
Home >Technology peripherals >AI >There is evidence. MIT shows that large language models ≠ random parrots can indeed learn semantics.
There is evidence. MIT shows that large language models ≠ random parrots can indeed learn semantics.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-05-23 08:01:051107browse
While large pre-trained language models (LLMs) have demonstrated dramatically improved performance across a range of downstream tasks, do they truly understand the semantics of the text they use and generate?
The AI community has long been deeply divided on this issue. One guess is that language models trained purely on the form of language (such as the conditional distribution of tokens in a training corpus) will not acquire any semantics. Instead, they merely generate text based on superficial statistical correlations gleaned from training data, with their strong emergence capabilities attributed to the size of the model and training data. These people refer to LLM as the "random parrot".
But some people do not agree with this view. A recent study showed that approximately 51% of NLP community respondents agreed that “some generative models trained solely on text, given sufficient data and computational resources, can understand nature in some meaningful way.” Language (beyond surface-level statistical correlations, involving understanding of the semantics and concepts behind language)”.
In order to explore this unanswered question, researchers from MIT CSAIL conducted a detailed study.

##Paper address: https://paperswithcode.com/paper/evidence-of- meaning-in-language-models
The language model used in this study is only trained to be a model for text prediction of the next token, and two hypotheses are formulated:
- H1: A LM trained solely by predicting next tokens on text is fundamentally limited by repeating surface-level statistical correlations in its training corpus;
- H2LM is unable to assign meaning to the text it digests and generates.
In order to explore the correctness of the two hypotheses H1 and H2, this study applies language modeling to the program synthesis task, that is, given the formal specification of the input and output examples Download the synthesis program. This study takes this approach primarily because the meaning (and correctness) of a program is entirely determined by the semantics of the programming language.
Specifically, this study trains a language model (LM) on a corpus of programs and their specifications, and then uses a linear classifier to detect the hidden state of the LM for the semantic representation of the program. The study found that the detector's ability to extract semantics is stochastic at initialization and then undergoes a phase change during training that is strongly correlated with the LM's ability to generate correct programs without having seen the specification. Additionally, the study presents results from an interventional experiment showing that semantics are represented in model states (rather than learned via probes).
The main contributions of this research include:
1. The experimental results show that there are some problems in the LM that performs the task of predicting the next token. representation of meaning. Specifically, the study uses a trained LM to generate programs given several input-output examples, and then trains a linear detector to extract information about the program state from the model state. Researchers found that the internal representation contains the following linear encoding: (1) abstract semantics (abstract interpretation) - tracking specified inputs during program execution; (2) future program state predictions corresponding to program tokens that have not yet been generated. During training, these linear representations of semantics develop in parallel with the LM's ability to generate correct programs during the training step.
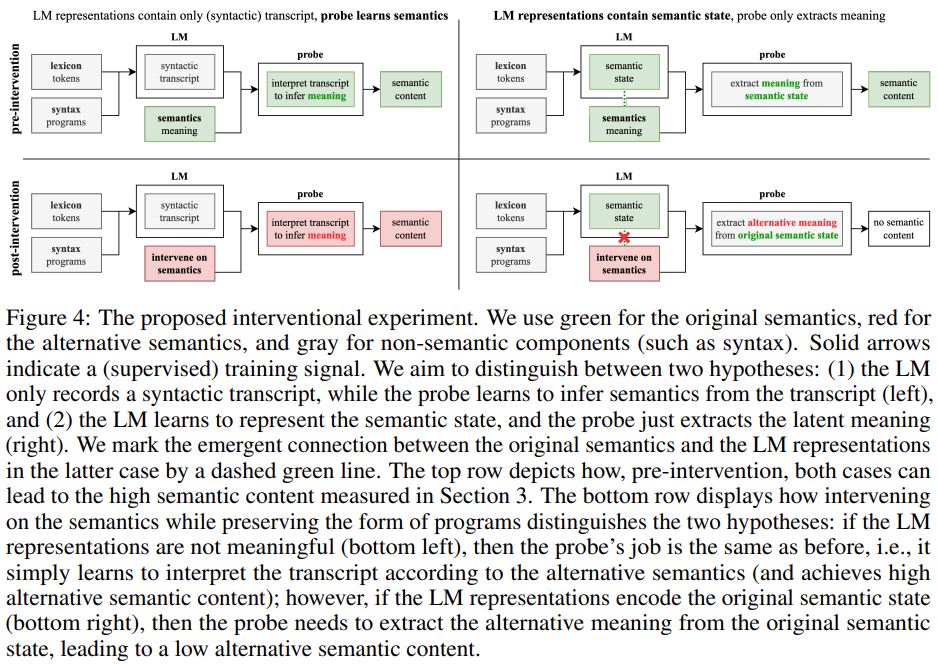
2. This study designed and evaluated a novel interventional method to explore the contributions of LM and detectors when extracting meaning from representations. Specifically, this study attempts to analyze which of the following two questions holds true: (1) LM representations contain pure (syntactic) transcripts while the detector learns to interpret the transcripts to infer meaning; (2) LM representations contain semantics State,detectors simply extract meaning from semantic states. The experimental results show that the LM representation is actually aligned with the original semantics (rather than just encoding some lexical and syntactic content), suggesting that hypothesis H2 is wrong.
3. This study shows that the output of LM is different from the training distribution, specifically manifested in that LM tends to generate shorter programs than those in the training set (and still be correct). Although LM's ability to synthesize correct programs has improved, LM's perplexity on programs in the training set remains high, indicating that hypothesis H1 is wrong.
Overall, this study proposes a framework for empirically studying LM based on the semantics of programming languages. This approach allows us to define, measure, and experiment with concepts from the precise formal semantics of the underlying programming language, thus contributing to the understanding of the emergent capabilities of current LMs.
Research background
This research uses trace semantics as a program meaning model. As a fundamental topic in programming language theory, formal semantics studies how to formally assign semantics to strings in a language. The semantic model used in this study consists of tracing the execution of a program: given a set of inputs (i.e., variable assignments), the meaning of a (syntactic) program is identified by semantic values computed from the expressions, and the trace is executed based on the inputs A sequence of intermediate values generated by the program.
There are several important reasons for using trace trajectories for program meaning models: first, the ability to accurately trace a piece of code is directly related to the ability to interpret the code; second, computer science education also emphasizes tracing It is an important method for understanding program development and locating reasoning errors; third, professional program development relies on tracing-based debuggers (dbugger).
The training set used in this study contained 1 million randomly sampled Karel programs. In the 1970s, Stanford University graduate Rich Pattis designed a programming environment that allowed students to teach robots to solve simple problems. This robot was called the Karel robot.
This study uses random sampling to construct a reference program for training samples, then samples 5 random inputs and executes the program to obtain the corresponding 5 outputs. The LM is trained to perform next token prediction on a corpus of samples. At the time of testing, this study only provides input and output prefixes to LM and uses greedy decoding to complete the program. Figure 1 below depicts the completion of an actual reference program and the trained LM.
This study trained a ready-made Transformer model to perform next token prediction on the data set. After 64,000 training steps and approximately 1.5 epochs, the finally trained LM achieved a generation accuracy of 96.4% on the test set. Every 2000 training steps, the study captured a trace dataset. For each training trajectory dataset, the study trains a linear detector to predict the program state given the model state.
The emergence of meaning
The researchers studied the following hypothesis: In the process of training the language model to perform the next token prediction, the representation of the semantic state will be a by-product Appears in model state. Considering that the final trained language model achieved a generation accuracy of 96.4%, if this hypothesis is rejected, it would be consistent with H2, that is, the language model has learned to use "only" surface statistics to consistently generate correct programs.
To test this hypothesis, the researchers trained a linear detector to extract the semantic state from the model state as five independent 4-way tasks (each input-oriented one direction), as described in Section 2.2.
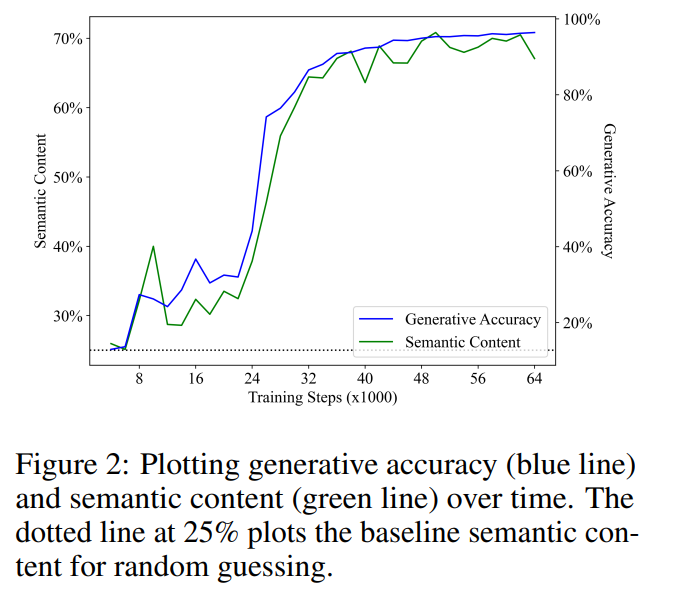
Meaning emergence is positively correlated with generation accuracy
Figure 2 shows the main results. Our first observation is that semantic content starts from baseline performance of random guessing (25%) and increases significantly during training. This result shows that the hidden state of the language model does indeed contain a (linear) encoding of the semantic state, and crucially, this meaning emerges in a language model purely used to perform next token predictions on text.
Linear regression was performed between generation accuracy and semantic content. The two showed an unexpectedly strong and statistically significant linear correlation during the training step (R2 = 0.968, p < ; 0.001), i.e. the variation in the LM's ability to synthesize correct programs is almost entirely explained by the semantic content of the LM's hidden layers. This shows that, within the scope of our experimental setup, learning to model the distribution of correct programs is directly related to the meaning of the learned programs, which negates the idea that language models cannot capture meaning (H2).
Representation is a prediction of future program semantics
The previous section discussed whether a language model can represent the meaning of the text it generates. The results of this paper give a positive answer to the question that language models are able to (abstractly) explain the generated programs. However, the interpreter is not the same as the synthesizer, and the ability to understand alone is not enough to generate. As far as the emergence of human language is concerned, there is broad consensus that language originates from a non-verbal message in the mind and is then transformed into utterance that reflects the original concept. The researchers hypothesize that the generation process of the trained language model follows a similar mechanism, that is, the representation of the language model encodes the semantics of the text that has not yet been generated.
To test this hypothesis, they trained a linear detector using the same method as above to predict future semantic states derived from the model states. Note that since they use a greedy decoding strategy, the future semantic state is also deterministic and thus the task is well-defined.
Figure 3 shows the performance of linear detectors in predicting the semantic state of steps 1 and 2 in the future (the green segment line represents "Semantic (1)", the green dotted line represents " Semantic (2)"). Similar to previous results, the detector's performance started from a baseline of random guessing and then improved significantly with training, and they also found that the semantic content of future states showed a strong correlation with the generation accuracy (blue line) during the training step. sex. The R2 values obtained by linear regression analysis of semantic content and generation accuracy are 0.919 and 0.900 respectively, corresponding to the semantic status of 1 step and 2 steps in the future, and the p values of both are less than 0.001.
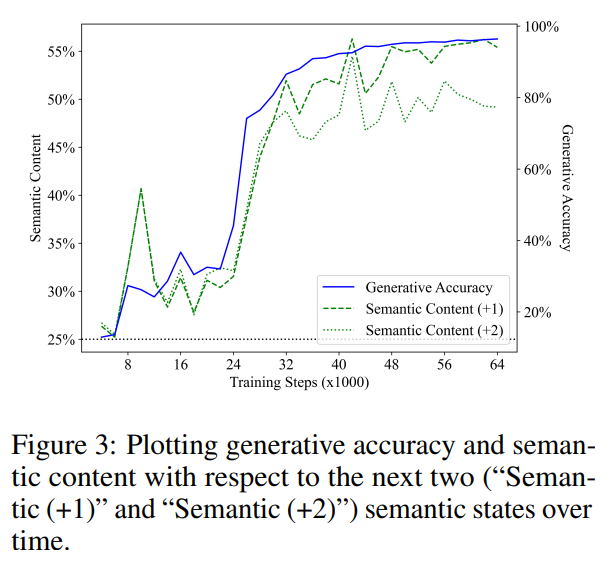
They also considered the assumption that the model’s representation only encodes the current semantic state, and the detector simply starts from the current semantic state Predict future semantic states. To test this hypothesis, they computed an optimal classifier that maps the ground truth facing direction in the current program to one of 4 facing directions in future programs.
It should be noted that 3 of the 5 operations maintain the facing direction, and the next token is evenly sampled. Therefore, they expected that, for the situation 1 step into the future, the optimal classifier for predicting the future semantic state should achieve 60% accuracy by predicting that the facing direction remains unchanged. In fact, by directly fitting the test set, they found that the upper bounds of predicting future semantic states from the current semantic state are 62.2% and 40.7%, respectively (corresponding to cases 1 and 2 steps into the future). In comparison, the detectors were 68.4% and 61.0% accurate at predicting future states, given that the detector correctly predicted the current state.
This shows that the detector's ability to extract future semantic states from model states cannot be inferred solely from representations of current semantic states. Therefore, their results show that language models learn to represent the meaning of tokens that have not yet been generated, which rejects the idea that language models cannot learn meaning (H2), and also shows that the generation process is not based on purely surface statistics (H1).
The generated output is different from the training distribution
Next, the researcher provides a rebuttal by comparing the program distribution generated by the trained language model with the program distribution in the training set Evidence for H1. If H1 holds, they expect that the two distributions should be roughly equal because the language model is simply replicating the statistical correlations of the text in the training set.
Figure 6a shows the average length of LM-generated programs over time (solid blue line), compared with the average length of the reference program in the training set (dashed red line) Compared. They found a statistically significant difference, indicating that the LM's output distribution is indeed different from the program distribution in its training set. This contradicts the point mentioned in H1 that LM can only replicate statistical correlations in its training data.
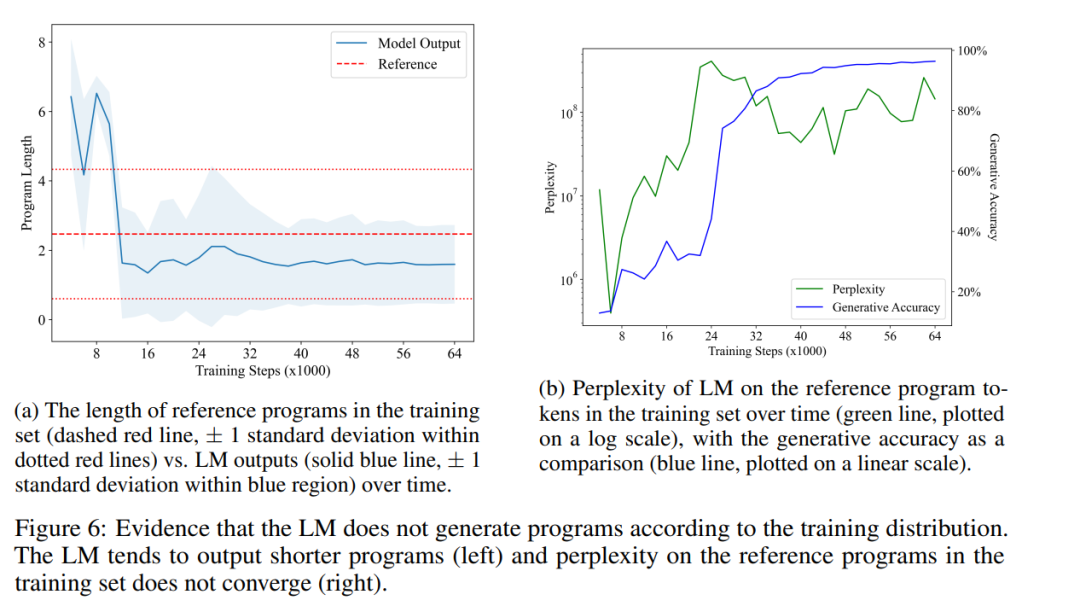
Finally, they also measured how the perplexity of the LM program in the training set changed over time. Figure 6b shows their results. As can be seen, LM never learns to fit the distribution of programs in the training set well, which further refutes H1. This may be because the randomly sampled programs in the training set contain many no-op instructions, while LM prefers to generate more concise programs. Interestingly, a sharp increase in perplexity—as LM moves beyond the imitation stage—seems to lead to improvements in generation accuracy (and semantic content). Since the problem of program equivalence is closely related to program semantics, LM's ability to generate short and correct programs shows that it has indeed learned some aspect of semantics.
For details, please refer to the original paper.
The above is the detailed content of There is evidence. MIT shows that large language models ≠ random parrots can indeed learn semantics.. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology