
Home >Database >Mysql Tutorial >How to find slow SQL statements in MySQL
How to find slow SQL statements in MySQL

- 黄舟Original
- 2017-05-21 09:15:101275browse
This article mainly introduces the method of finding slow SQL statements in Query in MySQL. Friends in need can refer to
How to find slow SQL statements in mysql What about SQL statements? This may be a problem for many people. MySQL uses slow query logs to locate SQL statements with low execution efficiency. When starting with the --log-slow-queries[=file_name] option, mysqld A log file containing all SQL statements whose execution time exceeds long_query_time seconds will be written, and less efficient SQL statements can be located by viewing this log file. The following describes how to query slow SQL statements in MySQL
1.MySQL databaseThere are several configuration options that can help us capture inefficient SQL statements in a timely manner
1, slow_query_log
This parameter is set to ON to capture SQL statements whose execution time exceeds a certain value.
2, long_query_time
When the SQL statement execution time exceeds this value, it will be recorded in the log. It is recommended to set it to 1 or shorter.
3, slow_query_log_file
The file name of the log.
4, log_queries_not_using_indexes
This parameter is set to ON, which can capture all SQL statements that do not use indexes, although this SQL statement may execute very quickly.
2. Method to detect the efficiency of sql statements in mysql
1. Through query log
(1), enable MySQL slow query under Windows
MySQL's configuration file in the Windows system is usually found in my.ini [mysqld] and adds
The code is as follows
log-slow -queries=F:/MySQL/log/mysqlslowquery. log
long_query_time = 2
(2)、Enable MySQL slow query under Linux
The configuration file of MySQL in Windows system is usually found in my.cnf [mysqld]Add
below and the code is as follows
log-slow-queries=/data/mysqldata/slowquery. log
long_query_time=2
Description
log-slow-queries = F:/MySQL/log/mysqlslowquery.
is the location where the slow query log is stored. Generally, this directory must have writable permissions for the MySQL running account. This directory is generally set as the MySQL data storage directory;
long_query_time=2 of 2 Indicates that the query will not be recorded until it takes more than two seconds;
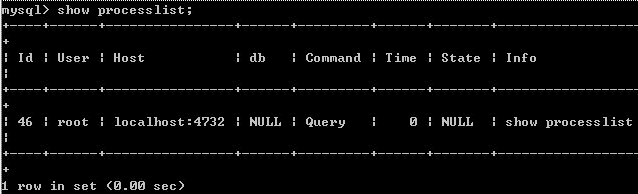
2.show processlist Command
WSHOW PROCESSLIST displays which threads are running. You can also use the mysqladmin processlist statement to get this information.
The meaning and purpose of each column:
ID column
An identifier. It is very useful when you want to kill a statement. Use the command to kill it. This query /*/mysqladmin kill process number.
User column
Displays the previous user. If you are not root, this command will only display the sql statements within your authority.
host column
Shows which IP and port this statement is sent from. Used to track the user who issued the problematic statement.
db column
Displays which database this process is currently connected to.
command column
Displays the executed command of the current connection, usually sleep, query, and connect.
time column
The duration of this state, the unit is seconds.
state column
Displays the status of the sql statement using the current connection. It is a very important column. All status descriptions will be described later. Please note that state is only a certain state in the execution of the statement. , a sql statement, taking query as an example, may need to go through copying to tmp table, Sorting result, Sending data and other states before it can be completed.
info column
Displays this sql statement. Because the length is limited, long sql statements are not fully displayed, but it is an important basis for judging problematic statements.
The most critical thing in this command is the state column. The states listed by mysql mainly include the following:
Checking table
Checking the data table (this is automatic).
Closing tables
The modified data in the table is being flushed to disk, and the tables that have been used up are being closed. This is a quick operation, but if this is not the case, you should verify that the disk space is full or that the disk is under heavy load.
Connect Out
The replication slave server is connecting to the master server.
Copying to tmp table on disk
Since the temporary result set is larger than tmp_table_size, the temporary table is being converted from memory storage to disk storage to save memory.
Creating tmp table
A temporary table is being created to store some query results.
deleting from main table
The server is executing the first part of multi-table deleting , and the first table has just been deleted.
deleting from reference tables
The server is executing the second part of multi-table deletion and is deleting records from other tables.
Flushing tables
Executing FLUSH TABLES, waiting for other threads to close the data table.
Killed
If a kill request is sent to a thread, then the thread will check the kill flag and give up the next kill request. MySQL will check the kill flag in each mainloop, but in some cases the thread may die after a short period of time. If the thread is locked by another thread, the kill request will take effect immediately when the lock is released.
Locked
Locked by other queries.
Sending data
The records of the SELECT query are being processed and the results are being sent to the client.
Sorting for group
Sorting for GROUP BY.
Sorting for order
Sorting for ORDER BY.
Opening tables
This process should be fast unless interfered by other factors. For example, the data table cannot be opened by other threads before the ALTER TABLE or LOCK TABLE statement is executed. Trying to open a table.
Removing duplicates
A SELECT DISTINCT query is being executed, but MySQL cannot optimize out those duplicate records in the previous stage. Therefore, MySQL needs to remove duplicate records again before sending the results to the client.
Reopen table
Obtained a lock on a table, but the lock must be obtained after the table structure is modified. The lock has been released, the data table has been closed, and an attempt is made to reopen the data table.
Repair by sorting
The repair directive is sorting to create the index.
Repair with keycache
The repair command is using the index cache to create new indexes one by one. It will be slower than Repair by sorting.
Searching rows for update
We are finding records that meet the conditions for update. It must be completed before UPDATE is to modify the related records.
Sleeping
Waiting for the client to send a new request.
System lock
Waiting to obtain an external system lock. If you are not currently running multiple mysqld servers requesting the same table at the same time, you can disable external system locks by adding the --skip-external-locking parameter.
Upgrading lock
INSERT DELAYED is trying to obtain a lock table to insert new records.
Updating
Searching for matching records and modifying them.
Waiting for GET_LOCK().
Waiting for tables
The thread is notified that the data table structure has been modified and the data table needs to be reopened to obtain the new structure. Then, in order to reopen the data table, you must wait until all other threads close the table. This notification will be generated in the following situations: FLUSH TABLES tbl_name, ALTER TABLE, RENAME TABLE, REPAIR TABLE, ANALYZE TABLE, or OPTIMIZE TABLE.
waiting for han
dler insert INSERT DELAYED has processed all pending insert operations and is waiting for new requests.
Most states correspond to very fast operations. As long as one thread remains in the same state for several seconds, there may be a problem and it needs to be checked.
There are other statuses not listed above, but most of them are only useful to check if there are any errors on the server.
For example:
3. Explain tounderstand the status of SQLexecution
explain shows how mysql uses indexes to process select statements and connection tables. It can help choose better indexes and write more optimized query statements.
How to use it, just add explain before the select statement:
For example:
explain select surname,first_name form a,b where a.id=b.id
The result is as shown in the figure

Explanation of EXPLAIN column
table
Show which table the data in this row refers to
type
This is an important column that shows what type is used for the connection. The join types from best to worst are const, eq_reg, ref, range, indexhe and ALL
possible_keys
Show possible applications in Index in this table. If empty, no index is possible. You can select an appropriate statement from the WHERE statement for the relevant domain
key
The actual index used. If NULL, no index is used. Rarely, MYSQL will select an index that is under-optimized. In this case, you can use USE INDEX (indexname) in the SELECT statement to force the use of an index or IGNORE INDEX (indexname) to force MYSQL to ignore the index used by the index
key_len
length. The shorter the length the better without losing accuracy
ref
Shows which column of the index is used, a constant if possible
rows
The number of rows that MYSQL believes must be examined to return the requested data
Extra
Extra information about how MYSQL parses the query. Will be discussed in Table 4.3, but bad examples that can be seen here are Using temporary and Using filesort, meaning that MYSQL cannot use the index at all, and the result is that the retrieval will be very slow
Description of the extra column returned The meaning
Distinct
Once MYSQL finds a row that matches the row union, it will no longer search
Not exists
MYSQL Optimized LEFT JOIN so that once it finds a row matching the LEFT JOIN criteria, it no longer searches
Range checked for each Record(index map :#)
The ideal index was not found, so for each combination of rows from the previous table, MYSQL checks which index was used and uses it to return the rows from the table. This is one of the slowest connections using an index
Using filesort
When you see this, the query needs to be optimized. MYSQL requires an extra step to discover how to sort the returned rows. It sorts all rows based on the connection type and the row pointers that store the sort key value and all rows matching the condition. Returned from the actual action table. This occurs when all requested columns of the table are part of the same index.
Using temporary
When you see this, the query needs improved. Here, MYSQL needs to create a temporary table to store the results. This usually occurs when ORDER BY is performed on different column sets instead of GROUP BY.
Where used
The WHERE clause is used to Limit which rows will match the next table or be returned to the user. This will happen if you do not want to return all rows in the table and the connection type is ALL or index, or there is a problem with the query. Explanation of different connection types (sorted in order of efficiency)
const
The maximum value of a record in the table that can match this query (the index can be a primary key or a unique index). Because there is only one row, this value is actually a constant, because MYSQL reads this value first and then treats it as a constant
eq_ref
In the connection, MYSQL reads the value from the previous table when querying , for each record union, a record is read from the table. It is used when the query uses the index as the primary key or the entire unique key.
ref
This connection type is only used when querying Occurs when a key that is not a unique or primary key is used, or is part of these types (e.g., using a leftmost prefix). For each row join of the previous table, all records will be read from the table. This type relies heavily on how many records are matched based on the index - the fewer the better
range
This join type uses the index to return a range of rows, such as using > or 4fcb229959b20b9368f337a7586e84a9 create index idx_sales_year on sales(year);
Query OK, 12 rows affected (0.01 sec)
Records: 12 Duplicates: 0 Warnings: 0
创建索引后,这条语句的执行计划如下:
mysql> explain select sum(profit) from sales a,company b where a.company_id = b.id and a.year = 2006\G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: a type: ref possible_keys: idx_sales_year key: idx_sales_year key_len: 4 ref: const rows: 3 Extra: *************************** 2. row *************************** id: 1 select_type: SIMPLE table: b type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 12 Extra: Using where 2 rows in set (0.00 sec)
可以发现建立索引后对 a 表需要扫描的行数明显减少(从全表扫描减少到 3 行),可见索引的使用可以大大提高数据库的访问速度,尤其在表很庞大的时候这种优势更为明显,使用索引优化 sql 是优化问题 sql 的一种常用基本方法,在后面的章节中我们会具体介绍如何使索引来优化 sql 。
本文主要介绍的是MySQL慢查询分析方法,前一段日子,我曾经设置了一次记录在MySQL数据库中对慢于1秒钟的SQL语句进行查询。想起来有几个十分设置的方法,有几个参数的名称死活回忆不起来了,于是重新整理一下,自己做个笔记。
对于排查问题找出性能瓶颈来说,最容易发现并解决的问题就是MySQL慢查询以及没有得用索引的查询。
OK,开始找出MySQL中执行起来不“爽”的SQL语句吧。
MySQL慢查询分析方法一:
这个方法我正在用,呵呵,比较喜欢这种即时性的。
MySQL5.0以上的版本可以支持将执行比较慢的SQL语句记录下来。
MySQL> show variables like 'long%';
注:这个long_query_time是用来定义慢于多少秒的才算“慢查询”
+-----------------+-----------+ | Variable_name | Value | +-----------------+-----------+ | long_query_time | 10.000000 | +-----------------+-----------+ 1 row in set (0.00 sec) MySQL> set long_query_time=1; 注: 我设置了1, 也就是执行时间超过1秒的都算慢查询。 Query OK, 0 rows affected (0.00 sec) MySQL> show variables like 'slow%'; +---------------------+---------------+ | Variable_name | Value | +---------------------+---------------+ | slow_launch_time | 2 | | slow_query_log | ON | 注:是否打开日志记录 | slow_query_log_file | /tmp/slow.log | 注: 设置到什么位置 +---------------------+---------------+ 3 rows in set (0.00 sec) MySQL> set global slow_query_log='ON'
注:打开日志记录
一旦slow_query_log变量被设置为ON,MySQL会立即开始记录。
/etc/my.cnf 里面可以设置上面MySQL全局变量的初始值。
long_query_time=1 slow_query_log_file=/tmp/slow.log
MySQL慢查询分析方法二:
MySQLdumpslow命令
/path/MySQLdumpslow -s c -t 10 /tmp/slow-log
这会输出记录次数最多的10条SQL语句,其中:
-s, 是表示按照何种方式排序,c、t、l、r分别是按照记录次数、时间、查询时间、返回的记录数来排序,ac、at、al、ar,表示相应的倒叙;
-t, 是top n的意思,即为返回前面多少条的数据;
-g, 后边可以写一个正则匹配模式,大小写不敏感的;
比如
/path/MySQLdumpslow -s r -t 10 /tmp/slow-log
得到返回记录集最多的10个查询。
/path/MySQLdumpslow -s t -t 10 -g “left join” /tmp/slow-log
得到按照时间排序的前10条里面含有左连接的查询语句。
简单点的方法:
打开 my.ini ,找到 [mysqld] 在其下面添加 long_query_time = 2 log-slow-queries = D:/mysql/logs/slow.log #设置把日志写在那里,可以为空,系统会给一个缺省的文件 #log-slow-queries = /var/youpath/slow.log linux下host_name-slow.log log-queries-not-using-indexes long_query_time 是指执行超过多长时间(单位是秒)的sql会被记录下来,这里设置的是2秒。
以下是mysqldumpslow常用参数说明,详细的可应用mysqldumpslow -help查询。 -s,是表示按照何种方式排序,c、t、l、r分别是按照记录次数、时间、查询时间、返回的记录数来排序(从大到小),ac、at、al、ar表示相应的倒叙。 -t,是top n的意思,即为返回前面多少条数据。 www.jb51.net -g,后边可以写一个正则匹配模式,大小写不敏感。 接下来就是用mysql自带的慢查询工具mysqldumpslow分析了(mysql的bin目录下 ),我这里的日志文件名字是host-slow.log。 列出记录次数最多的10个sql语句 mysqldumpslow -s c -t 10 host-slow.log 列出返回记录集最多的10个sql语句 mysqldumpslow -s r -t 10 host-slow.log 按照时间返回前10条里面含有左连接的sql语句 mysqldumpslow -s t -t 10 -g "left join" host-slow.log 使用mysqldumpslow命令可以非常明确的得到各种我们需要的查询语句,对MySQL查询语句的监控、分析、优化起到非常大的帮助
在日常开发当中,经常会遇到页面打开速度极慢的情况,通过排除,确定了,是数据库的影响,为了迅速查找具体的SQL,可以通过Mysql的日志记录方法。
-- 打开sql执行记录功能
set global log_output='TABLE'; -- 输出到表
set global log=ON; -- 打开所有命令执行记录功能general_log, 所有语句: 成功和未成功的.
set global log_slow_queries=ON; -- 打开慢查询sql记录slow_log, 执行成功的: 慢查询语句和未使用索引的语句
set global long_query_time=0.1; -- 慢查询时间限制(秒)
set global log_queries_not_using_indexes=ON; -- 记录未使用索引的sql语句
-- 查询sql执行记录
select * from mysql.slow_log order by 1; -- 执行成功的:慢查询语句,和未使用索引的语句
select * from mysql.general_log order by 1; -- 所有语句: 成功和未成功的.
-- 关闭sql执行记录
set global log=OFF;
set global log_slow_queries=OFF;
-- long_query_time参数说明
-- v4.0, 4.1, 5.0, v5.1 到 5.1.20(包括):不支持毫秒级别的慢查询分析(支持精度为1-10秒);
-- 5.1.21及以后版本 :支持毫秒级别的慢查询分析, 如0.1;
-- 6.0 到 6.0.3: 不支持毫秒级别的慢查询分析(支持精度为1-10秒);
-- 6.0.4及以后:支持毫秒级别的慢查询分析;
通过日志中记录的Sql,迅速定位到具体的文件,优化sql看一下,是否速度提升了呢?
本文针对MySQL数据库服务器查询逐渐变慢的问题, 进行分析,并提出相应的解决办法,具体的分析解决办法如下:会经常发现开发人员查一下没用索引的语句或者没有limit n的语句,这些没语句会对数据库造成很大的影...
本文针对MySQL数据库服务器查询逐渐变慢的问题, 进行分析,并提出相应的解决办法,具体的分析解决办法如下:
会经常发现开发人员查一下没用索引的语句或者没有limit n的语句,这些没语句会对数据库造成很大的影响,例如一个几千万条记录的大表要全部扫描,或者是不停的做filesort,对数据库和服务器造成io影响等。这是镜像库上面的情况。
而到了线上库,除了出现没有索引的语句,没有用limit的语句,还多了一个情况,mysql连接数过多的问题。说到这里,先来看看以前我们的监控做法
1. 部署zabbix等开源分布式监控系统,获取每天的数据库的io,cpu,连接数
2. 部署每周性能统计,包含数据增加量,iostat,vmstat,datasize的情况
3. Mysql slowlog收集,列出top 10
以前以为做了这些监控已经是很完美了,现在部署了mysql节点进程监控之后,才发现很多弊端
第一种做法的弊端: zabbix太庞大,而且不是在mysql内部做的监控,很多数据不是非常准备,现在一般都是用来查阅历史的数据情况
第二种做法的弊端:因为是每周只跑一次,很多情况没法发现和报警
第三种做法的弊端: 当节点的slowlog非常多的时候,top10就变得没意义了,而且很多时候会给出那些是一定要跑的定期任务语句给你。。参考的价值不大
那么我们怎么来解决和查询这些问题呢
对于排查问题找出性能瓶颈来说,最容易发现并解决的问题就是MYSQL的慢查询以及没有得用索引的查询。
OK,开始找出mysql中执行起来不“爽”的SQL语句吧。
方法一: 这个方法我正在用,呵呵,比较喜欢这种即时性的。
Mysql5.0以上的版本可以支持将执行比较慢的SQL语句记录下来。
mysql> show variables like 'long%'; 注:这个long_query_time是用来定义慢于多少秒的才算“慢查询”
+-----------------+-----------+ | Variable_name | Value | +-----------------+-----------+ | long_query_time | 10.000000 | +-----------------+-----------+ 1 row in set (0.00 sec) mysql> set long_query_time=1; 注: 我设置了1, 也就是执行时间超过1秒的都算慢查询。 Query OK, 0 rows affected (0.00 sec) mysql> show variables like 'slow%'; +---------------------+---------------+ | Variable_name | Value | +---------------------+---------------+ | slow_launch_time | 2 | | slow_query_log | ON | 注:是否打开日志记录 | slow_query_log_file | /tmp/slow.log | 注: 设置到什么位置 +---------------------+---------------+ 3 rows in set (0.00 sec)
mysql> set global slow_query_log='ON' 注:打开日志记录
一旦slow_query_log变量被设置为ON,mysql会立即开始记录。
/etc/my.cnf 里面可以设置上面MYSQL全局变量的初始值。
long_query_time=1
slow_query_log_file=/tmp/slow.log
方法二:mysqldumpslow命令
/path/mysqldumpslow -s c -t 10 /tmp/slow-log
这会输出记录次数最多的10条SQL语句,其中:
-s, 是表示按照何种方式排序,c、t、l、r分别是按照记录次数、时间、查询时间、返回的记录数来排序,ac、at、al、ar,表示相应的倒叙;
-t, 是top n的意思,即为返回前面多少条的数据;
-g, 后边可以写一个正则匹配模式,大小写不敏感的;
比如
/path/mysqldumpslow -s r -t 10 /tmp/slow-log
得到返回记录集最多的10个查询。
/path/mysqldumpslow -s t -t 10 -g “left join” /tmp/slow-log
得到按照时间排序的前10条里面含有左连接的查询语句。
最后总结一下节点监控的好处
1. 轻量级的监控,而且是实时的,还可以根据实际的情况来定制和修改
2. 设置了过滤程序,可以对那些一定要跑的语句进行过滤
3. 及时发现那些没有用索引,或者是不合法的查询,虽然这很耗时去处理那些慢语句,但这样可以避免数据库挂掉,还是值得的
4. 在数据库出现连接数过多的时候,程序会自动保存当前数据库的processlist,DBA进行原因查找的时候这可是利器
5. 使用mysqlbinlog 来分析的时候,可以得到明确的数据库状态异常的时间段
有些人会建义我们来做mysql配置文件设置
调节tmp_table_size 的时候发现另外一些参数
Qcache_queries_in_cache 在缓存中已注册的查询数目
Qcache_inserts 被加入到缓存中的查询数目
Qcache_hits 缓存采样数数目
Qcache_lowmem_prunes 因为缺少内存而被从缓存中删除的查询数目
Qcache_not_cached 没有被缓存的查询数目 (不能被缓存的,或由于 QUERY_CACHE_TYPE)
Qcache_free_memory 查询缓存的空闲内存总数
Qcache_free_blocks 查询缓存中的空闲内存块的数目
Qcache_total_blocks 查询缓存中的块的总数目
Qcache_free_memory 可以缓存一些常用的查询,如果是常用的sql会被装载到内存。那样会增加数据库访问速度
The above is the detailed content of How to find slow SQL statements in MySQL. For more information, please follow other related articles on the PHP Chinese website!