

 Technology peripheralsAIAI has seen you clearly, YOLO+ByteTrack+multi-label classification network
Technology peripheralsAIAI has seen you clearly, YOLO+ByteTrack+multi-label classification networkAI has seen you clearly, YOLO+ByteTrack+multi-label classification network

Today I will share with you a pedestrian attribute analysis system. Pedestrians can be identified from video or camera video streams and each person's attributes can be marked.

The recognized attributes include the following 10 categories

Some categories have multiple attributes. If the body orientation is: front , side and back, so there are 26 attributes in the final training.
Implementing such a system requires 3 steps:
- Use YOlOv5 to identify pedestrians
- Use ByteTrack to track and mark the same person
- Train multi-label images Classification network, identifying 26 attributes of pedestrians
1. Pedestrian recognition and tracking
Pedestrian recognition uses the YOLOv5 target detection model. You can train the model yourself, or you can directly use YOLOv5 pre-training Good model.
Pedestrian tracking uses Multi-Object Tracking Technology (MOT) technology. The video is composed of pictures. Although we humans can identify the same person in different pictures, if we do not track pedestrians, AI is unrecognizable. MOT technology is needed to track the same person and assign a unique ID to each pedestrian.
The training and use of the YOLOv5 model, as well as the principles and implementation plans of the multi-object tracking technology (MOT) technology, are detailed in the previous article. Interested friends can check out the article there. YOLOv5 ByteTrack counts traffic flow.
2. Training multi-label classification network
Most of the image classifications we first came into contact with were single-label classification, that is: a picture is classified into category 1, and the category can be two categories. It can also be multiple categories. Assuming there are three categories, the label corresponding to each picture may be in the following general format:
001.jpg010 002.jpg100 003.jpg100
labelOnly one position is 1.
The multi-label classification network we are going to train today is a picture that contains multiple categories at the same time. The label format is as follows:
001.jpg011 002.jpg111 003.jpg100
label can have multiple positions of 1.
There are two options for training such a network. One is to treat each category as a single-label classification, calculate the loss separately, summarize the total, and calculate the gradient to update the network parameters.
The other one can be trained directly, but you need to pay attention to the network details, taking ResNet50 as an example
resnet50 = ResNet50(include_top=False, weights='imagenet')
# 迁移学习,不重新训练卷积层
for layer in resnet50.layers:
layer.trainable = False
# 新的全连接层
x = Flatten()(resnet50.output)
x = Dense(1024)(x)
x = Activation('relu')(x)
x = BatchNormalization()(x)
x = Dropout(0.5)(x)
# 输出 26 个属性的多分类标签
x = Dense(26, activatinotallow='sigmoid')(x)
model = Model(inputs = resnet50.input, outputs=x)The activation function of the final output layer must be sigmoid, because each attribute needs to be calculated separately Probability. In the same way, the loss function during training also needs to use binary_crossentropy.
In fact, the principles of the above two methods are similar, but the development workload is different.
For convenience here, I use PaddleCls for training. Paddle's configuration is simple, but its disadvantage is that it is a bit of a black box. You can only follow its own rules, and it is more troublesome to customize it.
The model training uses the PA100K data set. It should be noted that although the original label defined by the PA100K data set has the same meaning as Paddle, the order is different.
For example: The 1st digit of the original label represents whether the label is female, while Paddle requires the 1st digit to represent whether the label is wearing a hat, and the 22nd digit represents whether the label is female.

#We can adjust the original label position according to Paddle’s requirements, so that it will be easier for us to reason later.
Download PaddleClas
git clone https://github.com/PaddlePaddle/PaddleClas
Unzip the downloaded dataset and place it in the dataset directory of PaddleClas.
Find the ppcls/configs/PULC/person_attribute/PPLCNet_x1_0.yaml configuration file and configure the image and label paths.
DataLoader: Train: dataset: name: MultiLabelDataset image_root: "dataset/pa100k/" #指定训练AI has seen you clearly, YOLO+ByteTrack+multi-label classification network所在根路径 cls_label_path: "dataset/pa100k/train_list.txt" #指定训练列表文件位置 label_ratio: True transform_ops: Eval: dataset: name: MultiLabelDataset image_root: "dataset/pa100k/" #指定评估AI has seen you clearly, YOLO+ByteTrack+multi-label classification network所在根路径 cls_label_path: "dataset/pa100k/val_list.txt" #指定评估列表文件位置 label_ratio: True transform_ops:
train_list.txt format is
00001.jpg0,0,1,0,....
After configuration, you can train directly
python3 tools/train.py -c ./ppcls/configs/PULC/person_attribute/PPLCNet_x1_0.yaml
After training, export the model
python3 tools/export_model.py -c ./ppcls/configs/PULC/person_attribute/PPLCNet_x1_0.yaml -o Global.pretrained_model=output/PPLCNet_x1_0/best_model -o Global.save_inference_dir=deploy/models/PPLCNet_x1_0_person_attribute_infer
will The exported results are placed in the ~/.paddleclas/inference_model/PULC/person_attribute/ directory

You can use the function provided by PaddleCls to directly call
import paddleclas model = paddleclas.PaddleClas(model_name="person_attribute") result = model.predict(input_data="./test_imgs/000001.jpg") print(result)
for output The results are as follows:
[{'attributes': ['Female', 'Age18-60', 'Front', 'Glasses: False', 'Hat: False', 'HoldObjectsInFront: True', 'ShoulderBag', 'Upper: ShortSleeve', 'Lower:Trousers', 'No boots'], 'output': [0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0], 'filename': './test_imgs/000001.jpg'}]The model training process ends here, the data set and the source code of the entire project have been packaged.
The above is the detailed content of AI has seen you clearly, YOLO+ByteTrack+multi-label classification network. For more information, please follow other related articles on the PHP Chinese website!

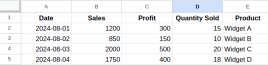 What is Data Formatting in Excel? - Analytics VidhyaApr 14, 2025 am 11:05 AM
What is Data Formatting in Excel? - Analytics VidhyaApr 14, 2025 am 11:05 AMIntroduction Handling data efficiently in Excel can be challenging for analysts. Given that crucial business decisions hinge on accurate reports, formatting errors can lead to significant issues. This article will help you und
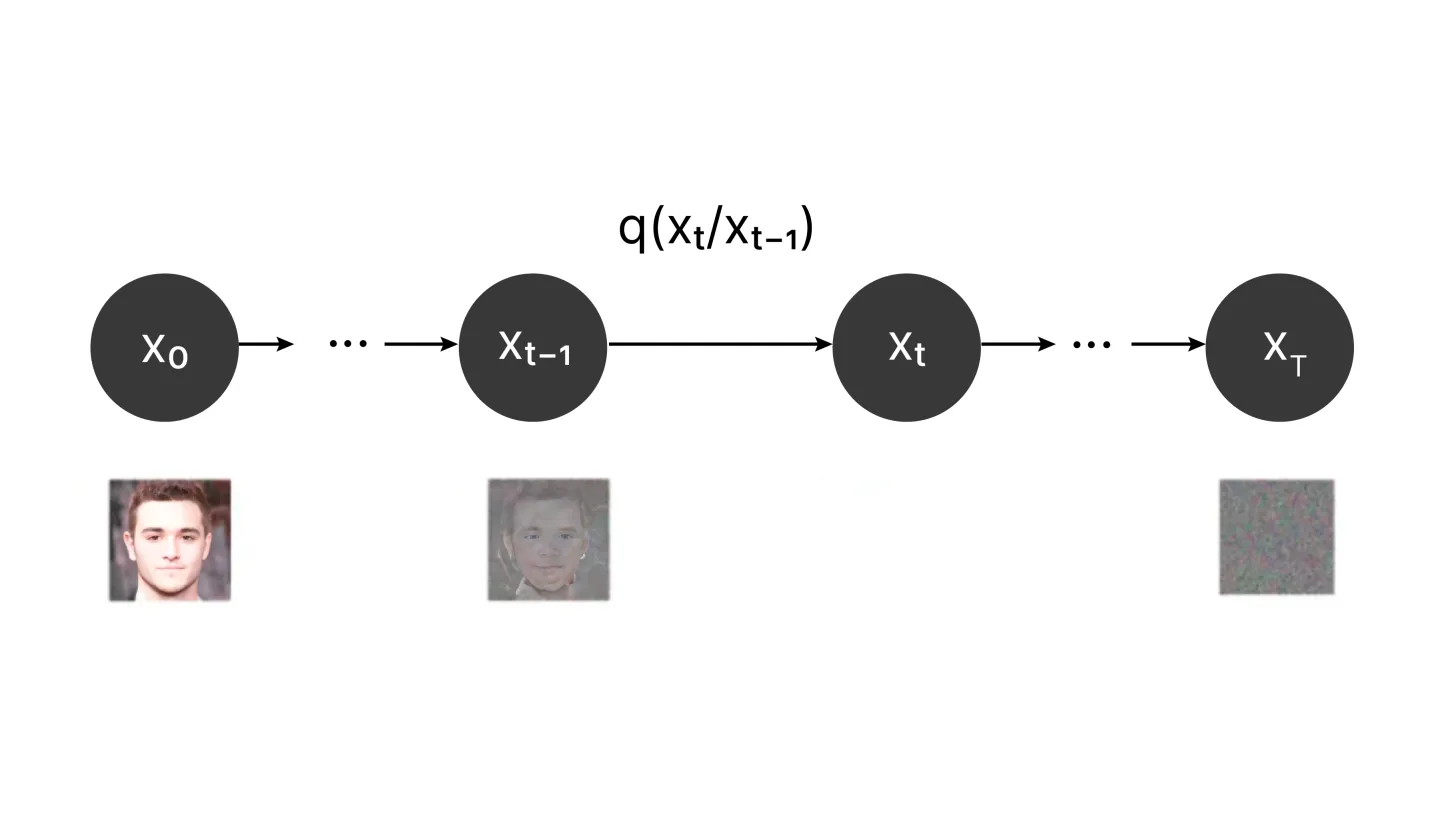 What are Diffusion Models?Apr 14, 2025 am 11:00 AM
What are Diffusion Models?Apr 14, 2025 am 11:00 AMDive into the World of Diffusion Models: A Comprehensive Guide Imagine watching ink bloom across a page, its color subtly diffusing until a captivating pattern emerges. This natural diffusion process, where particles move from high to low concentrati
 What is Heuristic Function in AI? - Analytics VidhyaApr 14, 2025 am 10:51 AM
What is Heuristic Function in AI? - Analytics VidhyaApr 14, 2025 am 10:51 AMIntroduction Imagine navigating a complex maze – your goal is to escape as quickly as possible. How many paths exist? Now, picture having a map that highlights promising routes and dead ends. That's the essence of heuristic functions in artificial i
 A Comprehensive Guide on Backtracking AlgorithmApr 14, 2025 am 10:45 AM
A Comprehensive Guide on Backtracking AlgorithmApr 14, 2025 am 10:45 AMIntroduction The backtracking algorithm is a powerful problem-solving technique that incrementally builds candidate solutions. It's a widely used method in computer science, systematically exploring all possible avenues before discarding any potenti
 5 Best YouTube Channels to Learn Statistics for FreeApr 14, 2025 am 10:38 AM
5 Best YouTube Channels to Learn Statistics for FreeApr 14, 2025 am 10:38 AMIntroduction Statistics is a crucial skill, applicable far beyond academia. Whether you're pursuing data science, conducting research, or simply managing personal information, a grasp of statistics is essential. The internet, and especially distance
 AvBytes: Key Developments and Challenges in Generative AI - Analytics VidhyaApr 14, 2025 am 10:36 AM
AvBytes: Key Developments and Challenges in Generative AI - Analytics VidhyaApr 14, 2025 am 10:36 AMIntroduction Hey there, AI enthusiasts! Welcome to The AV Bytes, your friendly neighborhood source for all things AI. Buckle up, because this week has been a wild ride in the world of AI! We’ve got some mind-blowing stuff t
 Self Hosting RAG Applications On Edge Devices with LangchainApr 14, 2025 am 10:35 AM
Self Hosting RAG Applications On Edge Devices with LangchainApr 14, 2025 am 10:35 AMIntroduction In the second part of our series on building a RAG application on a Raspberry Pi, we’ll expand on the foundation we laid in the first part, where we created and tested the core pipeline. In the first part, we crea
 Cursor AI: Why You Should Try It Once? - Analytics VidhyaApr 14, 2025 am 10:22 AM
Cursor AI: Why You Should Try It Once? - Analytics VidhyaApr 14, 2025 am 10:22 AMIntroduction After Andrej Karpathy’s viral tweet,“English has become the new programming language,” here is another trending tweet on X saying, “Future be like Tab Tab Tab.”You might be wondering


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

WebStorm Mac version
Useful JavaScript development tools

Notepad++7.3.1
Easy-to-use and free code editor

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

