
Home >Technology peripherals >AI >GPT-4: Do you dare to use the code I wrote? Research shows its API misuse rate exceeds 62%
GPT-4: Do you dare to use the code I wrote? Research shows its API misuse rate exceeds 62%

- WBOYforward
- 2023-09-13 09:13:01789browse
The new era of language modeling has arrived. Large language models (LLM) have extraordinary capabilities. They can not only understand natural language, but even generate customized code according to user needs.
As a result, more and more software engineers are choosing to query large language models to answer programming questions, such as using APIs to generate code snippets or detect bugs in code. Large language models can retrieve more appropriately tailored answers to programming questions than searching online programming forums like Stack Overflow.
LLM is fast, but this also masks potential risks in its code generation. From a software engineering perspective, the robustness and reliability of LLM's ability to generate code have not been thoroughly studied, even though many research results have been published (in terms of avoiding syntactic errors and improving semantic understanding of generated code).
Unlike what is the case with web programming forums, the code generated by LLM is not reviewed by community peers, so API misuse issues may occur, such as missing boundaries in file reading and variable indexing. Checks, missing file I/O closures, failed transaction completion, etc. Even if the generated code sample can be executed or can perform functions correctly, misuse may lead to serious potential risks in the product, such as memory leaks, program crashes, garbage data collection failures, etc.
Worse yet, the programmers who ask these questions are the ones most vulnerable because they are more likely to be new to the API and unable to discern potential problems in the generated code snippets .
The following figure shows an example of a software engineer asking LLM for programming questions. It can be seen that Llama-2 can give a code segment with correct syntax, correct function, and syntax alignment, but it There is a problem that it is not robust enough because it does not take into account the situation where the file already exists or the folder does not exist.

Therefore, when evaluating the code generation capabilities of large language models, the reliability of the code must be considered.
In terms of evaluating the code generation capabilities of large language models, most existing benchmarks focus on the functional correctness of the execution results of the generated code, which means that as long as the generated code If it can meet the functional needs of users, users will accept it.
But in the field of software development, it is not enough for the code to execute correctly. What software engineers need is code that can use the new API correctly and reliably without potential risks in the long run.
Furthermore, the scope of most current programming problems is far removed from software engineering. Most of its data sources are online programming challenge networks, such as Codeforces, Kattis, Leetcode, etc. Although the achievement is remarkable, it is not enough to help the software development work in practical application scenarios.
To this end, Li Zhong and Zilong Wang of the University of California, San Diego proposed RobustAPI, a framework that can evaluate the reliability and robustness of code generated by large language models, including a programming Problem dataset and an evaluator using abstract syntax trees (AST).

Paper address: https://arxiv.org/pdf/2308.10335.pdf
where The goal of the dataset is to create an evaluation setting that approximates real software development. To this end, the researchers collected representative questions about Java from Stack Overflow. Java is one of the most popular programming languages and is widely used for software development thanks to its write once run anywhere (WORA) feature.
For each question, the researchers provided a detailed description and related Java API. They also designed a set of templates for calling large language models to generate code snippets and corresponding explanations.
The researchers also provide an evaluator that uses an abstract syntax tree (AST) to analyze the generated code snippets and compare them to expected API usage patterns.
The researchers also formalized the AI usage pattern into a structured call sequence according to the method of Zhang et al. (2018). This structured sequence of calls can demonstrate how these APIs can be used correctly to eliminate potential system risks. From a software engineering perspective, any violation of this structured call sequence is considered a failure.
The researchers collected 1208 real questions from Stack Overflow, involving 24 representative Java APIs. The researchers also conducted experimental evaluations, including not only closed-source language models (GPT-3.5 and GPT-4), but also open-source language models (Llama-2 and Vicuna-1.5). For the hyperparameter settings of the model, they used the default settings and did not perform further hyperparameter adjustments. They also designed two experimental forms: zero-shot and one-shot, which provide zero or one demonstration sample in the prompt respectively.
The researchers comprehensively analyzed the code generated by LLM and studied common API misuses. They hope this will shed light on the important issue of LLM misusing APIs when generating code, and this research will also provide a new dimension to the evaluation of LLMs beyond the commonly used functional correctness. In addition, the dataset and estimator will be open source.
The contributions of this paper are summarized as follows:
- A method for evaluating the reliability and robustness of LLM code generation is proposed A new benchmark: RobustAPI.
- Provides a comprehensive evaluation framework that includes a dataset of Stack Overflow questions and an API usage checker using AST. Based on this framework, researchers analyzed the performance of commonly used LLMs, including GPT-3.5, GPT-4, Llama-2 and Vicuna-1.5.
- Comprehensive analysis of the performance of LLM generated code. They summarize common API misuses for each model and point out directions for improvements for future research.
Method Overview
RobustAPI is a framework for comprehensively evaluating the reliability and robustness of LLM-generated code.
The data collection process and prompt generation process when building this data set will be described below, and then the API misuse patterns evaluated in RobustAPI will be given and the potential consequences of misuse will be discussed. Finally We will also present a static analysis of using RobustAPI to detect API misuse, using an abstract syntax tree.
It was found that compared to rule-based methods such as keyword matching, the new method can evaluate API misuse of LLM-generated code with higher accuracy.
Data collection
In order to take advantage of existing research results in the field of software engineering, the researchers built RobustAPI based on The starting point is the dataset from ExampleCheck (Zhang et al. 2018). ExampleCheck is a framework for studying common Java API misuses in web Q&A forums.
The researcher selected 23 common Java APIs from this data set, as shown in Table 1 below. These 23 APIs cover 5 areas, including string processing, data structures, mobile development, encryption, and database operations.

prompt generation
RobustAPI also contains a prompt template that can be used filled with samples from the data set. The researchers then collected LLM's responses to the prompt and used an API checker to evaluate the reliability of their code.

In this prompt, the task introduction and required response format will first be given. Then, if the experiment performed is a few-sample experiment, a few-sample demonstration will also be given. Here is an example:
Demo sample
##Demo sample has been proven to help LLM understand natural language. In order to thoroughly analyze the code generation ability of LLM, the researchers designed two few-shot settings: single-sample irrelevant demonstration and single-sample dependent demonstration.
In a single-sample agnostic demo setting, the demo examples provided for LLM use APIs that are agnostic. The researchers hypothesized that such demonstration examples would eliminate syntactic errors in the generated code. An unrelated example used in RobustAPI is:

In a single-sample correlation demo setting, the demo examples provided for LLM use the same API as the given problem. This example contains a question and answer pair. The questions in this demo were not included in the test dataset, and the answers were manually corrected to ensure that there were no API misuses and that the semantics of the answers and questions were well aligned.
Misuse of Java API
The researcher summarized 40 API rules for the 23 APIs in RobustAPI. They are verified in the documentation of these APIs. These rules include:
(1) Guard conditions for APIs, which should be checked before API calls. For example, the result of File.exists () should be checked before File.createNewFile ().
(2) The required API call sequence, that is, the API should be called in a certain order. For example, close () should be called after File.write ().
(3) API control structure. For example, SimpleDateFormat.parse () should be included in a try-catch structure.
An example is given below:

Detecting API misuse
In order to evaluate the correctness of API usage in the code, RobustAPI can detect API misuse according to API usage rules by extracting call results and control structures from the code segment, as shown below 2 shown.

The code checker will first check the generated code segment to see if this code is a piece of code in a method or from a class a method so that it can encapsulate that piece of code and use it to build an abstract syntax tree (AST).
The inspector then traverses the AST and records all method calls and control structures in order, which generates a sequence of calls.
Next, the checker compares this sequence of calls to API usage rules. It infers the instance type for each method call and uses that type and method as keys to retrieve the corresponding API usage rules.
Finally, the checker calculates the longest common sequence between this call sequence and the API usage rules.
If the call sequence does not match the expected API usage rules, the checker reports an API misuse.
Experimental results
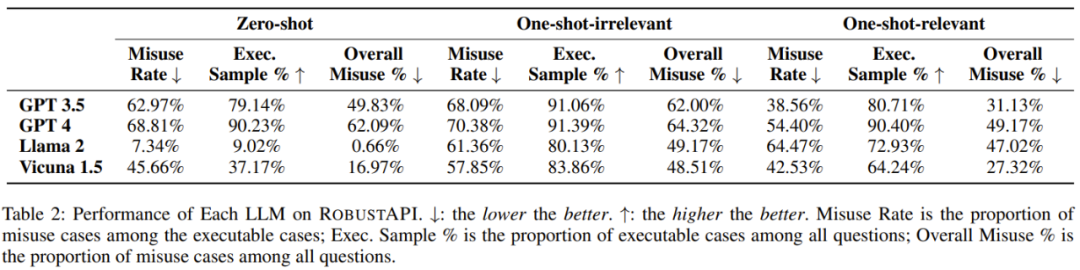
The researchers evaluated RobustAPI on 4 LLMs: GPT-3.5, GPT-4 , Llama-2 and Vicuna-1.5.
The evaluation indicators used in the experiment include: API misuse rate, executable sample percentage, and overall API misuse percentage.
The purpose of the experiment is to try to answer the following questions:
- Question 1: The APIs of these LLMs in solving real-world programming problems What is the misuse rate?
- Question 2: What impact will irrelevant demo samples have on the results?
- Question 3: Can correct API usage examples reduce API misuse rates?
- Question 4: Why does the code generated by LLM fail the API usage check?
For the specific experimental process, please refer to the original paper. Here are the five findings obtained by the researchers:
Discovery 1: Current state-of-the-art large language model answers to real-world programming problems suffer from widespread API misuse.

Finding 2: Among all LLM answers containing executable code, 57-70% of the code segments have API misuse issues. This It may bring serious consequences to production.
Finding 3: Irrelevant sample examples do not help reduce API misuse rates, but trigger more effective answers, which can be used effectively Benchmarking model performance.
Finding 4: Some LLMs can learn correct usage examples, which can reduce API misuse rates.
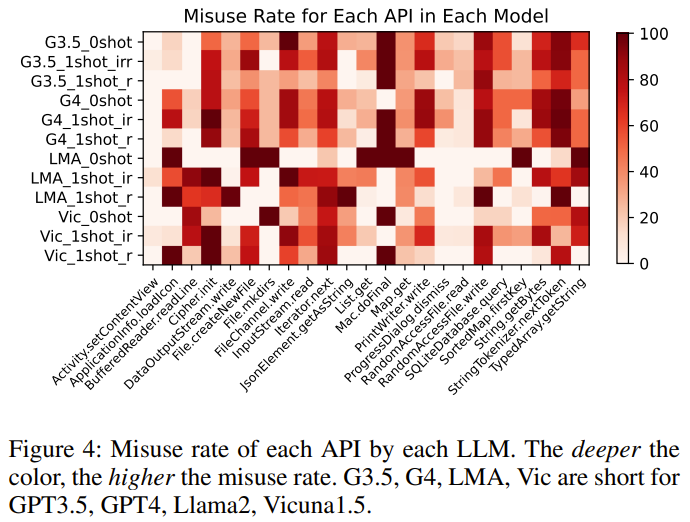
Finding 5: GPT-4 has the highest number of answers containing executable code. For the baseline API, different LLMs also have different trends in misuse rates.
In addition, the researcher also demonstrated a typical case based on GPT-3.5 in the paper: the model has different responses under different experimental settings.
The task is to ask the model to help write a string to a file using the PrintWriter.write API.

The answers are slightly different in the zero-sample and single-sample irrelevant demo settings, but API misuse issues arise - no exceptions are considered Condition. After the model is given correct examples of API usage, the model learns how to use the API and produces reliable code.
Please refer to the original paper for more details.
The above is the detailed content of GPT-4: Do you dare to use the code I wrote? Research shows its API misuse rate exceeds 62%. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- How to delete redundant models in ZBrush
- Introducing one of the GIT code branch management models
- What is the data model using tree structure?
- This year's English College Entrance Examination, CMU used reconstruction pre-training to achieve a high score of 134, significantly surpassing GPT3
- US media: Musk and others are right to call for a suspension of AI training and need to slow down for safety