
Home >Technology peripherals >AI >Completely solve ChatGPT amnesia! Breaking through the Transformer input limit: measured to support 2 million valid tokens
Completely solve ChatGPT amnesia! Breaking through the Transformer input limit: measured to support 2 million valid tokens

- 王林forward
- 2023-05-13 14:07:062151browse
ChatGPT, or the Transformer class model, has a fatal flaw, that is, it is too easy to forget. Once the token of the input sequence exceeds the context window threshold, the subsequent output content will not match the previous logic.
ChatGPT can only support the input of 4000 tokens (about 3000 words). Even the newly released GPT-4 only supports a maximum token window of 32000. If the input sequence length continues to be increased, the computational complexity will also increase. will grow quadratically.
Recently, researchers from DeepPavlov, AIRI, and the London Institute of Mathematical Sciences released a technical report using the Recurrent Memory Transformer (RMT) to increase BERT's effective context length to "an unprecedented 2 million tokens." while maintaining high memory retrieval accuracy.
Paper link: https://www.php.cn/link/459ad054a6417248a1166b30f6393301
This method can store and process local and global information, and use loops to allow the information to be stored in each part of the input sequence. flow between segments.
The experimental section demonstrates the effectiveness of this approach, which has extraordinary potential to enhance long-term dependency processing in natural language understanding and generation tasks, enabling large-scale context processing for memory-intensive applications.
However, there is no free lunch in the world. Although RMT can not increase memory consumption and can be extended to nearly unlimited sequence lengths, there is still the problem of memory decay in RNN and longer inference time is required.

But some netizens have proposed a solution, RMT is used for long-term memory, large context is used for short-term memory, and then model training is performed at night/during maintenance.
Cyclic Memory Transformer
In 2022, the team proposed the cyclic memory Transformer (RMT) model, by adding a special memory token to the input or output sequence, and then training the model to control Memory operations and sequence representation processing can implement a new memory mechanism without changing the original Transformer model.

Paper link: https://arxiv.org/abs/2207.06881
Published conference: NeurIPS 2022
with Transformer-XL In comparison, RMT requires less memory and can handle longer sequences of tasks.
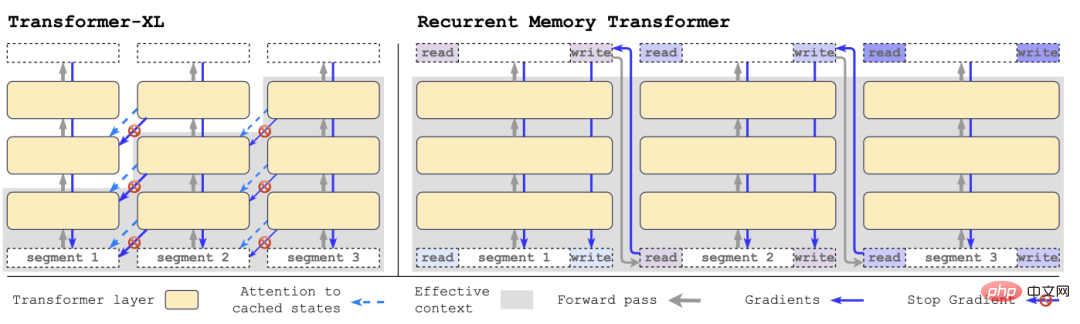
Specifically, RMT consists of m real-valued trainable vectors. The input sequence that is too long is divided into several segments, and the memory vector is preset to in the first segment embedding and processed together with the segment token.
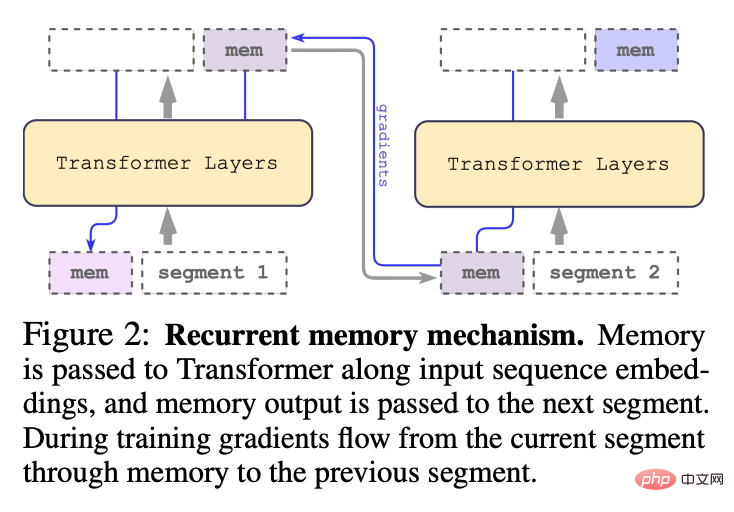
Different from the original RMT model proposed in 2022, for a pure encoder model like BERT, the memory is only added once at the beginning of the segment; the decoding model will Memory is divided into two parts: reading and writing.
In each time step and segment, loop as follows, where N is the number of Transformer layers, t is the time step, and H is the segment
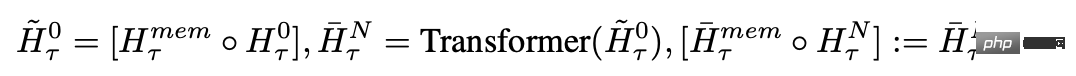
After processing the segments of the input sequence in order, in order to achieve recursive connection, the researcher passes the output of the memory token of the current segment to the input of the next segment:
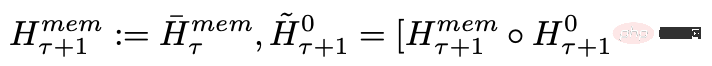
The memory and loop in RMT are only based on global memory tokens, which can keep the backbone Transformer model unchanged, making RMT's memory enhancement capability compatible with any Transformer model.
Computational efficiency
According to the formula, the FLOPs required for RMT and Transformer models of different sizes and sequence lengths can be estimated
In terms of vocabulary size, number of layers, hidden size, and intermediate Regarding the parameter configuration of the hidden size and number of attention heads, the researchers followed the configuration of the OPT model and calculated the number of FLOPs after the forward pass, taking into account the impact of the RMT cycle.
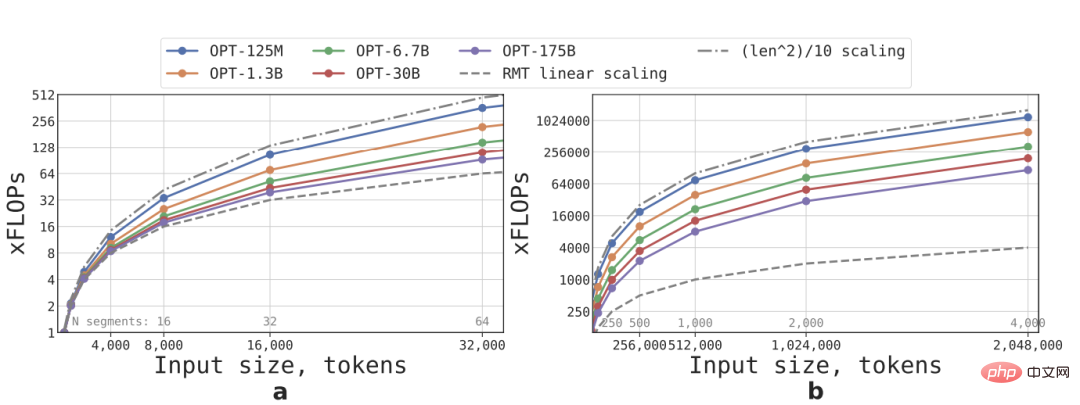
Linear expansion is achieved by dividing an input sequence into several segments and calculating the entire attention matrix only within the boundaries of the segment. The result can be seen that if the segment length Fixed, the inference speed of RMT increases linearly for any model size.
Due to the large amount of calculation of the FFN layer, larger Transformer models tend to show a slower quadratic growth rate relative to the sequence length. However, on extremely long sequences with a length greater than 32,000, FLOPs return to quadratic. state of growth.
For sequences with more than one segment (larger than 512 in this study), RMT has lower FLOPs than acyclic models, and can increase the efficiency of FLOPs by up to ×295 times on smaller models. ; In larger models such as OPT-175B, it can be increased by ×29 times.
Memory Task
To test memory abilities, the researchers constructed a synthetic dataset that required the model to memorize simple facts and basic reasoning.
Task input consists of one or several facts and a question that can only be answered with all of these facts.
In order to increase the difficulty of the task, natural language text that is not related to the question or answer is also added to the task. These texts can be regarded as noise, so the task of the model is actually to separate the facts from the irrelevant text. , and use factual text to answer questions.

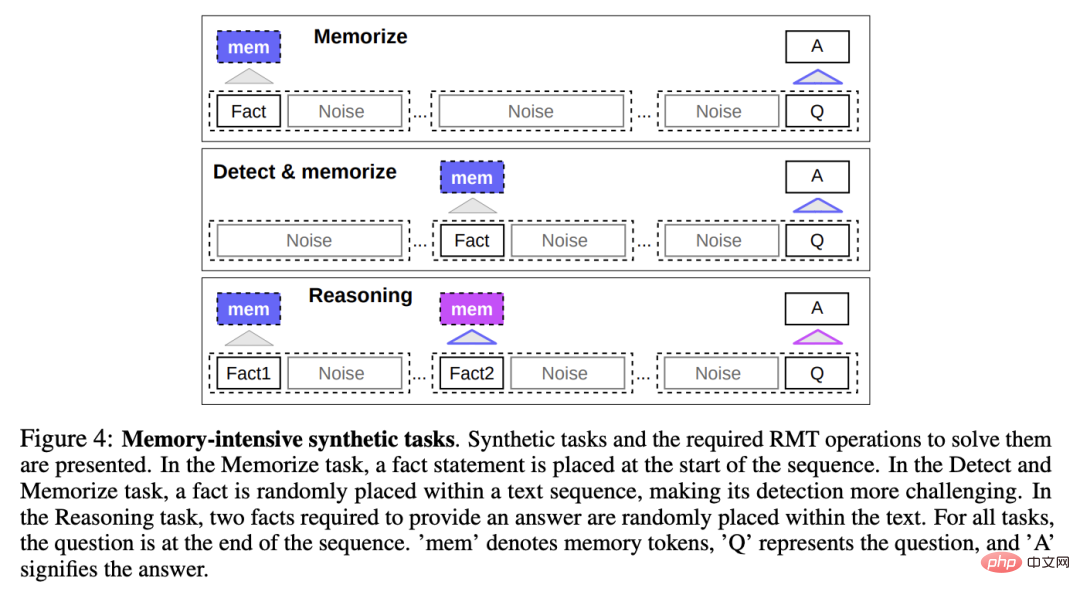
Factual Memory
Test RMT writes and stores information in memory for long periods of time Power: In the simplest case, the facts are at the beginning of the input, the questions are at the end of the input, and gradually increase the amount of irrelevant text between questions and answers until the model cannot accept all the input at once.

Fact detection and memory
Fact detection increases the difficulty of the task by moving the fact to a random position in the input, requiring The model first separates facts from irrelevant text, writes them into memory, and then answers the question at the end.
Reasoning based on memorized facts
Another important operation of memory is to use memorized facts and the current context to reason.
To evaluate this feature, the researchers introduced a more complex task in which two facts are generated and randomly placed in the input sequence; a question asked at the end of the sequence must be chosen to answer the question with the correct fact .

Experimental results
The researchers used the pre-trained Bert-base-cased model in HuggingFace Transformers as the backbone of RMT in all experiments, and all models were based on memory Enhanced with a size of 10.
Train and evaluate on 4-8 NVIDIA 1080Ti GPUs; for longer sequences, switch to a single 40GB NVIDIA A100 for accelerated evaluation.
Curriculum Learning
The researchers observed that using training scheduling can significantly improve the accuracy and stability of the solution.
Initially let RMT train on a shorter task version. After the training converges, increase the task length by adding a segment, and continue the course learning process until the ideal input length is reached.
Start the experiment with a sequence that fits a single segment. The actual segment size is 499 because 3 BERT's special markers and 10 memory placeholders are retained from the model input, giving a total size of 512.
It can be noticed that after training on shorter tasks, RMT is easier to solve longer tasks because it converges to a perfect solution using fewer training steps.
Extrapolation Abilities
In order to observe the generalization ability of RMT to different sequence lengths, the researchers evaluated models trained on different numbers of segments. , to solve tasks of greater length.
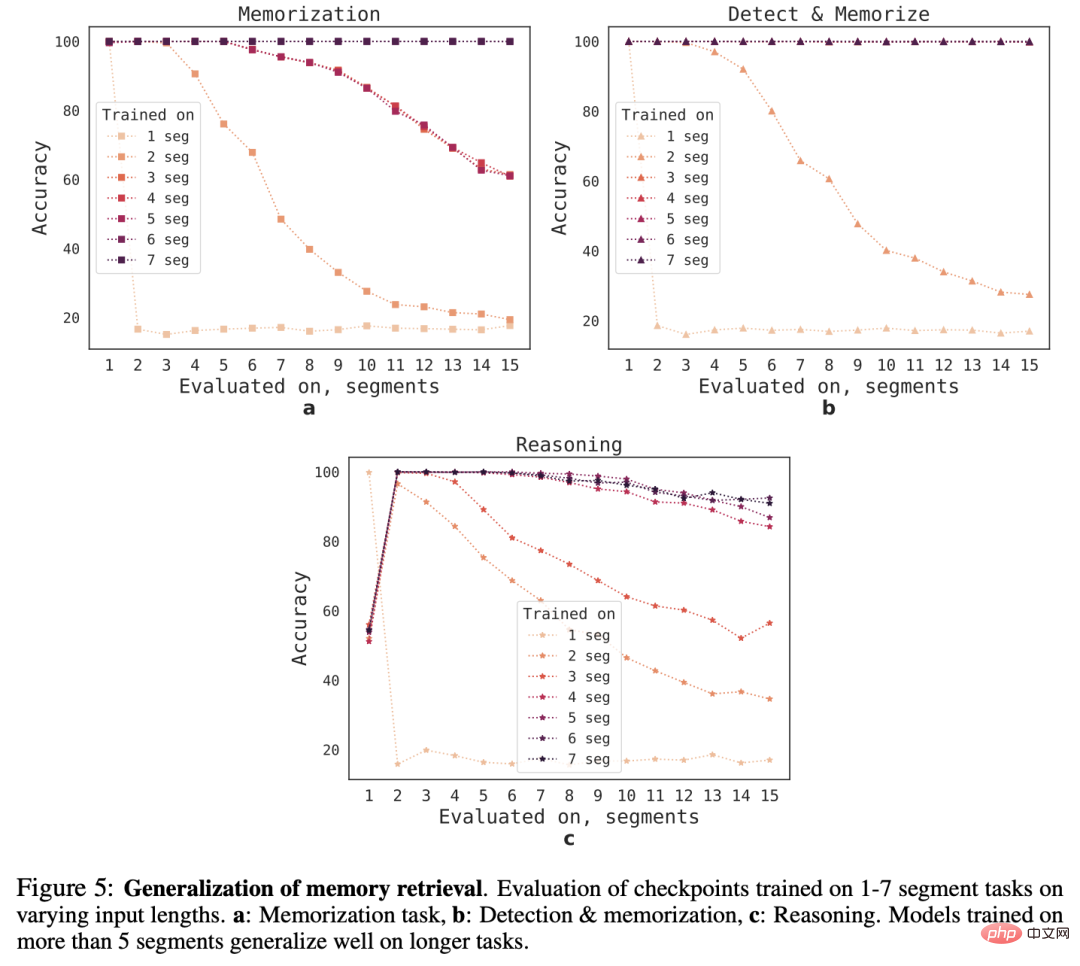
It can be observed that the model often performs well on shorter tasks, but after training the model on a longer sequence, it becomes difficult to handle single-segment inference tasks.
One possible explanation is that because the task size exceeds one segment, the model stops anticipating the problem in the first segment, resulting in a decline in quality.
Interestingly, as the number of training segments increases, RMT's generalization ability to longer sequences also appears. After training on 5 or more segments, RMT can handle twice as long sequences. nearly perfect generalization of tasks.
In order to test the limit of generalization, the researchers increased the size of the verification task to 4096 segments (i.e. 2,043,904 tokens).
RMT holds up surprisingly well on such long sequences, of which the "detection and memory" task is the simplest and the inference task is the most complex.
Reference materials: https://www.php.cn/link/459ad054a6417248a1166b30f6393301
The above is the detailed content of Completely solve ChatGPT amnesia! Breaking through the Transformer input limit: measured to support 2 million valid tokens. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology