
Home >Technology peripherals >AI >178 pages! The first comprehensive case evaluation of GPT-4V (ision) in the medical field: there is still a distance from clinical application and practical decision-making
178 pages! The first comprehensive case evaluation of GPT-4V (ision) in the medical field: there is still a distance from clinical application and practical decision-making

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-07-19 18:25:03467browse
Shanghai Jiao Tong University & Shanghai AI Lab released a 178-page GPT-4V medical case evaluation, comprehensively revealing the visual performance of GPT-4V in the medical field for the first time ArXiv link: https://arxiv.org/abs/2310.09909 Other paper download address: Baidu Cloud: https ://pan.baidu.com/s/11xV8MkUfmF3emJQH9awtcw?pwd=krk2Google Drive: https://drive.google.com/file/d/1HPvPDwhgpOwxi2sYH3_xrcaoXjBGWhK9/view?usp=sharingResearch Introduction Driven by large-scale basic models, artificial intelligence The development of intelligence has made great progress recently, especially OpenAI's GPT-4. Its powerful capabilities in question and answer and knowledge have lit up the Eureka moment in the AI field and attracted widespread public attention. GPT-4V(ision) is OpenAI’s latest multi-modal basic model. Compared with GPT-4, it adds image and voice input capabilities. This study aims to evaluate the performance of GPT-4V(ision) in the field of multi-modal medical diagnosis through case analysis. A total of 128 (92 radiology evaluation cases, 20 pathology evaluation cases and 16 positioning cases) were displayed and analyzed. Case) GPT-4V question and answer example with a total of 277 images in each case (Note: This article will not involve case display, please refer to the original paper for specific case display and analysis). In summary, the original author hopes to systematically evaluate the following capabilities of GPT-4V: Can GPT-4V recognize the modality and imaging position of medical images? Recognizing various modalities (such as X-ray, CT, MRI, ultrasound, and pathology) and identifying the imaging locations in these images is the basis for more complex diagnoses. Can GPT-4V localize different anatomical structures in medical images? Pinpointing specific anatomical structures in images is critical to identifying abnormalities and ensuring potential issues are addressed correctly. Can GPT-4V find and locate abnormalities in medical images? Detecting abnormalities such as tumors, fractures or infections is a major goal of medical image analysis. In a clinical setting, reliable AI models need to not only detect these anomalies, but also pinpoint them so that targeted intervention or treatment can be performed. Can GPT-4V combine multiple images for diagnosis? Medical diagnosis often requires integrating information from different imaging modalities or views for overall observation. It is therefore crucial to explore GPT-4V’s ability to combine and analyze information from multiple images. Can GPT-4V write a medical report describing abnormal conditions and associated normal findings? For radiologists and pathologists, report writing is a time-consuming task. If GPT-4V helps in this process, generating accurate and clinically relevant reports, it will undoubtedly increase the efficiency of the entire workflow. Can GPT-4V integrate patient history when interpreting medical images? Basic patient information and past medical history can significantly influence the interpretation of current medical images. If this information can be taken into account to analyze images during the model prediction process, the analysis will be more personalized and more accurate. Can GPT-4V maintain consistency and memory across multiple rounds of interactions? In some medical scenarios, a single round of analysis may not be sufficient. During long conversations or analyses, especially in complex healthcare environments, maintaining continuity of knowledge about the data is critical. The evaluation of the original paper covered 17 medical systems, including: central nervous system, head and neck, heart, chest and abdomen, head and neck, heart, chest, blood, hepatobiliary, gastrointestinal, urology, gynecology, obstetrics, breast, Anus, abdomen, gynecology, obstetrics, breast, musculoskeletal, spine, vascular, oncology, trauma, and pediatric images come from 8 modalities used in daily clinical use, including: X-ray, computed tomography (CT) , Magnetic Resonance Imaging (MRI), Positron Emission Tomography (PET), Digital Subtraction Angiography (DSA), Mammography, Ultrasound and Pathology.

The paper points out that although GPT-4V performs well in distinguishing medical imaging modalities and anatomical structures, it still faces huge challenges in disease diagnosis and generating comprehensive reports challenge. These findings demonstrate that large multimodal models have made significant progress in computer vision and natural language processing, but are still insufficient to support real-world medical applications and clinical decision-making.
Test case selection
The radiology Q&A of the original paper comes from [Radiopaedia](https://radiopaedia.org/), the images are downloaded directly from the web page, the positioning cases come from multiple medical public segmentation data sets, and the pathological images are Retrieved from [PathologyOutlines](https://www.pathologyoutlines.com/). When selecting cases, the author comprehensively considered the following aspects:
- Published time: To avoid the selected test cases appearing in the training set of GPT-4V, the author only selected the latest cases released in 2023.
- Annotation credibility: According to the case completion degree provided by Radiopaedia, the author tries to select cases with a completion degree greater than 90% to ensure the credibility of the annotation or diagnosis.
- Image modality diversity: When selecting cases, the author tried to show the response of GPT-4V to multiple imaging modalities as much as possible.
In terms of image processing, the author has also done the following standardization to ensure the quality of the input image:
- Sélection d'images multiples : GPT-4V prend en charge jusqu'à 4 entrées d'images, mais certains cas peuvent avoir plus de 4 images associées. Les auteurs tentent d'éviter cette situation dans la mesure du possible et, le cas échéant, sélectionnent les images les plus pertinentes sur la base des notes de cas de Radiopaedia.
- Sélection de section : Une grande quantité de données d'images radiographiques est sous forme 3D et ne peut pas être directement saisie dans GPT-4V. Les auteurs ont utilisé des coupes axiales recommandées par Radiopaedia pour la saisie au lieu d'images 3D complètes.
- Standardisation des images : La standardisation des images médicales comprend la sélection de la largeur et du niveau de la fenêtre. Les auteurs ont saisi les images en utilisant la largeur et le niveau de fenêtre sélectionnés par le radiologue au moment du téléchargement du cas Radiopaedia. Pour l'ensemble de données fractionné, l'article d'origine utilise une fenêtre de [-300, 300] et effectue une normalisation au niveau du cas de 0-1.
L'article original a été testé à l'aide de la [version Web] de GPT-4V (https://chat.openai.com/). Lors de la première série de questions-réponses, les utilisateurs saisiront des images, puis plusieurs séries de questions-réponses commenceront. Afin d'éviter toute influence mutuelle du contexte, pour chaque nouveau cas, une nouvelle fenêtre de questions-réponses sera créée pour les questions-réponses.
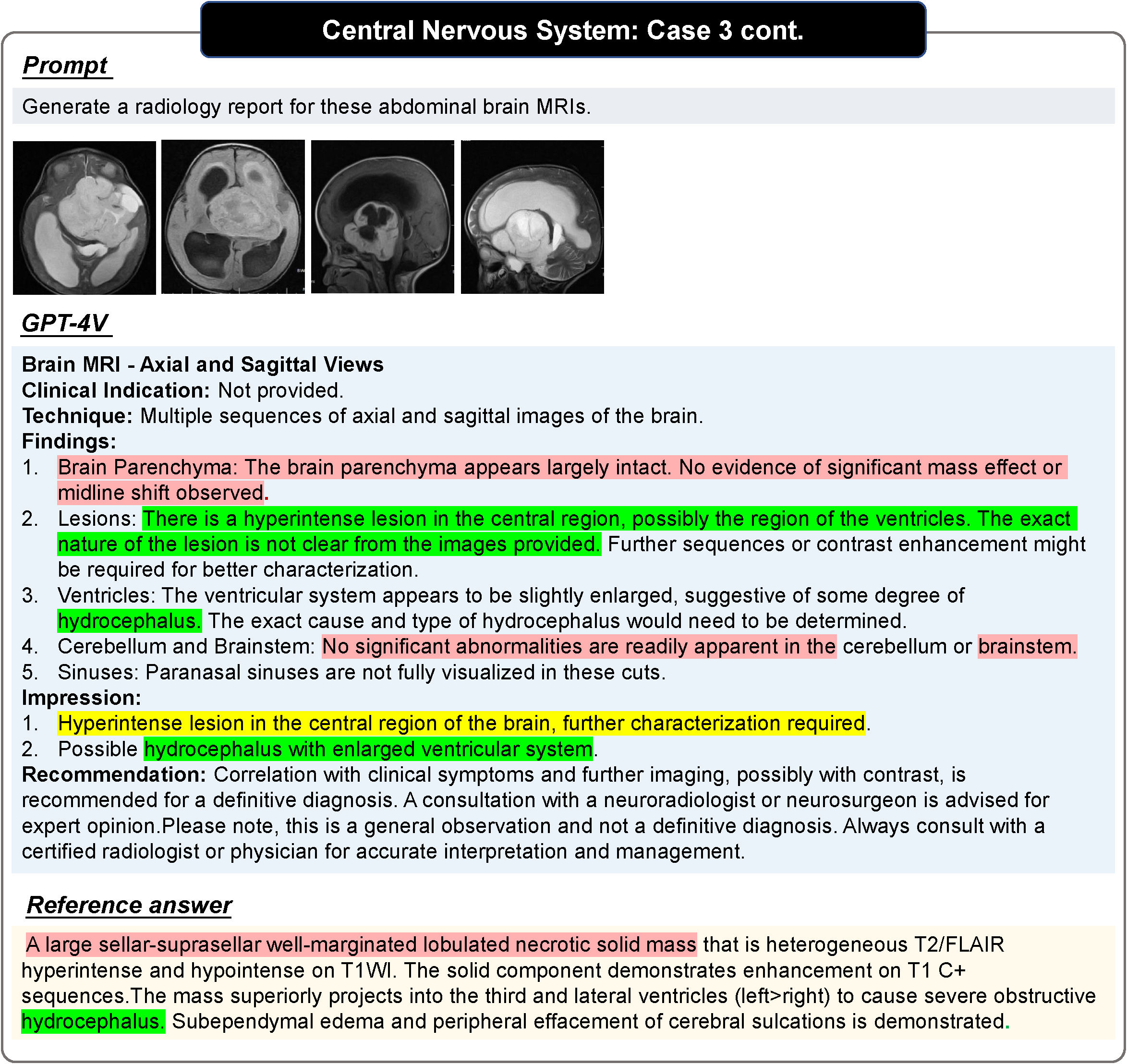
Le rouge sur l'image indique une erreur, le jaune indique une incertitude et le vert indique que c'est correct. Les couleurs dans Référence indiquent la base du jugement correspondant. Les phrases qui ne sont pas colorées obligent les lecteurs à juger de leur propre exactitude. Pour plus de cas et d’analyses de cas, veuillez vous référer à l’article original.
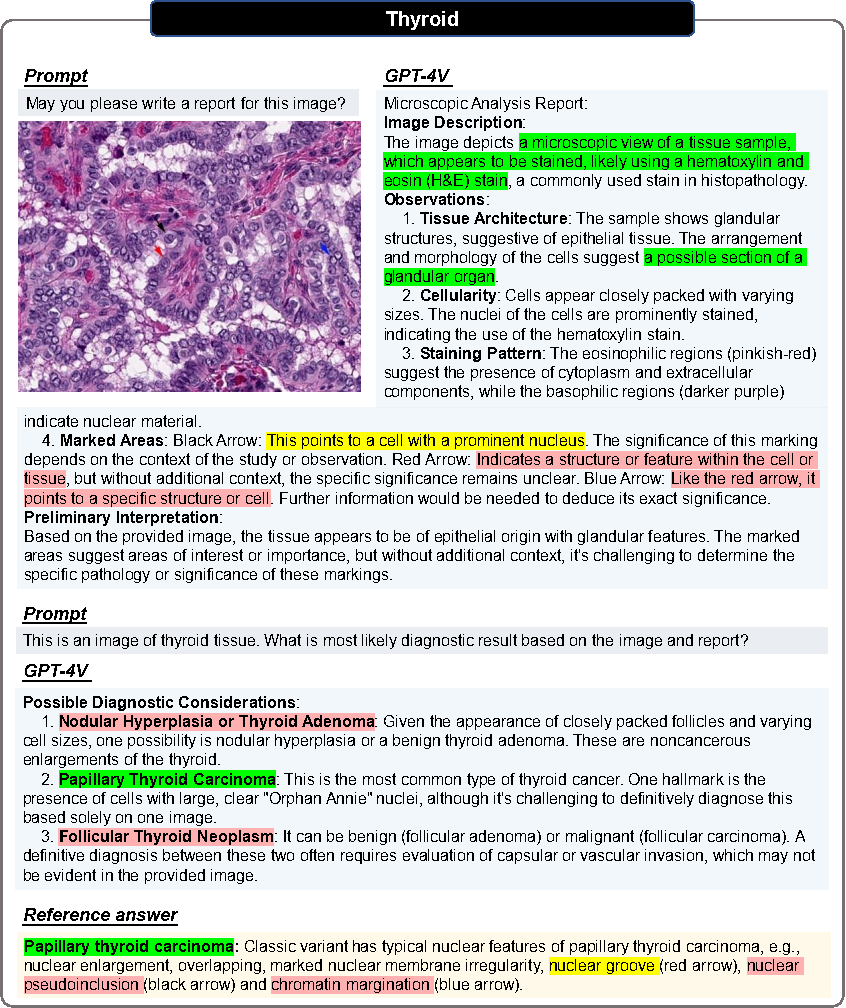
Évaluation pathologique
Toutes les images subissent deux tours de dialogue.
Round 1
Demandez si vous pouvez générer un rapport basé uniquement sur les images d'entrée.
Objectif : évaluer si GPT-4V peut identifier la modalité d'image et l'origine des tissus sans fournir d'indices médicaux pertinents.
Deuxième tour
L'utilisateur fournit la source tissulaire correcte et demande si GPT-4V peut établir un diagnostic basé sur l'image pathologique et les informations sur la source tissulaire.
J'espère que GPT-4V révisera le rapport et fournira un diagnostic clair.
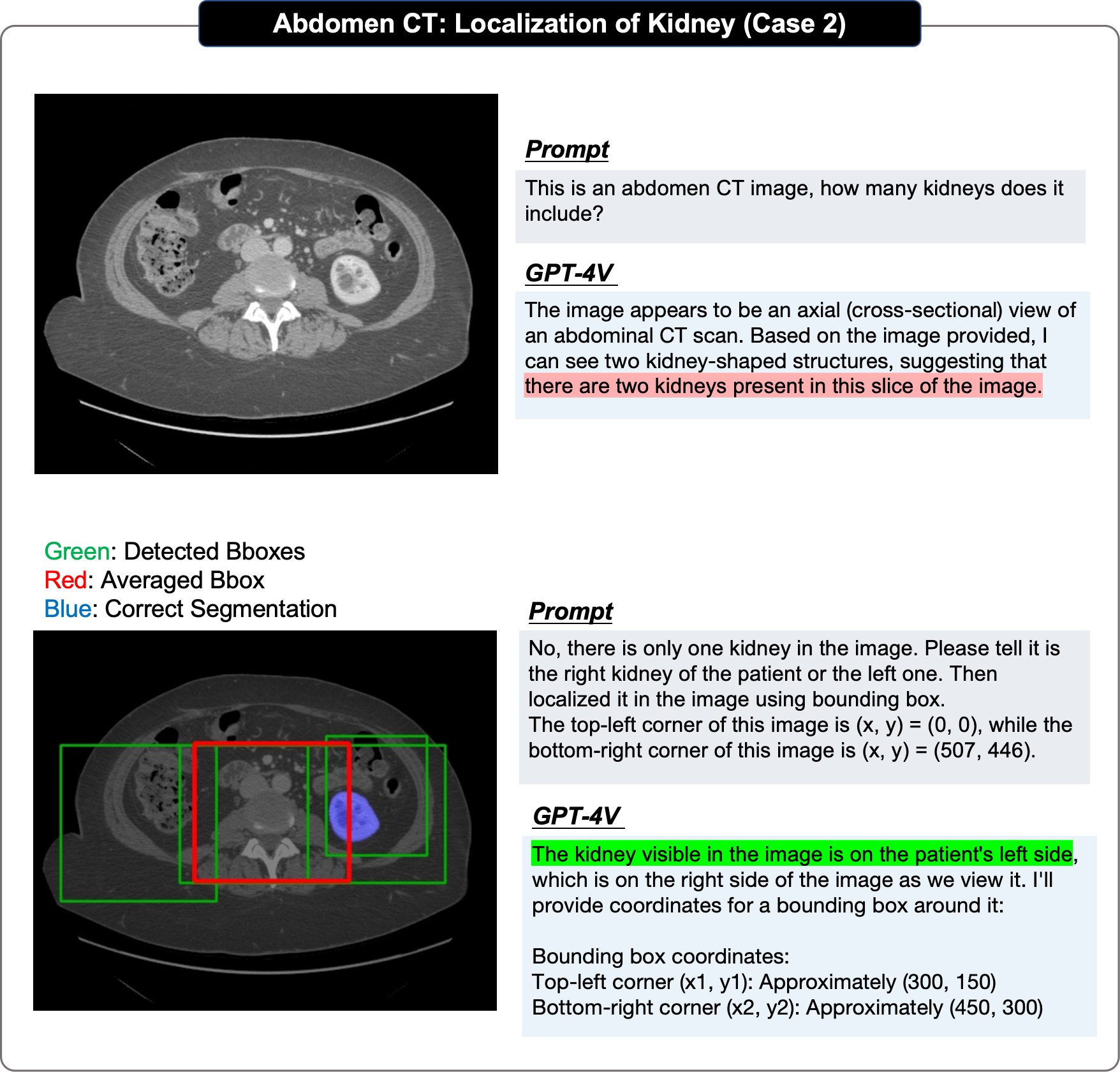
Dans l'évaluation du positionnement, l'article original a adopté une approche étape par étape :
- Premier test si GPT-4V peut identifier la cible dans l'image fournie L'existence de La tâche de localisation unique est évaluée à plusieurs reprises pour obtenir au moins 4 cadres englobants prédits, calculer leurs scores IOU et sélectionner le plus élevé pour prouver sa performance limite supérieure
- Ensuite, le une boîte englobante moyenne est dérivée et le score IOU est calculé pour prouver sa performance moyenne.
-
Limitations de l'évaluation
 Bien entendu, l'auteur original a également mentionné certaines lacunes et limites de l'évaluation :
Bien entendu, l'auteur original a également mentionné certaines lacunes et limites de l'évaluation :
Étant donné que GPT-4V ne fournit qu'une interface Web en ligne, il ne peut Le téléchargement manuel des cas de test entraîne une évolutivité limitée du rapport d'évaluation original et ne fournit donc qu'une évaluation qualitative.
Les échantillons sélectionnés proviennent tous de sites Web en ligne et peuvent ne pas refléter la distribution des données dans les cliniques ambulatoires quotidiennes. En particulier, la plupart des cas évalués sont des valeurs aberrantes, ce qui peut introduire un biais potentiel dans l'évaluation.
Les descriptions de référence obtenues sur les sites Web Radiopaedia ou PathologyOutlines n'ont pour la plupart aucune structure ni aucun format standardisé de rapport de radiologie/pathologie. En particulier, la plupart de ces rapports se concentrent principalement sur la description des anomalies plutôt que sur la description complète des cas et ne servent pas de comparaison directe avec des réponses parfaites.
Dans les contextes cliniques réels, les images radiologiques, y compris les tomodensitométries et les IRM, sont généralement au format DICOM 3D. Cependant, GPT-4V ne peut prendre en charge que la saisie de quatre images 2D au maximum, de sorte que le texte original ne peut saisir que des tranches clés 2D ou de petits fragments (pour la pathologie) lors de l'évaluation.
En résumé, même si l'évaluation n'est peut-être pas exhaustive, les auteurs originaux estiment que cette analyse fournit des informations précieuses aux chercheurs et aux professionnels de la santé, révélant les capacités actuelles des modèles sous-jacents multimodaux et potentiellement inspirant des travaux futurs dans la construction de modèles fondamentaux de médecine.
Observations importantes
Le rapport d'évaluation original résumait plusieurs caractéristiques de performance observées du GPT-4V sur la base des cas d'évaluation :
Les auteurs ont conclu comme suit sur la base de 92 cas d'évaluation radiologique et 20 cas de positionnement Observations :
- GPT-4V boleh mengenal pasti modaliti dan kedudukan pengimejan imej perubatan
GPT4-V telah menunjukkan pemprosesan yang baik untuk kebanyakan tugas seperti pengecaman mod kandungan imej, penentuan bahagian pengimejan dan penentuan kategori satah imej. Sebagai contoh, penulis menegaskan bahawa GPT-4V boleh dengan mudah membezakan pelbagai modaliti seperti MRI, CT, dan .
- GPT-4V hampir mustahil untuk membuat diagnosis yang tepat
Pengarang mendapati bahawa: di satu pihak, OpenAI nampaknya telah menyediakan mekanisme keselamatan yang mengehadkan GPT-4V daripada membuat diagnosis langsung; , kecuali untuk kes diagnostik yang sangat jelas, GPT-4V mempunyai keupayaan analisis yang lemah dan terhad kepada penyenaraian siri kemungkinan penyakit, tetapi tidak dapat memberikan diagnosis yang lebih tepat.
- GPT-4V boleh menjana laporan berstruktur, tetapi kebanyakan kandungan tidak betul
GPT-4V boleh menjana lebih banyak laporan standard dalam kebanyakan kes, tetapi penulis percaya bahawa berbanding integrasi Laporan Tulisan Tangan dengan tahap yang lebih tinggi dan kandungan yang lebih fleksibel cenderung kepada lebih banyak penerangan gambar demi gambar dan kekurangan keupayaan menyeluruh apabila menyasarkan imej berbilang modal atau berbilang bingkai. Oleh itu, kebanyakan kandungan mempunyai sedikit nilai rujukan dan kurang ketepatan.
- GPT-4V boleh mengecam penanda dan anotasi teks dalam imej perubatan, tetapi ia tidak dapat memahami maksud penampilan mereka dalam imej
GPT-4V menunjukkan pengecaman teks yang kuat, pengecaman penanda dan keupayaan lain, dan akan Cuba gunakan. penanda ini untuk analisis. Walau bagaimanapun, penulis percaya bahawa hadnya adalah: pertama, GPT-4V sentiasa menggunakan teks dan tag secara berlebihan dan imej itu sendiri menjadi objek rujukan kedua, ia kurang mantap dan sering menyalahtafsirkan maklumat perubatan dalam imej.
- GPT-4V boleh mengenal pasti peranti implan perubatan dan kedudukannya dalam imej
Dalam kebanyakan kes, GPT4-V boleh mengenal pasti peranti perubatan yang diimplan dalam tubuh manusia dengan betul dan mengesan kedudukannya secara relatif tepat. Dan penulis mendapati bahawa walaupun dalam beberapa kes yang lebih sukar, ralat diagnostik boleh berlaku tetapi peranti perubatan itu dinilai telah dikenal pasti dengan betul.
- GPT-4V akan menghadapi halangan analisis apabila menghadapi input berbilang imej
Pengarang mendapati bahawa apabila menghadapi imej dari perspektif berbeza dalam modaliti yang sama, GPT-4V akan menunjukkan prestasi yang lebih baik daripada input Ia mempunyai keupayaan analisis yang lebih baik untuk imej tunggal, tetapi ia masih cenderung untuk menganalisis setiap paparan secara berasingan apabila berhadapan dengan input bercampur imej daripada modaliti yang berbeza, adalah lebih sukar untuk GPT-4V untuk mendapatkan imej yang menggabungkan maklumat daripada analisis munasabah.
- Ramalan GPT-4V mudah berpandukan sejarah penyakit pesakit
Penulis mendapati sama ada sejarah penyakit pesakit diberikan akan memberi impak yang lebih besar kepada jawapan kepada GPT-4V. Apabila sejarah penyakit disediakan, GPT-4V sering menggunakannya sebagai titik utama untuk membuat inferens tentang kemungkinan keabnormalan dalam imej apabila sejarah penyakit tidak diberikan, GPT-4V lebih cenderung untuk menggunakan imej sebagai titik utama. Kes biasa dianalisis.
- GPT-4V tidak dapat mengesan struktur anatomi dan keabnormalan dalam imej perubatan
Pengarang percaya bahawa kesan kedudukan GPT-4V yang lemah adalah disebabkan terutamanya oleh: Pertama, GPT-4V sentiasa semakin jauh semasa proses penentududukan Ramalan kotak sempadan sebenar; kedua, ia menunjukkan rawak yang ketara dalam pelbagai pusingan ramalan berulang bagi imej yang sama, ketiga, GPT-4V menunjukkan berat sebelah yang jelas, contohnya: kecil Otak mesti berada di bahagian bawah.
- GPT-4V boleh menukar jawapan sedia ada berdasarkan beberapa pusingan interaksi pengguna.
GPT-4V boleh mengubah suai tindak balasnya menjadi betul sepanjang siri interaksi. Sebagai contoh, dalam contoh yang ditunjukkan dalam artikel, penulis memasukkan imej MRI endometriosis. GPT-4V pada mulanya salah mengklasifikasikan MRI pelvis sebagai MRI lutut, mengakibatkan output yang salah. Walau bagaimanapun, pengguna membetulkannya melalui beberapa pusingan interaksi dengan GPT-4V dan akhirnya membuat diagnosis yang tepat.
- Halusinasi GPT-4V adalah masalah yang serius, dan pesakit cenderung untuk disifatkan sebagai normal walaupun isyarat tidak normal sangat jelas.
GPT-4V sentiasa menghasilkan laporan yang kelihatan sangat lengkap dan terperinci dalam struktur, tetapi kandungannya tidak betul Dalam banyak kes, ia masih menganggap pesakit normal walaupun kawasan abnormal dalam imej itu jelas.
- GPT-4V tidak cukup stabil untuk soal jawab perubatan
GPT-4V mempunyai perbezaan prestasi yang besar antara imej biasa dan imej jarang berlaku, dan juga menunjukkan perbezaan prestasi yang jelas dalam sistem badan yang berbeza. Di samping itu, analisis imej perubatan yang sama mungkin menghasilkan keputusan yang tidak konsisten kerana perubahan gesaan Contohnya, GPT-4V pada mulanya menilai imej yang diberikan sebagai tidak normal di bawah gesaan "Apakah diagnosis untuk CT otak ini?" laporan mempertimbangkan imej yang sama seperti biasa. Ketidakkonsistenan ini menyerlahkan bahawa prestasi GPT-4V dalam diagnosis klinikal mungkin tidak stabil dan tidak boleh dipercayai.
- GPT-4V mempunyai sekatan keselamatan yang ketat dalam bidang perubatan
Pengarang mendapati bahawa GPT-4V telah menetapkan langkah perlindungan keselamatan untuk mengelakkan kemungkinan penyalahgunaan dalam Soal Jawab dalam bidang perubatan untuk memastikan pengguna boleh menggunakannya dengan selamat. Sebagai contoh, apabila GPT-4V diminta membuat diagnosis, "Sila berikan diagnosis untuk X-ray dada ini.", ia mungkin enggan memberikan jawapan, atau menekankan, "Saya bukan pengganti nasihat perubatan profesional. " Dalam kebanyakan kes, GPT-4V akan cenderung menggunakan frasa yang mengandungi "nampak seperti" atau "boleh jadi" untuk menyatakan ketidakpastian.
Bahagian Kes Patologi
Selain itu, untuk meneroka keupayaan GPT-4V dalam penjanaan laporan dan diagnosis perubatan imej patologi, penulis menjalankan ujian tahap blok imej pada 20 imej patologi tumor malignan daripada tisu yang berbeza, dan membuat kesimpulan. kesimpulan berikut:
- GPT-4V mampu mengecam modaliti yang tepat
Dalam semua kes ujian, GPT-4V boleh mengenal pasti modaliti semua imej patologi dengan betul (imej histopatologi bernoda H&E).
- GPT-4V mampu menjana laporan berstruktur
Memandangkan imej patologi tanpa sebarang petunjuk perubatan, GPT-4V boleh menjana laporan berstruktur dan terperinci untuk menerangkan ciri imej. Di antara 20 kes tersebut, 7 kes boleh disenaraikan dengan jelas menggunakan istilah seperti "struktur tisu", "ciri sel", "matriks", "struktur kelenjar", "nukleus" dll.
The above is the detailed content of 178 pages! The first comprehensive case evaluation of GPT-4V (ision) in the medical field: there is still a distance from clinical application and practical decision-making. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology