel model architectures, as shown in Figure 1(a). Specifically, we directly use 2D convolutions instead of 3D convolutions in contemporary methods, and replace the occupancy logits derived from the 3D convolution outputs with channel-to-height transformations of BEV-level features obtained through 2D convolutions. These models not only achieve the best trade-off between accuracy and time consumption, but also demonstrate excellent deployment compatibility
FlashOcc successfully completed real-time look-around 3D occupancy prediction with extremely high accuracy, representing seminal contributions in this field. Furthermore, it demonstrates enhanced versatility for deployment across different vehicular platforms as it does not require expensive voxel-level feature processing, where view transformers or 3D (deformable) convolution operators are avoided. As shown in Figure 2, the input data of FlashOcc consists of surround images, while the output is dense occupancy prediction results. Although FlashOcc in this article focuses on enhancing existing models in a versatile and plug-and-play manner, it can still be divided into five basic modules: (1) 2D image encoder, responsible for extracting image features from multi-camera images. (2) A view transformation module that helps map 2D perceptual view image features to 3D BEV representations. (3) BEV encoder, responsible for processing BEV feature information. (4) Occupy the prediction module to predict the segmentation label of each voxel. (5) An optional temporal fusion module designed to integrate historical information to improve performance.
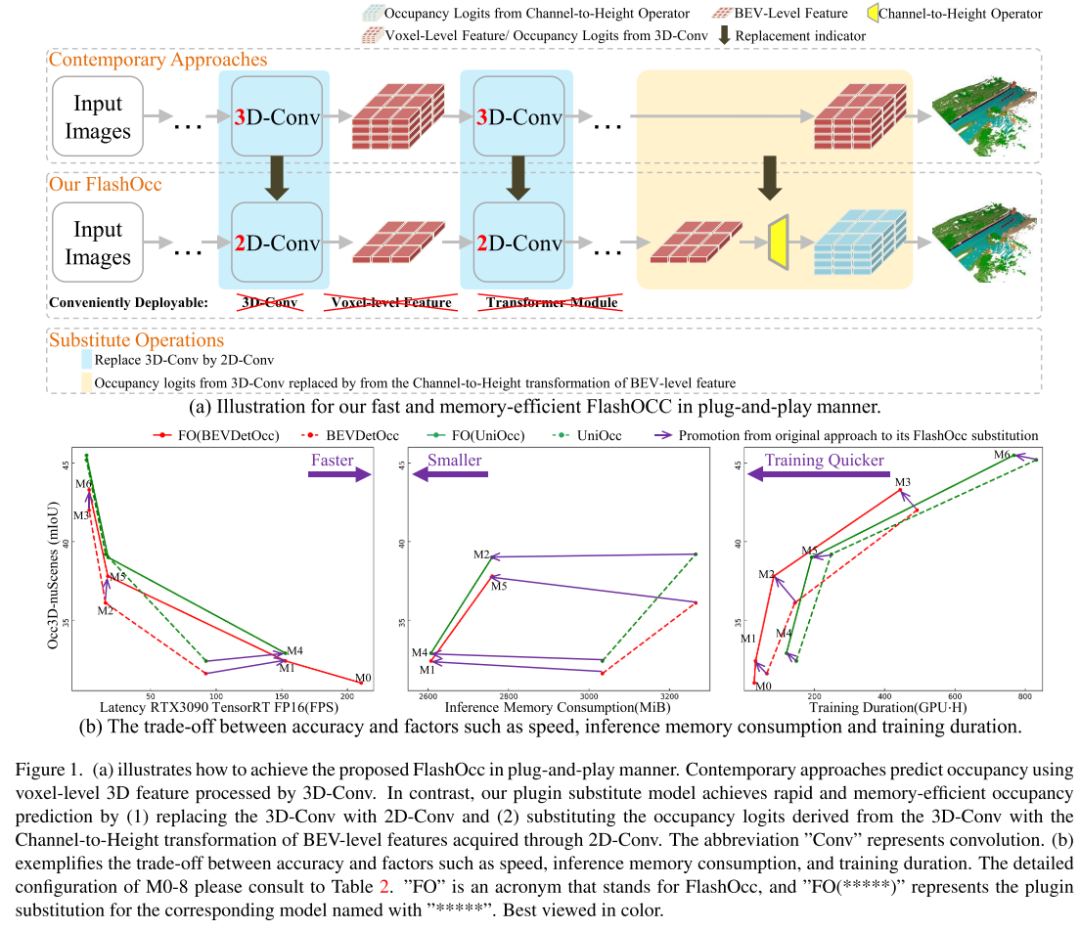
Figure 1.(a) illustrates how the proposed FlashOcc can be implemented in a plug-and-play manner. Modern methods use voxel-level 3D features processed by 3D-Conv to predict occupancy. In contrast, our plug-in replacement model is implemented by (1) replacing 3D-Conv with 2D-Conv and (2) replacing the occupancy logits derived from 3D-Conv with channel-to-height transformation. Fast and memory-efficient occupancy prediction of BEV-level features obtained via 2D-Conv. The abbreviation "Conv" stands for convolution. (b) illustrates the trade-off between accuracy and factors such as speed, inference memory consumption, and training duration.
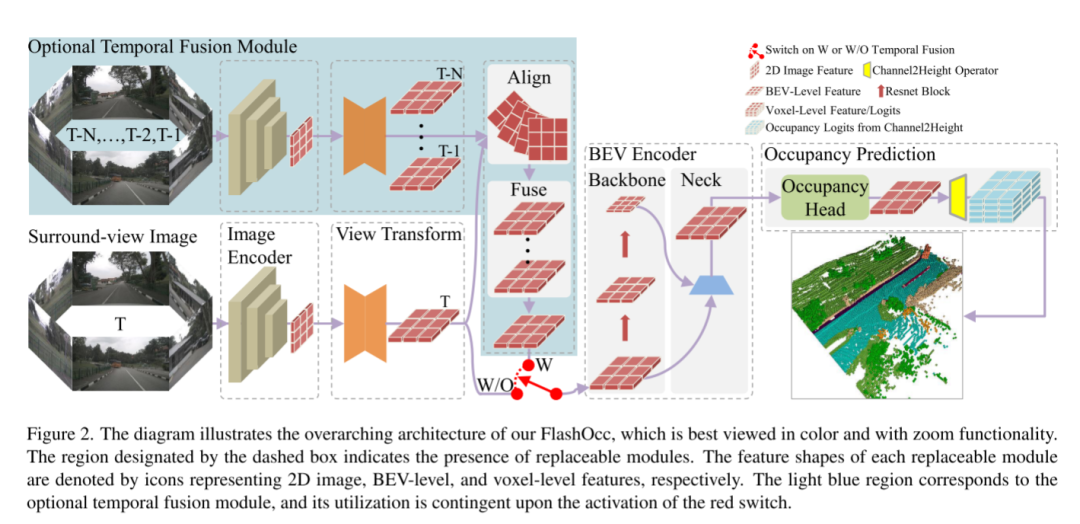
Figure 2. This diagram illustrates the overall architecture of FlashOcc and is best viewed in color with zoom capabilities. The area designated by the dashed box indicates the presence of replaceable modules. The feature shape of each replaceable module is represented by icons representing 2D image, BEV-level, and voxel-level features, respectively. The light blue area corresponds to the optional temporal fusion module, the use of which depends on the activation of the red switch.
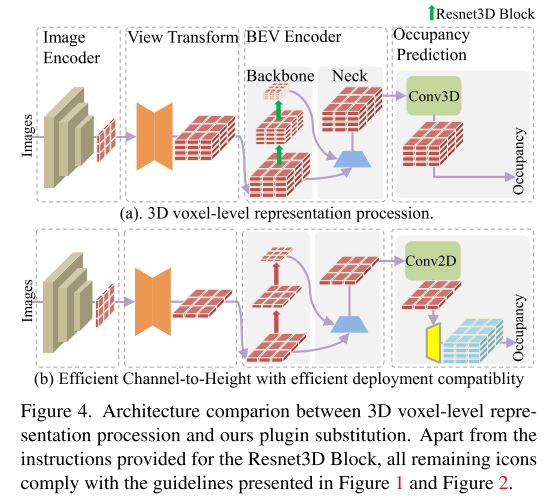
Figure 4 shows the architectural comparison between 3D voxel-level representation processing and the plug-in replacement proposed in this article
Experimental results:
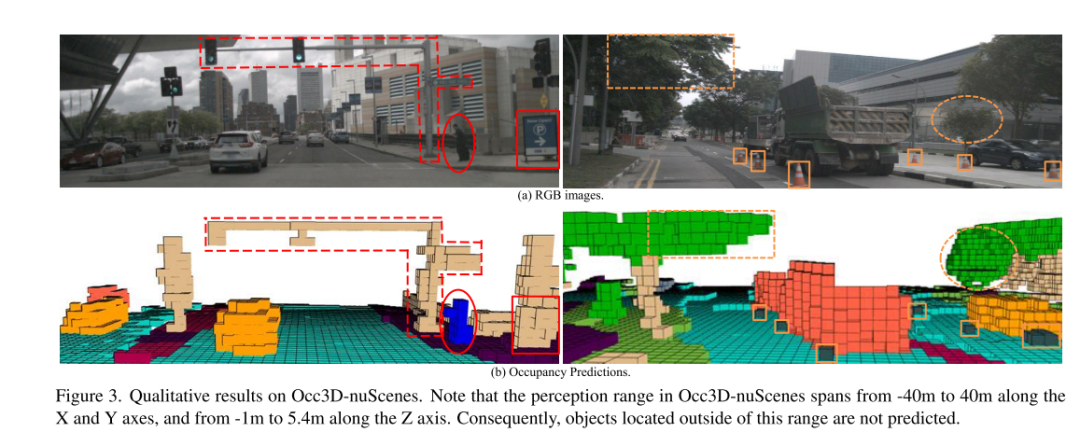
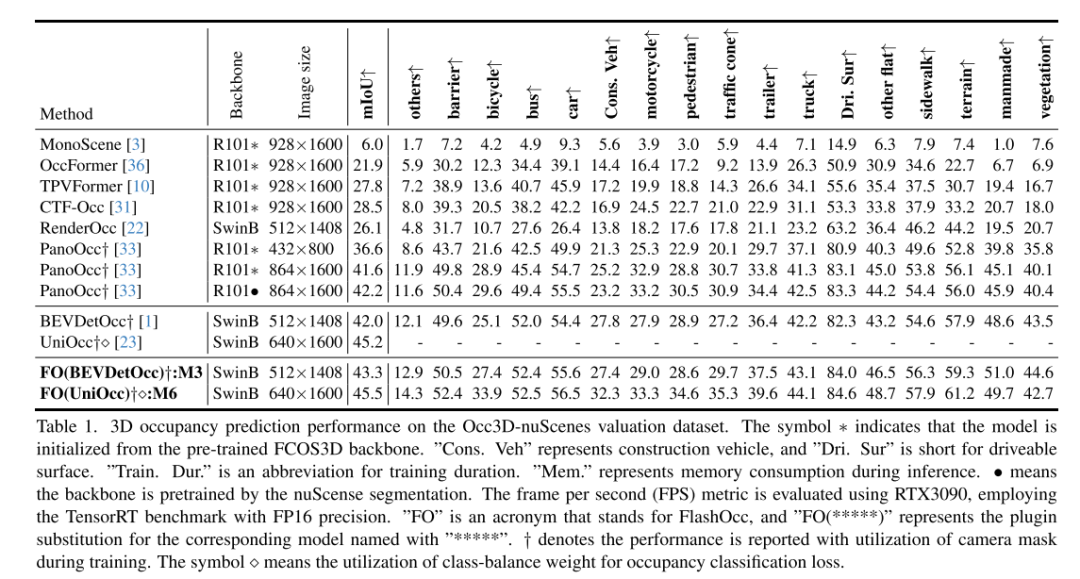
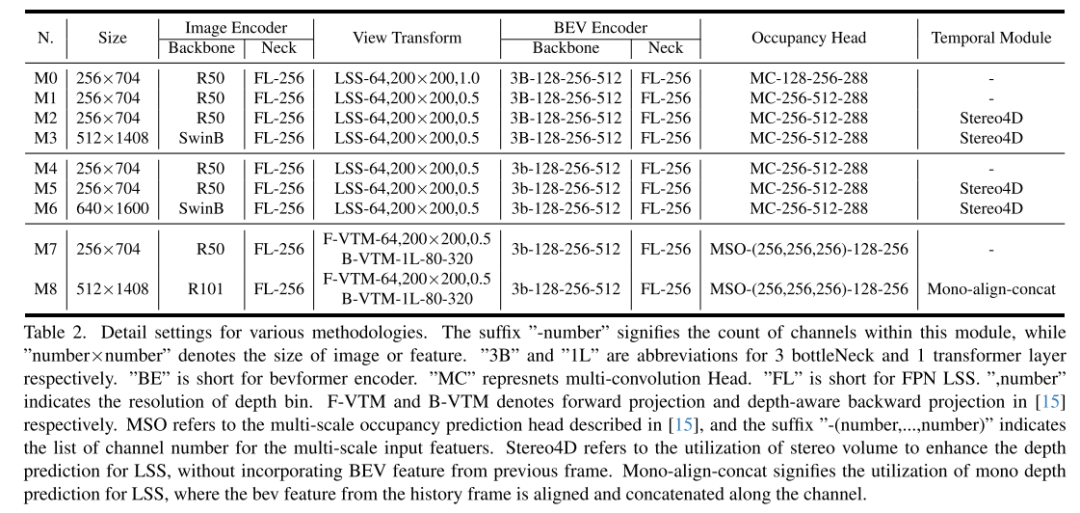
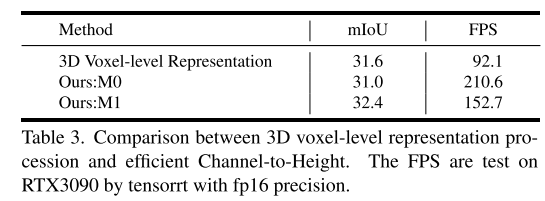
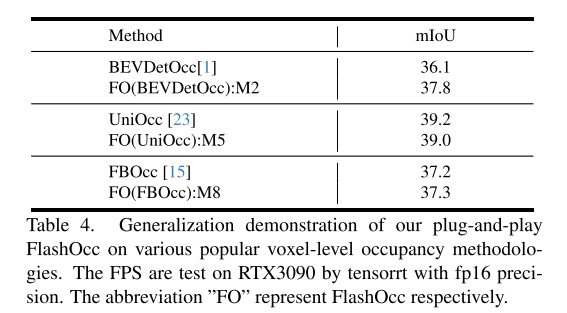
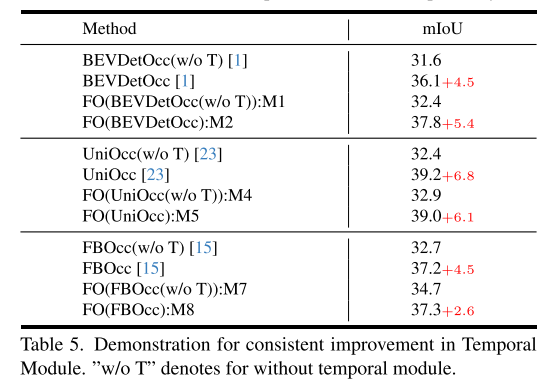
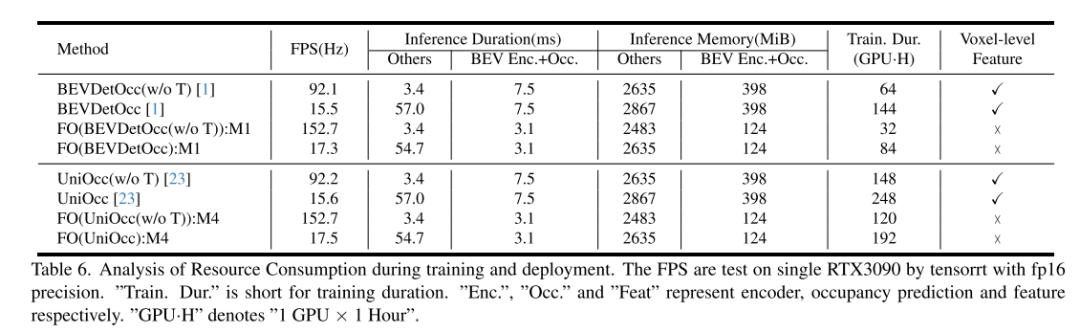
#Summary:
This article introduces a plug-and-play method called FlashOCC, designed to achieve fast and memory-efficient occupancy prediction. This method uses 2D convolutions to directly replace the 3D convolutions in voxel-based occupancy methods and combines channel-to-height transformation to reshape flattened BEV features into occupancy logits. FlashOCC has demonstrated its effectiveness and generalizability across a variety of voxel-level occupancy prediction methods. Extensive experiments demonstrate that this method outperforms previous state-of-the-art methods in terms of accuracy, time consumption, memory efficiency, and deployment-friendliness. To the best of our knowledge, FlashOCC is the first method to apply the sub-pixel paradigm (Channel-to-Height) to occupancy tasks, exclusively leveraging BEV-level features and completely avoiding the use of computational 3D (deformable) convolution or transformer modules. The visualization results convincingly demonstrate that FlashOCC successfully retains height information. In future work, this method will be integrated into the perception pipeline of autonomous driving, aiming to achieve efficient on-chip deploymentCitation:
Yu, Z., Shu, C., Deng, J., Lu, K., Liu, Z., Yu, J., Yang, D., Li, H., & Chen, Y. (2023). FlashOcc: Fast and Memory-Efficient Occupancy Prediction via Channel-to-Height Plugin. ArXiv. /abs/2311.12058
The above is the detailed content of FlashOcc: New ideas for occupancy prediction, new SOTA in accuracy, efficiency and memory usage!. For more information, please follow other related articles on the PHP Chinese website!