
Home >Technology peripherals >AI >Intel helps build open source large-scale sparse model training/prediction engine DeepRec
Intel helps build open source large-scale sparse model training/prediction engine DeepRec

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-04-08 22:01:101656browse
DeepRec (PAI-TF) is Alibaba Group’s unified open source recommendation engine (https://github.com/alibaba/DeepRec). It is mainly used for sparse model training and prediction, and can support hundreds of billions of features, Ultra-large-scale sparse training with trillions of samples has obvious advantages in training performance and effects; currently DeepRec supports Taobao search, recommendation, advertising and other scenarios, and is widely used in Taobao, Tmall, Alimama, Amap and other businesses.
Intel has been working closely with the Alibaba PAI team since 2019 to apply Intel Artificial Intelligence (AI) technology to DeepRec, targeting operators, subgraphs, and runtime , framework layer and model to fully leverage the advantages of Intel software and hardware to help Alibaba accelerate the performance of internal and external AI business.
Main advantages of DeepRec
The current mainstream open source engines still have certain limitations in supporting ultra-large-scale sparse training scenarios. For example, they do not support Online training, features cannot be dynamically loaded, and online deployment and iteration are inconvenient. In particular, the performance is difficult to meet business needs. The problem is particularly obvious. In order to solve the above problems, DeepRec has been deeply customized and optimized for sparse model scenarios based on TensorFlow1.15. The main measures include the following three categories:
Model effect: Mainly through Added EmbeddingVariable (EV) dynamic elastic feature function and improved Adagrad Optimizer to achieve optimization. The EV function solves problems such as difficulty in estimating native Variable size and feature conflicts, and provides a wealth of advanced features such as feature admission and elimination strategies. At the same time, it automatically configures hot and cold feature dimensions based on the frequency of feature occurrences, adding The expressiveness of high-frequency features alleviates over-fitting and can significantly improve the effect of sparse models;
Training and inference performance: For sparse scenarios, DeepRec is in distributed , subgraphs, operators, runtime and other aspects have been in-depth performance optimization, including distributed strategy optimization, automatic pipeline SmartStage, automatic graph fusion, Embedding and Attention and other graph optimizations, common sparse operator optimization, memory management optimization, significantly reducing Memory usage significantly accelerates end-to-end training and inference performance;
Deployment and Serving:DeepRec supports incremental model export and loading, achieving 10TB level Minute-level online training and updates of very large models are launched, which meets the high timeliness requirements of the business; in view of the hot and cold skew characteristics of features in sparse models, DeepRec provides multi-level hybrid storage (up to four-level hybrid storage, that is, HBM DRAM PMem SSD) capabilities can improve the performance of large models while reducing costs.
Intel technology helps DeepRec achieve high performance
The close cooperation between Intel and Alibaba’s PAI team played an important role in achieving the above three unique advantages. DeepRec’s three The big advantage also fully reflects the huge value of Intel technology:
In terms of performance optimization, Intel's ultra-large-scale cloud software team works closely with Alibaba to target CPU platforms , optimize from operators, subgraphs, frameworks, runtime and other levels, make full use of various new features of Intel® Xeon® Scalable processors, and maximize the hardware advantages;
In order toimprove the usability of DeepRec on the CPU platform, modelzoo was also built to support most mainstream recommendation models, and DeepRec’s unique EV function was applied to these models to achieve development Out-of-the-box user experience.
At the same time, in response to the special needs of ultra-large-scale sparse training model EV for storage and KV lookup operations, the Intel Optane Innovation Center team provides solutions based on Intel® OptaneTM The memory management and storage solution of persistent memory ("PMem" for short) supports and cooperates with the DeepRec multi-level hybrid storage solution to meet the needs of large memory and low cost; Programmable Solutions Division Team Use FPGA to implement the KV search function for Embedding, which greatly improves the Embedding query capability and releases more CPU resources. Combining the different hardware characteristics of CPU, PMem and FPGA, and from a system perspective, Intel's software and hardware advantages can be fully utilized for different needs, which can accelerate the implementation of DeepRec in Alibaba's AI business and provide better solutions for the entire sparse scenario business ecosystem. Excellent solution.
Intel® DL Boost provides critical performance acceleration for DeepRec
The optimization of DeepRec by Intel® DL Boost (Intel® Deep Learning Acceleration) is mainly reflected in the four levels of framework optimization, operator optimization, subgraph optimization and model optimization.
- Intel x86 Platform AI Capability Evolution - Intel® DL Boost
From Intel® Xeon® Scalable Processing Since the advent of the processor, Intel has doubled the capabilities of AVX by upgrading from AVX 256 to AVX-512, greatly improving deep learning training and inference capabilities; and the second-generation Intel® Xeon® Scalable processors have The introduction of DL Boost_VNNI has greatly improved the performance of INT8 multiplication and addition calculations; since the third generation Intel® Xeon® Scalable processors, Intel has launched an instruction set that supports the BFloat16 (BF16) data type to further improve deep learning training and inference performance . With the continuous innovation and development of hardware technology, Intel will launch new AI processing technology in the next generation of Xeon® Scalable processors to further improve the capabilities of VNNI and BF16 from 1-dimensional vector to 2-dimensional matrix. The above-mentioned hardware instruction set technologies have been applied in the optimization of DeepRec, allowing different hardware features to be used for different computing requirements. It also verified that Intel® AVX-512 and BF16 are very suitable for training and inference acceleration in sparse scenarios.
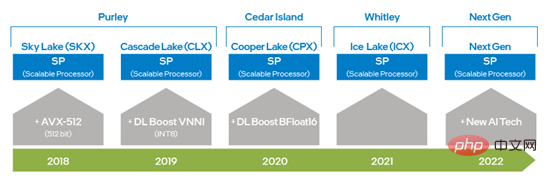
Figure 1 Intel x86 platform AI capability evolution chart
- Framework optimization
DeepRec integrates Intel’s open source cross-platform deep learning performance acceleration library oneDNN (oneAPI Deep Neural Network Library ), and modified oneDNN’s original thread pool to unify it into DeepRec’s Eigen thread pool, which reduced thread pool switching overhead and avoided performance degradation caused by competition between different thread pools. oneDNN has implemented performance optimization for a large number of mainstream operators, including MatMul, BiasAdd, LeakyReLU and other common operators in sparse scenarios, which can provide strong performance support for search and promotion models, and the operators in oneDNN also support BF16 Data type, used together with the third generation Intel® Xeon® Scalable processor equipped with the BF16 instruction set, can significantly improve model training and inference performance.
In the DeepRec compilation options, just add "--config=mkl_threadpool" to easily enable oneDNN optimization.
- Operator optimization
## Although oneDNN can be used to greatly improve computationally intensive operators performance, but there are a large number of sparse operators in the search advertising recommendation model, such as Select, DynamicStitch, Transpose, Tile, SparseSegmentMean, etc. Most of the native implementations of these operators have a certain space for memory access optimization, for which targeted The solution achieves additional optimization. This optimization calls AVX-512 instructions and can be turned on by adding "--copt=-march=skylake-avx512" to the compilation command. The following are two of the optimization cases.
Case 1: The implementation principle of the Select operator is to select elements based on conditions. In this case, the mask load method of Intel® AVX-512 can be used, as shown in the left picture of Figure 2 , to reduce the time overhead caused by the large number of judgments caused by the if condition, and then improve the data reading and writing efficiency through batch selection. The final online test showed that the performance improved significantly;

Figure 2 Select operator optimization case
Case 2: Same , you can use the unpack and shuffle instructions of Intel® AVX-512 to optimize the transpose operator, that is, transpose the matrix through small blocks, as shown in the right picture of Figure 2. The final online test shows that the performance improvement is also very significant. Significantly.
- Subgraph optimization
Graph optimization is the main effective method for current AI performance optimization one. Similarly, when DeepRec is applied in large-scale sparse scenarios, there is usually a large amount of feature information processing mainly embedding features, and embedding contains a large number of small operators; in order to achieve general performance improvement, optimization measures are implemented in DeepRec The fused_embedding_lookup function is added to fuse embedding subgraphs, reducing a large number of redundant operations. At the same time, using Intel® AVX-512 instructions to accelerate calculations, the performance of embedding subgraphs is significantly improved.
By setting do_fusion to True in the tf.feature_column.embedding_column(..., do_fusion=True) API, you can turn on the embedding subgraph optimization function.
- Model optimization
Based on the CPU platform, Intel built DeepRec covering WDL, DeepFM, DLRM, DIEN, A unique collection of recommended models for multiple mainstream models such as DIN, DSSM, BST, MMoE, DBMTL, ESMM, etc., involving a variety of common scenarios such as recall, sorting, and multi-objectives; and performance optimization for hardware platforms, compared with other frameworks , which brings great performance improvements to these models on the CPU platform based on open source data sets such as Criteo.
The most outstanding performance is undoubtedly the optimized implementation of mixed precision BF16 and Float32. By adding the function of customizing the data type of the DNN layer in DeepRec to meet the high performance and high accuracy requirements of sparse scenes; the way to enable optimization is as shown in Figure 3. The data type of the current variable is retained as Float32 through keep_weights, which is used for Prevent the accuracy drop caused by gradient accumulation, and then use two cast operations to convert the DNN operation into BF16 for calculation. Relying on the BF16 hardware computing unit of the third-generation Intel® Xeon® Scalable processor, it greatly improves DNN computing. performance, while further improving performance through graph fusion cast operations.

Figure 3 How to enable mixed precision optimization
In order to demonstrate the impact of BF16 on model accuracy AUC (Area Under Curve) and performance Gsteps/s, the above mixed precision optimization method is applied to existing modelzoo models. The evaluation of Alibaba PAI team using DeepRec on the Alibaba Cloud platform shows that [1], based on the Criteo data set and optimized using BF16, the model WDL accuracy or AUC can approach FP32, and the training performance of the BF16 model is improved by up to 1.4 times, which is a significant effect.
In the future, in order to maximize the advantages of CPU platform hardware, especially to maximize the effect of new hardware features, DeepRec will further implement optimization from different angles, including optimizer operators , attention subgraphs, adding multi-objective models, etc. to create higher-performance CPU solutions for sparse scenes.
Use PMem to implement Embedding storage
For very large scale If the sparse model training and prediction engine (hundred billion features, trillions of samples, and 10TB model level) is all stored in dynamic random access memory (DynamicRandomAccessMemory, DRAM), the total cost of ownership (Total Cost of Ownership) will be greatly increased. , TCO), at the same time, it puts huge pressure on the IT operation and management of enterprises, making the implementation of AI solutions encounter challenges.
PMem has the advantages of higher storage density and data persistence, I/O performance is close to DRAM, and the cost is more affordable. It can fully meet the requirements of high performance and high performance for ultra-large-scale sparse training and prediction. Large capacity needs in both aspects.
PMem supports two operating modes, namely Memory Mode and App Direct Mode. In in-memory mode, it is identical to regular volatile (non-persistent) system storage, but at a lower cost, enabling higher capacity while maintaining system budgets, and providing terabytes of memory in a single server Total capacity; compared to memory mode, application direct access mode can take advantage of the persistence feature of PMem. In application direct access mode, PMem and its adjacent DRAM memory will be recognized as byte-addressable memory. The operating system can use PMem hardware as two different devices. One is FSDAX mode, PMem It is configured as a block device, and users can format it into a file system for use; the other is DEVDAX mode, PMem is driven as a single character device, relies on the KMEM DAX feature provided by the kernel (5.1 or above), and treats PMem as volatile It uses non-standard memory and is connected to the memory management system. As a slower and larger memory NUMA node similar to DRAM, the application can access it transparently.
In very large-scale feature training, Embedding variable storage takes up more than 90% of the memory, and memory capacity will become one of its bottlenecks. Saving EV to PMem can break this bottleneck and create multiple values, such as improving the memory storage capacity of large-scale distributed training, supporting the training and prediction of larger models, reducing communication between multiple machines, and improving model training performance. , while reducing TCO.
In Embedding multi-level hybrid storage, PMem is also an excellent choice to break the DRAM bottleneck. Currently, there are three ways to store EVs into PMem, and when running micro-benchmark, WDL model and WDL-proxy model in the following three ways, the performance is very close to that of storing EVs into DRAM, which undoubtedly makes its TCO better. Big advantage:
- Configure PMem into memory mode to save EV;
- Configure PMem into application direct access FSDAX mode , and use the allocator based on the Libpmem library to save EV;
- #Configure PMem as a NUMA node and use the allocator based on the Memkind library to save EV.
The Alibaba PAI team used 3 ways to save EV on the Alibaba Cloud memory-enhanced instance ecs.re7p.16xlarge to conduct a comparative test of the WDL stand-alone model in Modelzoo[2], these three methods are to store EV in DRAM, use the allocator based on Libpmem library to save EV and use the allocator based on Libpmem library to save EV. Memkind library allocator to save EV, test results show that the performance of saving EV to PMem is very close to that of saving EV to DRAM.

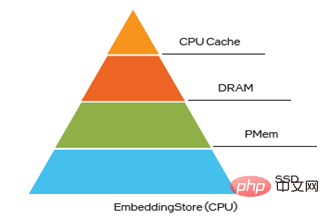
##Figure 4 Embedding multi-level hybrid storage
Therefore, the next optimization plan will use PMem to save the model and store the sparse model checkpoint file in persistent memory to achieve multiple orders of magnitude performance improvement and get rid of the current use of SSD to save and restore. Very large models take a long time, and training predictions will be interrupted during the process.
FPGA Accelerated Embedding Lookup
##Big Scaled sparse training and prediction cover a variety of scenarios, such as distributed training, single-machine and distributed prediction, and heterogeneous computing training. Compared with traditional Convolutional Neural Network (CNN) or Recurrent Neural Networks (RNN), they have a key difference, that is, the processing of embedding table, and the Embedding table processing requirements in these scenarios are faced with New challenges:
- Huge storage capacity requirements (up to 10TB or more);
- Relatively low computing density;
- Irregular memory access pattern.
- Use software through multi-threading The implemented KV engine has become the bottleneck of circulation;
- The overhead brought by rpc based on TCP/RDMA makes Parameter Server become a bottleneck during distributed expansion. Obvious latency and performance bottlenecks.
In order to solve the problem of circulation bottleneck and delay, Intel® Agilex that supports CXL (Compute Express Link) was introduced in the optimization. TM I series FPGA, the implementation path is shown in Figure 5:
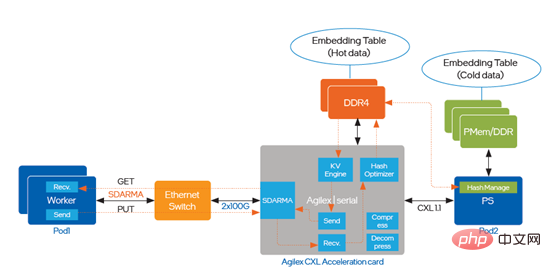
##Figure 5 introduces Intel® AgilexTM I series FPGA implementation optimization The acceleration solution based on Intel® AgilexTM I series FPGA can support all the above scenarios on one hardware platform, significantly increasing the throughput. , while providing lower access latency. The previous article introduced the optimization implementation scheme of DeepRec on different hardware of CPU, PMem and FPGA, and successfully deployed it to multiple internal and external business scenarios of Alibaba , it has also achieved significant end-to-end performance acceleration in actual business, and solved the problems and challenges faced by ultra-large-scale sparse scenarios from different angles. As we all know, Intel provides diversified hardware options for AI applications, making it possible for customers to choose more cost-effective AI solutions; at the same time, Intel, Alibaba and its customers are working together to implement software-hardware innovation based on diversified hardware. Collaborate and optimize to more fully realize the value of Intel technologies and platforms. Intel also hopes to continue to work with industry partners to develop deeper cooperation and continue to contribute to the deployment of AI technology. Intel does not control or audit third-party data. Please review this content, consult other sources, and confirm that the data mentioned is accurate. Performance test results are based on testing conducted on April 27, 2022, and May 23, 2022, and may not reflect all publicly available security updates. See Configuration Disclosure for details. No product or component is completely safe. The cost reduction scenarios described are intended to illustrate how specific Intel products can impact future costs and provide cost savings in specific situations and configurations. Every situation is different. Intel does not guarantee any costs or cost reductions. Intel technology features and benefits depend on system configuration and may require enabled hardware, software or services to be activated. Product performance will vary based on system configuration. No product or component is completely safe. More information is available from the original equipment manufacturer or retailer, or see intel.com. Intel, the Intel logo, and other Intel trademarks are trademarks of Intel Corporation or its subsidiaries in the United States and/or other countries. © Intel Corporation All Rights Reserved [1] If you want To learn more about performance testing, please visit https://github.com/alibaba/DeepRec/tree/main/modelzoo/WDL [2] For more details on performance testing, please visit https://help.aliyun.com/document_detail/25378.html?spm=5176.2020520101.0.0.787c4df5FgibRE#re7p
Summary
Legal Notice
The above is the detailed content of Intel helps build open source large-scale sparse model training/prediction engine DeepRec. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology