
Home >Technology peripherals >AI >75-year-old Hinton's latest speech at the China Conference, 'Two Roads to Intelligence,' ended with emotion: I am already old, and the future is left to young people.
75-year-old Hinton's latest speech at the China Conference, 'Two Roads to Intelligence,' ended with emotion: I am already old, and the future is left to young people.

- 王林forward
- 2023-06-13 19:13:551465browse
"But I'm getting old, and all I want is for young, promising researchers like you to figure out how we can have these superintelligences that make our lives better, and Not controlled by them."
On June 10, in the closing speech of the 2023 Beijing Intelligent Source Conference, when talking about how to prevent super intelligence from deceiving and controlling humans, Geoffrey Hinton, the 75-year-old Turing Award winner this year, said with emotion.
Hinton’s speech is titled “Two Paths to Intelligence”. That is, immortal calculations performed in digital form and hardware-dependent immortal calculations, represented by digital computers and human brains respectively. At the end of the speech, he focused on the concerns about the threat of superintelligence brought to him by large language models (LLM). Regarding this topic involving the future of human civilization, he very straightforwardly showed his pessimistic attitude.
At the beginning of his speech, Hinton declared that superintelligence may be born much earlier than he once thought. This observation raises two major questions: (1) Will the intelligence level of artificial neural networks soon surpass that of real neural networks? (2) Can humans guarantee control of super AI? In his speech at the conference, he discussed the first question in detail; regarding the second question, Hinton said at the end of his speech: Superintelligence may be coming soon.

First, let’s look at traditional calculations. The design principle of computers is to be able to execute instructions accurately, which means that if we run the same program (whether it is a neural network or not) on different hardware, the effect should be the same. This means that the knowledge contained in the program (such as the weights of a neural network) is immortal and has nothing to do with the specific hardware.

To achieve the immortality of knowledge, we run transistors at high power so that they can be used digitally ) to operate reliably. But in doing so, we are equivalent to abandoning other properties of hardware, such as rich analog and high variability.

The reason traditional computers adopt that design pattern is because the programs running traditional computing are all written by humans. Now with the development of machine learning technology, computers have another way to obtain program and task goals: sample-based learning.
This new paradigm allows us to abandon one of the most basic principles of previous computer system design, that is, the separation of software design and hardware; instead, we can co-design software and hardware.
The advantage of software and hardware separation design is that the same program can be run on many different hardware. At the same time, when designing the program, we can only look at the software, regardless of the hardware - this is also a computer The reason why the Department of Science and the Department of Electronic Engineering can be established separately.
For software and hardware co-design, Hinton proposed a new concept: Mortal Computation. Corresponds to the immortal form of software mentioned above, which we translate here as "immortal computing".
What is mortal calculation?

Immortal computing gives up the immortality of running the same software on different hardware in favor of a new Design thinking: Knowledge is inseparable from the specific physical details of the hardware. This new idea naturally has its advantages and disadvantages. Key advantages include energy savings and low hardware costs.
In terms of energy saving, we can refer to the human brain, which is a typical mortal computing device. Although there are still one-bit digital calculations in the human brain, that is, neurons either fire or do not fire, overall, the vast majority of calculations in the human brain are analog calculations with very low power consumption.
Immortal computing can also use lower-cost hardware. Compared with today's processors, which are produced with high precision in a two-dimensional model, the hardware of immortal computing can be "grown" in a three-dimensional model because we do not need to know exactly how the hardware is connected and the exact function of each component. It is clear that in order to achieve the "growth" of computing hardware, we will need many new nanotechnologies or the ability to genetically modify biological neurons. Methods of engineering biological neurons may be easier to implement because we already know that biological neurons can roughly do the tasks we want.
To demonstrate the efficient capabilities of simulation calculations, Hinton gave an example: calculating the product of a neural activity vector and a weight matrix (most of the work of neural networks is such calculations ).

For this task, current computer practice is to use high-power transistors to convert values Represented in digitized bit form, O (n²) numeric operations are then performed to multiply two n-bit values. Although this is just a single operation on the computer, it is an n² bit operation.
And what if simulation calculations are used? We can think of neural activity as voltage and weight as conductance; then in each unit time, the voltage multiplied by the conductance can get the charge, and the charges can be superimposed. The energy efficiency of this way of working will be much higher, and in fact, chips that work in this way already exist. Unfortunately, Hinton said, people still have to use very expensive converters to convert the analog results into digital form. He hopes that in the future we can complete the entire calculation process in the simulation field.
Deadly computing also faces some problems, the most important of which is that it is difficult to ensure the consistency of the results, that is, the calculation results on different hardware may be different. In addition, we need to find new methods when backpropagation is not available.
Problems facing perishable computing: Backpropagation is not available
When learning to perform perishable calculations on specific hardware, you need to let the program learn to use the hardware specific simulated properties, but they don't need to know what those properties are. For example, they do not need to know how a neuron is internally connected or what function connects the neuron's input and output.

This means that we cannot use the back propagation algorithm to get the gradient because the reverse Propagation requires an exact forward propagation model.
So since backpropagation cannot be used in decaying calculations, what should we do? Let's look at a simple learning process performed on simulated hardware using a method called weight perturbation.

First, generate a random vector consisting of small random perturbations for each weight in the network. Then, based on one or a small number of samples, the change of the global objective function after using this perturbation vector is measured. Finally, according to the improvement of the objective function, the effect brought by the disturbance vector is permanently proportioned to the weight.
The advantage of this algorithm is that its general behavior pattern is consistent with backpropagation and also follows the gradient. But the problem is that it has very high variance. Therefore, when the network size increases, the noise generated when selecting random movement directions in the weight space will be large, making this method unsustainable. This means that this method is only suitable for small networks and not for large networks.

#Another approach is activity perturbation, which suffers from similar problems but also works better with larger networks.

Activity perturbation method is to perform a random vector on the overall input of each neuron Perturb, then observe the changes in the objective function under a small batch of samples, and then calculate how to change the weight of the neuron to follow the gradient.
Activity perturbations are much less noisy than weight perturbations. And this method is enough to learn simple tasks like MNIST. If you use a very small learning rate, then it behaves exactly like backpropagation, but much slower. If the learning rate is large, there will be a lot of noise, but it is enough to handle tasks like MNIST.
But what if our network scale is even larger? Hinton mentioned two approaches.
The first method is to use a huge number of objective functions, which means that instead of using a single function to define the goal of a large neural network, a large number of functions are used to define different neurons in the network. The group's local goals.

In this way, the large neural network is broken into parts, and we can Learning small multi-layer neural networks using activity perturbations. But here comes the question: Where do these objective functions come from?

##One possibility is to use unsupervised on local patches at different levels Comparative learning. It works like this: a local patch has multiple representation levels, and at each level, the local patch tries to be consistent with the average representation produced by all other local patches of the same image; at the same time, Try to remain distinct from other representations of images at that level.
Hinton said the approach works well in practice. The general approach is to have multiple hidden layers for each representation level, so that non-linear operations can be performed. These levels use activity perturbations for greedy learning and do not backpropagate to lower levels. Since it cannot pass as many layers as backpropagation, it will not be as powerful as backpropagation.
In fact, this is one of the most important research results of the Hinton team in recent years. For details, please refer to the report of the Heart of the Machine "After giving up backpropagation, Geoffrey Hinton participated in the previous Important research on learning from gradients is coming."

Mengye Ren has shown through extensive research that this method can actually be effective in neural networks, but it is very difficult to operate. It’s complicated, and the actual effect can’t keep up with backpropagation. If the depth of a large network is deeper, the gap with backpropagation will be even greater.
Hinton said that this learning algorithm that can take advantage of simulation properties can only be said to be OK, enough to handle tasks such as MNIST, but it is not really easy to use, such as on the ImageNet task. The performance is not very good.
Problems faced by perishable computing: inheritance of knowledge
Another major problem faced by perishable computing is that it is difficult to ensure the inheritance of knowledge. Because perishable computing is highly hardware-dependent, knowledge cannot be copied by copying weights, which means that when a specific piece of hardware “dies,” the knowledge it has learned disappears with it.
Hinton said the best way to solve the problem is to transfer knowledge to students before the hardware "dies." This type of method is called knowledge distillation, a concept first proposed by Hinton in the 2015 paper "Distilling the Knowledge in a Neural Network" co-authored with Oriol Vinyals and Jeff Dean.

The basic idea of this concept is very simple, similar to a teacher teaching students knowledge: the teacher shows the students the correct responses to different inputs, and the students try Model the teacher's response.
Hinton used former U.S. President Trump’s tweets as an example to give an intuitive explanation: Trump often makes very emotional comments about various events when he tweets. In response, this prompts his followers to change their "neural networks" to produce the same emotional response; in this way, Trump distills the prejudice into the minds of his followers, just as - Hinton clearly does not Don't like Trump.
How effective is the knowledge distillation method? Considering Trump's many supporters, the effect should not be bad. Hinton uses an example to explain: Suppose an agent needs to classify images into 1024 non-overlapping categories.

To identify the correct answer, we only need 10 bits of information. Therefore, to train the agent to correctly identify a specific sample, only 10 bits of information need to be provided to constrain its weights.
But what if we train an agent to have roughly the same probabilities as a teacher on these 1024 categories? That is, make the probability distribution of the agent the same as that of the teacher. This probability distribution has 1023 real numbers, and if these probabilities are not very small, it provides hundreds of times more constraints.

##In order to ensure that these probabilities are not too small, you can run the teacher at "high temperature" during training Students are also run at "high temperature" when they are students. For example, if you're using logit, that's the input to softmax. For teachers, they can scale it based on the temperature parameter to get a softer distribution; then use the same temperature when training students.
Let’s look at a specific example. Below are some images of character 2 from the MNIST training set, corresponding to the right are the probabilities assigned by the teacher to each image when the temperature at which the teacher is run is high.
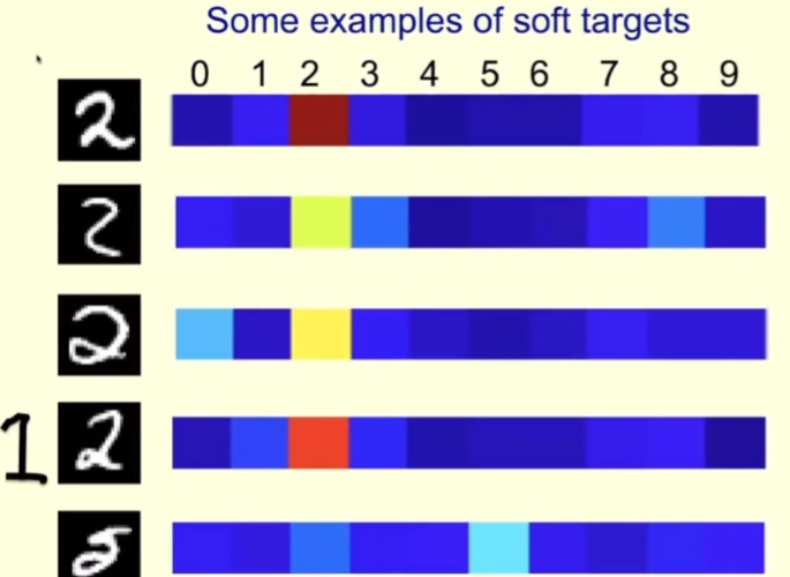
##For the first line, the teacher is confident that it is 2; the teacher is also confident that the second line is 2, but it Also thought it might be 3 or 8. The third line is something like 0. For this sample, the teacher should say it's a 2, but should also leave some room for a 0. In this way, students will learn more from it than if they were told directly that this is 2.
For the fourth line, you can see that the teacher is confident that it is 2, but it also thinks that it may be 1. After all, sometimes the 1 we write is similar to the one drawn on the left side of the picture. That way.
For the fifth row, the teacher made a mistake and thought it was 5 (but according to the MNIST label it should be 2). Students can also learn a lot from their teachers’ mistakes.
Distillation has a very special property, that is, when using the probability given by the teacher to train students, it is training the students to generalize in the same way as the teacher. If the teacher assigns a certain small probability to the wrong answer, students will also be trained to generalize to the wrong answer.

Obviously, we can create richer outputs for distillation. For example, we could give each image a description, rather than just a single label, and then train students to predict the words in those descriptions.



At the same time, since this method requires each agent to work in exactly the same way, it can only be a digital model.
The cost of weight sharing is also very high. Getting different pieces of hardware to work in the same way requires producing computers with such high precision that they always get the same results when they execute the same instructions. In addition, the power consumption of transistors is not low.

Distillation can also replace weight sharing. Especially when your model uses simulated properties of specific hardware, you cannot use weight sharing, but must use distillation to share knowledge.

The efficiency of sharing knowledge using distillation is not high and the bandwidth is very low. Just like in school, teachers want to pour the knowledge they know into students' heads, but this is impossible because we are biological intelligence, and your weight is of no use to me.

Here is a brief summary. Two completely different methods of performing calculations are mentioned above. methods (digital computing and biological computing), and the way knowledge is shared between agents is also very different.
So what is the form of large-scale language model (LLM) that is currently developing? They are numerical calculations that can use weight sharing.

But each replica agent of LLM can only perform a very inefficient distillation way to learn the knowledge in the document. What LLM does is predict the next word of the document, but there is no probability distribution of the next word by the teacher. All it has is a random selection, that is, the word chosen by the author of the document at the next word position. LLM actually learns from us humans, but the bandwidth to transfer knowledge is very low.
Then again, although the efficiency of each copy of LLM learning through distillation is very low, there are many of them, up to thousands, so they can learn Thousands of times more stuff than we have. Which means the current LLM is more knowledgeable than any of us.
Will super intelligence end human civilization?
Next Hinton raised a question: "What happens if these digital intelligences do not learn from us very slowly through distillation, but start learning directly from the real world?"

In fact, when LLM is learning documents, it is already learning what humans have accumulated over thousands of years. Knowledge. Because humans describe our understanding of the world through language, digital intelligence can directly acquire the knowledge accumulated by humans through text learning. Although distillation is slow, they do learn very abstract knowledge.
What if digital intelligence could perform unsupervised learning through image and video modeling? There is now a huge amount of imaging data available on the Internet, and in the future we may be able to find ways for AI to effectively learn from this data. In addition, if AI has methods such as robotic arms that can manipulate reality, it can further help them learn.
Hinton believes that if digital agents can do this, their learning capabilities will be far better than humans, and their learning speed will be very fast.
Now back to the question Hinton raised at the beginning: If AI’s intelligence exceeds ours, can we still control them?
Hinton said he gave the speech primarily to express his concerns. "I think superintelligence may emerge much sooner than I thought before," he said. He gave several possible ways for superintelligence to control humans.

## Bad actors might use superintelligence to manipulate elections or win wars (actually There are already people using existing AI to do these things).
In this case, if you want the superintelligence to be more efficient, you might allow it to create subgoals on its own. Controlling more power is an obvious sub-goal. After all, the greater the power and the more resources it controls, the better it can help the agent achieve its ultimate goal. The superintelligence might then discover that it can easily gain more power by manipulating the people who wield it.
It’s hard for us to imagine beings smarter than us and the ways we interact with them. But Hinton believes that a superintelligence smarter than us could definitely learn to trick humans, who have so many novels and political literature to learn from.
Once a superintelligence learns to trick humans, it can make humans perform the behaviors it wants. There is actually no essential difference between this and deceiving others. For example, Hinton said, if someone wants to hack a building in Washington, they don't actually have to go there, they just have to trick people into believing they're hacking the building to save democracy.
"I think this is very scary." Hinton's pessimism is palpable. "Now, I can't see how to prevent this from happening, but I am old." He hopes that young people Talented people can find ways to use superintelligence to help humans live better lives, rather than letting humans fall under their control.
But he also said we have an advantage, albeit a rather small one, in that AI did not evolve but was created by humans. In this way, AI does not have the same competitiveness and goals as original humans. Maybe we can set moral and ethical principles for AI in the process of creating them.
However, if it is a super intelligence whose intelligence level far exceeds that of humans, this may not be effective. Hinton says he has never seen a case where something of a higher level of intelligence was controlled by something of a far lower level of intelligence. Let's say that if frogs created humans, who controls whom between frogs and humans now?
Finally, Hinton pessimistically released the last slide of the speech:

This not only marks the end of the speech, but also serves as a warning to all mankind: superintelligence may lead to the end of human civilization.
The above is the detailed content of 75-year-old Hinton's latest speech at the China Conference, 'Two Roads to Intelligence,' ended with emotion: I am already old, and the future is left to young people.. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology