
Home >Technology peripherals >AI >A review of visual methods for trajectory prediction
A review of visual methods for trajectory prediction

- PHPzforward
- 2023-05-22 23:54:161589browse
A recent review paper "Trajectory-Prediction With Vision: A Survey" comes from Hyundai and Aptiv's company Motional; however, it refers to the review article "Vision-based Intention and Trajectory Prediction in Autonomous Vehicles: A Survey" by Oxford University ".
The prediction task is basically divided into two parts: 1) Intention, which is a classification task that pre-designs a set of intention classes for the agent; it is usually regarded as a supervised learning problem, and it is necessary to label the possibility of the agent Classification intention; 2) Trajectory, which requires predicting a set of possible positions of the agent in subsequent future frames, called waypoints; this constitutes the interaction between agents and between agents and roads.
Previous behavioral prediction models can be divided into three categories: physics-based, maneuver-based and interaction-perception models. This sentence can be rewritten as: Using the dynamic equations of the physical model, artificially controllable movements are designed for various types of agents. This method cannot model the potential states of the entire situation, but usually only focuses on a specific agent. However, in the era before deep learning, this trend used to be SOTA. Maneuver-based models are models based on the type of movement expected by the agent. An interaction-aware model is typically a machine learning-based system that performs pairwise inference for each agent in the scene and generates interaction-aware predictions for all dynamic agents. There is a high degree of correlation between different nearby agent targets in the scene. Modeling complex agent trajectory attention modules can lead to better generalization.
Predicting future actions or events can be expressed implicitly, or its future trajectory can be explicit. The agent's intentions may be influenced by: a) the agent's own beliefs or wishes (which are often not observed and therefore difficult to model); b) social interactions, which can be modeled in different ways, e.g. Pooling, graph neural networks, attention, etc.; c) environmental constraints, such as road layout, which can be encoded through high-definition (HD) maps; d) background information in the form of RGB image frames, lidar point clouds, optical flow, segmentation Figure etc. Trajectory prediction, on the other hand, is a more challenging problem since it involves regression (continuous) rather than classification problems, unlike recognizing intent.
Trajectory and intention need to start from interaction-awareness. A reasonable assumption is that when trying to drive aggressively onto a highway with heavy traffic, a passing vehicle may brake hard. Modeling. It is better to model in BEV space, which allows trajectory prediction, but also in the image view (also called perspective). This sentence can be rewritten as: "This is because regions of interest (RoIs) can be assigned in the form of a grid to a dedicated distance range.". However, due to the vanishing line in perspective, the image perspective can theoretically expand the RoI infinitely. BEV space is more suitable for modeling occlusion because it models motion more linearly. By performing attitude estimation (translation and rotation of the own vehicle), compensation of own motion can be carried out simply. In addition, this space preserves the motion and scale of the agent, that is, the surrounding vehicles will occupy the same number of BEV pixels no matter how far away they are from the self-vehicle; but this is not the case for the image perspective. In order to predict the future, one needs to have an understanding of the past. This can usually be done through tracking, or it can be done with historical aggregated BEV features.
The following figure is a block diagram of some components and data flow of the prediction model:
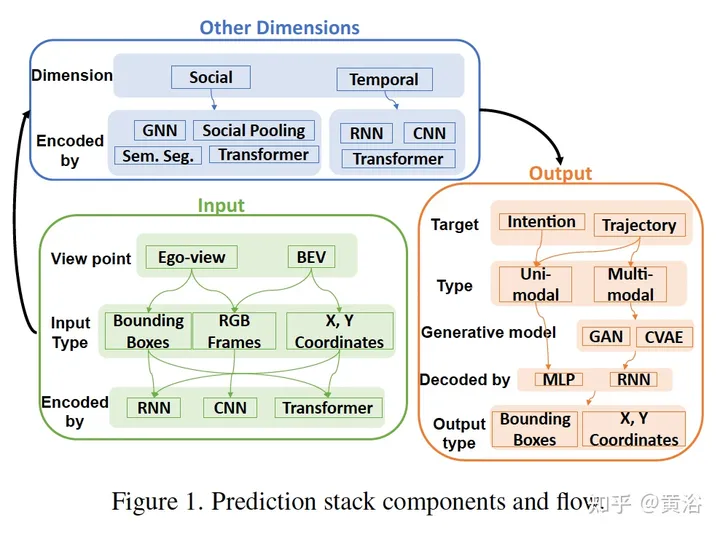
The following table is a summary of the prediction model:
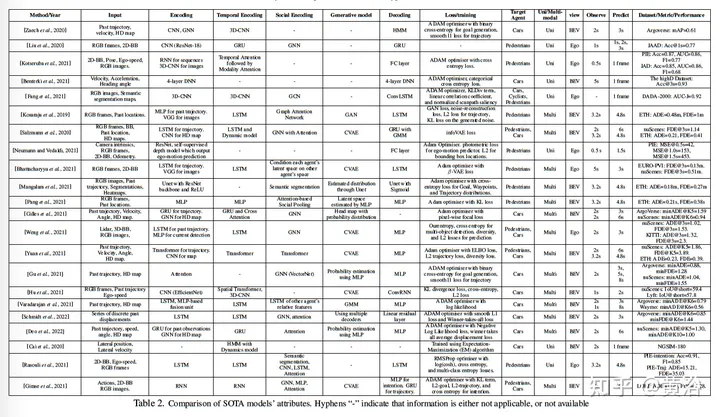
The following basically discusses the prediction model starting from input/output:
1) Tracklets: The perception module predicts the current status of all dynamic agents. This state includes 3-D center, dimensions, velocity, acceleration and other attributes. Trackers can leverage this data and establish temporary associations so that each tracker can preserve a history of the state of all agents. Now, each tracklet represents the agent's past movements. This form of predictive model is the simplest since its input consists only of sparse trajectories. A good tracker is able to track an agent even if it is occluded in the current frame. Since traditional trackers are based on non-machine learning networks, it becomes very difficult to implement an end-to-end model.
2) Raw sensor data: This is an end-to-end method. The model obtains raw sensor data information and directly predicts the trajectory prediction of each agent in the scene. This method may or may not have auxiliary outputs and their losses to supervise complex training. The disadvantage of this type of approach is that the input is information intensive and computationally expensive. This is due to the merging of the three problems of perception, tracking and prediction, making the model difficult to develop and even more difficult to achieve convergence.
3) Camera-vs-BEV: The BEV method processes data from a top-view map, and the camera prediction algorithm perceives the world from the perspective of the self-vehicle. The latter is usually more challenging than the former for a variety of reasons; first, from BEV perception can obtain a wider field of view and richer prediction information. In comparison, the camera's field of view is shorter, which limits the prediction range because the car cannot plan outside the field of view; in addition, the camera is more likely to be blocked, so it is different from the camera based on Compared with the camera method, the BEV method is subject to fewer "partial observability" challenges; secondly, unless lidar data is available, monocular vision makes it difficult for the algorithm to infer the depth of the agent in question, which is an important clue to predict its behavior ; Finally, the camera is moving, which needs to deal with the movement of the agent and the self-vehicle, which is different from the static BEV; A word of caution: As a shortcoming, the BEV representation method still has the problem of accumulated errors; although in processing the camera view There are inherent challenges, but it is still more practical than BEVs, and cars rarely have access to cameras that show the location of BEVs and concerned agents on the road. The conclusion is that the prediction system should be able to see the world from the perspective of the self-vehicle, including lidar and/or stereo cameras, whose data may be advantageous to perceive the world in 3D; another important related point is that every time if attention must be included When predicting the position of the agent, it is better to use the bounding box position rather than the pure center point, because the coordinates of the former imply changes in the relative distance between the vehicle and the pedestrian as well as the self-motion of the camera; in other words, as the agent As the body approaches the self-vehicle, the bounding box becomes larger, providing an additional (albeit preliminary) estimate of depth.
4) Self-motion prediction: Model the self-vehicle motion to generate a more accurate trajectory. Other approaches use deep networks or dynamical models to model the motion of the agent of interest, leveraging additional quantities computed from the dataset input, such as poses, optical flow, semantic maps, and heat maps.
5) Time domain encoding: Since the driving environment is dynamic and there are many active agents, it is necessary to encode in the agent time dimension to build a better prediction system that compares what happened in the past with The future is connected by what is happening now; knowing where the agent comes from helps guess where the agent might go next. Most camera-based models deal with shorter time scales, while for longer time scales deal with predictions. The model requires a more complex structure.
6) Social Encoding: To address the “multi-agent” challenge, most of the best-performing algorithms use different types of graph neural networks (GNN) to encode social interactions between agents; most Methods encode the temporal and social dimensions separately—either starting with the temporal dimension and then considering the social dimension, or in reverse order; there is a Transformer-based model that encodes both dimensions simultaneously.
7) Prediction based on expected goals: Behavioral intention prediction, like scene context, is usually affected by different expected goals and should be inferred through explanation; for future predictions conditioned on expected goals, this goal Will be modeled as the future state (defined as destination coordinates) or the type of movement expected by the agent; research in neuroscience and computer vision shows that people are usually goal-oriented agents; in addition, while making decisions, people Following a series of successive levels of reasoning, ultimately formulating a short or long-term plan; based on this, the question can be divided into two categories: the first is cognitive, answering the question of where the agent is going; the second is arbitrary Sexually, answer the question of how this agent achieves its intended goals.
8) Multi-modal prediction: Since the road environment is stochastic, a previous trajectory can unfold different future trajectories; therefore, a practical prediction system that solves the "stochasticity" challenge will have a huge impact on the problem. Uncertainty is modeled; although there are methods for latent space modeling of discrete variables, multimodality is only applied to trajectories, fully showing its potential in intention prediction; an attention mechanism is used, which can be used to calculate weights.
The above is the detailed content of A review of visual methods for trajectory prediction. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology