
Home >Technology peripherals >AI >In few-shot learning, use SetFit for text classification
In few-shot learning, use SetFit for text classification

- 王林forward
- 2023-11-28 11:14:281974browse
Translator| ##In this article, I will introduce you to the related concepts of "few-shot (Few-shot
) and focus on the widely usedSetFit method of text classification.
Traditional Machine Learning (ML) In Supervision (S
upervised
In-depth study
Sentence Transformer fine-tuning(SetFit) Before, we need to briefly review an important aspect of natural language processing (
Natural Language Processing, NLP) , that is: "few-shot learning". Few-shot learning## Few-shot learning means: using limited training data set to train the model. The model can obtain knowledge from these small collections called support sets. This type of learning aims to teach a few-shot model to recognize similarities and differences in the training data. For example, instead of instructing the model to classify a given image as a cat or a dog, we instruct it to grasp the commonalities and differences between various animals. As can be seen, this approach focuses on understanding similarities and differences in the input data. Therefore, it is also often called meta-learning (meta-learning), or learning-to-learn
).
It is worth mentioning that the support set of few-shot learning is also called k to ( k-way)nSample (n-shot) learning. Among them, "k" represents the number of categories in the support set. For example, in binary classification,
k is equal to 2. And "n" indicates the number of available samples for each category in the support set. For example, if the positive classification has 10 data points, and the negative classification also has 10 data points, then n is equal to 10. In summary, this support set can be described as bidirectional 10 sample learning. Now that we have a basic understanding of few-shot learning, let’s proceed by using SetFit Quickly learn and apply text classification to e-commerce data sets. SetFitArchitecture
ByHugging Face
#SetFit, jointly developed with the Intel Labs team, is an open source tool for few-sample photo classification. You can find comprehensive information about SetFit in the project library link-https://github.com/huggingface/setfit?ref=hackernoon.com.
In terms of output, SetFit only uses Customer Reviews (Customer Reviews, CR) Eight annotated examples of each category in the sentiment analysis dataset. The result is the same as the result of the tuned RoBERTa Large on the full training set consisting of three thousand examples. It is worth emphasizing that in terms of volume, the slightly optimized
RoBERTa model is three times larger than the SetFit model. The picture below shows the SetFit architecture: ##Image source: https:/ /www.php.cn/link/2456b9cd2668fa69e3c7ecd6f51866bfUse
SetFit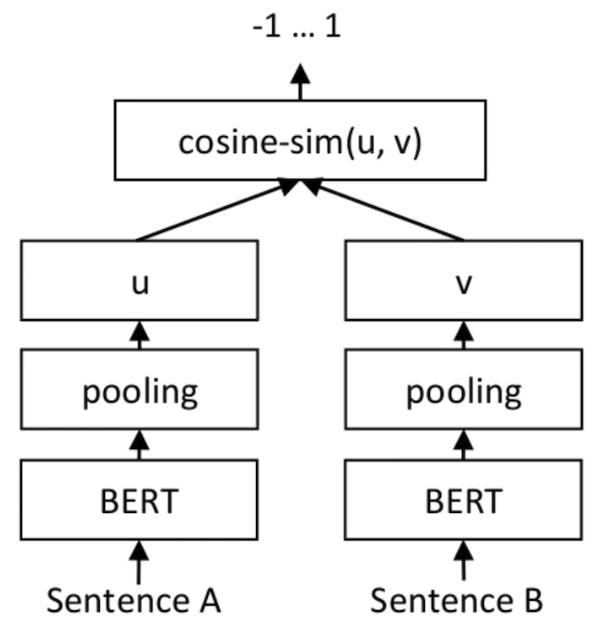
#SetFit is very fast and efficient. Its performance is extremely competitive compared with large models such as GPT-3
and T-FEW. See the image below:
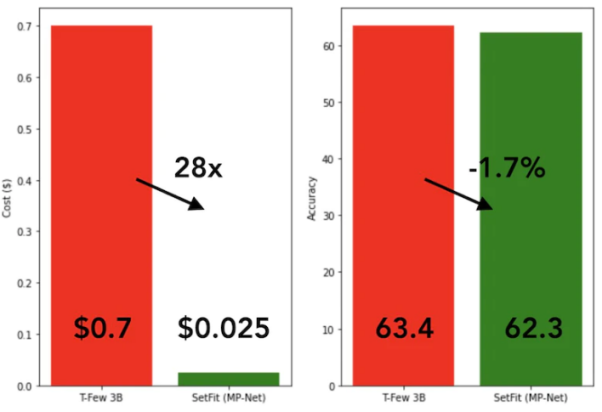 Comparison between SetFit and T-Few 3B model
Comparison between SetFit and T-Few 3B model
As shown in the figure below, SetFit is less The performance in sample learning is better than RoBERTa.
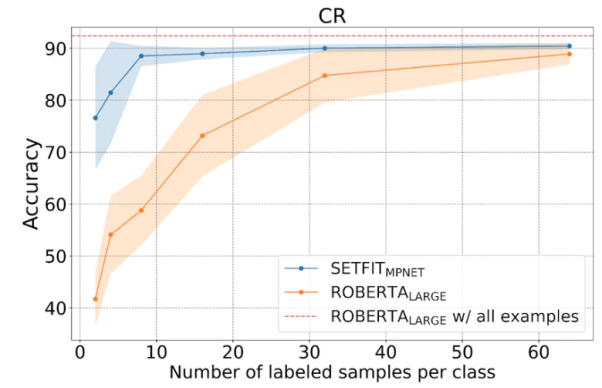
Comparison between SetFit and RoBERT, picture source: https://www .php.cn/link/3ff4cea152080fd7d692a8286a587a67
Dataset
Below , we will use a unique e-commerce data set consisting of four different categories: books, clothing and accessories, electronics, and home furnishings. The main purpose of this dataset is to classify product descriptions from e-commerce websites into specified tags.
In order to facilitate the use of a few-sample training method, we will select eight samples from each of the four categories, resulting in a total of 32 training samples. The remaining samples will be reserved for testing purposes. In short, the support set we use here is 4 learning from 8 examples. The figure below shows an example of a custom e-commerce data set:
 Custom e-commerce data set sample
Custom e-commerce data set sample
We use the Sentence Transformers pre-trained model named "all-mpnet-base-v2" to convert text data into various vector embeddings. This model can generate vector embeddings of dimension 768 for input text.
As shown in the following command, we will use the conda environment (which is an open source software package management system and environment management system) to start the implementation of SetFit.
!pip3 install SetFit !pip3 install sklearn !pip3 install transformers !pip3 install sentence-transformers
After installing the software package, we can load the data set through the following code.
from datasets import load_datasetdataset = load_dataset('csv', data_files={"train": 'E_Commerce_Dataset_Train.csv',"test": 'E_Commerce_Dataset_Test.csv'})
Let’s refer to the figure below to see the number of training samples and test samples.
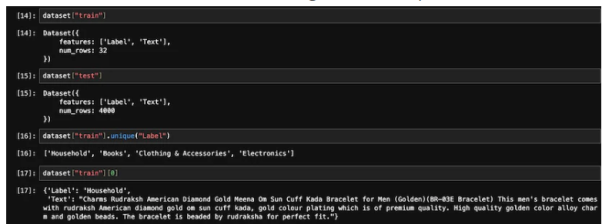 Training and testing data
Training and testing data
We use sklearn##LabelEncoder in the package converts text labels into encoded labels.
from sklearn.preprocessing import LabelEncoder le = LabelEncoder()
Through LabelEncoder, we will encode the training and test data sets and encode the The label is added to the "Label" column of the dataset. See the code below:
Encoded_Product = le.fit_transform(dataset["train"]['Label']) dataset["train"] = dataset["train"].remove_columns("Label").add_column("Label", Encoded_Product).cast(dataset["train"].features)Encoded_Product = le.fit_transform(dataset["test"]['Label']) dataset["test"] = dataset["test"].remove_columns("Label").add_column("Label", Encoded_Product).cast(dataset["test"].features)
Below, we will initialize the SetFit model and sentence converter (sentence- transformers) model.
from setfit import SetFitModel, SetFitTrainer from sentence_transformers.losses import CosineSimilarityLossmodel_id = "sentence-transformers/all-mpnet-base-v2" model = SetFitModel.from_pretrained(model_id)trainer = SetFitTrainer( model=model, train_dataset=dataset["train"], eval_dataset=dataset["test"], loss_class=CosineSimilarityLoss, metric="accuracy", batch_size=64, num_iteratinotallow=20, num_epochs=2, column_mapping={"Text": "text", "Label": "label"})
After initializing the two models, we can now call the training program.
trainer.train()
After completing 2 training rounds (epochs), we will eval_dataset, evaluate the trained model.
trainer.evaluate()
After testing, the highest accuracy of our training model was 87.5%. Although the accuracy of 87.5% is not high, after all, our model only used 32 samples for training. In other words, considering the limited size of the data set, achieving an accuracy of 87.5% on the test data set is actually quite impressive.
In addition, SetFit can also save the trained model to local storage for subsequent use. Disk loading for future predictions.
trainer.model._save_pretrained(save_directory="SetFit_ECommerce_Output/")model=SetFitModel.from_pretrained("SetFit_ECommerce_Output/", local_files_notallow=True)
The following code shows the prediction results based on new data:
input = ["Campus Sutra Men's Sports Jersey T-Shirt Cool-Gear: Our Proprietary Moisture Management technology. Helps to absorb and evaporate sweat quickly. Keeps you Cool & Dry. Ultra-Fresh: Fabrics treated with Ultra-Fresh Antimicrobial Technology. Ultra-Fresh is a trademark of (TRA) Inc, Ontario, Canada. Keeps you odour free."]output = model(input)
It can be seen that its predicted output is 1, and the LabelEncoded value of the label is "Clothing and Accessories". Traditional AI models require a large amount of training resources (including time and data) to produce a stable level of output. In contrast, our model is both accurate and efficient.
At this point, I believe you have basically mastered the concept of "few-shot learning" and how to use SetFit for text classification and other applications. Of course, in order to gain a deeper understanding, I strongly recommend that you choose an actual scenario, create a data set, write the corresponding code, and extend the process to zero-shot learning and single-shot learning.
Translator introduction
##Julian Chen is the editor of the 51CTO community , he has more than ten years of experience in IT project implementation, is good at managing internal and external resources and risks, and focuses on disseminating knowledge and experience in network and information security
Original title: ##Mastering Few-Shot Learning with SetFit for Text Classification, author : Shyam Ganesh S)
The above is the detailed content of In few-shot learning, use SetFit for text classification. For more information, please follow other related articles on the PHP Chinese website!