


Microsoft's new hot paper: Transformer expands to 1 billion tokens

When everyone continues to upgrade and iterate their own large models, the ability of LLM (large language model) to process context windows has also become an important evaluation indicator.
For example, the star large model GPT-4 supports 32k tokens, equivalent to 50 pages of text; Anthropic, founded by a former member of OpenAI, has increased Claude's token processing capabilities to 100k, about 75,000 One word is roughly equivalent to summarizing the first part of "Harry Potter" in one click.
In Microsoft’s latest research, they directly expanded Transformer to 1 billion tokens this time. This opens up new possibilities for modeling very long sequences, such as treating an entire corpus or even the entire Internet as one sequence.
For comparison, the average person can read 100,000 tokens in about 5 hours, and may take longer to digest, remember, and analyze the information. Claude can do this in less than a minute. If converted into this research by Microsoft, it would be a staggering number.
 Picture
Picture
- Paper address: https://arxiv.org/pdf/2307.02486.pdf
- Project address: https://github.com/microsoft/unilm/tree/master
Specifically, the study proposes LONGNET, a Transformer variant that can extend sequence length to over 1 billion tokens without sacrificing performance for shorter sequences. The article also proposes dilated attention, which can exponentially expand the model's perception range.
LONGNET has the following advantages:
1) It has linear computational complexity;
2) It can be used as a distributed trainer for longer sequences;
3) dilated attention can seamlessly replace standard attention and work seamlessly with existing Transformer-based optimization methods integrated.
Experimental results show that LONGNET exhibits strong performance in both long sequence modeling and general language tasks.
In terms of research motivation, the paper states that in recent years, extending neural networks has become a trend, and many networks with good performance have been studied. Among them, the sequence length, as part of the neural network, should ideally be infinite. But the reality is often the opposite, so breaking the limit of sequence length will bring significant advantages:
- First, it provides a large-capacity memory and receptive field for the model. Enable it to interact effectively with humans and the world.
- Secondly, longer context contains more complex causal relationships and reasoning paths that the model can exploit in the training data. On the contrary, shorter dependencies will introduce more spurious correlations, which is not conducive to the generalization of the model.
- Third, longer sequence length can help the model explore longer contexts, and extremely long contexts can also help the model alleviate the catastrophic forgetting problem.
#However, the main challenge in extending sequence length is finding the right balance between computational complexity and model expressive power.
For example, RNN style models are mainly used to increase sequence length. However, its sequential nature limits parallelization during training, which is crucial in long sequence modeling.
Recently, state space models have become very attractive for sequence modeling, which can be run as a CNN during training and converted to an efficient RNN at test time. However, this type of model does not perform as well as Transformer at regular lengths.
Another way to extend the sequence length is to reduce the complexity of the Transformer, that is, the quadratic complexity of self-attention. At this stage, some efficient Transformer-based variants have been proposed, including low-rank attention, kernel-based methods, downsampling methods, and retrieval-based methods. However, these approaches have yet to scale Transformer to the scale of 1 billion tokens (see Figure 1).
 Picture
Picture
The following table compares the computational complexity of different calculation methods. N is the sequence length, and d is the hidden dimension.
 picture
picture
Method
The study’s solution, LONGNET, successfully extended the sequence length to 1 billion tokens. Specifically, this research proposes a new component called dilated attention and replaces the attention mechanism of Vanilla Transformer with dilated attention. A general design principle is that the allocation of attention decreases exponentially as the distance between tokens increases. The study shows that this design approach obtains linear computational complexity and logarithmic dependence between tokens. This resolves the conflict between limited attention resources and access to every token.
 Picture
Picture
During the implementation process, LONGNET can be converted into a dense Transformer to seamlessly support existing Transformer-specific There are optimization methods (such as kernel fusion, quantization and distributed training). Taking advantage of linear complexity, LONGNET can be trained in parallel across nodes, using distributed algorithms to break computing and memory constraints.
In the end, the research effectively expanded the sequence length to 1B tokens, and the runtime was almost constant, as shown in the figure below. In contrast, the vanilla Transformer's runtime suffers from quadratic complexity.

This research further introduces the multi-head dilated attention mechanism. As shown in Figure 3 below, this study performs different computations across different heads by sparsifying different parts of query-key-value pairs.
 Picture
Picture
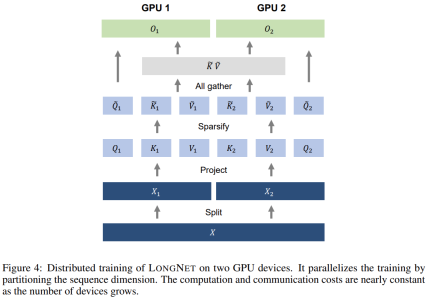
Distributed training
Although the computational complexity of dilated attention has been greatly reduced to , due to computing and memory limitations, it is not feasible to extend the sequence length to millions of levels on a single GPU device of. There are some distributed training algorithms for large-scale model training, such as model parallelism [SPP 19], sequence parallelism [LXLY21, KCL 22] and pipeline parallelism [HCB 19]. However, these methods are not enough for LONGNET, especially is when the sequence dimension is very large.
, due to computing and memory limitations, it is not feasible to extend the sequence length to millions of levels on a single GPU device of. There are some distributed training algorithms for large-scale model training, such as model parallelism [SPP 19], sequence parallelism [LXLY21, KCL 22] and pipeline parallelism [HCB 19]. However, these methods are not enough for LONGNET, especially is when the sequence dimension is very large.
This research utilizes the linear computational complexity of LONGNET for distributed training of sequence dimensions. Figure 4 below shows the distributed algorithm on two GPUs, which can be further scaled to any number of devices.
##Experiment
This research will LONGNET Comparisons were made with vanilla Transformer and sparse Transformer. The difference between the architectures is the attention layer, while the other layers remain the same. The researchers expanded the sequence length of these models from 2K to 32K, while reducing the batch size to ensure that the number of tokens in each batch remained unchanged.
Table 2 summarizes the results of these models on the Stack dataset. Research uses complexity as an evaluation metric. The models were tested using different sequence lengths, ranging from 2k to 32k. When the input length exceeds the maximum length supported by the model, the research implements blockwise causal attention (BCA) [SDP 22], a state-of-the-art extrapolation method for language model inference.
In addition, the study removed absolute position encoding. First, the results show that increasing sequence length during training generally results in better language models. Second, the sequence length extrapolation method in inference does not apply when the length is much larger than the model supports. Finally, LONGNET consistently outperforms baseline models, demonstrating its effectiveness in language modeling.

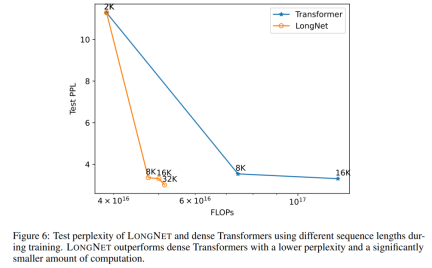
Expansion curve of sequence length
Figure 6 plots the sequence length expansion curves of vanilla transformer and LONGNET. This study estimates the computational effort by counting the total flops of matrix multiplications. The results show that both vanilla transformer and LONGNET achieve larger context lengths from training. However, LONGNET can extend the context length more efficiently, achieving lower test loss with less computation. This demonstrates the advantage of longer training inputs over extrapolation. Experiments show that LONGNET is a more efficient way to extend the context length in language models. This is because LONGNET can learn longer dependencies more efficiently.
##Expand model size
An important property of large language models is that the loss expands in a power law as the amount of calculation increases. To verify whether LONGNET still follows similar scaling rules, the study trained a series of models with different model sizes (from 125 million to 2.7 billion parameters). 2.7 billion models were trained with 300B tokens, while the remaining models used approximately 400B tokens. Figure 7 (a) plots the expansion curve of LONGNET with respect to computation. The study calculated the complexity on the same test set. This proves that LONGNET can still follow a power law. This also means that dense Transformer is not a prerequisite for extending language models. Additionally, scalability and efficiency are gained with LONGNET.

##Long context prompt
Prompt Yes An important way to bootstrap language models and provide them with additional information. This study experimentally validates whether LONGNET can benefit from longer context hint windows.This study retains a prefix (prefixes) as a prompt and tests the perplexity of its suffixes (suffixes). Moreover, during the research process, the prompt was gradually expanded from 2K to 32K. To make a fair comparison, the length of the suffix is kept constant while the length of the prefix is increased to the maximum length of the model. Figure 7(b) reports the results on the test set. It shows that the test loss of LONGNET gradually decreases as the context window increases. This proves the superiority of LONGNET in fully utilizing long context to improve language models.
The above is the detailed content of Microsoft's new hot paper: Transformer expands to 1 billion tokens. For more information, please follow other related articles on the PHP Chinese website!

 Understanding LangChain Agent FrameworkApr 21, 2025 am 11:25 AM
Understanding LangChain Agent FrameworkApr 21, 2025 am 11:25 AMLangChain is a powerful toolkit for building sophisticated AI applications. Its agent architecture is particularly noteworthy, allowing developers to create intelligent systems capable of independent reasoning, decision-making, and action. This expl
 What are the Radial Basis Functions Neural Networks?Apr 21, 2025 am 11:13 AM
What are the Radial Basis Functions Neural Networks?Apr 21, 2025 am 11:13 AMRadial Basis Function Neural Networks (RBFNNs): A Comprehensive Guide Radial Basis Function Neural Networks (RBFNNs) are a powerful type of neural network architecture that leverages radial basis functions for activation. Their unique structure make
 The Meshing Of Minds And Machines Has ArrivedApr 21, 2025 am 11:11 AM
The Meshing Of Minds And Machines Has ArrivedApr 21, 2025 am 11:11 AMBrain-computer interfaces (BCIs) directly link the brain to external devices, translating brain impulses into actions without physical movement. This technology utilizes implanted sensors to capture brain signals, converting them into digital comman
 Insights on spaCy, Prodigy and Generative AI from Ines MontaniApr 21, 2025 am 11:01 AM
Insights on spaCy, Prodigy and Generative AI from Ines MontaniApr 21, 2025 am 11:01 AMThis "Leading with Data" episode features Ines Montani, co-founder and CEO of Explosion AI, and co-developer of spaCy and Prodigy. Ines offers expert insights into the evolution of these tools, Explosion's unique business model, and the tr
 A Guide to Building Agentic RAG Systems with LangGraphApr 21, 2025 am 11:00 AM
A Guide to Building Agentic RAG Systems with LangGraphApr 21, 2025 am 11:00 AMThis article explores Retrieval Augmented Generation (RAG) systems and how AI agents can enhance their capabilities. Traditional RAG systems, while useful for leveraging custom enterprise data, suffer from limitations such as a lack of real-time dat
 What are Integrity Constraints in SQL? - Analytics VidhyaApr 21, 2025 am 10:58 AM
What are Integrity Constraints in SQL? - Analytics VidhyaApr 21, 2025 am 10:58 AMSQL Integrity Constraints: Ensuring Database Accuracy and Consistency Imagine you're a city planner, responsible for ensuring every building adheres to regulations. In the world of databases, these regulations are known as integrity constraints. Jus
 Top 30 PySpark Interview Questions and Answers (2025)Apr 21, 2025 am 10:51 AM
Top 30 PySpark Interview Questions and Answers (2025)Apr 21, 2025 am 10:51 AMPySpark, the Python API for Apache Spark, empowers Python developers to harness Spark's distributed processing power for big data tasks. It leverages Spark's core strengths, including in-memory computation and machine learning capabilities, offering
 Self-Consistency in Prompt EngineeringApr 21, 2025 am 10:50 AM
Self-Consistency in Prompt EngineeringApr 21, 2025 am 10:50 AMHarnessing the Power of Self-Consistency in Prompt Engineering: A Comprehensive Guide Have you ever wondered how to effectively communicate with today's advanced AI models? As Large Language Models (LLMs) like Claude, GPT-3, and GPT-4 become increas


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

SublimeText3 English version
Recommended: Win version, supports code prompts!

SublimeText3 Chinese version
Chinese version, very easy to use

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

