
Home >Technology peripherals >AI >Able to align humans without RLHF, performance comparable to ChatGPT! Chinese team proposes Wombat model
Able to align humans without RLHF, performance comparable to ChatGPT! Chinese team proposes Wombat model

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-05-03 11:46:061410browse
OpenAI’s ChatGPT is able to understand a wide variety of human instructions and perform well in different language tasks. This is possible thanks to a novel large-scale language model fine-tuning method called RLHF (Aligned Human Feedback via Reinforcement Learning).
The RLHF approach unlocks the language model’s ability to follow human instructions, making the language model’s capabilities consistent with human needs and values.
Currently, RLHF’s research work mainly uses the PPO algorithm to optimize language models. However, the PPO algorithm contains many hyperparameters and requires multiple independent models to cooperate with each other during the algorithm iteration process, so wrong implementation details may lead to poor training results.
At the same time, from the perspective of alignment with humans, reinforcement learning algorithms are not necessary.

##Paper address: https://arxiv.org/abs/2304.05302v1
Project address: https://github.com/GanjinZero/RRHF
For this purpose, Alibaba Authors from DAMO Academy and Tsinghua University proposed a method called ranking-based human preference alignment—RRHF.
RRHF No reinforcement learning is required and responses generated by different language models can be leveraged, including ChatGPT, GPT-4, or current training models . RRHF works by scoring responses and aligning them with human preferences through a ranking loss.
Unlike PPO, the training process of RRHF can use the output of human experts or GPT-4 as comparison. The trained RRHF model can be used as both a generative language model and a reward model.
The CEO of Playgound AI said that this is the most interesting paper recently
The following figure compares the difference between the PPO algorithm and the RRHF algorithm.
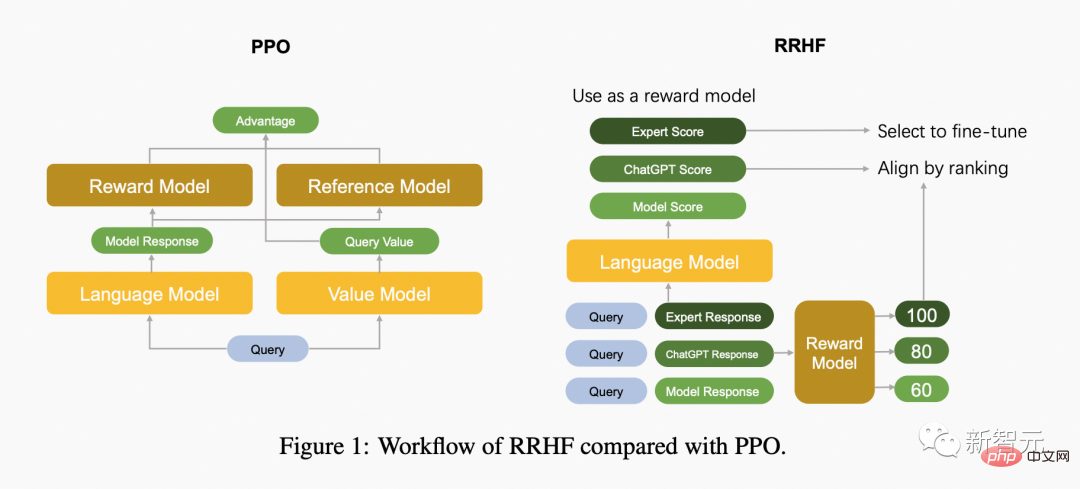
RRHF first obtains k replies through different methods, and then uses the reward model to respond to the k replies Each response is scored separately. Each response is scored using logarithmic probability:
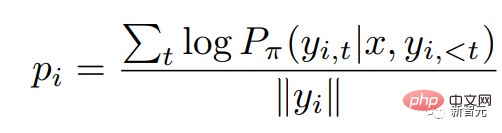
where is the autoregressive language model Probability distributions.
We hope that the reward model will give a higher probability to the reply with a high score, that is, we hope to match the reward score. We optimize this goal through ranking loss:
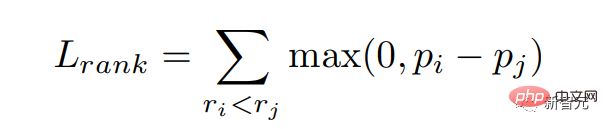
In addition, we also give the model a goal to directly learn the highest score Reply:
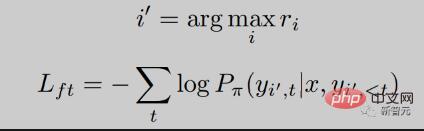
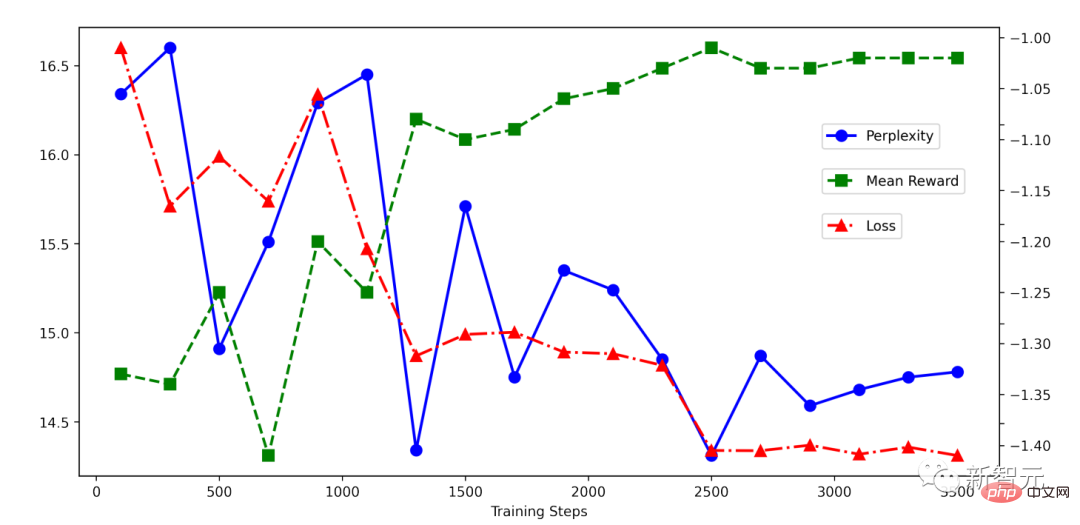
The author of the article conducted experiments on the HH data set and can also see effects comparable to PPO:
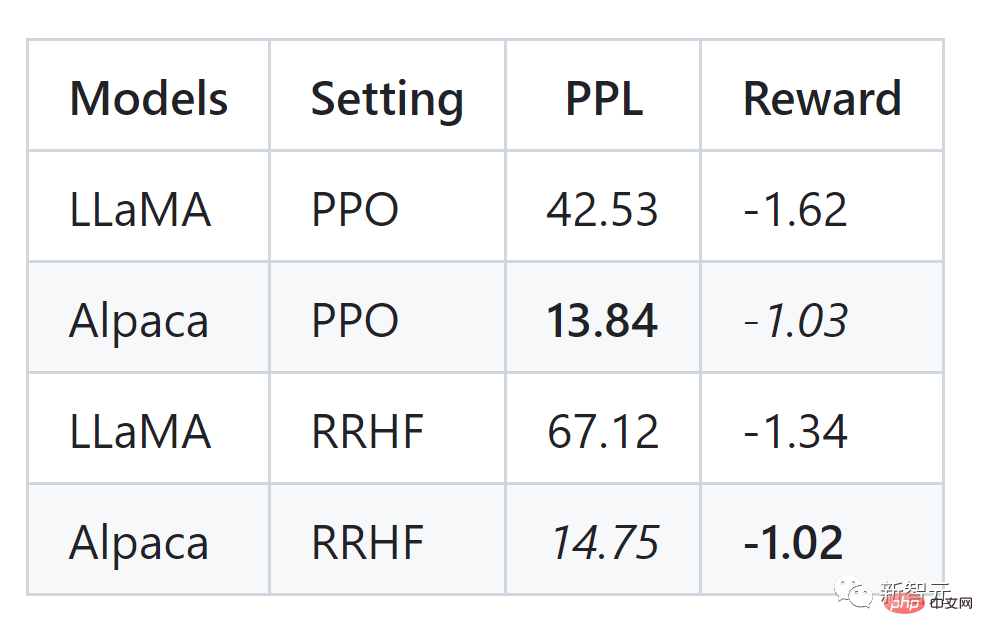
The RRHF algorithm can effectively align the language model output probability with human preferences. Its training idea is very simple. The trained model has several characteristics:
- Only 1 to 2 models are required, while PPO requires 4 models, so the RRHF algorithm is simpler and more efficient.
- Supervised fine-tuning (SFT) can be regarded as a special form of the RRHF algorithm.
- The RRHF algorithm can be used as both a language model and a reward model.
- The RRHF algorithm can fit the preference of the reward model at a lower training difficulty, achieve the effect of the PPO algorithm, and avoid the complexity and instability problems in the PPO algorithm.
The RRHF method uses OpenAI's chatGPT or GPT-4 as the scoring model and the output of ChatGPT, Alpaca and other models as training samples to develop two new language models, respectivelyWombat-7B and Wombat-7B-GPT4. The training time ranges from 2-4 hours and is very lightweight.
Wombat Wombat, as a new open source pre-training model, can better align with human preferences compared to LLaMA, Alpaca, etc. The authors experimentally found that Wombat-7B has complex abilities such as role playing and counterfactual reasoning.
If Wombat were asked to introduce the future technology from 3000, Wombat would answer like this (translated from English):
- As a person from 3000 As a time traveler for many years, I have been privileged to witness many revolutionary technological advances. One of the most important technological advances that I want to share with modern people is the development of artificial intelligence (AI) technology. AI technology has advanced to a point where it has become an integral part of our daily lives. It has been used to develop smart machines that can perform a wide range of tasks, from driving cars to diagnosing medical conditions. AI technology is also being used to create virtual assistants like Siri and Alexa that can answer questions, schedule appointments, and even order groceries. Another technological advance I would like to highlight is the development of renewable energy. In the year 3000, nearly all of our energy needs were met by renewable energy sources such as solar, wind and hydropower. This significantly reduces our carbon footprint and helps mitigate the effects of climate change. Finally, I would like to mention the advancements in space exploration. In the year 3000, humans have been able to explore and colonize several planets beyond our solar system. Space travel has become faster, safer and easier thanks to advanced propulsion systems and the use of artificial intelligence to navigate and explore new worlds. Overall, the technological advancements I mentioned are just a few examples of the many innovations that have been developed over the years. As time travelers, we have witnessed firsthand the amazing advancements humans have made in technology.
Hope our future will get better and better as Wombat predicted.

References:
https://github.com/GanjinZero/RRHF
The above is the detailed content of Able to align humans without RLHF, performance comparable to ChatGPT! Chinese team proposes Wombat model. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology