Can efficiently support business iterative customization and meet the needs of rapid business update |
The following will introduce our related exploration and practice in the above aspects based on the business scenario of station B.
Data cold start
The speech recognition task is to completely recognize from a piece of speech The text content (speech to text).
The ASR system that meets the requirements of modern industrial production relies on a large amount of and diverse training data. Here "diversity" refers to non-homogeneous data such as the surrounding environment of the speaker, the scene context (field) and the speaker's accent.
For the business scenario of station B, we first need to solve the problem of cold start of voice training data. We will encounter the following challenges:
- Cold start: There is only a very small amount of data at the beginning. Open source data, purchased data, and business scenarios are poorly matched.
- Wide range of business scenarios: The audio and video business scenarios of Station B cover dozens of fields, which can be considered as a general field and have high requirements for data "diversity".
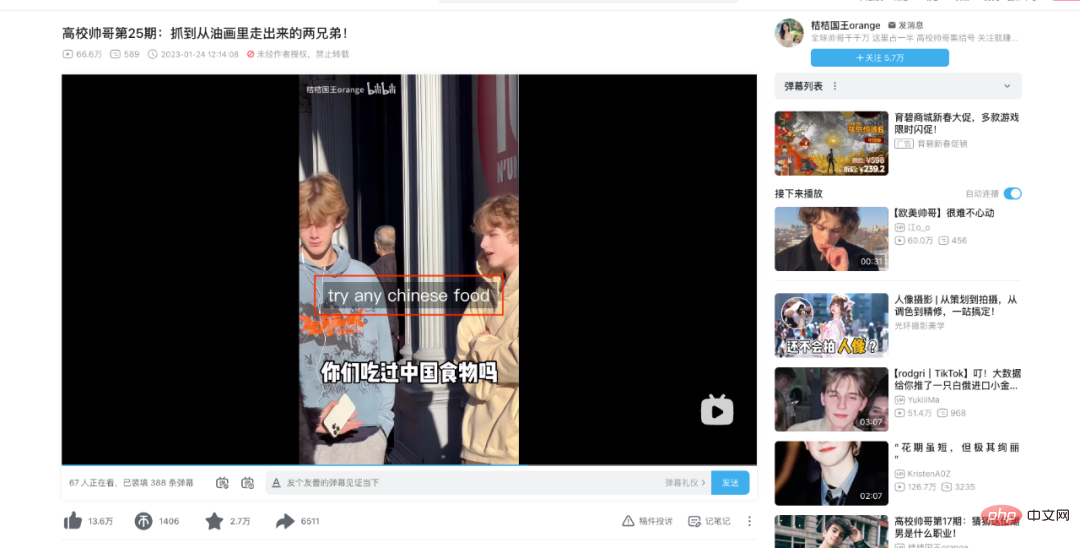
- Mixed Chinese and English: Station B has more young users, and there are more general knowledge videos mixed in Chinese and English.
For the above problems, we have adopted the following data solutions:
Business data filtering
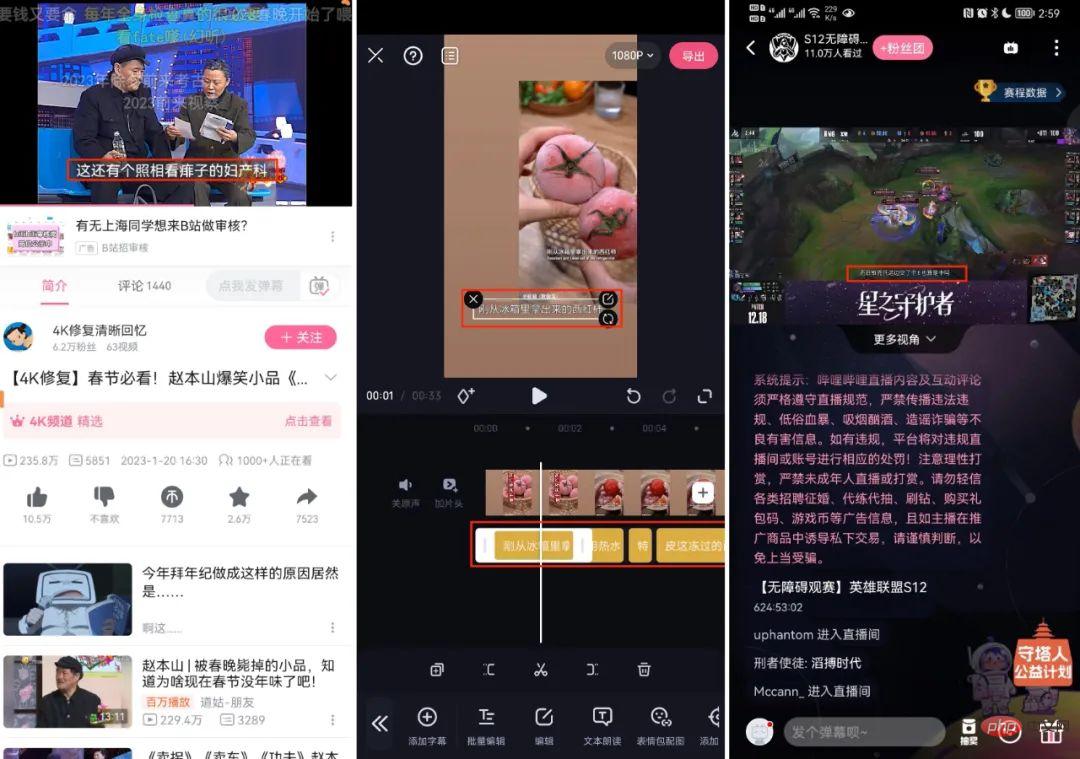
There are a small number of subtitles (cc subtitles) submitted by UP owners or users on site B, but there are also some problems:
- The timestamp is inaccurate, and the start and end timestamps of sentences are often between Between the first and last words or after a few words;
- There is no complete correspondence between speech and text, more words, less words, comments or translations, and subtitles may be generated based on meaning;
- Digital conversion, For example, the subtitles are 2002 (the actual pronunciation is 2002, 2002, etc.);
To this end, we train a screening data based on open source data, purchased finished product data and a small amount of annotated data The basic model uses the submitted subtitle text to train the sub-language model, which is used for sentence time alignment and subtitle filtering;
Semi-supervised training
In recent years, due to the significant improvement in data and GPU computing capabilities and the high cost of large-scale manual annotation of data, a large number of unsupervised (wav2vec, HuBERT, data2vec, etc.) [1][2] and semi-supervised have emerged in the industry Training methods.
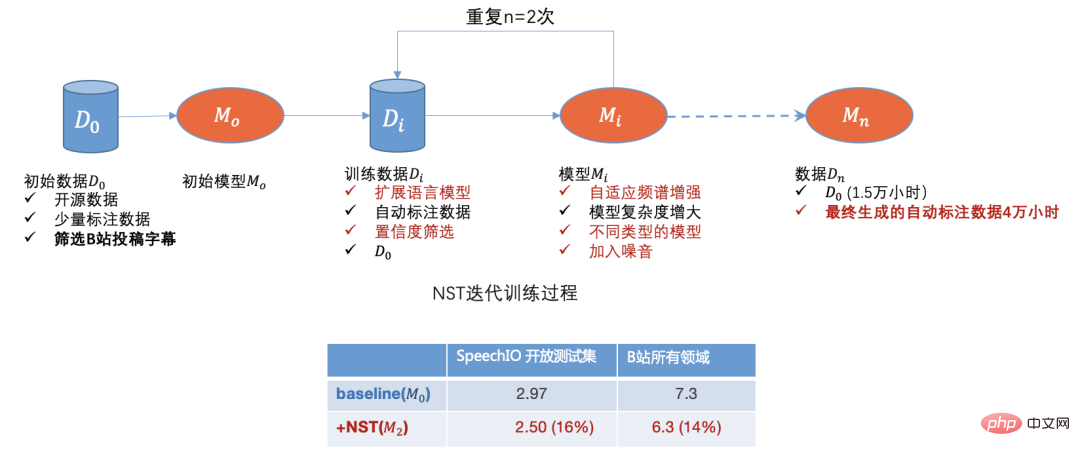
Site B has a large amount of unlabeled business data, and we also obtained a large amount of unlabeled video data from other websites. We used a semi-supervised training method called NST (Noisy Student Training) [3] in the early stage. ,
Initially, nearly 500,000 manuscripts were screened according to field and broadcast volume distribution, and finally generated about 40,000 hours of automatic annotation data. After the initial 15,000 hours of annotation data training, the recognition accuracy increased by about 15%. , and the model robustness is significantly improved.

Figure 1
Through open source data, B station submission data, manual annotation data and automatic annotation data, we have initially solved the data cold start problem. With the model By iterating, we can further filter out domain data with poor identification,
This forms a forward cycle. After initially solving the data problem, we will focus on the optimization of the model algorithm below.
Model algorithm optimization
ASR technology development history
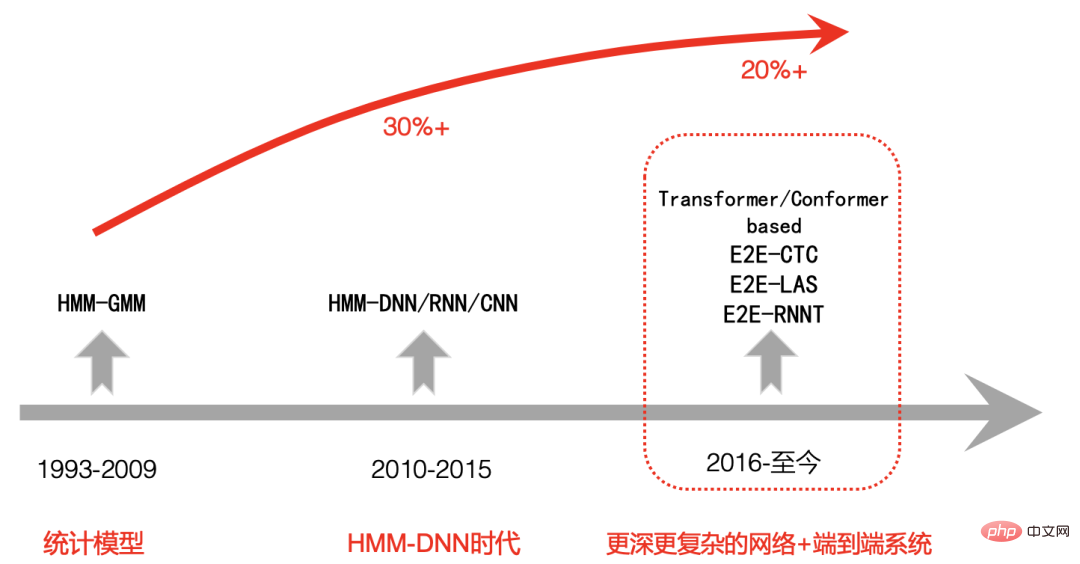
Let’s briefly review the development process of modern speech recognition, which can be roughly divided into three stages:
The first stage is from 1993 to 2009, and speech recognition has been in the In the HMM-GMM era, the past based on standard template matching began to shift to statistical models. The focus of research also shifted from small vocabulary and isolated words to large vocabulary and non-specific continuous speech recognition. Since the 1990s, speech has continued to improve for a long time. The development of recognition is relatively slow, and the recognition error rate has not dropped significantly.
The second stage is from 2009 to around 2015. With the significant improvement of GPU computing power, deep learning began to rise in speech recognition in 2009, and the speech recognition framework began to transform into HMM-DNN, and began to In the DNN era, speech recognition accuracy has been significantly improved.
The third stage is after 2015. Due to the rise of end-to-end technology, the development of CV, NLP and other AI fields promotes each other. Speech recognition begins to use deeper and more complex networks, while adopting end-to-end Technology has further greatly improved the performance of speech recognition, even exceeding human levels under some limited conditions.
Figure 2
B battle ASR technical plan
Introduction to important concepts
To facilitate understanding, here is a brief introduction to some important basic concepts
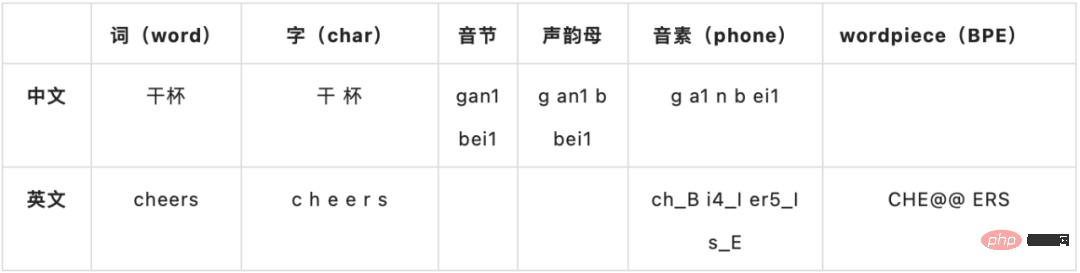
Modeling unit
Hybrid or E2E
The second stage hybrid framework HMM-DNN based on neural network has a huge improvement compared to the first stage HMM-GMM system speech recognition accuracy. This This point has also been unanimously agreed upon by everyone.
But the third phase of the end-to-end (E2E) system compared to the second phase was controversial in the industry for a period of time [4]. With the development of AI technology, especially transformer-related With the emergence of the model, the representation ability of the model is getting stronger and stronger.
At the same time, with the significant improvement of GPU computing power, we can add more data training, and the end-to-end solution gradually shows its advantages. More and more companies are choosing end-to-end solutions.
Here we compare these two solutions based on the business scenario of station B:
Figure 3
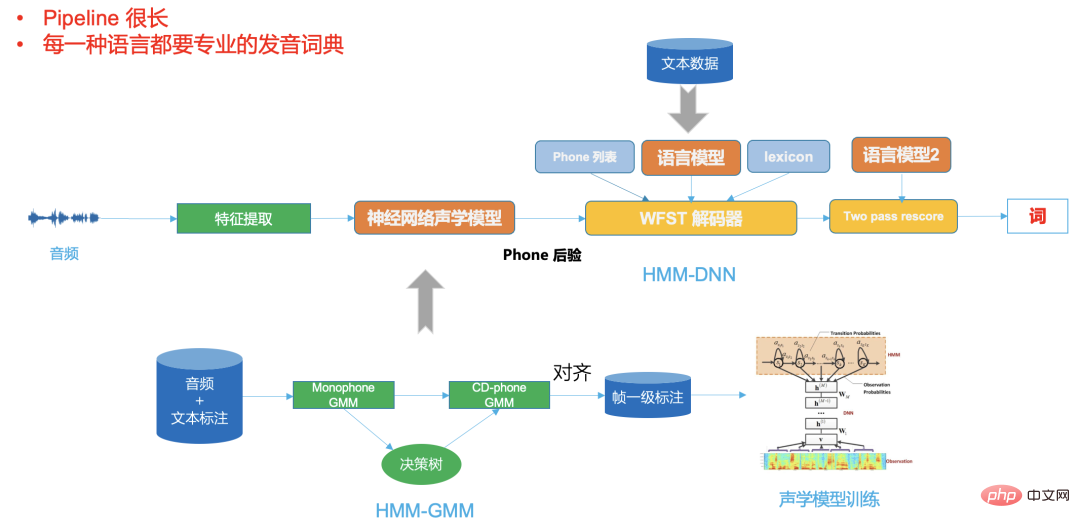
Figure 2 is a typical DNN- HMM framework, you can see that its pipeline is very long, different languages require professional pronunciation dictionaries,
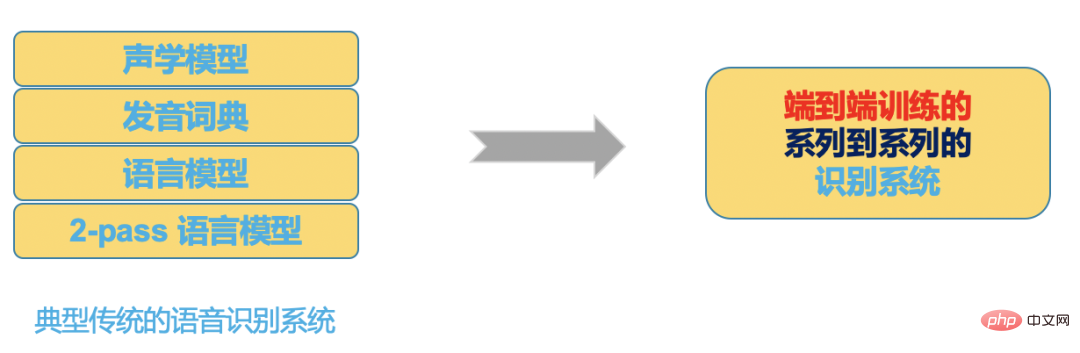
and the end-to-end system in Figure 3 puts all these in a neural network model, the neural network input is Audio (or features), the output is the recognition result we want.
Figure 4
With the development of technology, the advantages of end-to-end systems in development tools, communities and performance are becoming more and more obvious: - Comparison of representative tools and communities
|
##Hybrid framework (hybrid)
|
End-to-end framework (E2E)
|
| Representative open source tools and communities
| ##HTK, Kaldi
##Espnet, Wenet, DeepSpeech, K2, etc. |
|
Programming language
|
C/C, Shell |
Python, Shell |
|
Scalability
|
Developed from scratch |
TensorFlow/Pytorch |
|
The following table is a typical data set based on the optimal results (word error rate CER) of representative tools:
|
##Hybrid Framework
|
End-to-End Framework (E2E)
|
| Represents Tool
|
Kaldi
|
Espnet
|
| represents technology
|
tdnn chain rnnlm rescoring
|
conformer-las/ctc/rnnt
|
##Librispeech | 3.06 | 1.90 |
##GigaSpeech
|
14.84 |
10.80 |
|
Aishell-1
|
7.43 |
4.72 |
| ##WenetSpeech
|
12.83
| ##8.80 |
In short, by choosing an end-to-end system, compared with the traditional hybrid framework, given certain resources, we can develop a high-quality ASR system faster and better.
Of course, based on the hybrid framework, if we also use equally advanced models and highly optimized decoders, we can achieve results close to end-to-end, but we may need to invest several times the manpower and resources in development Optimize this system.
End-to-end solution selection
Station B has hundreds of thousands of hours of audio that need to be transcribed every day. The throughput and speed requirements of the ASR system are very high, and the accuracy of generating AI subtitles is also high. At the same time, the scene coverage of station B is also very wide. It is very important for us to choose a reasonable and efficient ASR system.
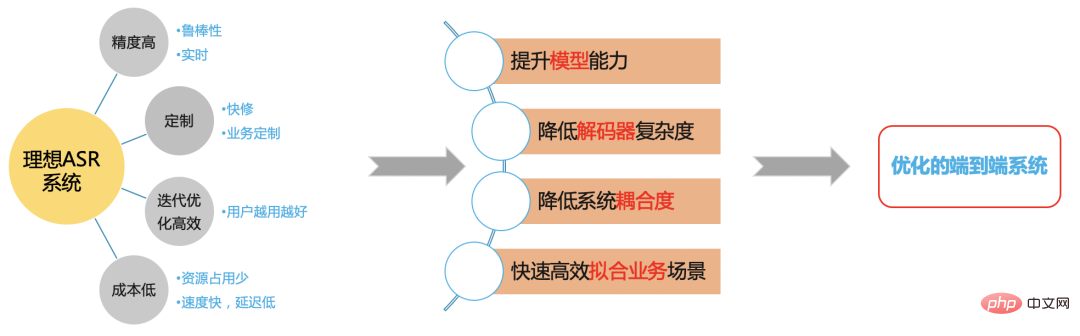
Ideal ASR system
Figure 5
We hope to build an efficient ASR system based on the end-to-end framework to solve the problem at station B Scenario issues.
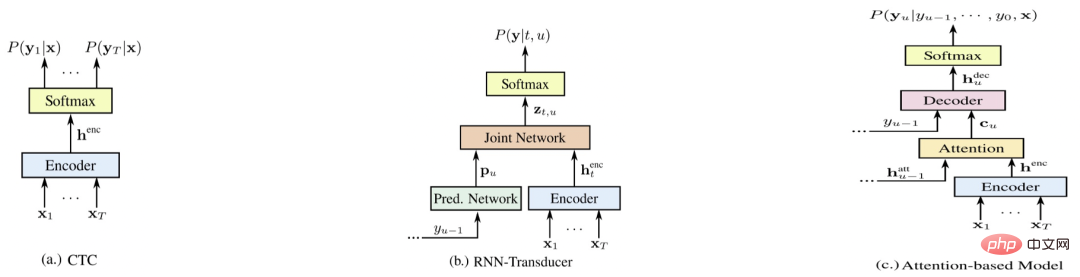
Comparison of end-to-end systems
Figure 6
Figure 4 is the three representative end-to-end systems [5 ], respectively E2E-CTC, E2E-RNNT, and E2E-AED. The following compares the advantages and disadvantages of each system from various aspects (the higher the score, the better)
|
#E2E-AED
|
E2E-RNNT
|
Optimized E2E-CTC
|
| Recognition accuracy
|
6
|
5
|
6
|
| Live (Streaming)
|
3
| ##5
##5 |
|
Cost and Speed
4 |
3 |
5 |
Quick Repair |
3 |
##3
|
6
|
| Fast and efficient iteration
|
6
|
4
|
5
|
- Non-streaming precision comparison (word error rate CER)
|
|
2000 hours |
15000 hours |
Kaldi Chain model LM |
13.7 |
-- |
E2E-AED |
11.8 |
6.6 |
E2E- RNNT |
12.4 |
##--
|
##E2E-CTC( greedy) | 13.1 | 7.1 |
##Optimized E2E- CTC LM
|
10.2 |
##5.8 |
The above are the results of life and food scenes at station B based on 2,000 hours and 15,000 hours of video training data respectively. Chain and E2E-CTC use the extended language model trained with the same corpus.
E2E-AED and E2E-RNNT does not use an extended language model, and the end-to-end system is based on the Conformer model.
It can be seen from the second table that the accuracy of a single E2E-CTC system is not significantly weaker than other end-to-end systems, but at the same time the E2E-CTC system has the following advantages:
- Because there is no autoregressive (AED decoder and RNNT predict) structure of the neural network, the E2E-CTC system has natural advantages in streaming, decoding speed, and deployment cost;
- In terms of business customization, the E2E-CTC system It is also easier to externally connect various language models (nnlm and ngram), which makes its generalization stability significantly better than other end-to-end systems in general open fields that do not have enough data to fully cover.
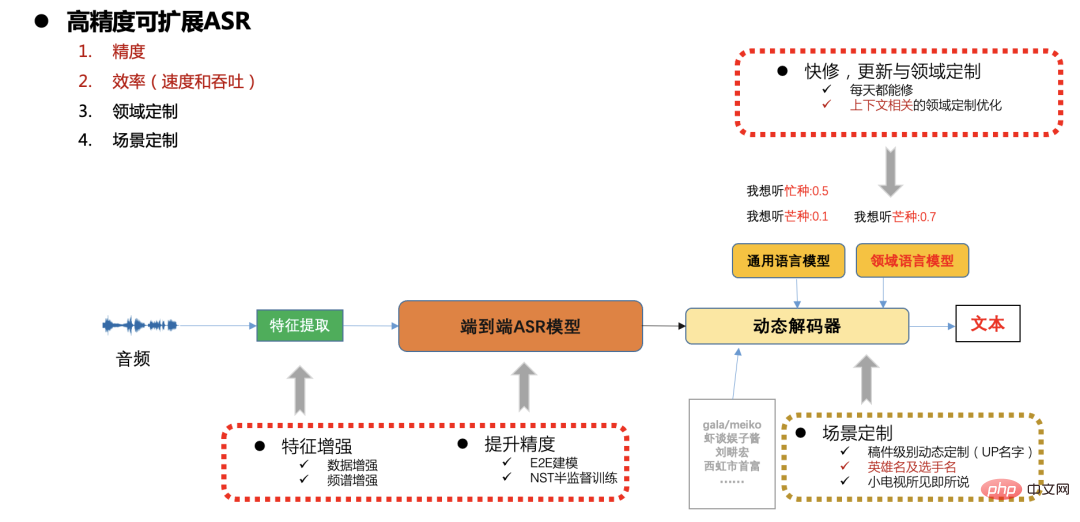
High-quality ASR solution
High-precision scalable ASR framework
Figure 7
In the production environment of station B, there are high requirements for speed, accuracy and resource consumption, and there are also rapid updates in different scenarios. and customization needs (such as entity words related to manuscripts, customization of popular games and sports events, etc.),
Here we generally use an end-to-end CTC system to solve the scalability customization problem through dynamic decoders. The following will focus on the model accuracy, speed and scalability optimization work.
End-to-end CTC discriminative training
Our system uses Chinese characters plus English BPE modeling. After multi-task training based on AED and CTC, we only retain For the CTC part, we will perform discriminative training later. We use end-to-end lattice free mmi[6][7] Discriminative training:
- Discriminative training criteria
- Discrimination Criterion-MMI
# #Differences from traditional discriminative training-
1. Traditional approach a. First generate alignment and decoding lattice corresponding to all training corpus on the CPU; b . During training, each minibatch uses the pre-generated alignment and lattice to calculate the numerator and denominator gradients respectively and update the model; 2. Our approach a. During training, each minibatch is directly in Calculate the numerator and denominator gradients on the GPU and update the model;
and kaldi’s phone-based lattice free mmi discriminative training
## 1. Direct End-to-end modeling of characters and English BPE, abandoning the phone hmm state transfer structure; 2. The modeling granularity is large, the training input is not approximately truncated, and the context is the entire sentence;
The following table is based on 15,000 hours of data. After CTC training is completed, 3,000 hours are selected for discriminative training using decoding confidence. It can be seen that the discriminative training results of end-to-end lattice free mmi are better than those of traditional DT. Training, in addition to improving accuracy, the entire training process can be completed in tensorflow/pytorch GPU.
|
##B station video test set |
CTC baseline |
6.96 |
TRADITIONALDT |
6.63 |
E2E LFMMI DT |
6.13 |
Compared with hybrid systems, the end-to-end system decoding result timestamps are not very accurate. AED training does not align monotonically with time. The CTC trained model is much more accurate than AED timestamps, but there is also a spike problem. Each time The duration of the word is inaccurate;
After end-to-end discriminative training, the model output will become flatter, and the timestamp boundary of the decoding result will be more accurate;
End-to-end End CTC decoder
In the development process of speech recognition technology, whether it is the first stage based on GMM-HMM or the second stage based on DNN-HMM hybrid framework, the decoder is very important. Part.
The performance of the decoder directly determines the speed and accuracy of the final ASR system. Business expansion and customization also mostly rely on flexible and efficient decoder solutions. Traditional decoders, whether they are dynamic decoders or static decoders based on WFST, are very complex. They not only rely on a lot of theoretical knowledge, but also require professional software engineering design. Developing a traditional decoding engine with superior performance not only requires a lot of manpower development in the early stage. , and the subsequent maintenance costs are also very high.
A typical traditional WFST decoder needs to compile hmm, triphone context, dictionary, and language model into a unified network, that is, HCLG, in a unified FST network search space, which can improve the decoding speed. Improve accuracy.
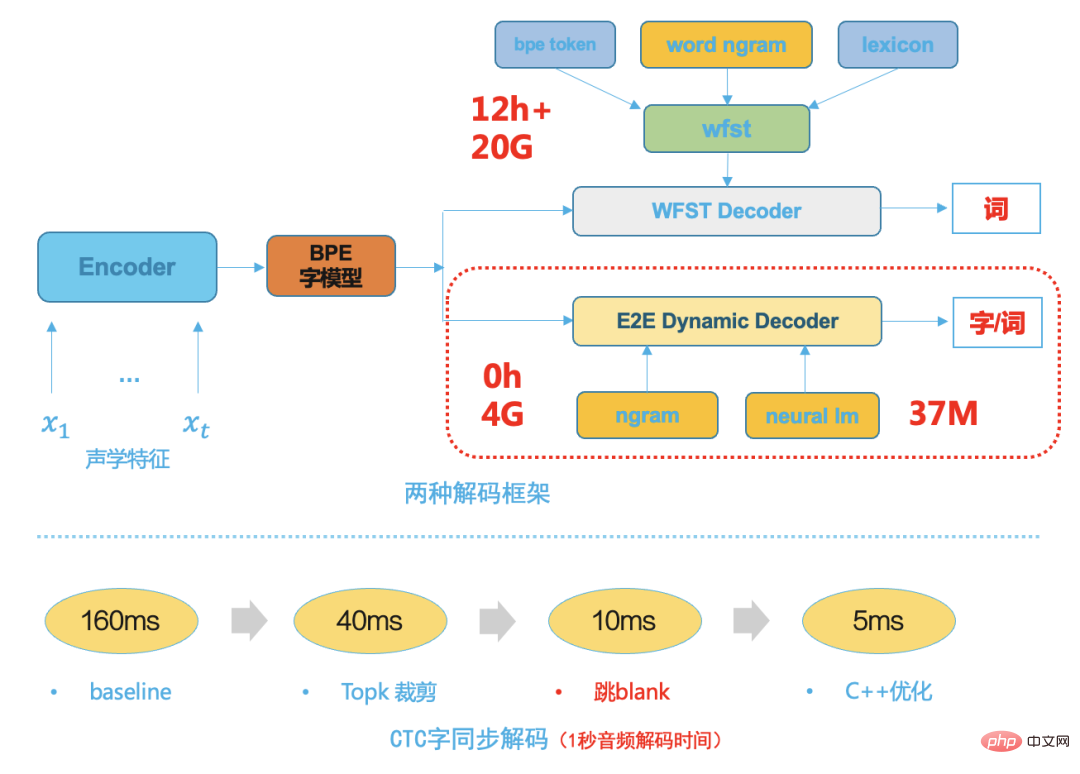
With the maturity of end-to-end system technology, the end-to-end system modeling unit has a larger granularity, such as Chinese words or English wordpieces, because the traditional HMM transfer structure, triphone context and pronunciation are removed. dictionary, which makes the subsequent decoding search space much smaller, so we choose a simple and efficient dynamic decoder based on beam search. The following figure shows two decoding frameworks. Compared with the traditional WFST decoder, end-to-end dynamic decoding The decoder has the following advantages:
- It takes up less resources, typically 1/5 of the WFST decoding resources;
- It has low coupling, which is convenient for business customization and easy integration with various language models. Decoding, no need to recompile decoding resources for each modification;
- The decoding speed is fast, using word synchronization decoding [8], which is typically 5 times faster than WFST decoding speed;
Figure 8
Model inference deployment
In a reasonable and efficient end-to-end ASR framework, the part with the largest amount of calculation should be Regarding the inference of the neural network model, this computationally intensive part can make full use of the computing power of the GPU. We optimize the model inference deployment from the inference service, model structure and model quantification:
- Model Using F16 half-precision inference;
- The model is converted to FasterTransformer[9], based on nvidia's highly optimized transformer;
- Uses triton to deploy the inference model, automatically organizes batches, and fully improves GPU usage efficiency;
Under a single GPU T4, the speed is increased by 30%, the throughput is increased by 2 times, and 3000 hours of audio can be transcribed in one hour;
Summary
#This article mainly introduces the implementation of speech recognition technology in the B station scenario, how to solve the training data problem from scratch, the selection of the overall technical solution, and various Introduction and optimization of sub-modules, including model training, decoder optimization and service inference deployment. In the future, we will further improve the user experience in relevant landing scenarios, such as using instant hot word technology to optimize the accuracy of relevant entity words at the manuscript level; combined with streaming ASR related technology, more efficient customization supports real-time subtitle transcription for games and sports events.
References
[1] A Baevski, H Zhou, et al. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
[2] A Baevski , W Hsu, et al. data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language
[3] Daniel S, Y Zhang, et al. Improved Noisy Student Training for Automatic Speech Recognition
[4] C Lüscher, E Beck, et al. RWTH ASR Systems for LibriSpeech: Hybrid vs Attention -- w/o Data Augmentation
[5] R Prabhavalkar , K Rao, et al , A Comparison of Sequence-to-Sequence Models for Speech Recognition
[6] D Povey, V Peddinti1, et al, Purely sequence-trained neural networks for ASR based on lattice-free MMI
[7] H Xiang, Z Ou, CRF-BASED SINGLE-STAGE ACOUSTIC MODELING WITH CTC TOPOLOGY
[8] Z Chen, W Deng, et al, Phone Synchronous Decoding with CTC Lattice
[9] https://www.php.cn/link/2ea6241cf767c279cf1e80a790df1885
The author of this issue: Deng Wei
Senior Algorithm Engineer
Head of Bilibili Speech Recognition Direction
|
|