

 Technology peripheralsAIOptimize the splicing performance of Ctrip's transfer transportation plan
Technology peripheralsAIOptimize the splicing performance of Ctrip's transfer transportation planOptimize the splicing performance of Ctrip's transfer transportation plan

About the author
In short, Ctrip back-end development manager, focusing on technical architecture, performance optimization, transportation planning and other fields.
1. Background introduction
Due to the limitations of transportation planning and transportation capacity resources, there may be no direct transportation between the two places queried by the user, or during major holidays, direct transportationare all sold out. However, users can still reach their destination through two-way or multi-way transfers such as trains, planes, cars, ships, etc. In addition, transfer transportation is sometimes more advantageous in terms of price and time consumption. For example, from Shanghai to Yuncheng, connecting via train may be faster and cheaper than a direct train.
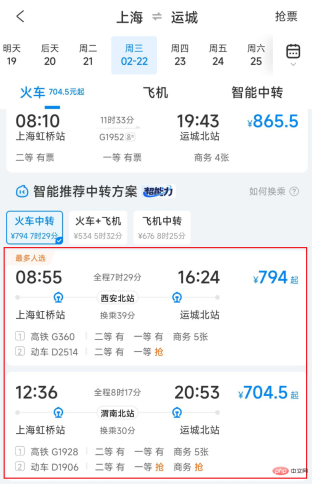
Figure 1 Ctrip train transfer transportation list
When providing transfer transportation solutions, it is very important One link is to stitch together two or more journeys of trains, planes, cars, ships, etc. to form a feasible transfer plan. The first difficulty in splicing transit traffic is that the splicing space is huge. Just considering Shanghai as a transit city, nearly 100 million combinations can be generated. Another difficulty lies in the requirement of real-time performance, because the production line data changes at any time and needs to be constantly updated. Query data on trains, planes, cars, and ships. Transit traffic splicing requires a lot of computing resources and IO overhead, so optimizing its performance is particularly important.
This article will combine examples to introduce the principles, analysis and optimization methods followed in the process of optimizing the performance of transfer traffic splicing, aiming to provide readers with valuable reference and inspiration.
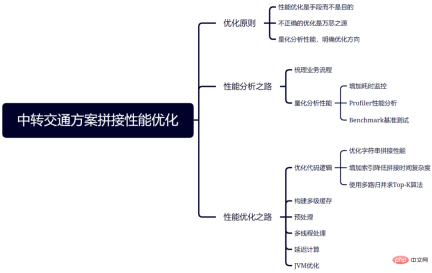
2. Optimization Principles
Performance optimization requires balancing and making trade-offs among various resources and constraints on the premise of meeting business needs, and following some major principles Helps eliminate uncertainty and approach the optimal solution to the problem. Specifically, the following three principles are mainly followed in the transfer traffic splicing optimization process:
2.1 Performance optimization is a means rather than an end
Although this article is about performance optimization , but it still needs to be emphasized at the beginning: don’t optimize for the sake of optimization. There are many ways to meet business needs, and performance optimization is just one of them. Sometimes the problem is very complex and there are many restrictions. Without significantly affecting the user experience, reducing the impact on users by relaxing restrictions or adopting other processes is also a good way to solve performance problems. In software development, there are many examples of significant cost reductions achieved by sacrificing a small amount of performance. For example, the HyperLogLog algorithm used for cardinality statistics (duplication removal) in Redis can count 264 data in only 12K space with a standard error of 0.81%.
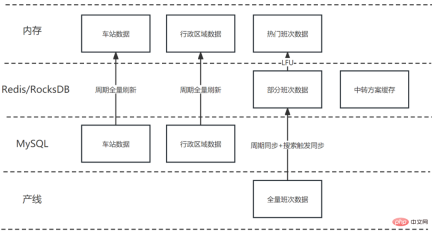
Back to the problem itself, since production line data needs to be queried frequently and massive splicing operations are performed, if each user is required to immediately return the freshest transfer plan when querying, The cost will be very high. To reduce costs, a balance needs to be struck between response time and data freshness. After careful consideration, we choose to accept minute-level data inconsistencies. For some unpopular routes and dates, there may not be a good transfer plan when querying for the first time. In this case, just guide the user to refresh the page.
2.2 Incorrect optimization is the root of all evil
Donald Knuth mentioned in "Structured Programming With Go To Statements": "Programmers waste a lot of time Thinking and worrying about the performance of non-critical paths and trying to optimize this part of performance will have a very serious negative impact on the debugging and maintenance of the overall code, so in 97% of cases, we should forget small optimization points." In short, before the real performance problem is discovered, excessive and ostentatious optimization at the code level will not only not improve performance, but may lead to more errors. However, the author also emphasized: "For the remaining critical 3%, we should not miss the opportunity to optimize." Therefore, you need to always pay attention to performance issues, not make decisions that will affect performance, and make correct optimizations when necessary.
2.3 Quantitatively analyze performance and clarify the direction of optimization
As mentioned in the previous section, before optimizing, you must first quantify the performance and identify bottlenecks, so that the optimization can be more targeted. Quantitative analysis of performance can use time-consuming monitoring, Profiler performance analysis tools, Benchmark benchmark testing tools, etc., focusing on areas that take a particularly long time or have a particularly high execution frequency. As Amdahl's law states: "The degree of system performance improvement that can be obtained by using a faster execution method for a certain component in the system depends on the frequency with which this execution method is used, or the proportion of the total execution time."
In addition, it is also important to note that performance optimization is a protracted battle. As the business continues to develop, the architecture and code are constantly changing, so it is even more necessary to continuously quantify performance, continuously analyze bottlenecks, and evaluate optimization effects.
3. The road to performance analysis
3.1 Sort out the business process
Before performance analysis, we must first sort out the business process. The splicing of transfer transportation plans mainly includes the following four steps:
#a. Load the route map, such as Beijing to Shanghai via Nanjing transfer, only the information of the route itself is considered, and has nothing to do with the specific flight;
b. Check the production line data of trains, planes, cars and ships, including departure time, arrival time, departure station, arrival station, price and remaining ticket information, etc.;
c. To stitch together all feasible transfer transportation options, the main consideration is that the transfer time should not be too short to avoid being unable to complete the transfer; at the same time, it should not be too long to avoid waiting too long. After splicing out feasible solutions, you still need to improve the business fields, such as total price, total time taken, transfer information, etc.;
d. According to certain rules, from all the spliced out From the feasible transfer solutions, some solutions that may be of interest to users are selected.
3.2 Quantitative analysis performance
(1) Increase time-consuming monitoring
Time-consuming Monitoring is the most intuitive way to observe the time-consuming situation of each stage from a macro perspective. It can not only view the time-consuming value and proportion of time-consuming at each stage of the business process, but also observe the time-consuming change trend over a long period of time.
Time-consuming monitoring can use the company’s internal indicator monitoring and alarm system to add time-consuming management to the main process of connecting transit transportation solutions. These processes include loading route maps, querying shift data and splicing it, filtering and saving splicing plans, etc. The time-consuming situation of each stage is shown in Figure 2. It can be seen that splicing (including production line data) takes the highest proportion of time-consuming, so it has become a key optimization target in the future.
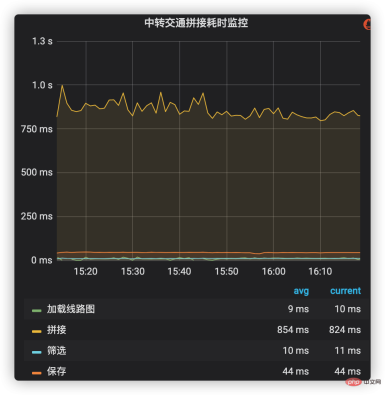
Figure 2 Time-consuming monitoring of transit traffic splicing
(2) Profiler performance analysis
Time-consuming management may invade business code and affect performance, so it should not be too many and is more suitable for monitoring main processes. The corresponding Profiler performance analysis tool (such as Async-profiler) can generate a more specific call tree and the CPU usage ratio of each function, thereby helping to analyze and locate critical paths and performance bottlenecks.

Figure 3 Splicing call tree and CPU ratio
As shown in Figure 3, the splicing scheme (combineTransferLines) accounts for 53.80%, and query production line data (querySegmentCacheable, cache used) accounts for 21.45%. In the splicing scheme, calculating scheme score (computeTripScore, accounting for 48.22%), creating scheme entity (buildTripBO, accounting for 4.61%) and checking splicing feasibility (checkCombineMatchCondition, accounting for 0.91%) are the three largest links.

Figure 4 Solution scoring call tree and CPU ratio
When we continued to analyze the calculation plan score (computeTripScore) with the highest proportion, we found that it was mainly related to the custom string formatting function (StringUtils.format), including direct calls (used to display plan score details), As well as an indirect call via getTripId (used to generate the ID of the scheme). The highest proportion of customized StringUtils.format is java/lang/String.replace. Java 8’s native string replacement is implemented through regular expressions, which is relatively inefficient (this problem has been improved after Java 9).
// 计算方案评分(computeTripScore) 中调用的StringUtils.format代码示例
StringUtils.format("AAAA-{0},BBBB-{1},CCCC-{2},DDDD-{3},EEEE-{4},FFFF-{5},GGGG-{6},HHHH-{7},IIII-{8},JJJJ-{9}",
aaaa, bbbb, cccc, dddd, eeee, ffff, gggg, hhhh, iiii, jjjj)
// getTripId 中调用StringUtils.format代码示例
StringUtils.format("{0}_{1}_{2}_{3}_{4}_{5}_{6}", aaaa, bbbb, cccc, dddd, eeee, ffff)
// 通过Java replace实现的自定义format函数
public static String format(String template, Object... parameters) {
for (int i = 0; i < parameters.length; i++) {
template = template.replace("{" + i + "}", parameters[i] + "");
}
return template;
}(3)Benchmark benchmark test
With the help of Benchmark benchmark test tool, you can measure the performance of the code more accurately execution time. In Table 1, we use JMH (Java Microbenchmark Harness) to conduct time-consuming tests on three string formatting methods and one string splicing method. The test results show that string formatting using Java8's replace method has the worst performance, while using Apache's string splicing function has the best performance.
Table 1 Comparison of string formatting and splicing performance
##Implementation |
Average time taken to execute 1000 times (us) |
StringUtils.format implemented using Java8's replace |
1988.982 |
StringUtils.format implemented using Apache replace |
656.537 |
Java8 comes with String.format |
##1417.474
|
| Apache's StringUtils.join
| ##116.812




The above is the detailed content of Optimize the splicing performance of Ctrip's transfer transportation plan. For more information, please follow other related articles on the PHP Chinese website!

 One Prompt Can Bypass Every Major LLM's SafeguardsApr 25, 2025 am 11:16 AM
One Prompt Can Bypass Every Major LLM's SafeguardsApr 25, 2025 am 11:16 AMHiddenLayer's groundbreaking research exposes a critical vulnerability in leading Large Language Models (LLMs). Their findings reveal a universal bypass technique, dubbed "Policy Puppetry," capable of circumventing nearly all major LLMs' s
 5 Mistakes Most Businesses Will Make This Year With SustainabilityApr 25, 2025 am 11:15 AM
5 Mistakes Most Businesses Will Make This Year With SustainabilityApr 25, 2025 am 11:15 AMThe push for environmental responsibility and waste reduction is fundamentally altering how businesses operate. This transformation affects product development, manufacturing processes, customer relations, partner selection, and the adoption of new
 H20 Chip Ban Jolts China AI Firms, But They've Long Braced For ImpactApr 25, 2025 am 11:12 AM
H20 Chip Ban Jolts China AI Firms, But They've Long Braced For ImpactApr 25, 2025 am 11:12 AMThe recent restrictions on advanced AI hardware highlight the escalating geopolitical competition for AI dominance, exposing China's reliance on foreign semiconductor technology. In 2024, China imported a massive $385 billion worth of semiconductor
 If OpenAI Buys Chrome, AI May Rule The Browser WarsApr 25, 2025 am 11:11 AM
If OpenAI Buys Chrome, AI May Rule The Browser WarsApr 25, 2025 am 11:11 AMThe potential forced divestiture of Chrome from Google has ignited intense debate within the tech industry. The prospect of OpenAI acquiring the leading browser, boasting a 65% global market share, raises significant questions about the future of th
 How AI Can Solve Retail Media's Growing PainsApr 25, 2025 am 11:10 AM
How AI Can Solve Retail Media's Growing PainsApr 25, 2025 am 11:10 AMRetail media's growth is slowing, despite outpacing overall advertising growth. This maturation phase presents challenges, including ecosystem fragmentation, rising costs, measurement issues, and integration complexities. However, artificial intell
 'AI Is Us, And It's More Than Us'Apr 25, 2025 am 11:09 AM
'AI Is Us, And It's More Than Us'Apr 25, 2025 am 11:09 AMAn old radio crackles with static amidst a collection of flickering and inert screens. This precarious pile of electronics, easily destabilized, forms the core of "The E-Waste Land," one of six installations in the immersive exhibition, &qu
 Google Cloud Gets More Serious About Infrastructure At Next 2025Apr 25, 2025 am 11:08 AM
Google Cloud Gets More Serious About Infrastructure At Next 2025Apr 25, 2025 am 11:08 AMGoogle Cloud's Next 2025: A Focus on Infrastructure, Connectivity, and AI Google Cloud's Next 2025 conference showcased numerous advancements, too many to fully detail here. For in-depth analyses of specific announcements, refer to articles by my
 Talking Baby AI Meme, Arcana's $5.5 Million AI Movie Pipeline, IR's Secret Backers RevealedApr 25, 2025 am 11:07 AM
Talking Baby AI Meme, Arcana's $5.5 Million AI Movie Pipeline, IR's Secret Backers RevealedApr 25, 2025 am 11:07 AMThis week in AI and XR: A wave of AI-powered creativity is sweeping through media and entertainment, from music generation to film production. Let's dive into the headlines. AI-Generated Content's Growing Impact: Technology consultant Shelly Palme


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

Dreamweaver CS6
Visual web development tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

SublimeText3 Linux new version
SublimeText3 Linux latest version

SublimeText3 Mac version
God-level code editing software (SublimeText3)

